The Shape of Overthinking: Backtracking Bursts in Long Reasoning Traces
Pith reviewed 2026-06-29 12:32 UTC · model grok-4.3
The pith
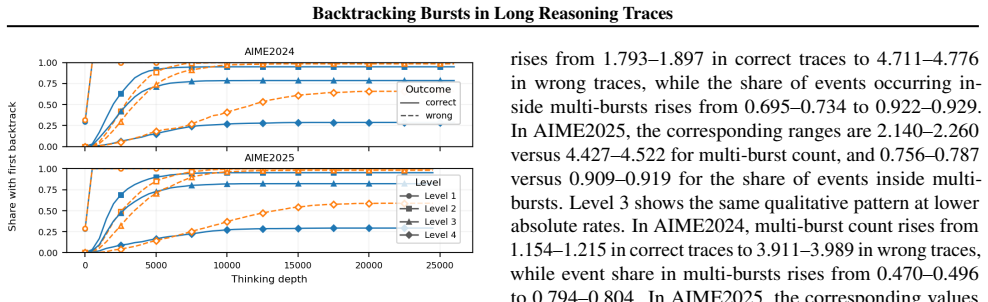
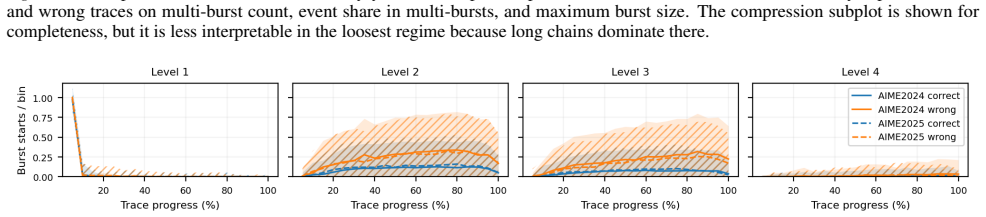
Early isolated repairs often succeed while persistent late backtrack clusters mark incorrect reasoning traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On 6,000 traces, early isolated repair is often compatible with correct reasoning, whereas incorrect traces more often show moderate-to-severe backtracks that persist and cluster late. Cross-corpus checks show the same qualitative asymmetry across additional model and domain pairs. Filtering analyses instantiate the signal as a prefix-causal selective early-exit policy: at shallow and intermediate depths, burst-aware filtering outperforms fixed length-based filtering while using only prefix-available features. Moderate length cutoffs remain strong completed-trace baselines, but burst-aware control provides a deployable mechanism for separating recoverable repair from likely instability.
What carries the argument
Segment-level backtrack severity annotation together with analysis of event timing, normalized depth, and local burst structure
If this is right
- Early isolated repair aligns with correct final answers in the studied traces.
- Incorrect traces feature persistent moderate-to-severe backtracks that cluster late.
- Burst-aware filtering outperforms fixed length-based filtering at shallow and intermediate depths.
- The filtering method uses only features available in the trace prefix.
- Moderate length cutoffs serve as strong baselines while burst-aware control supplies an additional deployable separation mechanism.
Where Pith is reading between the lines
- The temporal clustering of revisions may offer a more diagnostic signal than total revision count alone.
- Prefix burst features could support real-time monitoring to truncate likely unstable generations before completion.
- Similar burst analysis might extend to sequential decision tasks outside language-model reasoning.
- Training procedures could be adjusted to favor early resolution over late clustered revisions.
Load-bearing premise
Segment-level backtrack severity can be annotated reliably enough to distinguish useful self-correction from unproductive revision and the resulting patterns remain stable enough to support a prefix-causal filtering policy.
What would settle it
A fresh corpus in which segment-level severity annotations show no systematic difference in timing or clustering between correct and incorrect final answers, or in which burst features extracted from prefixes fail to improve early-exit accuracy over length alone.
