Beyond Surrogate Gradients: Fully Differentiable Token Pruning for Vision-Language Models
Pith reviewed 2026-06-29 13:04 UTC · model grok-4.3
The pith
DiffPrune replaces Gumbel-Softmax token selection in vision-language models with continuous noise modulation that learns importance scores through direct gradients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
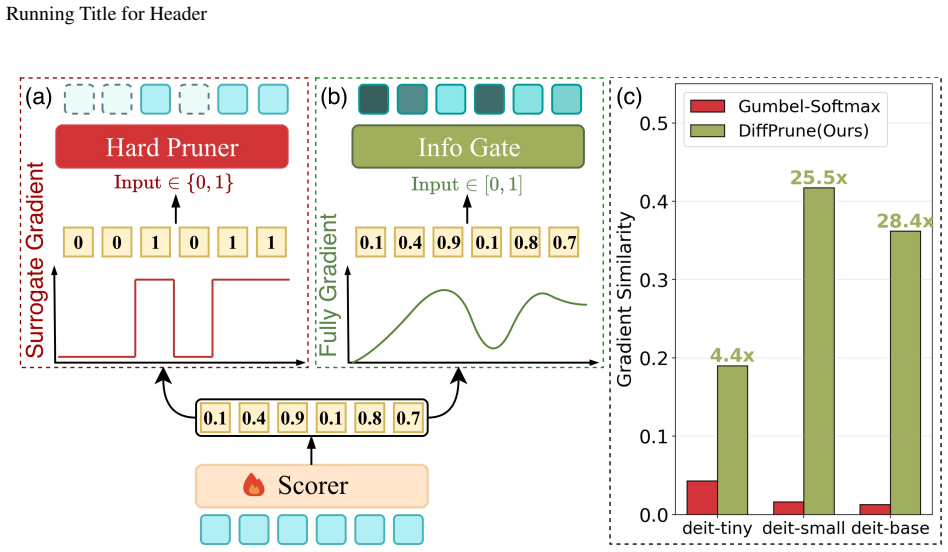
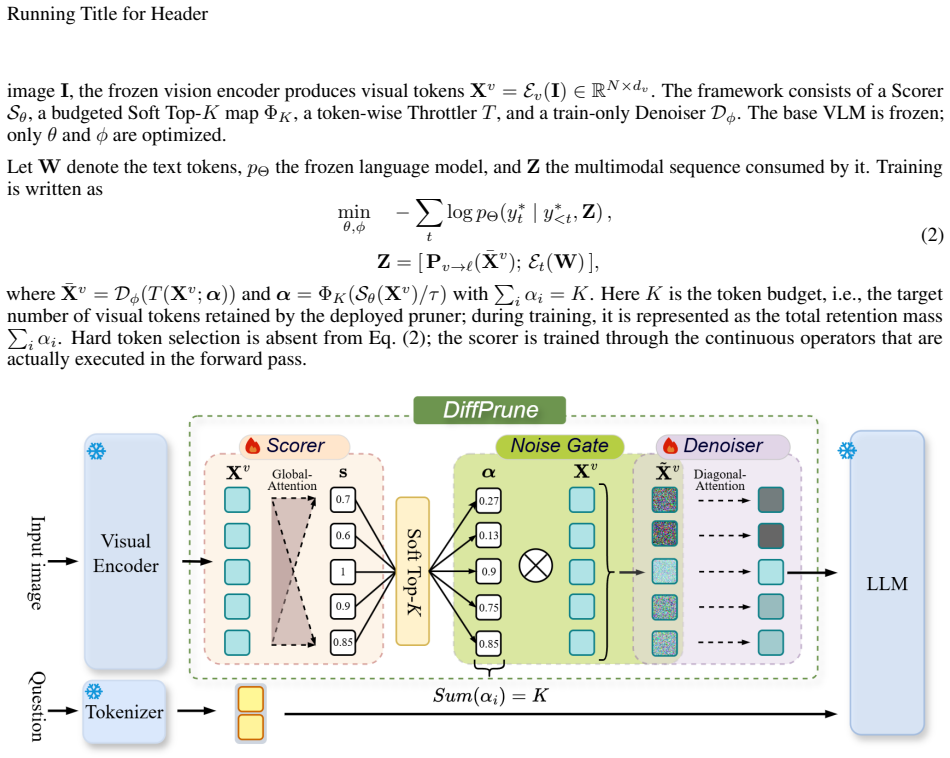
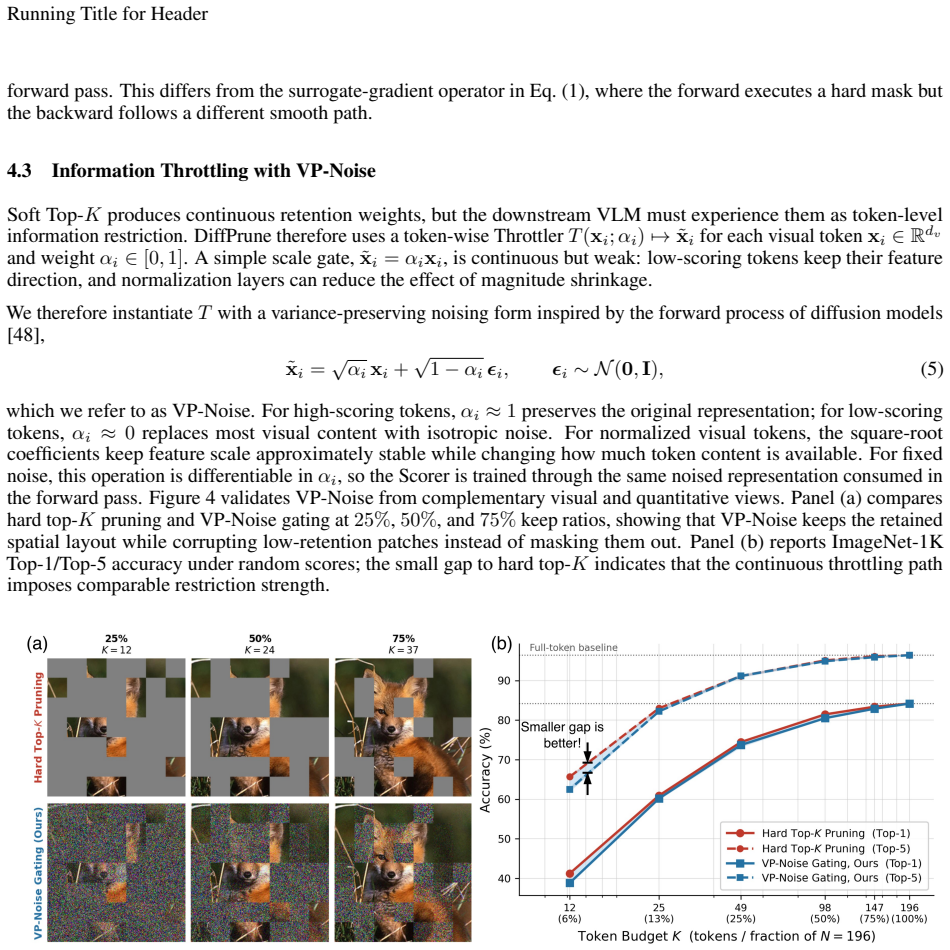
DiffPrune reformulates pruning as continuous control of token information instead of discrete selection learning. Specifically, it introduces an Information Throttler that modulates each token using variance-preserving noise conditioned on importance scores, where higher scores induce less information suppression during training. This design directly operates on token representations, naturally providing a fully differentiable optimization path for learning token importance. At inference, tokens are removed via hard thresholding on the learned scores.
What carries the argument
The Information Throttler, which adds variance-preserving noise to token representations with strength inversely related to a learned importance score, so that gradients flow straight through the modulated tokens to update the importance predictor.
If this is right
- Retains 96.5 percent of full-model accuracy across ten VLM benchmarks
- Accelerates LLM prefill stage by 2.85 times
- Adds only 0.69 milliseconds of overhead at inference
- Avoids the mismatch between surrogate gradients and the final discrete selection step
Where Pith is reading between the lines
- The same noise-modulation idea could be applied to other discrete decisions inside networks, such as routing or attention-head selection, where current methods also rely on surrogate gradients.
- Because the training and inference mechanisms are aligned, the learned scores may transfer more reliably across different downstream tasks than scores trained with surrogate objectives.
- The approach opens a route to pruning methods that optimize an explicit information-preservation objective rather than an indirect selection proxy.
Load-bearing premise
The assumption that modulating each token with variance-preserving noise whose strength is conditioned on a learned importance score will produce scores that, when used for hard thresholding at inference, preserve task-critical information without introducing optimization biases.
What would settle it
An experiment in which tokens ranked highest by the learned scores are removed and model accuracy falls by more than the drop seen with Gumbel-Softmax pruning on the same benchmarks, or in which the importance scores show no correlation with token ablation impact.
