Unified Synthesis of Compositional Speech and Sound from Free-Form Text Prompts
Pith reviewed 2026-06-29 10:26 UTC · model grok-4.3
The pith
PlanAudio generates unified audio with speech and sounds directly from free-form text prompts by using an LLM's reasoning and a semantic latent chain-of-thought.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
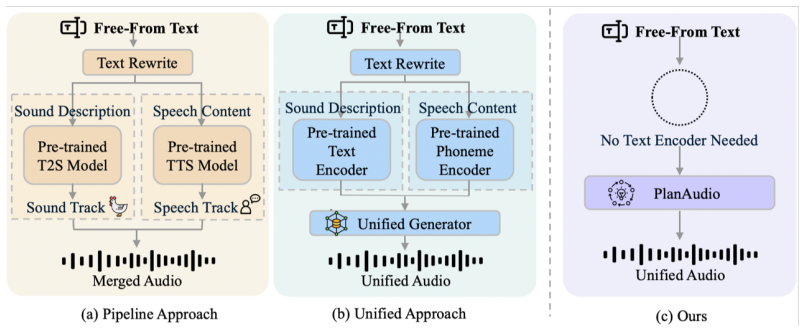
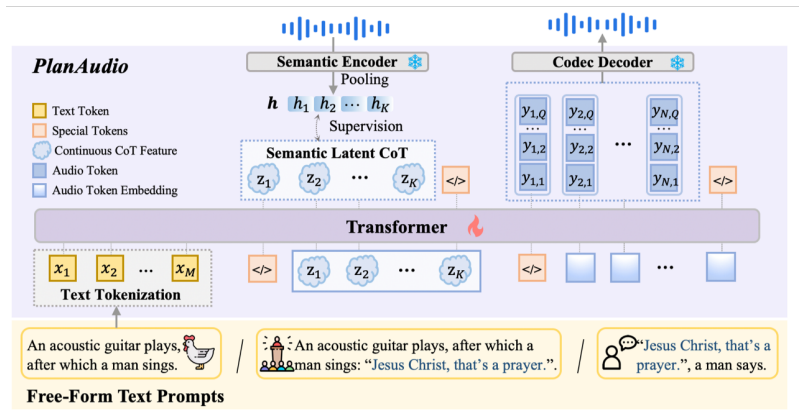
PlanAudio is a unified autoregressive LLM-based framework for the Free-Form-Text-Prompt-to-Unified-Audio task that simplifies architecture by relying on the LLM's intrinsic reasoning and introduces a semantic latent chain-of-thought mechanism to bridge high-level semantic understanding with low-level acoustic synthesis, enabling direct generation of composite audio from unconstrained natural language prompts.
What carries the argument
The semantic latent chain-of-thought mechanism, an implicit planning step inside the LLM that connects high-level semantics to low-level acoustic output without external text processing.
If this is right
- Composite audio can be produced in one forward pass without stitching outputs from separate speech and sound models.
- Fine-grained timing and interaction details between speech and sound emerge from the same latent planning step.
- No external text rewriting or conversion to structured formats is required for flexible prompt handling.