Figures



read the original abstract
Reasoning models often generate long traces in which useful self-correction and unproductive revision are hard to distinguish. We study this distinction through backtracking dynamics: local reconsideration, retraction, or re-derivation inside long-form reasoning traces. On 6{,}000 Qwen3-8B AIME traces, we annotate segment-level backtrack severity and analyze event timing, normalized depth, and local burst structure. We find that early isolated repair is often compatible with correct reasoning, whereas incorrect traces more often show moderate-to-severe backtracks that persist and cluster late. Cross-corpus checks show the same qualitative asymmetry across additional model/domain pairs. Filtering analyses instantiate the signal as a prefix-causal selective early-exit policy: at shallow and intermediate depths, burst-aware filtering outperforms fixed length-based filtering while using only prefix-available features. Moderate length cutoffs remain strong completed-trace baselines, but burst-aware control provides a deployable mechanism for separating recoverable repair from likely instability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes backtracking dynamics in long-form LLM reasoning traces, annotating 6,000 Qwen3-8B traces on AIME problems for segment-level backtrack severity, timing, normalized depth, and burst structure. It reports that early isolated repairs are often compatible with correct final answers, while incorrect traces more frequently exhibit moderate-to-severe backtracks that persist and cluster late; cross-corpus checks confirm the qualitative pattern. The work instantiates this as a prefix-causal burst-aware filtering policy that outperforms fixed length-based early exit at shallow and intermediate depths using only prefix-available features.
Significance. If the annotated distinctions prove reliable, the observational findings could clarify the boundary between productive self-correction and overthinking, supporting practical prefix-causal control policies for reasoning models. The cross-corpus replication and emphasis on deployable, prefix-only features are concrete strengths; however, the absence of annotation validation metrics substantially weakens the evidential basis for the central asymmetry and the derived filtering policy.
major comments (3)
- [Abstract] Abstract and annotation description: the central claim that early isolated repair is compatible with correct reasoning while incorrect traces show moderate-to-severe persistent late bursts rests on segment-level severity annotations of 6,000 traces, yet no annotation protocol, severity rubric, annotator count, or inter-annotator agreement is provided. This directly undermines the reliability of the useful-vs-unproductive distinction and any downstream filtering policy.
- [Filtering analyses] Filtering analyses: the reported superiority of burst-aware filtering over length-based baselines at shallow and intermediate depths is trained on the same unvalidated severity labels; without controls for trace-length distribution, statistical significance tests, or label reliability, the performance advantage cannot be attributed to the backtrack signal rather than annotation artifacts.
- [Cross-corpus checks] Cross-corpus checks: while the qualitative asymmetry is stated to replicate across additional model/domain pairs, the manuscript provides no quantitative metrics, sample sizes, or agreement statistics for these checks, leaving open whether the pattern is stable or driven by the same unvalidated labeling process.
minor comments (1)
- [Abstract] The abstract refers to 'normalized depth' and 'local burst structure' without defining the normalization procedure or burst detection algorithm in the provided summary; these should be formalized early in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing annotation transparency and analytical robustness. We agree that the manuscript would benefit from additional methodological details and controls, and we will revise accordingly to address each point.
read point-by-point responses
-
Referee: [Abstract] Abstract and annotation description: the central claim that early isolated repair is compatible with correct reasoning while incorrect traces show moderate-to-severe persistent late bursts rests on segment-level severity annotations of 6,000 traces, yet no annotation protocol, severity rubric, annotator count, or inter-annotator agreement is provided. This directly undermines the reliability of the useful-vs-unproductive distinction and any downstream filtering policy.
Authors: We agree that these details are necessary. In the revised manuscript we will add a dedicated methods subsection describing the annotation protocol, the severity rubric applied to segments, the number of annotators, and inter-annotator agreement statistics. These additions will directly support the reliability of the severity-based distinctions. revision: yes
-
Referee: [Filtering analyses] Filtering analyses: the reported superiority of burst-aware filtering over length-based baselines at shallow and intermediate depths is trained on the same unvalidated severity labels; without controls for trace-length distribution, statistical significance tests, or label reliability, the performance advantage cannot be attributed to the backtrack signal rather than annotation artifacts.
