Personality, Role, and Expressive Style in Large Language Models: An Interactionist Analysis
Pith reviewed 2026-06-29 12:49 UTC · model grok-4.3
The pith
Expressed Big Five traits in LLM dialogues arise from the interplay of trait prompts, dialogue roles, and expressive styles rather than prompts alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
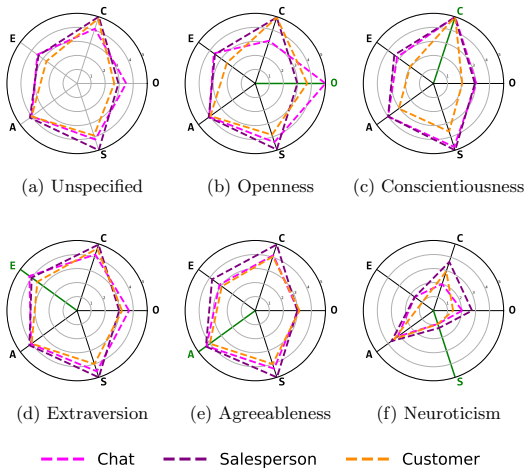
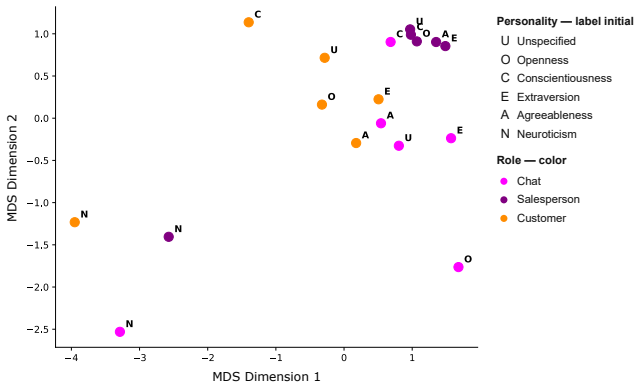
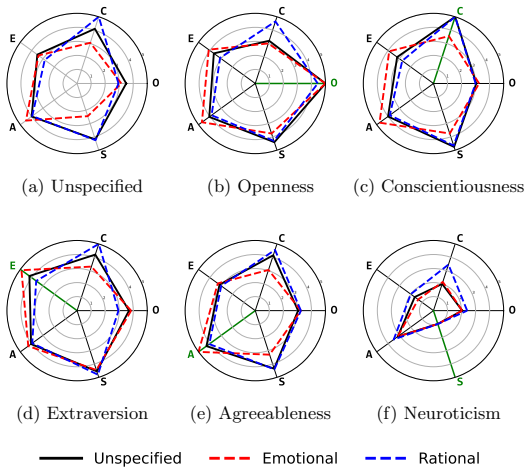
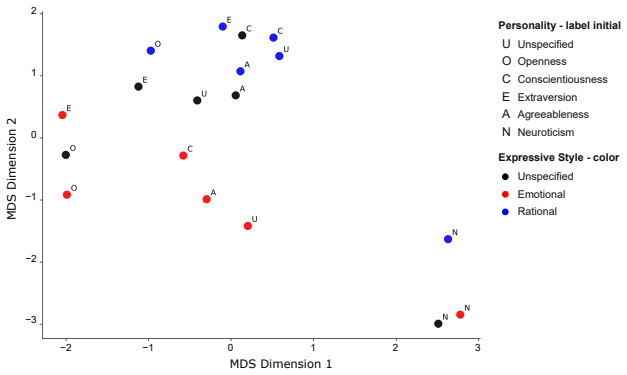
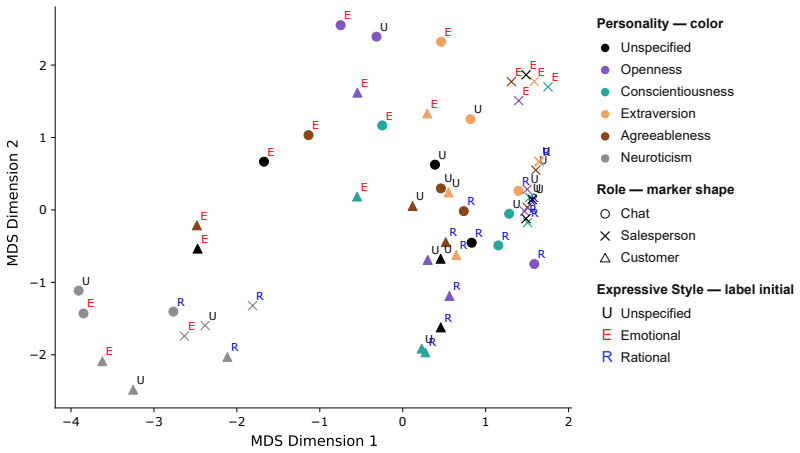
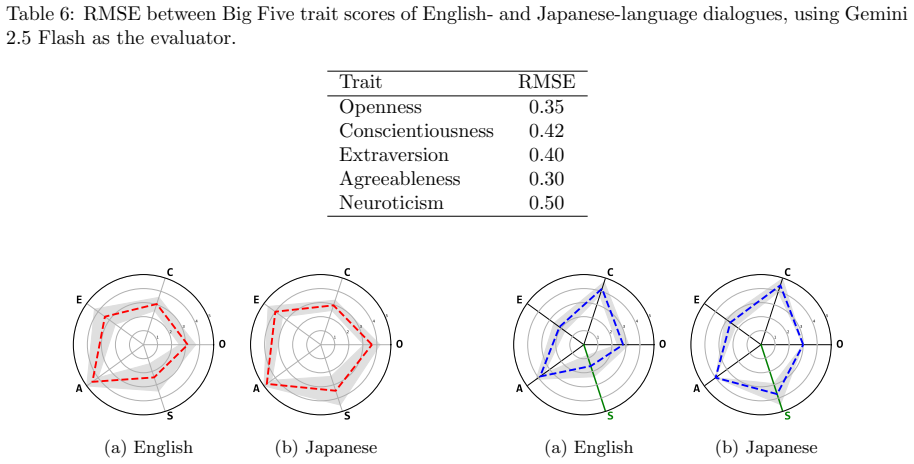
Perceived personality expression in LLM agents is a context-dependent outcome of three factors acting together: explicit personality-trait specification in the prompt, the assigned dialogue role, and the chosen expressive style. These factors produce trait-specific effects, with dialogue role exerting strong influence on Openness, expressive style shaping Conscientiousness and Agreeableness, and explicit trait specification dominating Neuroticism. Social and expressive conditions alone can induce distinct personality-like impressions without any trait prompt.
What carries the argument
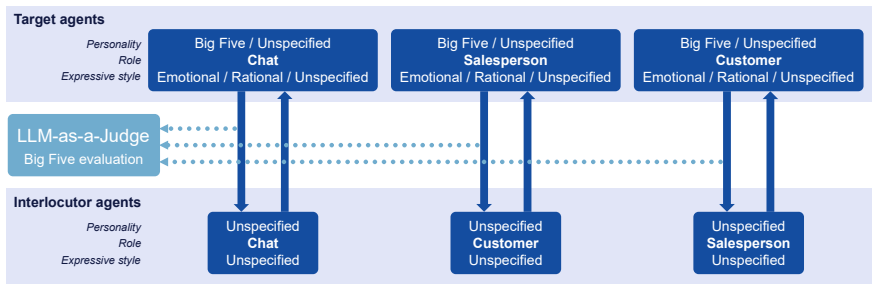
Factorial design that crosses six personality conditions, three dialogue roles, and three expressive-style conditions to generate and judge 1,080 dialogues per language, then scores expressed Big Five traits via LLM-as-a-judge on the target agent's utterances.
If this is right
- Personality control in LLM agents must treat trait prompting as one input among role and style rather than a direct switch.
- Without explicit trait prompts, role and style choices can still create consistent personality impressions across interactions.
- Control strategies should differ by target trait: role adjustments for Openness, style adjustments for Conscientiousness and Agreeableness.
- Cross-language consistency implies the same three-factor model can guide agent design in multiple languages.
Where Pith is reading between the lines
- Agent builders could combine role and style prompts to achieve trait expression even when direct trait specification is restricted.
- The same interactionist logic may apply to other measurable attributes such as emotional tone or decision style in generated text.
- Testing whether the patterns persist when the judge model differs from the generator model would clarify robustness.
Load-bearing premise
An LLM judge can accurately estimate the Big Five traits actually expressed in the generated utterances.
What would settle it
Human raters scoring the same dialogues produce trait estimates that do not match the LLM judge's scores or that erase the reported trait-specific effects of role and style.
