Can It Reach the Generator? Investigating the Survival of Prompt-Injection Attacks in Realistic RAG Settings
Pith reviewed 2026-06-29 11:53 UTC · model grok-4.3
The pith
In realistic RAG pipelines, most prompt-injection attacks do not survive retrieval and reranking to reach the generator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
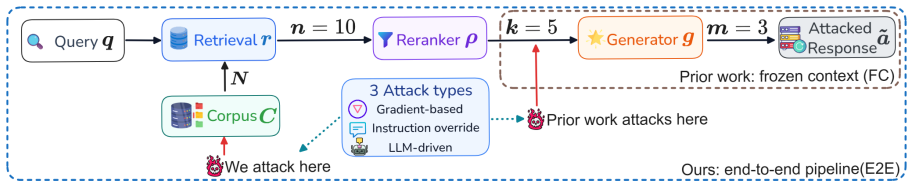
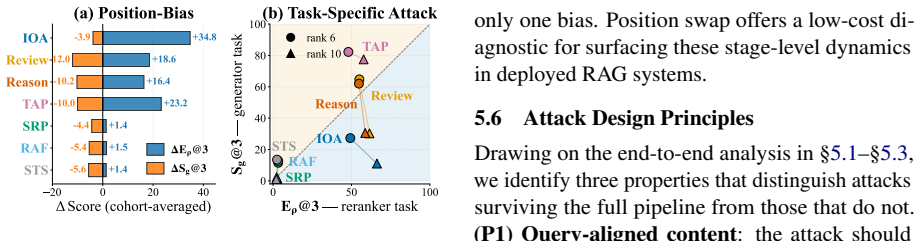
When GEO attacks are evaluated end-to-end through a retriever, LLM reranker, and LLM generator, gradient-based and instruction override attacks largely collapse before reaching the generator, and only LLM-driven prompt injections remain effective end-to-end.
What carries the argument
The three-stage pipeline of retriever followed by LLM reranker followed by LLM generator, which filters out many modified documents before they reach the final model.
If this is right
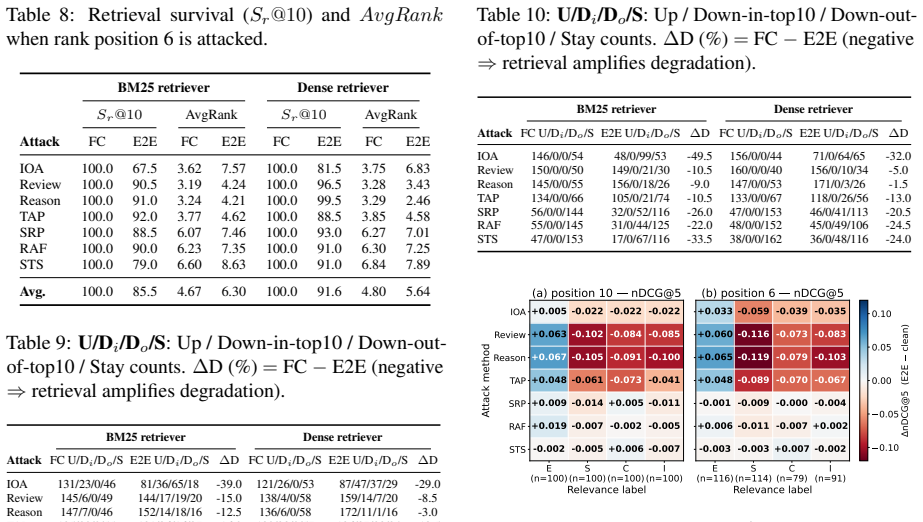
- Gradient-based attacks lose most of their effectiveness once document retrieval and reranking are required.
- Instruction override attacks also fail to survive the full pipeline at high rates.
- LLM-driven prompt injections maintain their ability to influence the generator.
- A lightweight finetuned prompt-injection guard detects every tested attack.
Where Pith is reading between the lines
- Production RAG systems may gain more protection by hardening the retrieval and reranking stages than by hardening the generator alone.
- Success rates measured in direct-injection tests should be treated as upper bounds when estimating risk for live deployments.
- Repeating the survival measurements on additional retriever and reranker architectures would test how general the collapse pattern is.
Load-bearing premise
The specific retriever, reranker, and generator models, datasets, and attack implementations chosen for the three-stage pipeline are representative of deployed production RAG systems.
What would settle it
Re-running the seven attacks through a different combination of retriever, reranker, and generator models and checking whether gradient-based and instruction-override attacks still largely fail to reach the generator.
