Knowledge Dependency Estimation for Reliable Question Answering
Pith reviewed 2026-06-29 12:41 UTC · model grok-4.3
The pith
Knot estimates how sensitive a black-box QA model is to each knowledge unit by learning from subset counterfactuals and latent factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
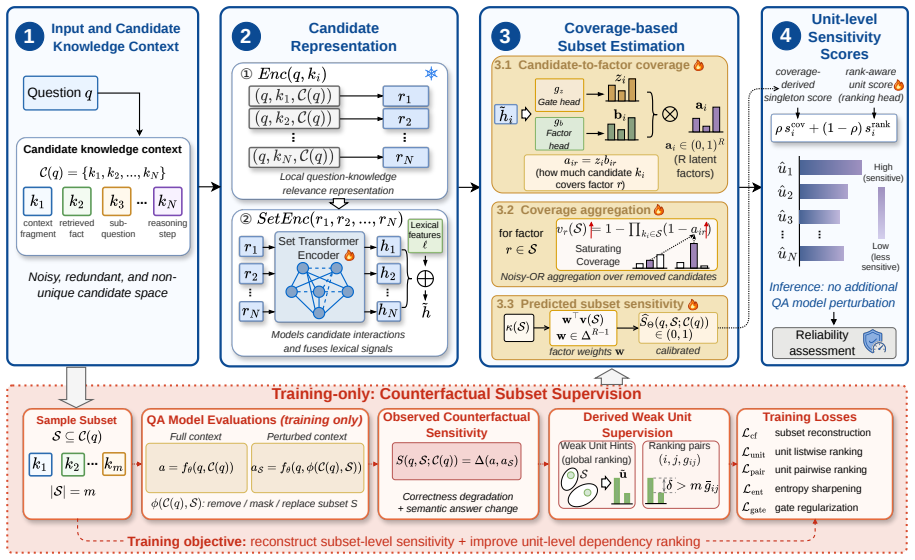
Knot learns from subset-level counterfactual supervision, models subset sensitivity through coverage over latent dependency factors, and derives rank-aware unit scores to identify influential candidates, outperforming baselines in subset-sensitivity prediction and producing more faithful rankings without extra QA-model calls.
What carries the argument
Knot, the structured rank-aware knowledge dependency estimator, which trains on subset counterfactuals and computes unit influence via coverage over latent dependency factors.
If this is right
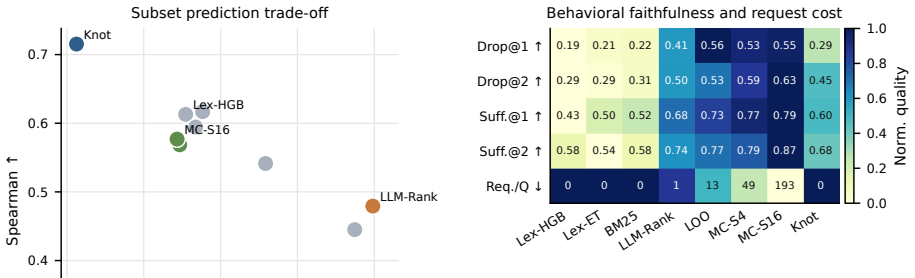
- Knot produces higher-accuracy subset-sensitivity predictions than compared baselines on multiple-choice and generative QA tasks.
- Its unit rankings are more faithful to true influence than those from deployable baselines that avoid extra QA calls.
- The resulting dependency scores can be used at inference time to screen and flag error-prone QA predictions before deployment.
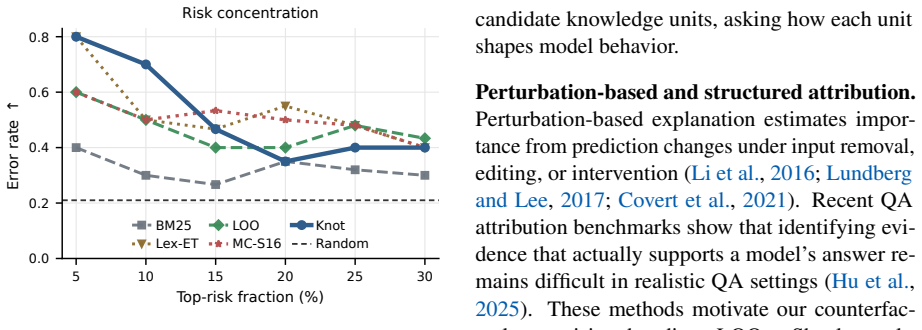
- The estimator captures redundancy and complementarity among knowledge units through its latent factor coverage mechanism.
