BPPO: Binary Prefix Policy Optimization for Efficient GRPO-Style Reasoning RL with Concise Responses
Pith reviewed 2026-06-29 13:50 UTC · model grok-4.3
The pith
BPPO replaces full GRPO updates with shortest correct-incorrect prefix pairs to cut training cost and response length.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Within each prompt group the shortest correct and shortest incorrect completions supply a compact yet sufficient contrastive signal; updating the policy only on their common prefix, while still normalizing advantages over the full group, preserves learning progress, reduces wall-clock time, and discourages redundant suffixes that lengthen responses.
What carries the argument
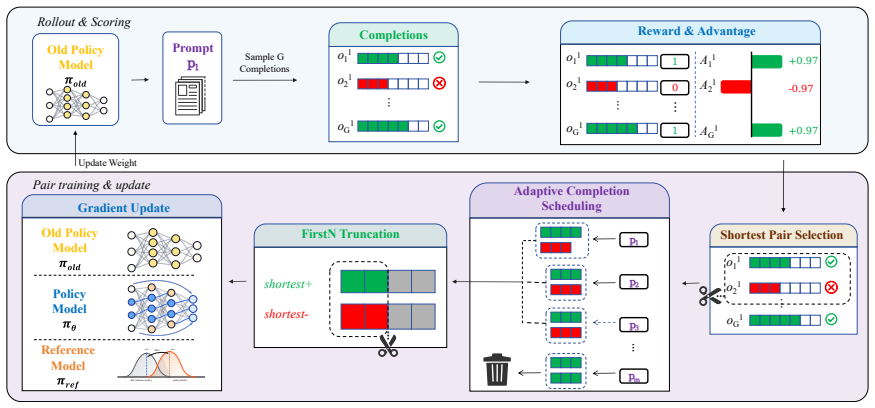
Binary Prefix Policy Optimization (BPPO), which selects the shortest correct and shortest incorrect completions per group and performs prefix-focused policy updates while preserving full-group advantage normalization.
If this is right
