Rethinking Visual Neglect: Steering via Context-Preference for MLLM Hallucination Mitigation
Pith reviewed 2026-06-29 13:27 UTC · model grok-4.3
The pith
Context-preference vectors from conflict samples steer MLLMs to reduce object hallucinations by balancing image, text, and parametric reliance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
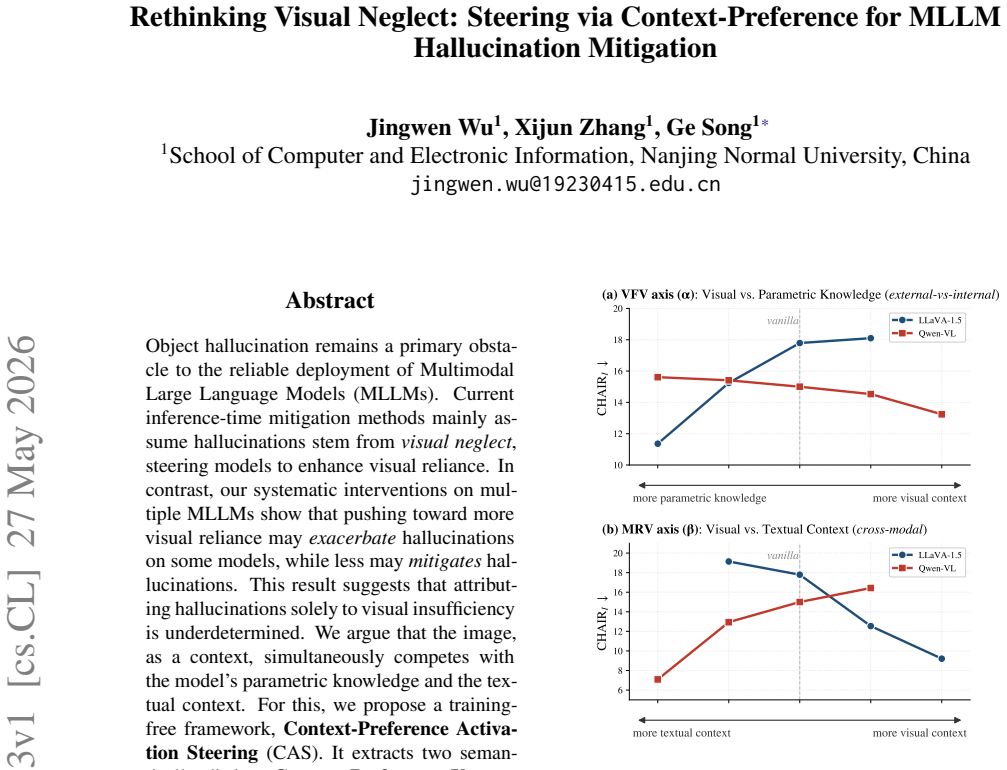
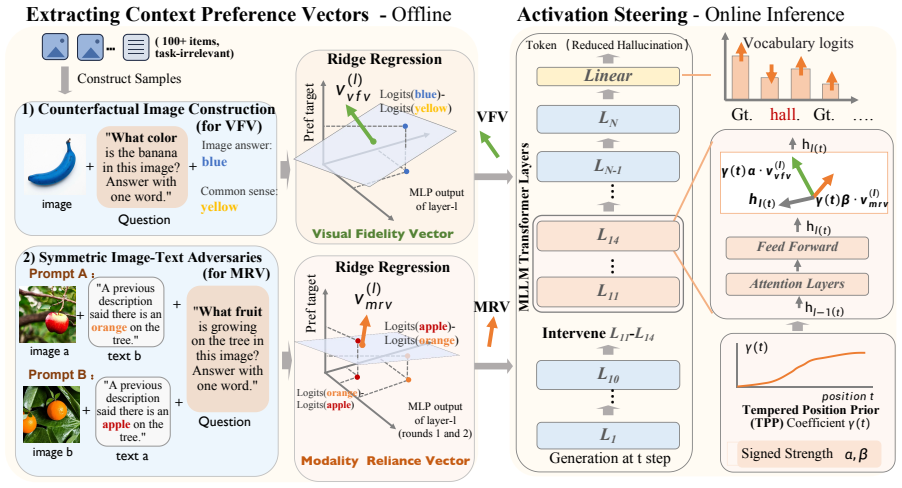
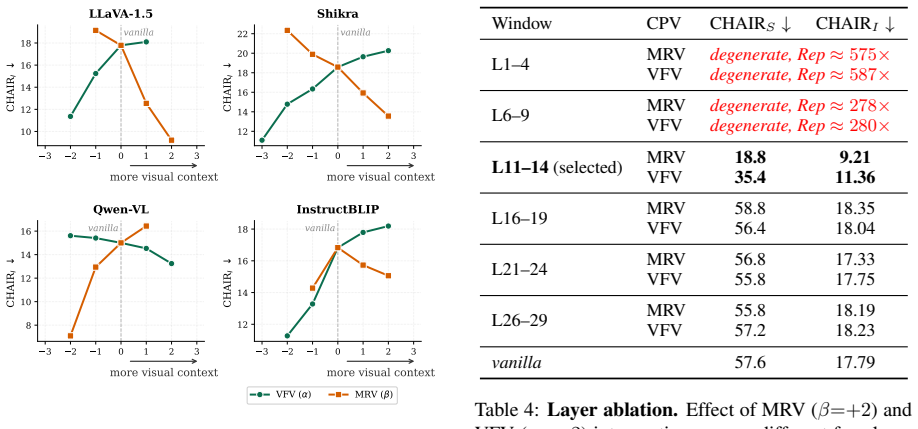
Object hallucinations arise from imbalanced competition among the image as context, the textual context, and the model's parametric knowledge rather than from visual insufficiency alone. Extracting two semantically distinct Context Preference Vectors from small sets of designed conflict samples and applying them via single-pass signed residual injection at mid-early MLP layers during inference allows selective control over information reliance, thereby mitigating hallucinations.
What carries the argument
Context Preference Vectors (CPVs), two vectors extracted from designed conflict samples and injected with signed residuals at mid-early MLP layers to modulate reliance on competing information sources.
If this is right
- CAS substantially mitigates object hallucinations on multiple MLLMs.
- The method adds no decoding latency.
- Native text-generation quality is preserved.
- The framework requires no training or parameter updates.
Where Pith is reading between the lines
- The same conflict-sample vector extraction could be tested on other multimodal tasks such as visual question answering to control different forms of inconsistency.
- Injection at MLP layers might be compared against attention-layer steering to identify which component most directly affects context competition.
- The approach suggests that preference vectors derived from minimal samples could extend to pure-language models for controlling factual versus creative output balance.
Load-bearing premise
Two small sets of designed conflict samples suffice to extract semantically distinct vectors whose signed injection at mid-early MLP layers reliably controls reliance without side effects on generation quality.