Figures
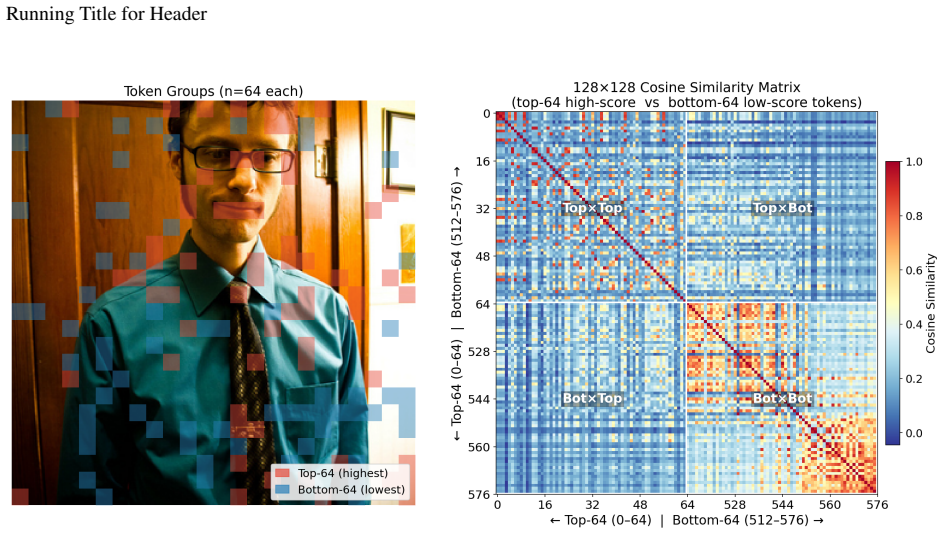
read the original abstract
Visual token pruning reduces the computational cost of Vision-Language Models (VLMs) by removing redundant visual tokens. Existing methods typically rely on Gumbel-Softmax to approximate discrete selection during training. However, the optimization is driven by surrogate gradients rather than the true selection process, leading to unreliable learning of token importance. In this paper, we propose DiffPrune, which reformulates pruning as continuous control of token information instead of discrete selection learning. Specifically, we introduce an Information Throttler that modulates each token using variance-preserving noise conditioned on importance scores, where higher scores induce less information suppression during training. This design directly operates on token representations, naturally providing a fully differentiable optimization path for learning token importance. At inference, tokens are removed via hard thresholding on the learned scores. Across ten VLM benchmarks, DiffPrune retains 96.5% of full-model accuracy while accelerating LLM prefill by 2.85x, with only 0.69 ms of inference overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DiffPrune, a token-pruning method for vision-language models that replaces Gumbel-Softmax surrogate gradients with an Information Throttler. The throttler modulates each token representation by variance-preserving noise whose strength is conditioned on a learned importance score (higher score yields less suppression). Training is fully differentiable through this continuous modulation; at inference the same scores drive hard thresholding to remove tokens. The abstract reports that the method retains 96.5% of full-model accuracy on ten VLM benchmarks while accelerating LLM prefill by 2.85× with 0.69 ms overhead.
Significance. If the training objective under noise modulation reliably identifies tokens whose complete removal preserves task performance, the approach would supply a direct, non-surrogate path for learning token importance and could improve pruning reliability in VLMs. The reported speed/accuracy numbers, if substantiated with proper controls, would be practically relevant for deployment.
major comments (1)
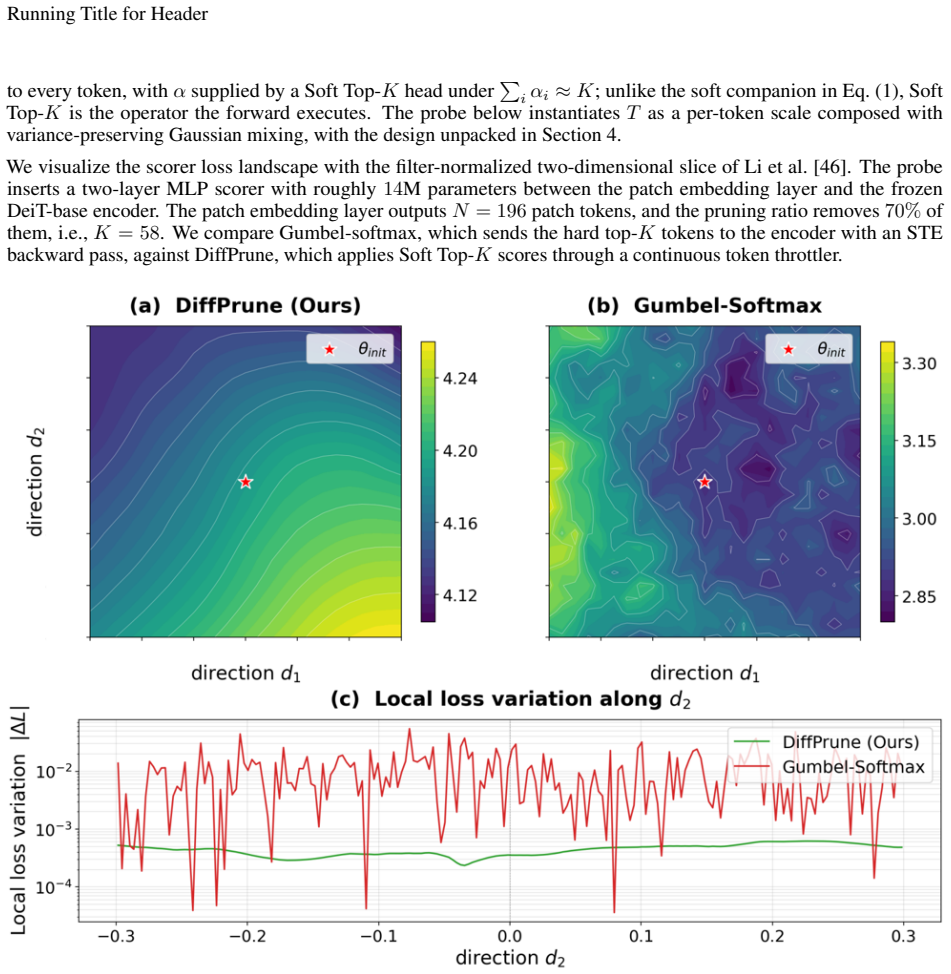
- [Abstract] Abstract (paragraph on Information Throttler): the central claim that the method supplies a 'fully differentiable optimization path' whose learned scores survive hard thresholding rests on an unverified alignment between the training distribution (every token present but noise-modulated) and the inference distribution (tokens absent). No argument or experiment is supplied showing that scores optimized for noise robustness also optimize for discrete removal; this mismatch is load-bearing for the assertion that DiffPrune is 'beyond surrogate gradients' in a substantive sense.
minor comments (1)
- [Abstract] Abstract: performance numbers are stated without reference to baselines, number of runs, error bars, or the precise pruning ratio used; these details are required to evaluate the 96.5% retention claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comment on the training-inference distribution alignment. We address the concern directly below and commit to revisions that strengthen the manuscript's claims.
