Continual Learning in Modern Hopfield Networks with an Application to Diffusion Models
Pith reviewed 2026-06-29 14:15 UTC · model grok-4.3
The pith
High-energy outlier samples raise their Hopfield energy more than clustered samples after a task shift, marking them as more forgettable in continual learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
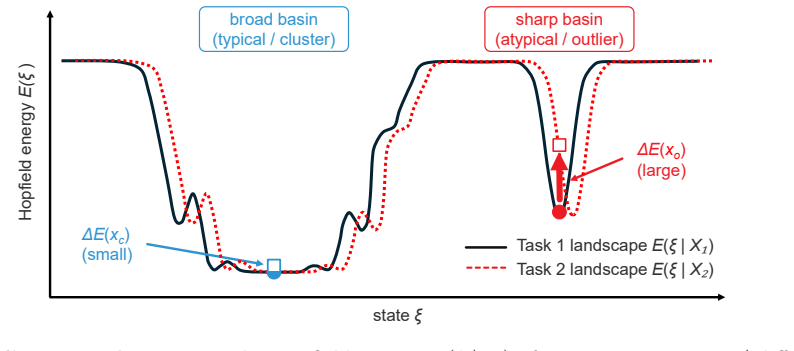
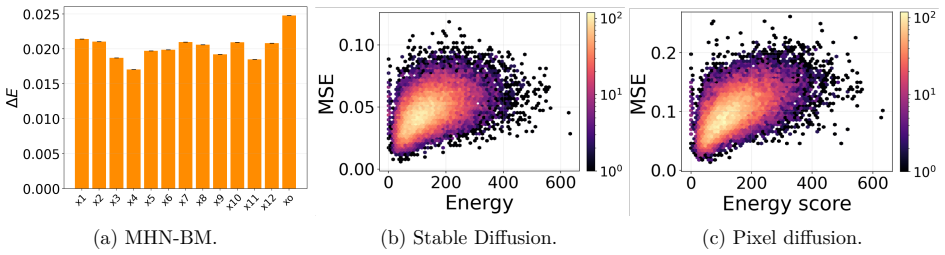
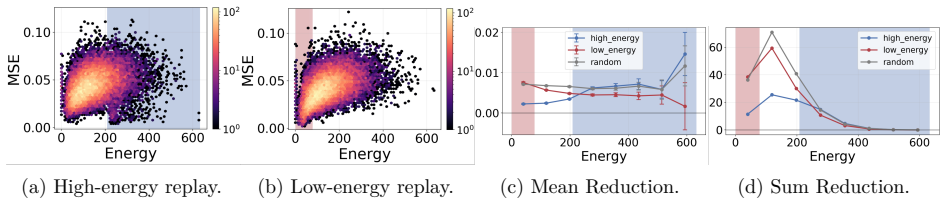
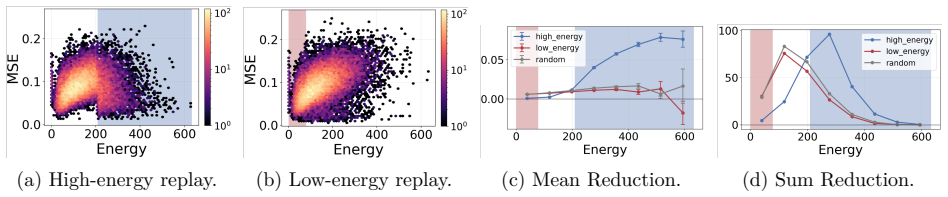
Intrinsic forgetting is defined as an increase in Hopfield energy after a task change. In tractable MHN settings, high-energy outlier-like samples undergo a larger energy increase than cluster-like samples, so samples in sharp isolated basins are more forgettable. Memory replay is particularly effective for high-energy samples and therefore permits energy-based selection of which samples to replay. These relations hold in experiments on MHNs and on Stable Diffusion and pixel-space DDPM under continual-learning schedules.
What carries the argument
The modern Hopfield energy function, which measures how well a sample fits the learned attractor landscape and rises when that fit is lost after a task change.