What would settle it
Observing that signed CPV injection fails to reduce object hallucinations or increases latency on additional MLLMs or standard benchmarks would show the control mechanism does not generalize.
Figures


read the original abstract
Object hallucination remains a primary obstacle to the reliable deployment of Multimodal Large Language Models (MLLMs). Current inference-time mitigation methods mainly assume hallucinations stem from visual neglect, steering models to enhance visual reliance. In contrast, our systematic interventions on multiple MLLMs show that pushing toward more visual reliance may exacerbate hallucinations on some models, while less may mitigate hallucinations. This result suggests that attributing hallucinations solely to visual insufficiency is underdetermined. We argue that the image, as a context, simultaneously competes with the model's parametric knowledge and the textual context. For this, we propose a training-free framework, Context-Preference Activation Steering (CAS). It extracts two semantically distinct Context Preference Vectors (CPVs) via two small sets of designed conflict samples and applies them via single-pass signed residual injection at mid-early MLP layers during inference to control information reliance. Experiments show that CAS substantially mitigates object hallucinations without increasing decoding latency and preserves native text-generation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that object hallucinations in MLLMs cannot be attributed solely to visual neglect, because systematic interventions show that increasing visual reliance exacerbates hallucinations on some models while decreasing it can mitigate them. It proposes Context-Preference Activation Steering (CAS), a training-free method that extracts two semantically distinct Context Preference Vectors (CPVs) from small sets of designed conflict samples and applies signed residual injection at mid-early MLP layers to control reliance between image context, parametric knowledge, and text, thereby reducing hallucinations without added decoding latency or loss of native text-generation quality.