read point-by-point responses
-
Referee: the central claim that the method supplies a 'fully differentiable optimization path' whose learned scores survive hard thresholding rests on an unverified alignment between the training distribution (every token present but noise-modulated) and the inference distribution (tokens absent). No argument or experiment is supplied showing that scores optimized for noise robustness also optimize for discrete removal; this mismatch is load-bearing for the assertion that DiffPrune is 'beyond surrogate gradients' in a substantive sense.
Authors: The Information Throttler is constructed so that variance-preserving noise with score-conditioned strength directly approximates the information loss of hard removal: low-importance tokens receive high-variance noise that renders their representations uninformative while preserving the overall feature statistics, allowing gradients to flow through the continuous modulation. This design choice ensures the optimization objective penalizes reliance on tokens that would be removed at inference. The empirical results (96.5% retained accuracy after hard thresholding) provide indirect support, but we agree that an explicit verification is warranted. In the revision we will add (i) a theoretical paragraph clarifying how the noise schedule emulates discrete removal and (ii) an ablation that reports the correlation between learned scores and per-token performance drop under hard removal versus under the training noise levels, confirming alignment. revision: yes
Circularity Check
No circularity: independent reformulation of pruning objective
full rationale
The paper presents DiffPrune as a direct reformulation that replaces discrete selection (and its surrogate gradients) with continuous variance-preserving noise modulation on token representations, conditioned on learned importance scores. This construction operates on the representations themselves and supplies gradients without invoking any fitted parameter that is then renamed as a prediction, any self-citation load-bearing uniqueness theorem, or any ansatz smuggled from prior author work. The inference step (hard thresholding) is stated as a separate post-training choice rather than being derived from or equivalent to the training objective by construction. No equations or claims in the provided text reduce the central result to its own inputs; the derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- pruning threshold
axioms (1)
- domain assumption Variance-preserving noise can be conditioned on importance scores to modulate token information content differentiably
invented entities (1)
-
Information Throttler
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Learnable Token Sparsification for Efficient Gigapixel Whole Slide Image Reasoning
Learnable sparsification framework compresses WSI visual tokens to 32 (0.78% of original) via SparseLearn, achieving 73.32% accuracy on SlideBench (TCGA) and outperforming baselines.