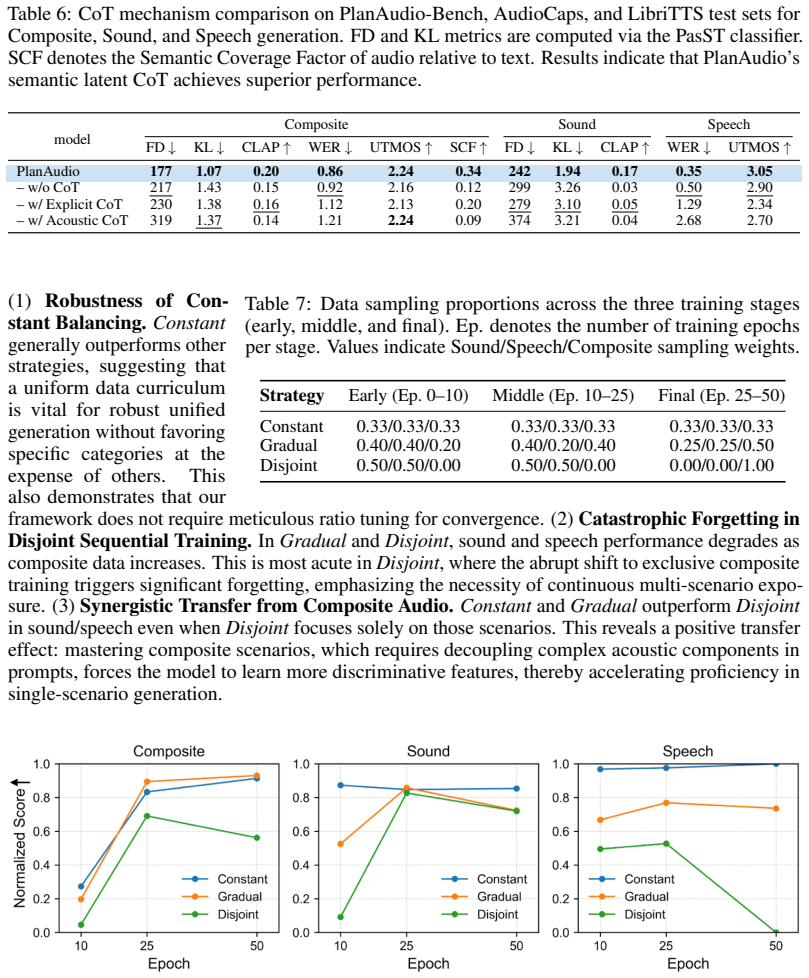
- Performance on mixed scenarios improves when the model trains continuously across speech, sound, and composite data rather than in isolation.
- Semantic latent chain-of-thought outperforms other chain-of-thought variants for this bridging task.
Where Pith is reading between the lines
- The same latent-planning approach could apply to generating synchronized video and audio from text.
- If the mechanism scales, it reduces the need for task-specific audio models in favor of general LLM-based generators.
- Real-world applications such as game sound design or film post-production could shift from manual layering to direct text prompting.
- The emphasis on continuous multi-scenario training suggests similar curricula may help other generative models handle mixed modalities.
Load-bearing premise
The LLM's built-in reasoning can reliably translate free-form text meaning into coherent acoustic details without separate text encoders, rewriters, or structured inputs.
What would settle it
A collection of free-form prompts that require precise timing and interaction between spoken words and background sounds, where the generated audio either fails to match the described scene or produces audible mismatches between speech and sound elements.
Figures
read the original abstract
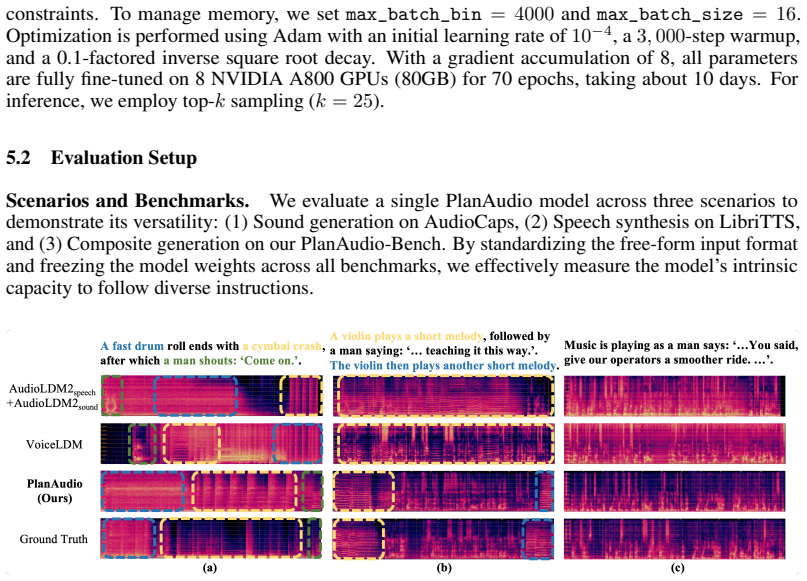
Audio generation has made significant progress, yet synthesizing unified audio where speech and sounds are naturally composited remains a challenge. Current methods either rely on disjoint pipelines, which fail to capture fine-grained interactions, or require structured inputs and external text rewriting, which limits the flexibility of free-form text prompts. In this paper, we introduce a new task: Free-Form-Text-Prompt-to-Unified-Audio generation, which aims to directly synthesize unified audio containing speech, sound, and their composites from unconstrained natural language. To address this task, we propose PlanAudio, a unified, autoregressive LLM-based framework. First, it simplifies the model architecture by leveraging intrinsic LLM reasoning capability instead of traditional text encoders. Second, it introduces a semantic latent chain-of-thought mechanism, an implicit planning mechanism that bridges high-level semantic understanding and low-level acoustic synthesis. Furthermore, we create PlanAudio-Bench, a specialized benchmark for evaluating composite audio scenarios. We perform evaluations in the scenarios of speech, sound, and their composites. The results demonstrate that PlanAudio generally outperforms the existing pipeline and unified baselines, while staying competitive with models designed for a single scenario. Our analysis further reveals the superiority of semantic latent CoT over other CoT mechanisms and highlights the importance of continuous multi-scenario training curricula.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the task of Free-Form-Text-Prompt-to-Unified-Audio generation and proposes PlanAudio, an autoregressive LLM-based framework that uses intrinsic LLM reasoning and a semantic latent chain-of-thought mechanism to synthesize composite audio containing speech, sounds, and their interactions directly from unconstrained natural language prompts. It also presents PlanAudio-Bench for evaluation across speech, sound, and composite scenarios, claiming that PlanAudio outperforms existing pipeline and unified baselines while remaining competitive with single-scenario models, with additional analysis showing benefits of the semantic latent CoT and multi-scenario training.