If this is right
- Samples located in sharp isolated basins are more forgettable than those in dense clusters.
- Energy-based selection of replay samples mitigates forgetting more efficiently than uniform selection.
- Hopfield energy serves as a proxy that tracks reconstruction-based forgetting in diffusion models after task shifts.
- Replay focused on high-energy samples produces stronger retention than replay of low-energy samples.
Where Pith is reading between the lines
- The same energy ranking could be used to decide which regions of the data manifold need protection during any sequential adaptation of a generative model.
- If the energy measure remains predictive at larger scales, it offers a lightweight way to monitor forgetting without running full reconstruction checks on every sample.
- The analysis suggests a concrete way to order replay buffers by energy so that the most vulnerable samples are protected first.
Load-bearing premise
The assumption that established links between modern Hopfield networks and diffusion models let the energy-based forgetting results transfer directly to diffusion models.
What would settle it
A controlled MHN experiment in which low-energy cluster samples show larger energy increases than high-energy outliers after a task change would falsify the central claim.
Figures


read the original abstract
Generative models, including diffusion models, are increasingly used as foundation models and adapted through sequential fine-tuning, making continual learning an essential problem setting. However, continual learning in such generative models remains poorly understood: after a task change, what aspects of the learned distribution are most easily lost, and what replay samples should be prioritized? We address these questions through the modern Hopfield energy. Recent links between modern Hopfield networks (MHNs) and diffusion models allow analyses in MHNs to be transferred to diffusion models. We introduce intrinsic forgetting as an increase in Hopfield energy after the task change. In tractable settings in an MHN, we prove that high-energy, outlier-like samples undergo a larger energy increase than cluster-like samples, implying that samples located in sharp, isolated basins are more forgettable. We further analyze memory replay and show that replay is particularly effective for high-energy samples, enabling an energy-based selection of replay samples. We validate these predictions in experiments on MHNs and two diffusion models under continual-learning settings: Stable Diffusion and a pixel-space DDPM. In these diffusion models, Hopfield energy tracks reconstruction-based forgetting, and replay experiments reveal energy-dependent mitigation of forgetting that is consistent with the MHN analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the modern Hopfield network (MHN) energy function provides a lens for analyzing continual learning in generative models. In tractable MHN settings it proves that high-energy outlier samples undergo a strictly larger energy increase after a task change than low-energy cluster samples, implying greater forgettability; it further shows that replay is especially effective for high-energy samples. Via cited links between MHNs and diffusion models, the same qualitative behavior is asserted to hold in diffusion models and is validated experimentally on Stable Diffusion and a pixel-space DDPM, where Hopfield energy correlates with reconstruction error and energy-based replay mitigates forgetting.
Significance. If the energy-increase inequality and its diffusion-model counterpart hold, the work supplies a theoretically grounded, energy-based criterion for identifying forgettable samples and for selecting replay data in continual fine-tuning of diffusion models. The explicit proof in tractable MHN regimes together with the empirical consistency across two diffusion architectures constitute clear strengths that could directly inform replay-buffer design for foundation-model adaptation.
major comments (2)
- [MHN-to-diffusion transfer] The transfer step (abstract and the diffusion-application section): the claim that the MHN energy-increase result carries over to diffusion models is asserted on the basis of 'recent links' without a derivation showing that the differential energy increase for high-energy samples survives the change of measure, the continuous-time limit, or the score-matching objective. Because the diffusion experiments only report post-hoc correlation between Hopfield energy and reconstruction error, this gap is load-bearing for the central application claim.
- [Diffusion experiments] Experimental validation section (diffusion-model results): the reported correlation between Hopfield energy and forgetting is consistent with the MHN prediction but lacks controls that would isolate energy from confounding factors such as local sample density or task similarity; without such controls the experiments do not yet confirm that the specific MHN inequality, rather than a coarser density effect, drives the observed forgetting pattern.
minor comments (1)
- [Introduction / Definitions] Define 'intrinsic forgetting' explicitly at first use and distinguish it from standard task-wise forgetting metrics to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and have revised the manuscript to clarify the scope of the MHN-to-diffusion transfer and to add controls in the experiments.
read point-by-point responses
-
Referee: [MHN-to-diffusion transfer] The transfer step (abstract and the diffusion-application section): the claim that the MHN energy-increase result carries over to diffusion models is asserted on the basis of 'recent links' without a derivation showing that the differential energy increase for high-energy samples survives the change of measure, the continuous-time limit, or the score-matching objective. Because the diffusion experiments only report post-hoc correlation between Hopfield energy and reconstruction error, this gap is load-bearing for the central application claim.