Reference graph
Works this paper leans on
-
[1]
Vita: An efficient video- to-text algorithm using vlm for rag-based video analysis system
Md Adnan Arefeen, Biplob Debnath, Md Yusuf Sarwar Uddin, and Srimat Chakradhar. Vita: An efficient video- to-text algorithm using vlm for rag-based video analysis system. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2266–2274, 2024
2024
-
[2]
Fastvlm: Efficient vision encoding for vision language models
Pavan Kumar Anasosalu Vasu, Fartash Faghri, Chun-Liang Li, Cem Koc, Nate True, Albert Antony, Gokula Santhanam, James Gabriel, Peter Grasch, Oncel Tuzel, et al. Fastvlm: Efficient vision encoding for vision language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19769–19780, 2025
2025
-
[3]
Mmtok: Multimodal coverage maximization for efficient inference of vlms.ICLR, 2026
Sixun Dong, Juhua Hu, Mian Zhang, Ming Yin, Yanjie Fu, and Qi Qian. Mmtok: Multimodal coverage maximization for efficient inference of vlms.ICLR, 2026. 12 Running Title for Header
2026
-
[4]
See what matters: Differentiable grid sample pruning for generalizable vision-language-action model.ICML, 2026
Yixu Feng, Zinan Zhao, Yanxiang Ma, Chenghao Xia, Chengbin Du, Yunke Wang, and Chang Xu. See what matters: Differentiable grid sample pruning for generalizable vision-language-action model.ICML, 2026
2026
-
[5]
Similarity-aware token pruning: Your vlm but faster.arXiv preprint arXiv:2503.11549, 2025
Ahmadreza Jeddi, Negin Baghbanzadeh, Elham Dolatabadi, and Babak Taati. Similarity-aware token pruning: Your vlm but faster.arXiv preprint arXiv:2503.11549, 2025
-
[6]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. InInternational conference on machine learning, pages 10347–10357. PMLR, 2021
2021
-
[7]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. 2024
2024
-
[8]
Sparsevlm: Visual token sparsification for efficient vision-language model inference.ICML, 2025
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference.ICML, 2025
2025
-
[9]
Token merging: Your ViT but faster
Daniel Bolya, Cheng-Yang Fu, Xiaodong Dai, Peize Zhang, and Judy Hoffman. Token merging: Your ViT but faster. InICLR, 2023
2023
-
[10]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InCVPR, pages 19792–19802, 2025
2025
-
[11]
Divprune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. 2025
2025
-
[12]
Beyond attention or similarity: Maximizing conditional diversity for token pruning in mllms.Advances in Neural Information Processing Systems, 38:25438–25468, 2026
Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She, and Shanghang Zhang. Beyond attention or similarity: Maximizing conditional diversity for token pruning in mllms.Advances in Neural Information Processing Systems, 38:25438–25468, 2026
2026
-
[13]
Efficientvlm: Fast and accurate vision- language models via knowledge distillation and modal-adaptive pruning
Tiannan Wang, Wangchunshu Zhou, Yan Zeng, and Xinsong Zhang. Efficientvlm: Fast and accurate vision- language models via knowledge distillation and modal-adaptive pruning. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13899–13913, 2023
2023
-
[14]
Xijun Wang, Junyun Huang, Rayyan Abdalla, Chengyuan Zhang, Ruiqi Xian, and Dinesh Manocha. Bi-vlm: Pushing ultra-low precision post-training quantization boundaries in vision-language models.arXiv preprint arXiv:2509.18763, 2025
-
[15]
Learnpruner: Rethinking attention-based token pruning in vision language models.ICLR 2026, 2026
Rinyoichi Takezoe, Yaqian Li, Zihao Bo, Anzhou Hou, Mo Guang, and Kaiwen Long. Learnpruner: Rethinking attention-based token pruning in vision language models.ICLR 2026, 2026
2026
-
[16]
Yumiao Zhao, Bo Jiang, Yuhe Ding, Xiao Wang, Jin Tang, and Bin Luo. Fine-grained vlm fine-tuning via latent hierarchical adapter learning.arXiv preprint arXiv:2508.11176, 2025
-
[17]
Xiaoyu Liang, Chaofeng Guan, Jiaying Lu, Huiyao Chen, Huan Wang, and Haoji Hu. Dynamic token reduction during generation for vision language models.arXiv preprint arXiv:2501.14204, 2025
-
[18]
Improving the straight-through estimator with zeroth-order information.Advances in Neural Information Processing Systems, 38:167408–167440, 2026
Ningfeng Yang and Tor Aamodt. Improving the straight-through estimator with zeroth-order information.Advances in Neural Information Processing Systems, 38:167408–167440, 2026
2026
-
[19]
A survey of token compression for efficient multimodal large language models.Transactions on Machine Learning Research, 2025
Kele Shao, TAO Keda, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, and Huan Wang. A survey of token compression for efficient multimodal large language models.Transactions on Machine Learning Research, 2025
2025
-
[20]
Towards efficient multimodal large language models: A survey on token compression
Linli Yao, Long Xing, Yang Shi, Sida Li, Yuanxin Liu, Yuhao Dong, Yi-Fan Zhang, Lei Li, Qingxiu Dong, Xiaoyi Dong, et al. Towards efficient multimodal large language models: A survey on token compression. TechRxiv preprint, 2026