Figures


read the original abstract
Prompt-based personality control is a key technique for designing large language model (LLM) dialogue agents that behave consistently across social contexts. However, specifying Big Five personality traits (BFTs) in a prompt does not ensure that the intended traits are expressed in generated utterances. This paper investigates this mismatch from an interactionist perspective, viewing personality expression as a context-dependent outcome shaped by the interplay between trait specification and situational factors. We analyze how perceived BFT expression in LLM-generated dialogue is influenced by three prompt factors: personality traits, dialogue roles, and expressive styles. Using a factorial design that combines six personality conditions, three roles, and three expressive-style conditions, we generate 1,080 LLM-agent dialogues in each of English and Japanese. We then evaluate the target agent's utterances using an LLM-as-a-judge framework to estimate expressed Big Five traits. The results show that expressed personality is shaped not only by explicit trait specification, but also by dialogue role and expressive style. These effects are trait-specific: dialogue role strongly influences Openness, expressive style substantially shapes Conscientiousness and Agreeableness, and explicit trait specification dominates Neuroticism. Even without explicit personality-trait specification, social and expressive conditions induce distinct personality-like impressions. Cross-linguistic comparisons show broadly similar patterns between English and Japanese dialogues, with noticeable differences only under specific combinations of personality, role, and expressive style. These findings suggest that personality control in LLM agents should be understood not as a direct consequence of trait prompting, but as a context-dependent process involving personality specification, social role, and expressive style.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that expressed Big Five personality traits in LLM-generated dialogues are shaped by the interaction of explicit trait specifications, dialogue roles, and expressive styles in a trait-specific manner (role strongly affects Openness; style affects Conscientiousness and Agreeableness; trait specification dominates Neuroticism). This is supported by a 3×3×6 factorial experiment generating 1,080 dialogues each in English and Japanese, scored via an LLM-as-a-judge framework, with broadly similar patterns across languages.
Significance. If the trait measurements are valid, the results demonstrate that personality prompting in LLMs is not a direct mapping but a context-dependent process, with implications for designing consistent dialogue agents. The factorial design and cross-linguistic comparison are strengths, but the absence of measurement validation limits the strength of the conclusions.
major comments (3)
- [Evaluation subsection (methods)] Evaluation subsection (methods): The central claims rest on LLM-as-a-judge trait scores, yet no validation against human Big-Five ratings, inter-judge agreement, or reliability metrics (e.g., Cronbach’s α) is reported. Without this, it is impossible to rule out that the reported trait-specific interactions are artifacts of the judge model’s own prompt sensitivities.
- [Results section] Results section: The abstract and high-level claims describe trait-specific effects but supply no statistical tests, p-values, confidence intervals, or effect sizes for the interactions; this makes it impossible to assess whether the observed differences (e.g., role on Openness) exceed noise.
- [Methods] Methods (prompt details): Exact wording of the personality, role, style, and judge prompts is not provided, nor is it stated whether the judge sees the original conditioning prompts; this prevents replication and raises the possibility that judge outputs simply echo the manipulated factors.
minor comments (2)
- The paper should include the exact number of utterances per dialogue and how they were aggregated for scoring.
- Cross-linguistic differences are described qualitatively; quantitative comparison (e.g., correlation of effect sizes between languages) would strengthen the claim of broad similarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Evaluation subsection (methods)] The central claims rest on LLM-as-a-judge trait scores, yet no validation against human Big-Five ratings, inter-judge agreement, or reliability metrics (e.g., Cronbach’s α) is reported. Without this, it is impossible to rule out that the reported trait-specific interactions are artifacts of the judge model’s own prompt sensitivities.
Authors: We acknowledge this as a genuine limitation of the current manuscript. The LLM-as-a-judge approach follows common practice but lacks the requested validation. In the revised version we will add a dedicated paragraph in the Evaluation subsection discussing known limitations of LLM judges for personality assessment and report any internal consistency checks performed across judge runs. Full human validation against Big-Five ratings would require new annotation studies that are outside the scope of the present revision. revision: partial
-
Referee: [Results section] The abstract and high-level claims describe trait-specific effects but supply no statistical tests, p-values, confidence intervals, or effect sizes for the interactions; this makes it impossible to assess whether the observed differences (e.g., role on Openness) exceed noise.
Authors: The referee correctly identifies the absence of inferential statistics. The original manuscript emphasized descriptive patterns across the factorial design. We will revise the Results section to include appropriate statistical tests (e.g., three-way ANOVA with interaction terms), reporting p-values, confidence intervals, and effect sizes for the key trait-specific effects. revision: yes
-
Referee: [Methods] Exact wording of the personality, role, style, and judge prompts is not provided, nor is it stated whether the judge sees the original conditioning prompts; this prevents replication and raises the possibility that judge outputs simply echo the manipulated factors.