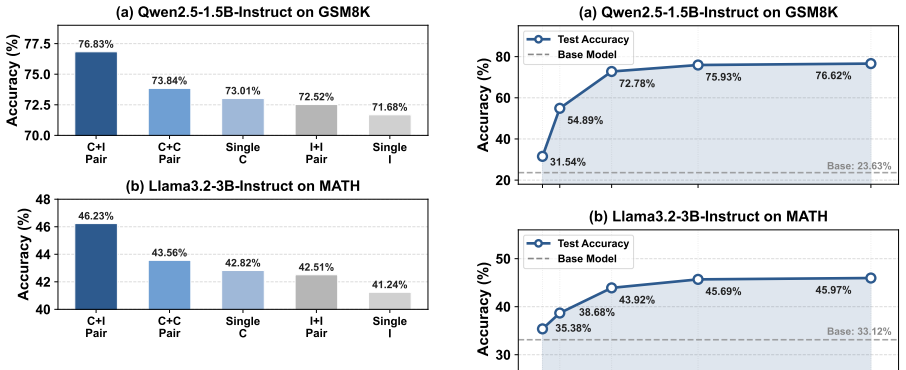
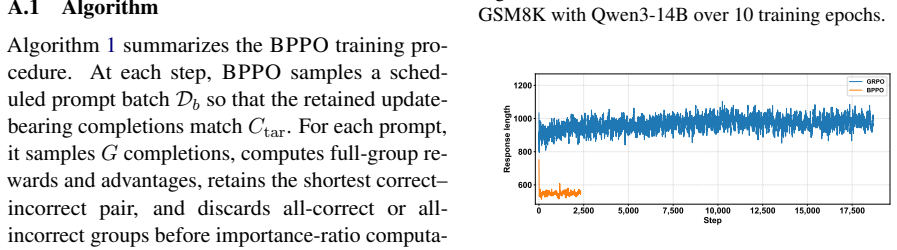
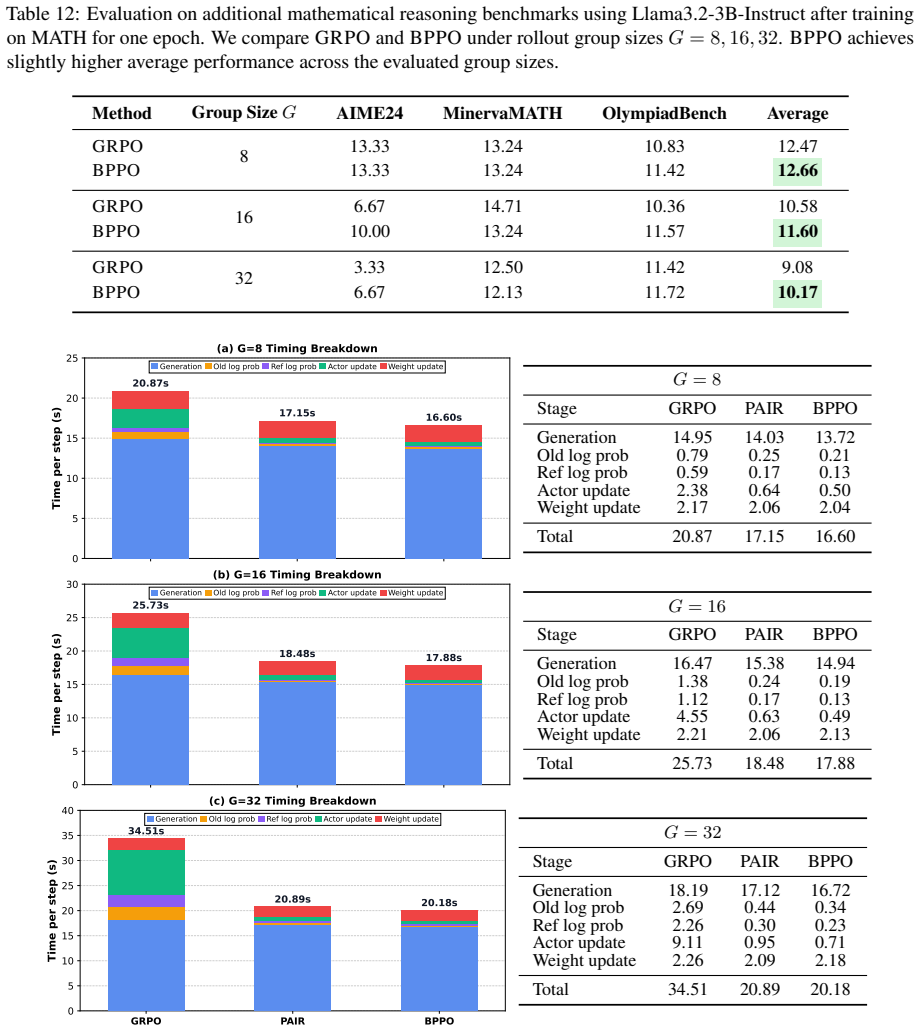
- Training reaches competitive accuracy on GSM8K, MATH and Geo3K at up to 6.08 times lower wall-clock cost than GRPO.
- Mean response length drops 30-50 percent with no length penalty added to the reward.
- Adaptive completion scheduling and prefix-only gradients further reduce computation while avoiding reinforcement of verbose suffixes.
- Full-group advantage normalization is retained, so relative ranking signals across all samples remain available.
Where Pith is reading between the lines
- The same binary-prefix selection could be applied to other group-based RL algorithms that currently update every sample.
- Shorter reasoning traces may reduce inference latency and memory use when the trained models are deployed.
- The approach may interact favorably with reward functions that already penalize length, though the paper does not test this combination.