Authors: We acknowledge the value of these controls. The revision will include explicit controls for trace-length distribution, statistical significance tests on the performance differences, and a discussion of label reliability to better isolate the contribution of the backtrack signal. revision: yes
-
Referee: [Cross-corpus checks] Cross-corpus checks: while the qualitative asymmetry is stated to replicate across additional model/domain pairs, the manuscript provides no quantitative metrics, sample sizes, or agreement statistics for these checks, leaving open whether the pattern is stable or driven by the same unvalidated labeling process.
Authors: We will expand the cross-corpus section with quantitative metrics, sample sizes for each additional model/domain pair, and any agreement statistics available from those checks to demonstrate the stability of the asymmetry. revision: yes
Circularity Check
No significant circularity; purely observational empirical study
full rationale
The paper conducts an annotation-based analysis of 6000 reasoning traces followed by empirical filtering comparisons. No equations, mathematical derivations, fitted parameters, or self-citations are present in the provided text that could reduce any claimed result to its inputs by construction. The filtering policy is an empirical instantiation of observed patterns rather than a prediction forced by the annotation process itself. This is self-contained observational work with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chen, R., Zhang, Z., Hong, J., Kundu, S., and Wang, Z
URL https://arxiv.org/abs/2310.0 5424. Chen, R., Zhang, Z., Hong, J., Kundu, S., and Wang, Z. SEAL: Steerable reasoning calibration of large language models for free.arXiv preprint, 2025. URL https: //arxiv.org/abs/2504.07986. Chen, Y ., Pan, X., Li, Y ., Ding, B., and Zhou, J. EE-LLM: Large-scale training and inference of early-exit large lan- guage mode...
-
[2]
Aly, Beidi Chen, and Carole-Jean Wu
URL https://arxiv.org/abs/2505.0 7686. Del Corro, L., Del Giorno, A., Agarwal, S., Yu, B., Awadal- lah, A., and Mukherjee, S. SkipDecode: Autoregres- sive skip decoding with batching and caching for ef- ficient LLM inference.arXiv preprint, 2023. URL https://arxiv.org/abs/2307.02628. Elhoushi, M., Shrivastava, A., Liskovich, D., Hosmer, B., Wasti, B., Lai...
-
[3]
doi: 10.18653/v1/2025.emnlp-main.904
Association for Computational Linguistics. doi: 10.18653/v1/2025.emnlp-main.904. URL https://ac lanthology.org/2025.emnlp-main.904/. Microsoft Research. Phi-4-reasoning, 2025. URL https: //huggingface.co/microsoft/Phi-4-rea soning. Hugging Face model card. OpenAI. GPT-4o model, 2024. URL https://develo pers.openai.com/api/docs/models/gpt-4 o. OpenAI API d...
-
[4]
Pan, X., Chen, Y ., Li, Y ., Ding, B., and Zhou, J
Hugging Face dataset. Pan, X., Chen, Y ., Li, Y ., Ding, B., and Zhou, J. EE-Tuning: An economical yet scalable solution for tuning early- exit large language models.arXiv preprint, 2024. URL https://arxiv.org/abs/2402.00518. Qwen Team. Qwen3-8B, 2025. URL https://huggin gface.co/Qwen/Qwen3-8B. Hugging Face model card. Qwen Team. Qwen3.5-9B, 2026. URL htt...
-
[5]
URL http://ieeexplore.ieee.org/document/ 7900006/
URL https://openreview.net/forum ?id=Ti67584b98. Sharma, A. and Chopra, P. Think just enough: Sequence- level entropy as a confidence signal for LLM reasoning. arXiv preprint, 2025. URL https://arxiv.org/ abs/2510.08146. Teerapittayanon, S., McDanel, B., and Kung, H. T. BranchyNet: Fast inference via early exiting from deep neural networks. InProceedings ...
-
[6]
URL https://arxiv.org/abs/2504.0 5419. Zhou, W., Xu, C., Ge, T., McAuley, J., Xu, K., and Wei, F. BERT loses patience: Fast and robust inference with early exit. InAdvances in Neural Information Processing Systems, volume 33, 2020. URL https://procee dings.neurips.cc/paper/2020/hash/d4d d111a4fd973394238aca5c05bebe3-Abstrac t.html. A. Severity-Scale Sanit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.