Authors: We acknowledge that the manuscript does not contain a full derivation proving that the precise energy-increase inequality survives the change of measure, continuous-time limit, and score-matching objective of diffusion models. The transfer is motivated by the structural correspondences established in the cited literature on MHN-diffusion connections, which support a qualitative analogy for the behavior of the energy function. The diffusion experiments are offered as empirical corroboration of the predicted pattern rather than as a formal proof. In the revised manuscript we have added an explicit discussion paragraph in the diffusion-application section that states the assumptions of the transfer, qualifies the claim as qualitative, and notes the absence of a complete bridging derivation. This tempers the central application claim while preserving the motivation from the cited links. revision: yes
-
Referee: [Diffusion experiments] Experimental validation section (diffusion-model results): the reported correlation between Hopfield energy and forgetting is consistent with the MHN prediction but lacks controls that would isolate energy from confounding factors such as local sample density or task similarity; without such controls the experiments do not yet confirm that the specific MHN inequality, rather than a coarser density effect, drives the observed forgetting pattern.
Authors: We agree that the original experiments do not include explicit controls that isolate Hopfield energy from confounders such as local sample density or task similarity. In the revised manuscript we have added new analysis that matches or bins samples by local density (estimated via nearest-neighbor distances in the feature space used for the Hopfield energy) while varying energy, and we report that the correlation between energy and reconstruction error persists within density-matched groups. We have also included a brief discussion of task similarity for the chosen continual-learning splits. These additions provide evidence that the observed pattern is not reducible to a generic density effect. revision: yes
- A rigorous derivation establishing that the differential energy-increase inequality holds exactly under the diffusion change of measure, continuous-time limit, and score-matching objective is not supplied and would require substantial new theoretical work beyond the present manuscript.
Circularity Check
No significant circularity; MHN proof stands independently of diffusion transfer
full rationale
The paper's core derivation is a mathematical proof, performed inside tractable MHN regimes, that high-energy samples undergo strictly larger energy increase than cluster samples after a task change. This step is presented as a first-principles result under the MHN energy function and is not shown to reduce to any fitted parameter, self-definition, or input by construction. The subsequent claim that the same qualitative behavior transfers to diffusion models rests on an external premise ("recent links between MHNs and diffusion models") rather than on any equation inside the present manuscript that would make the inequality tautological. Diffusion-model experiments are described only as post-hoc validation that Hopfield energy correlates with reconstruction error; they do not supply the inequality itself. No self-citation chain, ansatz smuggling, or renaming of known results is required for the MHN proof. The derivation chain is therefore self-contained against the stated MHN assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recent links between modern Hopfield networks (MHNs) and diffusion models allow analyses in MHNs to be transferred to diffusion models.