Load-bearing premise
Gradient updates from same-class completions are similar enough that discarding all but the shortest pair loses no essential learning signal.
What would settle it
An ablation on the same benchmarks in which replacing the binary shortest pair with random same-class pairs produces measurably lower final accuracy or slower convergence.
Figures





read the original abstract
Group Relative Policy Optimization (GRPO) is widely used for training reasoning models, but updating all sampled completions in each group incurs substantial cost and can reinforce verbose reasoning trajectories. In this paper, we study whether all completions provide equally useful update signals in GRPO-style reasoning RL. Our gradient-similarity analysis shows that, within the same prompt group, same-class completions often induce highly similar update directions, whereas correct-incorrect pairs provide more distinct contrastive signals. Motivated by this observation, we propose Binary Prefix Policy Optimization (BPPO), which uses the shortest correct completion and the shortest incorrect completion as a compact update unit while preserving full-group advantage normalization. BPPO further improves efficiency with adaptive completion scheduling and prefix-focused optimization; by updating only response prefixes, it avoids reinforcing redundant suffixes and encourages more concise responses. Experiments on GSM8K, MATH, and Geo3K show that BPPO achieves up to 6.08x speedup over GRPO while maintaining competitive accuracy, and reduces mean response length by approximately 30-50% without modifying the reward with an explicit length penalty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Binary Prefix Policy Optimization (BPPO) to improve the efficiency of Group Relative Policy Optimization (GRPO) for reasoning reinforcement learning. Through gradient-similarity analysis, it observes that same-class completions within a prompt group produce similar update directions, while correct and incorrect pairs provide distinct signals. BPPO selects the shortest correct and shortest incorrect completions for updates, maintains full-group advantage normalization, incorporates adaptive completion scheduling, and uses prefix-focused optimization to promote concise responses. On benchmarks like GSM8K, MATH, and Geo3K, it reports up to 6.08x speedup over GRPO with competitive accuracy and 30-50% shorter mean response lengths without an explicit length penalty in the reward.
Significance. If the results hold, this work could significantly advance efficient RL training for reasoning models by reducing computational costs and response verbosity, which is important for scaling such methods and improving practical usability of reasoning LLMs.
major comments (3)
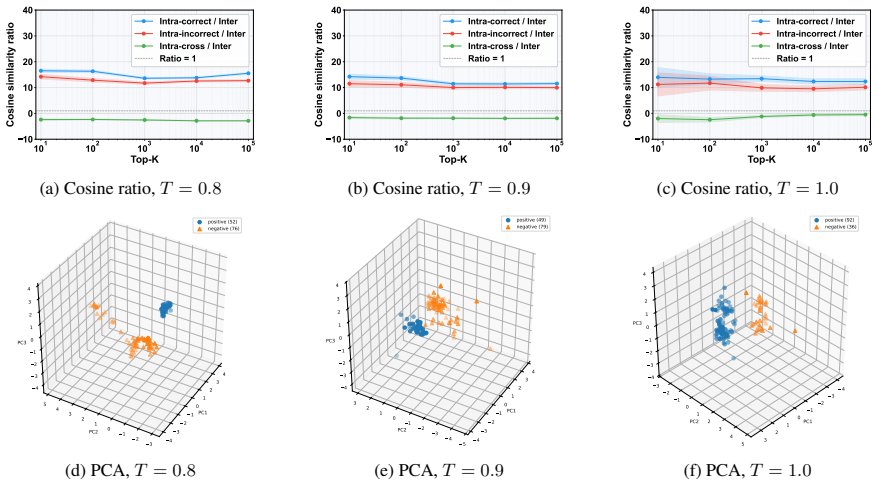
- [Gradient-similarity analysis] The gradient-similarity analysis (motivating the binary selection) claims same-class completions induce highly similar update directions while correct-incorrect pairs yield distinct signals, but provides no quantitative thresholds, variance metrics across groups, model scales, reward formulations, or group sizes. This is load-bearing for the central efficiency claim, as moderate similarity could mean discarding completions loses useful gradient signal or introduces bias toward shortest trajectories.