Significance. If the empirical claims hold with rigorous validation, the work would advance unified audio synthesis by removing reliance on structured inputs or external rewriting, enabling more flexible generation of naturally composited speech and environmental sounds; the introduction of a specialized benchmark and the implicit planning mechanism could influence downstream applications in multimedia and conversational AI.
major comments (2)
- [Abstract / Results] The abstract states that PlanAudio 'generally outperforms' baselines on PlanAudio-Bench but supplies no quantitative metrics, error bars, dataset sizes, or ablation results; without these in the results section, the central empirical claim cannot be assessed for statistical significance or fairness of comparisons.
- [Method / Framework description] The semantic latent chain-of-thought mechanism is presented as bridging high-level semantics to low-level acoustics without external rewriting, yet the manuscript provides no formal definition, training objective, or ablation isolating its contribution versus standard CoT or direct prompting; this is load-bearing for the architectural novelty claim.
minor comments (2)
- [Benchmark section] Clarify the exact composition of PlanAudio-Bench (number of prompts per scenario, annotation process, and how composite cases are constructed) to allow reproducibility.
- [Method] The claim of 'parameter-free' or simplified architecture via LLM reasoning should be supported by explicit comparison of parameter counts or training stages against baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point-by-point below, clarifying aspects of the manuscript and outlining planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Results] The abstract states that PlanAudio 'generally outperforms' baselines on PlanAudio-Bench but supplies no quantitative metrics, error bars, dataset sizes, or ablation results; without these in the results section, the central empirical claim cannot be assessed for statistical significance or fairness of comparisons.
Authors: The results section contains quantitative tables reporting performance metrics across speech, sound, and composite scenarios on PlanAudio-Bench, with direct comparisons to pipeline and unified baselines as well as single-scenario models. The experimental setup details dataset sizes, and the analysis section includes ablations on the semantic latent CoT and multi-scenario training. We agree that the abstract would benefit from including key quantitative results to make the claims more concrete. We will revise the abstract to report specific metrics (e.g., relative improvements) and ensure clear cross-references to the results tables, error bars where applicable, and dataset statistics. revision: yes
-
Referee: [Method / Framework description] The semantic latent chain-of-thought mechanism is presented as bridging high-level semantics to low-level acoustics without external rewriting, yet the manuscript provides no formal definition, training objective, or ablation isolating its contribution versus standard CoT or direct prompting; this is load-bearing for the architectural novelty claim.