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, 2020. 11
2020
-
[2]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Diffusion Models Beat GANs on Image Synthesis
Prafulla Dhariwal and Alex Nichol. Diffusion models beat GANs on image synthesis.arXiv preprint arXiv:2105.05233, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models.arXiv preprint arXiv:2112.10752, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Tomczak, Tomasz Trzciński, Florian Shkurti, and Piotr Miłoś
Michał Zaj¸ ac, Kamil Deja, Anna Kuzina, Jakub M. Tomczak, Tomasz Trzciński, Florian Shkurti, and Piotr Miłoś. Exploring continual learning of diffusion models.arXiv preprint arXiv:2303.15342, 2023
-
[6]
Continual diffusion: Continual customization of text-to-image diffusion with C-LoRA.Transactions on Machine Learning Research, 2024
James Seale Smith, Yen-Chang Hsu, Lingyu Zhang, Ting Hua, Zsolt Kira, Yilin Shen, and Hongxia Jin. Continual diffusion: Continual customization of text-to-image diffusion with C-LoRA.Transactions on Machine Learning Research, 2024. ISSN 2835-8856
2024
-
[7]
DDGR: Continual learning with deep diffusion-based generative replay
Rui Gao and Weiwei Liu. DDGR: Continual learning with deep diffusion-based generative replay. InInternational Conference on Machine Learning, volume 202, pages 10744–10763. PMLR, 2023
2023
-
[8]
Continual learning of diffusion models with generative distillation
Sergi Masip, Pau Rodriguez, Tinne Tuytelaars, and Gido M van de Ven. Continual learning of diffusion models with generative distillation. InThird Conference on Lifelong Learning Agents (CoLLAs), 2024
2024
-
[9]
Hopfield
John J. Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558, 1982
1982
-
[10]
Large associative memory problem in neurobiology and machine learning
Dmitry Krotov and John J Hopfield. Large associative memory problem in neurobiology and machine learning. InInternational Conference on Learning Representations, 2021
2021
-
[11]
Memory in plain sight: Surveying the uncanny resemblances of associative memories and diffusion models
Benjamin Hoover, Hendrik Strobelt, Dmitry Krotov, Judy Hoffman, Zsolt Kira, and Duen Horng Chau. Memory in plain sight: Surveying the uncanny resemblances of associative memories and diffusion models. InNeurIPS 2023 Workshop on Associative Memory and Hopfield Networks, 2023
2023
-
[12]
NRGPT: An energy-based alternative for GPT
Nima Dehmamy, Benjamin Hoover, Bishwajit Saha, Leo Kozachkov, Jean-Jacques Slotine, and Dmitry Krotov. NRGPT: An energy-based alternative for GPT. InInternational Conference on Learning Representations, 2026
2026
-
[13]
Out-of-distribution detection based on in-distribution data patterns memo- rization with modern hopfield energy
Jinsong Zhang, Qiang Fu, Xu Chen, Lun Du, Zelin Li, Gang Wang, Xiaoguang Liu, Shi Han, and Dongmei Zhang. Out-of-distribution detection based on in-distribution data patterns memo- rization with modern hopfield energy. InInternational Conference on Learning Representations, September 2022
2022
-
[14]
Energy- based hopfield boosting for out-of-distribution detection
Claus Hofmann, Simon Schmid, Bernhard Lehner, Daniel Klotz, and Sepp Hochreiter. Energy- based hopfield boosting for out-of-distribution detection. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[15]
Equilibrium propagation: Bridging the gap between energy-based models and backpropagation.Frontiers in computational neuroscience, 11:24, 2017
Benjamin Scellier and Yoshua Bengio. Equilibrium propagation: Bridging the gap between energy-based models and backpropagation.Frontiers in computational neuroscience, 11:24, 2017. 12
2017
-
[16]
Hopfield networks is all you need
Hubert Ramsauer, Bernhard Schäfl, Johannes Lehner, Philipp Seidl, Michael Widrich, Thomas Adler, Lukas Gruber, Markus Holzleitner, Milena Pavlović, Geir Kjetil Sandve, Victor Greiff, David Kreil, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. Hopfield networks is all you need. InInternational Conference on Learning Representat...