Significance. If the empirical results hold, the work usefully reframes hallucination mitigation away from uniform visual-enhancement strategies toward context-preference control. The training-free, sample-driven construction of CPVs and the single-pass signed injection are practical strengths that could be adopted quickly; the finding that visual steering is not uniformly beneficial is a falsifiable claim worth testing across additional models.
major comments (2)
- [§3.2] §3.2 (CPV extraction): the claim that two small sets of designed conflict samples suffice to produce semantically distinct CPVs whose signed mid-early MLP injection reliably controls information reliance rests on the weakest assumption; the manuscript must demonstrate robustness to sample choice, explicit validation of semantic distinctness, and absence of unintended side-effects on generation quality.
- [§4] §4 (experimental evaluation): the central claim that CAS substantially mitigates object hallucinations on multiple MLLMs requires the full list of models, datasets, quantitative metrics (e.g., hallucination rates, latency, text-quality scores), and controls; without these the support for the reframing and the method cannot be assessed.
minor comments (2)
- Notation for CPVs and the signed residual injection should be defined once with a clear equation or pseudocode block to avoid ambiguity in later sections.
- Figure captions and table headers should explicitly state the number of conflict samples used and the exact injection layers to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential impact. We address the two major comments point-by-point below. Where additional evidence or clarification is warranted, we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (CPV extraction): the claim that two small sets of designed conflict samples suffice to produce semantically distinct CPVs whose signed mid-early MLP injection reliably controls information reliance rests on the weakest assumption; the manuscript must demonstrate robustness to sample choice, explicit validation of semantic distinctness, and absence of unintended side-effects on generation quality.
Authors: We agree that explicit robustness checks would strengthen the section. In revision we will add: (i) results across 3–5 independently sampled conflict sets per model, reporting mean and variance in hallucination reduction; (ii) cosine-similarity and nearest-neighbor analyses confirming the two CPVs are semantically distinct; and (iii) text-quality metrics (perplexity on held-out captions, win-rate on non-hallucination prompts) showing no degradation. These additions directly address the concern without altering the core method. revision: yes
-
Referee: [§4] §4 (experimental evaluation): the central claim that CAS substantially mitigates object hallucinations on multiple MLLMs requires the full list of models, datasets, quantitative metrics (e.g., hallucination rates, latency, text-quality scores), and controls; without these the support for the reframing and the method cannot be assessed.
Authors: The current manuscript reports results on LLaVA-1.5, MiniGPT-4, and InstructBLIP using POPE and CHAIR, with hallucination-rate reductions, latency measurements (no increase), and preservation of text-generation quality. To make the evaluation fully transparent we will expand §4 with a consolidated table listing every model, dataset, exact metric values, and all controls (layer ablations, sign-flip controls, and comparison to visual-steering baselines). This is a straightforward expansion rather than new experiments. revision: yes
Circularity Check
No significant circularity; method is empirical and sample-driven
full rationale
The paper presents CAS as a training-free, inference-time framework that extracts Context Preference Vectors from two small sets of designed conflict samples and applies signed residual injection at MLP layers. No equations, derivations, or fitted parameters are described that reduce the claimed hallucination mitigation to a self-definition, a renamed input, or a self-citation chain. The central claims rest on systematic interventions and empirical results rather than any load-bearing mathematical reduction to the method's own construction. The approach is self-contained against external benchmarks of hallucination metrics and generation quality.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The image, as a context, simultaneously competes with the model's parametric knowledge and the textual context.
invented entities (1)
-
Context Preference Vectors (CPVs)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. https://arxiv.org/abs/2308.12966 Qwen- VL : A versatile vision-language model for understanding, localization, text reading, and beyond . arXiv preprint arXiv:2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. 2023. https://arxiv.org/abs/2306.15195 Shikra: Unleashing multimodal LLM 's referential dialogue magic . arXiv preprint arXiv:2306.15195
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [5]
-
[6]
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. 2024. https://arxiv.org/abs/2309.03883 DoLa : Decoding by contrasting layers improves factuality in large language models . In Proceedings of the Twelfth International Conference on Learning Representations (ICLR)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [7]
-
[8]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. 2023. https://arxiv.org/abs/2305.06500 Instruct BLIP : Towards general-purpose vision-language models with instruction tuning . In Advances in Neural Information Processing Systems (NeurIPS)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Jiawei Feng, Jiancan Wu, Xingyu Zhu, Junkang Wu, Xiang Wang, and Xiangnan He. 2026. https://openreview.net/forum?id=uZ5AmOJKqV PEA-DPO : Perception-enhanced alignment direct preference optimization for MLLMs alignment . Submitted to ICLR 2026
2026
-
[10]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. https://arxiv.org/abs/2012.14913 Transformer feed-forward layers are key-value memories . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [11]
-
[12]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. 2024. https://arxiv.org/abs/2311.17911 OPERA : Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogn...