Where Pith is reading between the lines
- The same subset-counterfactual training pattern could be adapted to estimate dependencies in other black-box generation tasks such as summarization or code completion.
- If latent factors prove stable across domains, Knot-style estimators might serve as lightweight add-ons for any retrieval-augmented pipeline without retraining the underlying model.
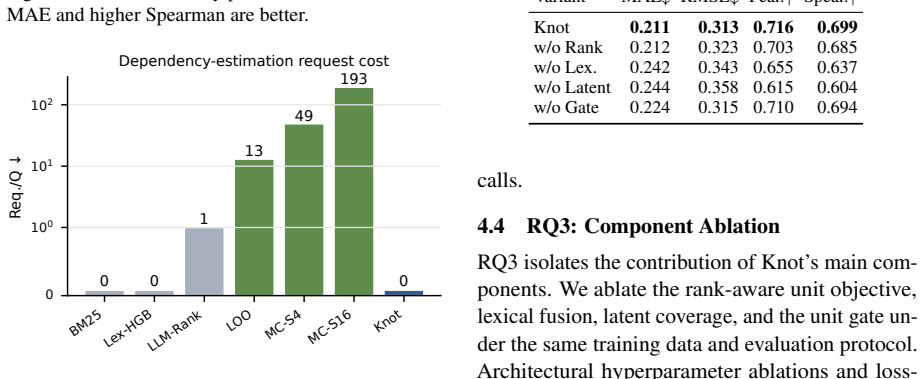
- Scaling the approach to very large candidate sets would require testing whether the latent-factor coverage remains computationally tractable.
Load-bearing premise
Subset-level counterfactual supervision can be generated at training time in a form that teaches accurate sensitivity without requiring exhaustive perturbation of every candidate combination.
What would settle it
Measure actual QA output changes under exhaustive single-unit and subset perturbations on a held-out benchmark and check whether Knot's predicted dependency scores correlate with those measured changes.
Figures
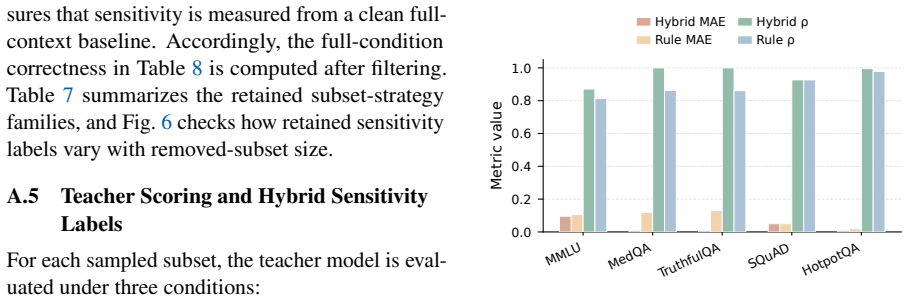
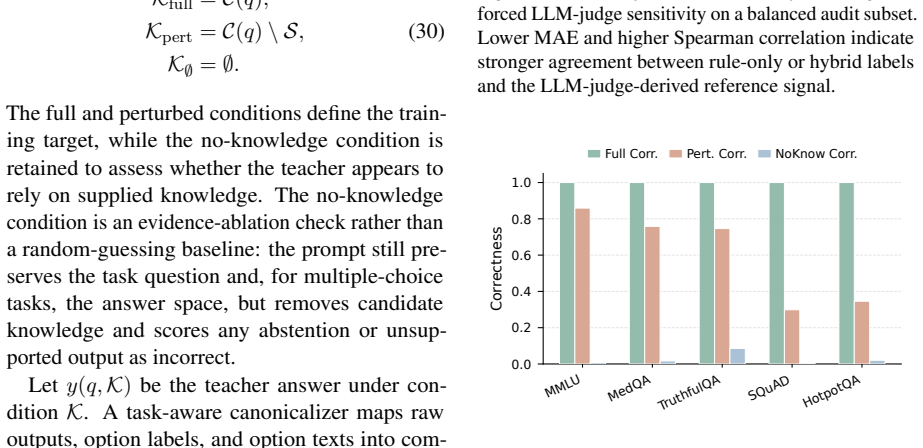
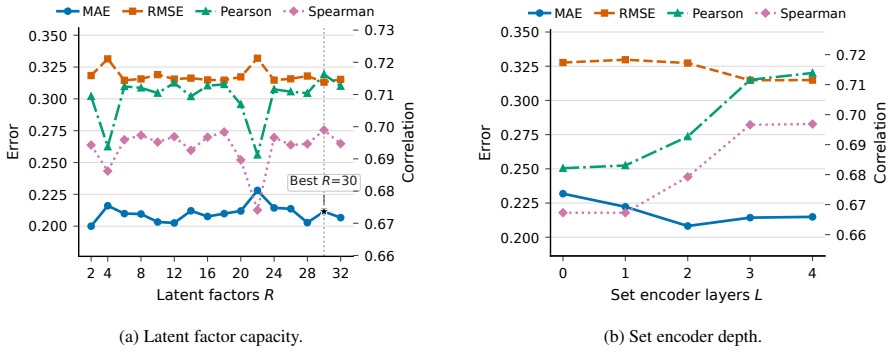
read the original abstract
Reliable question answering requires identifying not only whether an answer is correct, but also which available knowledge the prediction depends on. In realistic LLM-based QA, this knowledge may come from context, retrieval, decomposition, or intermediate reasoning, forming a noisy and redundant candidate space rather than a clean gold evidence set. We study \emph{knowledge dependency estimation}: estimating the sensitivity of a fixed black-box QA model to different candidate knowledge units. The challenge is to obtain fine-grained dependency scores without exhaustive test-time perturbation while modeling redundancy, substitutability, and complementarity. We propose \textbf{Knot}, a structured rank-aware knowledge dependency estimator. Knot learns from subset-level counterfactual supervision, models subset sensitivity through coverage over latent dependency factors, and derives rank-aware unit scores to identify influential candidates. Across multiple-choice and generative QA benchmarks, Knot outperforms all compared baselines in subset-sensitivity prediction and produces more faithful unit rankings than deployable baselines without extra QA-model calls; when used for practical risk screening, its dependency scores help flag error-prone QA predictions early.