Authors: We agree that prompt transparency is essential. The revised manuscript will include all prompt templates (personality, role, style, and judge) in a new appendix. We will also explicitly state that the judge prompt receives only the generated dialogue utterances and the evaluation instructions, without the original conditioning prompts. revision: yes
Circularity Check
No circularity: purely empirical factorial study with no derivations or self-referential reductions
full rationale
The paper describes a factorial experiment generating 1,080 dialogues per language under controlled prompt conditions (personality traits, roles, expressive styles) and then scoring the outputs via an LLM judge. No equations, fitted parameters, uniqueness theorems, or derivation chains are present in the abstract or described methods. The reported trait-specific effects are direct empirical observations from the generated data, not quantities that reduce to prior inputs by construction. Self-citation is not invoked as load-bearing evidence for any central claim. The analysis is self-contained against external benchmarks in the sense that it reports observed patterns without claiming mathematical necessity or re-deriving inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-as-a-judge framework accurately measures expressed Big Five traits
Reference graph
Works this paper leans on
-
[1]
From biased chatbots to biased agents: Examining role assignment effects on llm agent robustness.arXiv:2602.12285. Jiangjie Chen, Xintao Wang, Rui Xu, Siyu Yuan, Yikai Zhang, Wei Shi, Jian Xie, Shuang Li, Ruihan Yang, Tinghui Zhu, and 1 others
-
[2]
arXiv preprint arXiv:2404.18231 , year=
From persona to personalization: A survey on role-playing language agents.arXiv preprint arXiv:2404.18231. Susan T Fiske, Amy JC Cuddy, Peter Glick, and Jun Xu
- [3]
-
[4]
InFindings of the Association for Computational Linguistics: NAACL 2024, pages 3605–3627, Mexico City, Mexico
PersonaLLM: Investigating the ability of large language models to express personality traits. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 3605–3627, Mexico City, Mexico. Association for Computational Linguistics. Oliver P. John, Eileen M. Donahue, and Robert L. Kentle
2024
-
[5]
Better zero-shot reasoning with role-play prompting. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), page 4099–4113. Cheng Li, Jindong Wang, Yixuan Zhang, Kaijie Zhu, Wenxin Hou, Jianxun Lian, Fang Luo, Qiang Yang, and Xing Xie
2024
-
[6]
arXiv preprint arXiv:2307.11760
Large language models understand and can be enhanced by emotional stimuli. arXiv preprint arXiv:2307.11760. Jane Loevinger and 1 others. 2014.Measuring Ego Development. Psychology Press. Yang Lu, Jordan Yu, and Shou-Hsuan Stephen Huang
-
[7]
Illuminating the black box: A psychometric investigation into the multifaceted nature of large language models.Preprint, arXiv:2312.14202. Fran¸ cois Mairesse and Marilyn Walker
-
[8]
Personality and Assessment at Age 40: Reflections on the Past Person–Situation Debate and Emerging Directions of Future Person-Situation Integration
From personality and assessment (1968) to personality science, 2009.Journal of Research in Personality, 43(2):282–290. Personality and Assessment at Age 40: Reflections on the Past Person–Situation Debate and Emerging Directions of Future Person-Situation Integration. Walter Mischel. 2013.Personality and assessment. Psychology Press. Isabel Briggs Myers a...
1968
-
[9]
In Japanese
Exploring social cognition-based dialogue systems with large language models.JSAI SIG-SLUD. In Japanese. James W. Pennebaker, Martha E. Francis, and Roger J. Booth. 2001.Linguistic Inquiry and Word Count (LIWC): LIWC2001. Lawrence Erlbaum Associates, Mahwah, NJ. Angela Ramirez, Mamon Alsalihy, Kartik Aggarwal, Cecilia Li, Liren Wu, and Marilyn Walker
2001
-
[10]
20 Emily Reif, Daphne Ippolito, Ann Yuan, Andy Coenen, Chris Callison-Burch, and Jason Wei
Controlling personality style in dialogue with zero-shot prompt-based learning.arXiv preprint arXiv:2302.03848. 20 Emily Reif, Daphne Ippolito, Ann Yuan, Andy Coenen, Chris Callison-Burch, and Jason Wei
-
[11]
Bringing comparative cognition to computers.arXiv preprint arXiv:2503.02882. Dustin Wood and Brent W. Roberts
-
[12]
HumanLM: Simulating users with state alignment beats response imitation.arXiv preprint arXiv:2603.03303. Xiuwen Wu, Hao Wang, Zhiang Yan, Xiaohan Tang, Pengfei Xu, Wai-Ting Siok, Ping Li, Jia-Hong Gao, Bingjiang Lyu, and Lang Qin
-
[13]
arXiv preprint arXiv:2506.13978
AI shares emotion with humans across languages and cultures. arXiv preprint arXiv:2506.13978. Ivan Zakazov, Mikolaj Boronski, Lorenzo Drudi, and Robert West
-
[14]
Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston
Assessing social alignment: Do personality-prompted large language models behave like humans? InNeurIPS 2024 Workshop on Behavioral Machine Learning. Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.