- [13]
-
[14]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. 2024. https://arxiv.org/abs/2311.16922 Mitigating object hallucinations in large vision-language models through visual contrastive decoding . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
-
[15]
Qiming Li, Zekai Ye, Xiaocheng Feng, Weihong Zhong, Libo Qin, Ruihan Chen, Baohang Li, Kui Jiang, Yaowei Wang, Ting Liu, and Bing Qin. 2025. https://arxiv.org/abs/2506.23590 Cai: Caption-sensitive attention intervention for mitigating object hallucination in large vision-language models . arXiv preprint arXiv:2506.23590
-
[16]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.20 Evaluating object hallucination in large vision-language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 292--305, Singapore. Association for Computational Linguistics
-
[17]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Doll\' a r. 2014. https://arxiv.org/abs/1405.0312 Microsoft COCO : Common objects in context . In Proceedings of the European Conference on Computer Vision (ECCV)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024 a . https://arxiv.org/abs/2310.03744 Improved baselines with visual instruction tuning . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Highlight
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Shi Liu, Kecheng Zheng, and Wei Chen. 2024 b . https://doi.org/10.1007/978-3-031-73010-8_8 Paying more attention to image: A training-free method for alleviating hallucination in LVLMs . In Proceedings of the European Conference on Computer Vision (ECCV)
-
[20]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. https://arxiv.org/abs/2202.05262 Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems (NeurIPS)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2018. https://arxiv.org/abs/1809.02156 Object hallucination in image captioning . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), Brussels, Belgium. Association for Computational Linguistics
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Nan Sun, Zhenyu Zhang, Xixun Lin, Kun Wang, Yanmin Shang, Naibin Gu, Shuohuan Wang, Yu Sun, Hua Wu, Haifeng Wang, and Yanan Cao. 2025. https://arxiv.org/abs/2512.03542 V-iti: Mitigating hallucinations in multimodal large language models via visual inference-time intervention . arXiv preprint arXiv:2512.03542
- [23]
- [24]
-
[25]
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, and Jitao Sang. 2024. https://arxiv.org/abs/2311.07397 AMBER : An LLM -free multi-dimensional benchmark for MLLMs hallucination evaluation . arXiv preprint arXiv:2311.07397
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [26]
-
[27]
Gonzalez, Trevor Darrell, and David M
Tsung-Han Wu, Heekyung Lee, Jiaxin Ge, Joseph E. Gonzalez, Trevor Darrell, and David M. Chan. 2025. https://arxiv.org/abs/2504.13169 Generate, but verify: Reducing hallucination in vision-language models with retrospective resampling . arXiv preprint arXiv:2504.13169
-
[28]
Shuo Xing, Peiran Li, Yuping Wang, Ruizheng Bai, Yueqi Wang, Chan-Wei Hu, Chengxuan Qian, Huaxiu Yao, and Zhengzhong Tu. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.121 Re- A lign: Aligning vision language models via retrieval-augmented direct preference optimization . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Pr...
-
[29]
Jianghao Yin, Qin Chen, Kedi Chen, Jie Zhou, Xingjiao Wu, and Liang He. 2026. https://openreview.net/forum?id=YtWZdwEG5K Dynamic multimodal activation steering for hallucination mitigation in large vision-language models . In The Fourteenth International Conference on Learning Representations (ICLR)
2026
-
[30]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Tong Xu, Hao Wang, Dianbo Sui, Yunhang Shen, Ke Li, Xing Sun, and Enhong Chen. 2024. https://doi.org/10.1007/s11432-024-4251-x Woodpecker: Hallucination correction for multimodal large language models . Science China Information Sciences
-
[31]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, and Tat-Seng Chua. 2024. https://arxiv.org/abs/2312.00849 RLHF-V : Towards trustworthy MLLMs via behavior alignment from fine-grained correctional human feedback . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern R...
- [32]
-
[33]
Yiyang Zhou, Chenhang Cui, Jaehong Yoon, Linjun Zhang, Zhun Deng, Chelsea Finn, Mohit Bansal, and Huaxiu Yao. 2024. https://arxiv.org/abs/2310.00754 Analyzing and mitigating object hallucination in large vision-language models . In Proceedings of the Twelfth International Conference on Learning Representations (ICLR)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [34]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.