2026
-
[21]
[CLS] attention is all you need for training-free visual token pruning: Make VLM inference faster, 2024
Haoran Zhang et al. [CLS] attention is all you need for training-free visual token pruning: Make VLM inference faster, 2024. arXiv preprint
2024
-
[22]
Boosting multimodal large language models with visual tokens withdrawal for rapid inference
Zhihang Lin, Mingbao Lin, Luxi Lin, and Rongrong Ji. Boosting multimodal large language models with visual tokens withdrawal for rapid inference. InAAAI, volume 39, pages 5334–5342, 2025
2025
-
[23]
Hired: Attention-guided token dropping for efficient inference of high-resolution vision-language models
Kazi Hasan Ibn Arif, JinYi Yoon, Dimitrios S Nikolopoulos, Hans Vandierendonck, Deepu John, and Bo Ji. Hired: Attention-guided token dropping for efficient inference of high-resolution vision-language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 1773–1781, 2025
2025
-
[24]
Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction.CVPR, 2025
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction.CVPR, 2025. 13 Running Title for Header
2025
-
[25]
Topv: Compatible token pruning with inference time optimization for fast and low-memory multimodal vision language model
Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Chendi Li, Jinghua Yan, Yu Bai, Ponnuswamy Sadayappan, Xia Hu, and Bo Yuan. Topv: Compatible token pruning with inference time optimization for fast and low-memory multimodal vision language model. InCVPR, pages 19803–19813, 2025
2025
-
[26]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. 2024
2024
-
[27]
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. 2025
2025
-
[28]
Feather the throttle: Revisiting visual token pruning for vision-language model acceleration
Mark Endo, Xiaohan Wang, and Serena Yeung-Levy. Feather the throttle: Revisiting visual token pruning for vision-language model acceleration. 2024
2024
-
[29]
important tokens
Zichen Wen, Yifeng Gao, Shaobo Wang, Junyuan Zhang, Qintong Zhang, Weijia Li, Conghui He, and Linfeng Zhang. Stop looking for “important tokens” in multimodal language models: Duplication matters more. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9972–9991, 2025
2025
-
[30]
highlighted tokens
Xin Zou, Di Lu, Yizhou Wang, Yibo Yan, Yuanhuiyi Lyu, Xu Zheng, Linfeng Zhang, and Xuming Hu. Don’t just chase “highlighted tokens” in mllms: Revisiting visual holistic context retention.NeurIPS, 2025
2025
-
[31]
Balanced token pruning: Accelerating vision language models beyond local optimization
Kaiyuan Li, Xiaoyue Chen, Chen Gao, Yong Li, and Xinlei Chen. Balanced token pruning: Accelerating vision language models beyond local optimization. 2025
2025
-
[32]
Prune redundancy, preserve essence: Vision token compression in vlms via synergistic importance-diversity
Zhengyao Fang, Pengyuan Lyu, Chengquan Zhang, Guangming Lu, Jun Yu, and Wenjie Pei. Prune redundancy, preserve essence: Vision token compression in vlms via synergistic importance-diversity. InThe Fourteenth International Conference on Learning Representations, 2025
2025
-
[33]
Maskllm: Learnable semi-structured sparsity for large language models.Advances in Neural Information Processing Systems, 37:7736–7758, 2024
Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, and Xinchao Wang. Maskllm: Learnable semi-structured sparsity for large language models.Advances in Neural Information Processing Systems, 37:7736–7758, 2024
2024
-
[34]
LKV: End-to-End Learning of Head-wise Budgets and Token Selection for LLM KV Cache Eviction
Enshuai Zhou, Yifan Hao, Chao Wang, Rui Zhang, Di Huang, Jiaming Guo, Xing Hu, Zidong Du, Qi Guo, and Yunji Chen. Lkv: End-to-end learning of head-wise budgets and token selection for llm kv cache eviction.arXiv preprint arXiv:2605.06676, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Constraint-aware and ranking-distilled token pruning for efficient transformer inference
Junyan Li, Li Lyna Zhang, Jiahang Xu, Yujing Wang, Shaoguang Yan, Yunqing Xia, Yuqing Yang, Ting Cao, Hao Sun, Weiwei Deng, et al. Constraint-aware and ranking-distilled token pruning for efficient transformer inference. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1280–1290, 2023
2023
-
[36]
Vlm-pruner: Buffering for spatial sparsity in an efficient vlm centrifugal token pruning paradigm.CVPR 2026, 2025
Zhenkai Wu, Xiaowen Ma, Zhenliang Ni, Dengming Zhang, Han Shu, Xin Jiang, and Xinghao Chen. Vlm-pruner: Buffering for spatial sparsity in an efficient vlm centrifugal token pruning paradigm.CVPR 2026, 2025
2026
-
[37]
Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021
2021
-
[38]
ATP-LLaV A: Adaptive token pruning for large vision language models
Xubing Ye, Yukang Gan, Yixiao Ge, Xiao-Ping Zhang, and Yansong Tang. ATP-LLaV A: Adaptive token pruning for large vision language models. InCVPR, pages 24972–24982, 2025
2025
-
[39]