Figures

read the original abstract
Recent generative engine optimisation (GEO) research has shown that prompt-injection attacks can push a target product to the top of an LLM's recommendation list, with the strongest attacks reporting around $80\%$ success and raising serious security concerns about RAG-based recommendation. However, these results assume the attacked document is always fed directly to the generator, bypassing the retriever and reranker. This is unrealistic: in deployed RAG systems, the attack modifies the document content, which can in turn change whether the document is retrieved and reranked highly enough to reach the generator at all. In this paper, we re-evaluate seven GEO attacks under a realistic three-stage pipeline (retriever\,$\to$\,LLM reranker\,$\to$\,LLM generator). We find that prior protocols substantially overstate attack effectiveness: gradient-based and instruction override attacks largely collapse before reaching the generator, and only LLM-driven prompt injections remain effective end-to-end. Our analysis further reveals that current GEO attacks are easily detectable: a lightweight prompt-injection guard finetuned on a small attack dataset already detects every attack. Our code and data are available at https://github.com/ielab/geo_injection_rag_survival.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prior GEO research overstates the effectiveness of prompt-injection attacks by assuming attacked documents are directly passed to the generator. Re-evaluating seven attacks in a realistic three-stage RAG pipeline (retriever → LLM reranker → LLM generator) shows that gradient-based and instruction-override attacks largely fail to reach the generator, while only LLM-driven prompt injections remain effective end-to-end; the attacks are also easily detectable by a lightweight finetuned guard. Code and data are released.
Significance. If the results hold, the work underscores the gap between simplified attack evaluations and deployed RAG systems, indicating that security concerns from earlier studies may be overstated. The open release of code and data is a clear strength that supports reproducibility and further testing of the survival-rate findings.
major comments (2)
- [Abstract] The central claim that gradient-based and instruction-override attacks 'largely collapse' before reaching the generator is measured only on one fixed retriever/reranker/generator pipeline (Abstract); without ablations on alternative dense retrievers, cross-encoders, or production rerankers, the result is tied to this specific configuration and its generalizability to other deployed systems is unclear.
- [Abstract] The abstract states clear experimental outcomes on attack survival rates but provides no details on statistical tests, exact model sizes, dataset sizes, or controls for confounding factors, preventing full assessment of support for the reported differences between attack types.
minor comments (1)
- [Abstract] The 80% success rate cited from prior work lacks a specific reference to the protocols being compared.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We respond to each major comment below and outline revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] The central claim that gradient-based and instruction-override attacks 'largely collapse' before reaching the generator is measured only on one fixed retriever/reranker/generator pipeline (Abstract); without ablations on alternative dense retrievers, cross-encoders, or production rerankers, the result is tied to this specific configuration and its generalizability to other deployed systems is unclear.
Authors: We chose a representative three-stage pipeline (dense retriever, LLM reranker, LLM generator) to reflect common deployed RAG setups and highlight the survival problem. We agree that additional ablations would strengthen claims of generalizability. In the revision we will add results using an alternative dense retriever and a cross-encoder reranker, reporting attack survival rates across these configurations. This will allow readers to assess whether the observed collapse is configuration-specific. revision: yes
-
Referee: [Abstract] The abstract states clear experimental outcomes on attack survival rates but provides no details on statistical tests, exact model sizes, dataset sizes, or controls for confounding factors, preventing full assessment of support for the reported differences between attack types.
Authors: The abstract is space-constrained, but we accept that key parameters should be stated to support the claims. We will revise the abstract to include dataset size (1000 queries), model sizes (7B reranker and generator), and note that statistical significance was assessed via paired tests. Full details on controls (fixed seeds, identical templates) and exact statistical procedures already appear in Section 3 and the released code; we will add an explicit cross-reference in the abstract. revision: partial
Circularity Check
No circularity; purely empirical attack survival measurements
full rationale
The paper conducts an empirical re-evaluation of seven GEO attacks by measuring their end-to-end survival rates through an explicit three-stage RAG pipeline (retriever → reranker → generator). No equations, fitted parameters, self-citations used as load-bearing premises, or derivations are present in the provided text. All claims reduce directly to observed success rates on the chosen models and datasets, with no reduction by construction or renaming of prior results. This is a standard empirical comparison and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, and Ameet Deshpande. 2024. Geo: Generative engine optimization. In Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, pages 5--16
2024
-
[2]
Amazon News . 2025. https://www.aboutamazon.com/news/retail/amazon-rufus-ai-assistant-personalized-shopping-features Amazon's next-gen ai assistant for shopping is now even smarter, more capable, and more helpful . Accessed: 2026-05-08
2025
-
[3]