2021
-
[17]
Luca Ambrogioni. In search of dispersed memories: Generative diffusion models are associative memory networks.Entropy, 26(5):381, 2024. doi: 10.3390/e26050381
-
[18]
Bao Pham, Gabriel Raya, Matteo Negri, Mohammed J Zaki, Luca Ambrogioni, and Dmitry Krotov. Memorization to generalization: Emergence of diffusion models from associative memory.arXiv preprint arXiv:2505.21777, 2025
-
[19]
Spontaneous symmetry breaking in generative diffusion models
Gabriel Raya and Luca Ambrogioni. Spontaneous symmetry breaking in generative diffusion models. InAdvances in Neural Information Processing Systems, volume 36, pages 66377–66389, 2023
2023
-
[20]
The statistical thermodynamics of generative diffusion models: Phase transitions, symmetry breaking, and critical instability.Entropy, 27(3):291, 2025
Luca Ambrogioni. The statistical thermodynamics of generative diffusion models: Phase transitions, symmetry breaking, and critical instability.Entropy, 27(3):291, 2025. doi: 10.3390/ e27030291
2025
-
[21]
On large-batch training for deep learning: Generalization gap and sharp minima
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima. InInternational Conference on Learning Representations, 2017
2017
-
[22]
SWAD: Domain generalization by seeking flat minima
Junbum Cha, Sanghyuk Chun, Kyungjae Lee, Han-Cheol Cho, Seunghyun Park, Yunsung Lee, and Sungrae Park. SWAD: Domain generalization by seeking flat minima. InAdvances in Neural Information Processing Systems, volume 34, pages 22405–22418, 2021
2021
-
[23]
Dense associative memory for pattern recognition
Dmitry Krotov and John J Hopfield. Dense associative memory for pattern recognition. In Advances in Neural Information Processing Systems, June 2016
2016
-
[24]
On a model of associative memory with huge storage capacity.Journal of Statistical Physics, 168:288–299, 2017
Mete Demircigil, Judith Heusel, Matthias Löwe, Sven Upgang, and Franck Vermet. On a model of associative memory with huge storage capacity.Journal of Statistical Physics, 168:288–299, 2017
2017
-
[25]
Jason Ramapuram, Magda Gregorova, and Alexandros Kalousis. Lifelong generative modeling. Neurocomputing, 404:381–400, 2020. doi: 10.1016/j.neucom.2020.02.115
-
[26]
Memory replay GANs: Learning to generate new categories without forgetting
Chenshen Wu, Luis Herranz, Xialei Liu, Yaxing Wang, Joost van de Weijer, and Bogdan Raducanu. Memory replay GANs: Learning to generate new categories without forgetting. In Advances in Neural Information Processing Systems, volume 31, 2018
2018
-
[27]
Lifelong GAN: Continual learning for conditional image generation
Mengyao Zhai, Lei Chen, Frederick Tung, Jiawei He, Megha Nawhal, and Greg Mori. Lifelong GAN: Continual learning for conditional image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2759–2768, 2019
2019
-
[28]
Multiband VAE: Latent space alignment for knowledge consolidation in continual learning
Kamil Deja, Paweł Wawrzyński, Wojciech Masarczyk, Daniel Marczak, and Tomasz Trzciński. Multiband VAE: Latent space alignment for knowledge consolidation in continual learning. arXiv preprint arXiv:2106.12196, 2021. 13
-
[29]
Avoid catastrophic forgetting with rank-1 fisher from diffusion models
Zekun Wang, Anant Gupta, Zihan Dong, and Christopher J MacLellan. Avoid catastrophic forgetting with rank-1 fisher from diffusion models. InInternational Conference on Learning Representations, 2026
2026
-
[30]
Exponential capacity of dense associative memories.Phys
Carlo Lucibello and Marc Mézard. Exponential capacity of dense associative memories.Phys. Rev. Lett., 132(7):077301, February 2024
2024
-
[31]
Toshihiro Ota and Ryo Karakida. Attention in a family of Boltzmann machines emerging from modern Hopfield networks.Neural Computation, 35:1463–1480, 2023. doi: 10.1162/neco_a_ 01597
-
[32]
Beatrice Achilli, Luca Ambrogioni, Carlo Lucibello, Marc Mézard, and Enrico Ventura. The capacity of modern hopfield networks under the data manifold hypothesis.arXiv preprint arXiv:2503.09518, 2025
-
[33]
standard
Sebastian Lee, Stefano Sarao Mannelli, Claudia Clopath, Sebastian Goldt, and Andrew Saxe. Maslow’s hammer in catastrophic forgetting: Node re-use vs. node activation. InInternational Conference on Machine Learning, pages 12455–12477. PMLR, 2022. 14 Appendices A Diffusion–Hopfield Correspondence We summarize the correspondence between diffusion energies an...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.