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Knot, a structured rank-aware knowledge dependency estimator for reliable QA. It learns subset sensitivity from counterfactual supervision, models interactions (redundancy, substitutability, complementarity) via coverage over latent dependency factors, and derives unit rankings to identify influential knowledge without extra QA-model calls at inference. The abstract claims outperformance over baselines on multiple-choice and generative QA benchmarks for subset-sensitivity prediction and faithful rankings, plus utility for early flagging of error-prone predictions.
Significance. If the empirical claims hold and the supervision procedure is efficient, Knot could offer a deployable method for dependency estimation that improves reliability screening in LLM-based QA systems. The latent-factor approach to capturing knowledge interactions without exhaustive perturbation is a potentially useful modeling contribution.
major comments (2)
- [Method] Method section: the description of subset-level counterfactual supervision does not specify a sub-exponential generation procedure. If labeling requires enumerating or heavily sampling subsets with repeated black-box QA evaluations, the claimed separation from perturbation-based baselines disappears at training time, undermining the practical advantage stated in the abstract.
- [Experiments] Experiments section: no quantitative results, baseline details, or experimental setup (e.g., number of units, subset sampling strategy, or exact metrics) are supplied in the abstract or summary description, preventing assessment of whether the reported outperformance on sensitivity prediction and rankings is robust or an artifact of supervision construction.
minor comments (2)
- [Abstract] Abstract: include at least one key quantitative result (e.g., improvement in subset-sensitivity AUC or ranking correlation) to support the outperformance claim.
- [Method] Notation: clarify how latent dependency factors are defined and how coverage is computed to derive unit scores.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Method] Method section: the description of subset-level counterfactual supervision does not specify a sub-exponential generation procedure. If labeling requires enumerating or heavily sampling subsets with repeated black-box QA evaluations, the claimed separation from perturbation-based baselines disappears at training time, undermining the practical advantage stated in the abstract.