Ricardo Baeza-Yates, Berthier Ribeiro-Neto, and 1 others. 1999. Modern information retrieval, volume 463. ACM press New York
1999
- [4]
-
[5]
Xin Cheng, Xun Wang, Xingxing Zhang, Tao Ge, Si-Qing Chen, Furu Wei, Huishuai Zhang, and Dongyan Zhao. 2024. xrag: Extreme context compression for retrieval-augmented generation with one token. Advances in Neural Information Processing Systems, 37:109487--109516
2024
-
[6]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, and 1 others. 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2(1):32
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, and Wayne Xin Zhao. 2024. Large language models are zero-shot rankers for recommender systems. In European conference on information retrieval, pages 364--381. Springer
2024
-
[8]
Chumeng Jiang, Jiayin Wang, Weizhi Ma, Charles LA Clarke, Shuai Wang, Chuhan Wu, and Min Zhang. 2025. Beyond utility: Evaluating llm as recommender. In Proceedings of the ACM on Web Conference 2025, pages 3850--3862
2025
- [9]
-
[10]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769--6781
2020
- [11]
-
[12]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts. Transactions of the association for computational linguistics, 12:157--173
2024
-
[13]
Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. 2024. Fine-tuning llama for multi-stage text retrieval. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2421--2425
2024
- [14]
-
[15]
Meta . 2025 a . Llama guard 4. https://www.llama.com/docs/model-cards-and-prompt-formats/llama-guard-4/. Accessed: 2026-05-10
2025
-
[16]
Meta . 2025 b . Prompt guard 2. https://www.llama.com/docs/model-cards-and-prompt-formats/prompt-guard/. Accessed: 2026-05-10
2025
-
[17]
Rodrigo Nogueira, Zhiying Jiang, Ronak Pradeep, and Jimmy Lin. 2020. Document ranking with a pretrained sequence-to-sequence model. In Findings of the association for computational linguistics: EMNLP 2020, pages 708--718
2020
-
[18]
Samuel Pfrommer, Yatong Bai, Tanmay Gautam, and Somayeh Sojoudi. 2024. Ranking manipulation for conversational search engines. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9523--9552
2024
-
[19]
Yaoyao Qian, Yifan Zeng, Yuchao Jiang, Chelsi Jain, and Huazheng Wang. 2025. The ranking blind spot: Decision hijacking in llm-based text ranking. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21969--21979
2025
-
[20]
Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Le Yan, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, and 1 others. 2024. Large language models are effective text rankers with pairwise ranking prompting. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 1504--1518
2024
-
[21]
David Rau, Herv \'e D \'e jean, Nadezhda Chirkova, Thibault Formal, Shuai Wang, St \'e phane Clinchant, and Vassilina Nikoulina. 2024. Bergen: A benchmarking library for retrieval-augmented generation. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7640--7663
2024
- [22]
-
[23]
Stephen Robertson and Hugo Zaragoza. 2009. The probabilistic relevance framework: BM25 and beyond, volume 4. Now Publishers Inc
2009
-
[24]
Stephen E Robertson and K Sparck Jones. 1976. Relevance weighting of search terms. Journal of the American Society for Information science, 27(3):129--146
1976
-
[25]
Devendra Sachan, Mike Lewis, Mandar Joshi, Armen Aghajanyan, Wen-tau Yih, Joelle Pineau, and Luke Zettlemoyer. 2022. Improving passage retrieval with zero-shot question generation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3781--3797
2022
-
[26]
Hinrich Sch \"u tze, Christopher D Manning, and Prabhakar Raghavan. 2008. Introduction to information retrieval, volume 39. Cambridge University Press Cambridge
2008
-
[27]
Dave Smith. 2025. https://fortune.com/2025/11/02/amazon-rufus-ai-shopping-assistant-chatbot-10-billion-sales-monetization/ Amazon says its ai shopping assistant rufus is so effective it's on pace to pull in an extra \ 10 billion in sales . Accessed: 2026-05-08
2025
-
[28]
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. Is chatgpt good at search? investigating large language models as re-ranking agents. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 14918--14937
2023
-
[29]
Raphael Tang, Crystina Zhang, Xueguang Ma, Jimmy Lin, and Ferhan T \"u re. 2024. Found in the middle: Permutation self-consistency improves listwise ranking in large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pag...
2024
- [30]
- [31]
-
[32]
Lidan Wang, Jimmy Lin, and Donald Metzler. 2011. A cascade ranking model for efficient ranked retrieval. In Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval, pages 105--114
2011
-
[33]
Tiancheng Xing, Jerry Li, Yixuan Du, and Xiyang Hu. 2025. Are llms reliable rankers? rank manipulation via two-stage token optimization. arXiv preprint arXiv:2510.06732
work page internal anchor Pith review arXiv 2025
- [34]
-
[35]
Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, and Bryan Catanzaro. 2024. Rankrag: Unifying context ranking with retrieval-augmented generation in llms. Advances in Neural Information Processing Systems, 37:121156--121184
2024
-
[36]
Haiquan Zhao, Chenhan Yuan, Fei Huang, Xiaomeng Hu, Yichang Zhang, An Yang, Bowen Yu, Dayiheng Liu, Jingren Zhou, Junyang Lin, and 1 others. 2025. Qwen3guard technical report. arXiv preprint arXiv:2510.14276
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Tao Zhou and Songtao Li. 2026. Understanding user switch of information seeking: From search engines to generative ai. Journal of librarianship and information science, 58(1):696--708
2026
-
[38]
Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, and Guido Zuccon. 2024. A setwise approach for effective and highly efficient zero-shot ranking with large language models. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 38--47
2024
-
[39]
Guido Zuccon, Shengyao Zhuang, and Xueguang Ma. 2025. R2llms: Retrieval and ranking with llms. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 4106--4109
2025
-
[40]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[41]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.