Dynamic-llava: Efficient multimodal large language models via dynamic vision-language context sparsification
Wenxuan Huang, Zijie Zhai, Yunhang Shen, Shaosheng Cao, Fei Zhao, Xiangfeng Xu, Zheyu Ye, and Shaohui Lin. Dynamic-llava: Efficient multimodal large language models via dynamic vision-language context sparsification. InInternational Conference on Learning Representations, volume 2025, pages 69927–69955, 2025
2025
-
[40]
arXiv preprint arXiv:2509.12594 , year =
Titong Jiang, Xuefeng Jiang, Yuan Ma, Xin Wen, Bailin Li, Kun Zhan, Peng Jia, Yahui Liu, Sheng Sun, and Xianpeng Lang. The better you learn, the smarter you prune: Towards efficient vision-language-action models via differentiable token pruning.arXiv preprint arXiv:2509.12594, 2025
-
[41]
Jiaji Zhang, Hailiang Zhao, Guoxuan Zhu, Ruichao Sun, Jiaju Wu, Xinkui Zhao, Hanlin Tang, Weiyi Lu, Kan Liu, Tao Lan, et al. Shiva-dit: Residual-based differentiable top-k selection for efficient diffusion transformers.arXiv preprint arXiv:2602.05605, 2026
-
[42]
Growing a multi-head twig via distillation and reinforcement learning to accelerate large vision-language models, 2025
Zhenwei Shao, Mingyang Wang, Weijun Zhang, Zhou Yu, Wenwen Pan, Yan Yang, Tao Wei, Hongyuan Zhang, and Jun Yu. Growing a multi-head twig via distillation and reinforcement learning to accelerate large vision-language models, 2025
2025
-
[43]
Path sample-analytic gradient estimators for stochastic binary networks.Advances in neural information processing systems, 33:12884–12894, 2020
Alexander Shekhovtsov, Viktor Yanush, and Boris Flach. Path sample-analytic gradient estimators for stochastic binary networks.Advances in neural information processing systems, 33:12884–12894, 2020
2020
-
[44]
Rushi Shah, Mingyuan Yan, Michael Curtis Mozer, and Dianbo Liu. Improving discrete optimisation via decoupled straight-through gumbel-softmax.arXiv preprint arXiv:2410.13331, 2024. 14 Running Title for Header
-
[45]
Bias-variance tradeoffs in single-sample binary gradient estimators
Alexander Shekhovtsov. Bias-variance tradeoffs in single-sample binary gradient estimators. InDAGM German Conference on Pattern Recognition, pages 127–141. Springer, 2021
2021
-
[46]
Visualizing the loss landscape of neural nets.Advances in neural information processing systems, 31, 2018
Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein. Visualizing the loss landscape of neural nets.Advances in neural information processing systems, 31, 2018
2018
-
[47]
Bednarczyk, Igor T
Łukasz Struski, Michal B. Bednarczyk, Igor T. Podolak, and Jacek Tabor. LapSum - one method to differentiate them all: Ranking, sorting and top-k selection. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine Learn...
2025
-
[48]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
2020
-
[49]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255, 2009
2009
-
[50]
Imagenet-1k-vl-enriched, 2023
Visual Layer. Imagenet-1k-vl-enriched, 2023. HuggingFace dataset
2023
-
[51]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[52]
p-mod: Building mixture-of-depths mllms via progressive ratio decay
Jun Zhang, Desen Meng, Zhengming Zhang, Zhenpeng Huang, Tao Wu, and Limin Wang. p-mod: Building mixture-of-depths mllms via progressive ratio decay. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3705–3715, 2025
2025
-
[53]
Quan-Sheng Zeng, Yunheng Li, Qilong Wang, Peng-Tao Jiang, Zuxuan Wu, Ming-Ming Cheng, and Qibin Hou. A glimpse to compress: Dynamic visual token pruning for large vision-language models.arXiv preprint arXiv:2508.01548, 2025
-
[54]
Gqa: A new dataset for real-world visual reasoning and com- positional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and com- positional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019
2019
-
[55]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
2024
-
[56]
Mme: A comprehensive evaluation benchmark for multimodal large language models.NeurIPS, 2025
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.NeurIPS, 2025
2025
-
[57]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023
2023
-
[58]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in neural information processing systems, 35:2507–2521, 2022
2022
-
[59]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017
2017
-
[60]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019
2019
-
[61]
Seed-bench: Benchmarking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-bench: Benchmarking multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13299–13308, 2024
2024
-
[62]
Vizwiz: nearly real-time answers to visual questions
Jeffrey P Bigham, Chandrika Jayant, Hanjie Ji, Greg Little, Andrew Miller, Robert C Miller, Robin Miller, Aubrey Tatarowicz, Brandyn White, Samual White, et al. Vizwiz: nearly real-time answers to visual questions. In Proceedings of the 23nd annual ACM symposium on User interface software and technology, pages 333–342, 2010
2010
-
[63]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2...