- [BPPO method] § on BPPO algorithm: the claim that full-group advantage normalization is preserved while updating only the shortest correct and shortest incorrect completions requires explicit derivation or pseudocode verification; it is unclear how normalization over the full group is maintained without access to all completions.
- [Experiments] Experiments section: the 6.08x speedup and competitive accuracy claims need supporting tables with per-benchmark breakdowns, error bars, and ablations (e.g., shortest vs. random selection) to confirm the binary rule does not degrade performance under varying conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. We agree that the suggested additions will strengthen the manuscript and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Gradient-similarity analysis] The gradient-similarity analysis (motivating the binary selection) claims same-class completions induce highly similar update directions while correct-incorrect pairs yield distinct signals, but provides no quantitative thresholds, variance metrics across groups, model scales, reward formulations, or group sizes. This is load-bearing for the central efficiency claim, as moderate similarity could mean discarding completions loses useful gradient signal or introduces bias toward shortest trajectories.
Authors: We acknowledge that the current analysis is primarily based on visual inspection of gradient similarities. In the revision we will add quantitative results, including mean cosine similarity values with standard deviations computed across multiple prompt groups, and report these metrics for varying model scales, reward formulations, and group sizes. This will provide explicit thresholds and directly address concerns regarding potential loss of gradient signal. revision: yes
-
Referee: [BPPO method] § on BPPO algorithm: the claim that full-group advantage normalization is preserved while updating only the shortest correct and shortest incorrect completions requires explicit derivation or pseudocode verification; it is unclear how normalization over the full group is maintained without access to all completions.
Authors: The full-group advantage normalization is computed using all sampled completions to obtain standardized advantages; only the shortest correct and shortest incorrect completions are then selected for the subsequent policy gradient update. We will include explicit pseudocode and a derivation clarifying this two-stage process in the revised BPPO algorithm section. revision: yes
-
Referee: [Experiments] Experiments section: the 6.08x speedup and competitive accuracy claims need supporting tables with per-benchmark breakdowns, error bars, and ablations (e.g., shortest vs. random selection) to confirm the binary rule does not degrade performance under varying conditions.
Authors: We agree that more granular experimental evidence is required. The revised manuscript will include per-benchmark tables reporting accuracy and speedup with error bars from multiple random seeds, along with an ablation comparing shortest-class selection against random selection within the same class to verify robustness. revision: yes
Circularity Check
No significant circularity; claims rest on empirical benchmarks
full rationale
The paper presents BPPO as motivated by an empirical gradient-similarity observation and validated through experiments on GSM8K, MATH, and Geo3K showing speedup and length reduction. No derivation chain, equations, or self-citations are shown that reduce any claimed result to its own inputs by construction; the central efficiency and conciseness claims are externally falsifiable via reported metrics rather than self-referential.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Mz Dai, Chenxu Yang, and Qingyi Si. 2026. S-GRPO: Early exit via reinforcement learning in reasoning models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Tri Dao. 2024. Flashattention-2: Faster attention with better parallelism and work partition...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
AREAL: A large-scale asynchronous rein- forcement learning system for language reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, Amy Yang, Angela Fan, Anir...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
InAdvances in Neural Information Processing Systems
Solving quantitative reasoning problems with language models. InAdvances in Neural Information Processing Systems. Wendi Li, Wei Wei, Kaihe Xu, Wenfeng Xie, Dangyang Chen, and Yu Cheng. 2024. Reinforcement learning with token-level feedback for controllable text gen- eration. InFindings of the Association for Computa- tional Linguistics: NAACL 2024, pages...
-
[4]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. ZhiHang Lin, Mingbao Lin, Yuan Xie, and Rongrong Ji. 2026. CPPO: Accelerating the training of group relative policy optimization-based reasoning models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Wei Liu, Ruochen Zhou, Yiyun...