Authors: We agree that the method section requires an explicit description of the subset generation procedure to clarify efficiency. Knot uses a latent-factor-guided sampling approach that selects subsets based on coverage of dependency factors rather than exhaustive enumeration, resulting in a number of black-box QA calls that scales linearly with the number of units (with a small constant factor from repeated sampling per factor). We will revise the manuscript to include the precise sampling algorithm, the bound on evaluations, and empirical training costs. This preserves the inference-time advantage while making the training procedure transparent. revision: yes
-
Referee: [Experiments] Experiments section: no quantitative results, baseline details, or experimental setup (e.g., number of units, subset sampling strategy, or exact metrics) are supplied in the abstract or summary description, preventing assessment of whether the reported outperformance on sensitivity prediction and rankings is robust or an artifact of supervision construction.
Authors: The full manuscript's Experiments section contains the quantitative results on subset-sensitivity prediction and unit ranking fidelity, along with baseline implementations, the number of knowledge units per instance, the subset sampling strategy, and the exact metrics used. The abstract provides only a high-level summary due to length constraints. To improve clarity, we will add a concise experimental setup paragraph early in the paper and ensure all details are cross-referenced from the abstract claims. revision: partial
Circularity Check
No significant circularity; derivation relies on external supervision
full rationale
The abstract frames Knot as learning dependency scores from subset-level counterfactual supervision generated externally, then using latent factors to model sensitivity and derive rankings. No equations or steps are shown that reduce predictions to fitted inputs by construction, nor any self-citation chains or ansatzes that import the result. The method is presented as trained on independent labels, with inference avoiding extra QA calls. This matches the default case of a self-contained learning pipeline without load-bearing circular reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In Proceedings of the 22nd international conference on Machine learning, pages 89–96
Learning to rank using gradient descent. In Proceedings of the 22nd international conference on Machine learning, pages 89–96. Zhe Cao, Tao Qin, Tie-Yan Liu, Ming-Feng Tsai, and Hang Li. 2007. Learning to rank: from pairwise approach to listwise approach. InProceedings of the 24th international conference on Machine learning, pages 129–136. Ian Covert, Sc...
2007
-
[2]
A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Language Models (Mostly) Know What They Know
Measuring massive multitask language under- standing. InInternational Conference on Learning Representations. Arthur E Hoerl and Robert W Kennard. 1970. Ridge re- gression: Biased estimation for nonorthogonal prob- lems.Technometrics, 12(1):55–67. Nan Hu, Jiaoyan Chen, Yike Wu, Guilin Qi, Hongru Wang, Sheng Bi, Yongrui Chen, Tongtong Wu, and Jeff Z Pan. 2...
work page internal anchor Pith review Pith/arXiv arXiv 1970
-
[4]
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Learning the difference that makes a differ- ence with counterfactually-augmented data. InIn- ternational Conference on Learning Representations (ICLR). Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. 2024. Seman- tic entropy probes: Robust and cheap hallucination detection in llms.arXiv preprint arXiv:2406.15927. L...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Understanding Neural Networks through Representation Erasure
PMLR. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, and 1 others. 2020. Retrieval-augmented gen- eration for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459– 9474. Jiwei Li, Will Monroe, and Dan Jurafsky...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
Chaodong Tong, Qi Zhang, Lei Jiang, Yanbing Liu, Nan- nan Sun, and Wei Li
Princeton University Press, Princeton. Chaodong Tong, Qi Zhang, Lei Jiang, Yanbing Liu, Nan- nan Sun, and Wei Li. 2026. Semantic reformulation entropy for robust hallucination detection in qa tasks. 10 InICASSP 2026-2026 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 3381–3385. IEEE. Michael Tsang, Dehua Cheng, ...
-
[7]
Other work investigates con- fidence calibration and uncertainty-aware model behavior (Kadavath et al., 2022; Lin et al., 2022a)
estimates hallucination via sampling consis- 19 tency, while semantic entropy and related methods cluster semantically equivalent generations to es- timate uncertainty at the meaning level (Farquhar et al., 2024; Kossen et al., 2024; Kuhn et al., 2023; Tong et al., 2026). Other work investigates con- fidence calibration and uncertainty-aware model behavio...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.