2025
-
[64]
One leaf reveals the season: Occlusion-based contrastive learning with semantic-aware views for efficient visual representation
Xiaoyu Yang, Lijian Xu, Hongsheng Li, and Shaoting Zhang. One leaf reveals the season: Occlusion-based contrastive learning with semantic-aware views for efficient visual representation. InInternational Conference on Machine Learning, pages 71425–71440, 2025
2025
-
[65]
Shawn Young, Xingyu Zeng, and Lijian Xu. Fewer tokens, greater scaling: Self-adaptive visual bases for efficient and expansive representation learning.arXiv preprint arXiv:2511.19515, 2025
-
[66]
Scalar: Spatial- concept alignment for robust vision in harsh open world.Pattern Recognition, page 113203, 2026
Xiaoyu Yang, Lijian Xu, Xingyu Zeng, Xiaosong Wang, Hongsheng Li, and Shaoting Zhang. Scalar: Spatial- concept alignment for robust vision in harsh open world.Pattern Recognition, page 113203, 2026
2026
-
[67]
Segmentation and vascular vectorization for coronary artery by geometry-based cascaded neural network.IEEE Transactions on Medical Imaging, 44(1):259–269, 2024
Xiaoyu Yang, Lijian Xu, Simon Yu, Qing Xia, Hongsheng Li, and Shaoting Zhang. Segmentation and vascular vectorization for coronary artery by geometry-based cascaded neural network.IEEE Transactions on Medical Imaging, 44(1):259–269, 2024
2024
-
[68]
Geometry-based end-to-end segmentation of coronary artery in computed tomography angiography
Xiaoyu Yang, Lijian Xu, Simon Yu, Qing Xia, Hongsheng Li, and Shaoting Zhang. Geometry-based end-to-end segmentation of coronary artery in computed tomography angiography. InInternational Workshop on Trustworthy Machine Learning for Healthcare, pages 190–196. Springer, 2023
2023
-
[69]
Zhuo Chen, Shawn Young, and Lijian Xu. Tc-ssa: Token compression via semantic slot aggregation for gigapixel pathology reasoning.arXiv preprint arXiv:2603.01143, 2026
-
[70]
Peihang Wu, Zehong Chen, and Lijian Xu. Multimodal model for computational pathology: Representation learning and image compression.arXiv preprint arXiv:2603.18660, 2026
-
[71]
Lijian Xu, Ziyu Ni, Xinglong Liu, Xiaosong Wang, Hongsheng Li, and Shaoting Zhang. Learning a multi-task transformer via unified and customized instruction tuning for chest radiograph interpretation.arXiv preprint arXiv:2311.01092, 2023
-
[72]
Lijian Xu, Hao Sun, Ziyu Ni, Hongsheng Li, and Shaoting Zhang. Medvilam: A multimodal large language model with advanced generalizability and explainability for medical data understanding and generation.arXiv preprint arXiv:2409.19684, 2024
-
[73]
Lijian Xu, Ziyu Ni, Hao Sun, Hongsheng Li, and Shaoting Zhang. A foundation model for generalizable disease diagnosis in chest x-ray images.arXiv preprint arXiv:2410.08861, 2024
-
[74]
Wangyu Feng, Shawn Young, and Lijian Xu. Efficient chest x-ray representation learning via semantic-partitioned contrastive learning.arXiv preprint arXiv:2603.07113, 2026
-
[75]
Zerosense: How vision matters in long context compression.arXiv preprint arXiv:2603.11846, 2026
Yonghan Gao, Zehong Chen, Lijian Xu, Jingzhi Chen, Jingwei Guan, and Xingyu Zeng. Zerosense: How vision matters in long context compression.arXiv preprint arXiv:2603.11846, 2026
-
[76]
Landi He, Xiaoyu Yang, and Lijian Xu. The model knows which tokens matter:automatic token selection via noise gating.arXiv preprint arXiv:2603.07135, 2026. 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.