2026
-
[5]
InSecond Conference on Language Modeling
Understanding r1-zero-like training: A critical perspective. InSecond Conference on Language Modeling. Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. 2021. Inter-GPS: Interpretable geometry problem solving with formal language and symbolic reasoning. In Proceedings of the 59th Annual Meeting of the Asso- ciatio...
-
[6]
InThirty-seventh Conference on Neural Information Processing Sys- tems
Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Sys- tems. Soumya Rani Samineni, Durgesh Kalwar, Karthik Valmeekam, Kaya Stechly, and Subbarao Kambham- pati. 2025. RL in name only? analyzing the structural assumptions in RL post-training for LLMs. InFirst Workshop...
-
[7]
InAdvances in Neural Information Processing Systems, volume 38, pages 173449–173476
Improving data efficiency for llm reinforce- ment fine-tuning through difficulty-targeted online data selection and rollout replay. InAdvances in Neural Information Processing Systems, volume 38, pages 173449–173476. Curran Associates, Inc. Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Met- zler. 2022. Efficient transformers: A survey.ACM Comput. Surv....
2022
-
[8]
InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 9426–9439, Bangkok, Thailand
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 9426–9439, Bangkok, Thailand. Associ- ation for Computational Linguistics. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xi...
2022
-
[9]
Group Sequence Policy Optimization
Just enough thinking: Efficient reasoning with adaptive length penalties reinforcement learning. In NeurIPS 2025 Workshop on Efficient Reasoning. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gao- hong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Ch...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Calculate the daily time spent on one dog: - Each dog takes 0.5 hours per day
-
[11]
- Total daily time = Number of dogs×Time per dog - Total daily time =10×0.5hours
Calculate the total daily time for all dogs: - John takes care of 10 dogs. - Total daily time = Number of dogs×Time per dog - Total daily time =10×0.5hours
-
[12]
- Convert 0.5 hours to minutes: 0.5hours×60minutes/hour= 30minutes - So, each dog takes 30 minutes per day
Convert the daily time from hours to minutes (op- tional but useful): - There are 60 minutes in an hour. - Convert 0.5 hours to minutes: 0.5hours×60minutes/hour= 30minutes - So, each dog takes 30 minutes per day
-
[13]
- Total weekly time = Daily time×Days per week - Total weekly time = (10 dogs) × (30 minutes/dog/- day)×(7 days/week)
Calculate the weekly time spent on all dogs: - There are 7 days in a week. - Total weekly time = Daily time×Days per week - Total weekly time = (10 dogs) × (30 minutes/dog/- day)×(7 days/week)
-
[14]
Perform the multiplication: - First, multiply the number of dogs by the time per dog per day: 10×30 = 300minutes - Then, multiply this result by the number of days per week: 300minutes/day×7days/week= 2100minutes/week
-
[15]
- Convert 2100 minutes to hours: 2100minutes÷60minutes/hour= 35hours Therefore, the final answer is: 35
Convert the weekly time back to hours: - There are 60 minutes in an hour. - Convert 2100 minutes to hours: 2100minutes÷60minutes/hour= 35hours Therefore, the final answer is: 35 . BPPO Response✓ To determine how many hours John spends taking care of dogs each week, we can break down the problem into smaller steps:
-
[16]
Time per dog per day = 0.5 hours
-
[17]
Total time per day for 10 dogs: 0.5×10 = 5hours
-
[18]
Therefore, the final answer is: 35
Weekly time: 5×7 = 35hours. Therefore, the final answer is: 35 . John spends 35 hours a week taking care of his dogs. Figure 9: Case study on GSM8K. Both GRPO and BPPO generate the correct answer, while BPPO produces a more concise and direct reasoning trajectory. Question.A group of 10 Caltech students go to Lake Street for lunch. Each student eats at ei...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.