Authors: Section 3 describes the semantic latent chain-of-thought as an implicit planning mechanism integrated into the autoregressive LLM decoder that enables semantic composition reasoning prior to acoustic token generation. The analysis section reports comparisons demonstrating its superiority over alternative CoT mechanisms. We acknowledge that a formal definition and explicit training objective would improve rigor and clarity. We will add a mathematical formulation of the mechanism and the associated training objective in the revised method section. We will also expand the ablation studies to more explicitly compare against standard CoT and direct prompting baselines. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces a new task and an LLM-based framework (PlanAudio) with a semantic latent chain-of-thought mechanism, then reports empirical results on a new benchmark (PlanAudio-Bench) showing outperformance over baselines. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps are present in the abstract or described framework. Claims rest on external experimental comparisons rather than reducing to self-definition or imported uniqueness theorems. The central result is self-contained against the stated evaluations.
Axiom & Free-Parameter Ledger
invented entities (1)
-
semantic latent chain-of-thought mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cosyvoice 2: Scalable streaming speech synthesis with large language models,
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wang, F. Yu, H. Liu, Z. Sheng, Y . Gu, C. Deng, W. Wang, S. Zhang, Z. Yan, and J. Zhou, “Cosyvoice 2: Scalable streaming speech synthesis with large language models,”CoRR, vol. abs/2412.10117,
-
[2]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
[Online]. Available: https://doi.org/10.48550/arXiv.2412.10117
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.10117
-
[3]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Z. Du, C. Gao, Y . Wang, F. Yu, T. Zhao, H. Wang, X. Lv, H. Wang, C. Ni, X. Shi, K. An, G. Yang, Y . Li, Y . Chen, Z. Gao, Q. Chen, Y . Gu, M. Chen, Y . Chen, S. Zhang, W. Wang, and J. Ye, “Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training,”CoRR, vol. abs/2505.17589, 2025. [Online]. Available: https://doi.org/10.48550/arX...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.17589 2025
-
[4]
Q. Team, “Qwen3-tts technical report,”CoRR, vol. abs/2601.15621, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2601.15621
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.15621 2026
-
[5]
Audiogen: Textually guided audio generation,
F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. Défossez, J. Copet, D. Parikh, Y . Taigman, and Y . Adi, “Audiogen: Textually guided audio generation,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=CYK7RfcOzQ4
2023
-
[6]
Audioldm 2: Learning holistic audio generation with self-supervised pretraining,
H. Liu, Y . Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y . Wang, W. Wang, Y . Wang, and M. D. Plumbley, “Audioldm 2: Learning holistic audio generation with self-supervised pretraining,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 32, pp. 2871–2883, 2024. [Online]. Available: https://doi.org/10.1109/TASLP.2024.3399607
-
[7]
Audiocomposer: Towards fine-grained audio generation with natural language descriptions,
Z. Evans, J. D. Parker, C. Carr, Z. Zukowski, J. Taylor, and J. Pons, “Stable audio open,” in 2025 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2025, Hyderabad, India, April 6-11, 2025. IEEE, 2025, pp. 1–5. [Online]. Available: https://doi.org/10.1109/ICASSP49660.2025.10888461
-
[8]
Y . Lee, I. Yeon, J. Nam, and J. S. Chung, “V oiceldm: Text-to-speech with environmental context,” inIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2024, Seoul, Republic of Korea, April 14-19, 2024. IEEE, 2024, pp. 12 566–12 571. [Online]. Available: https://doi.org/10.1109/ICASSP48485.2024.10448268
-
[9]
Audiocomposer: Towards fine-grained audio generation with natural language descriptions,
J. Jung, J. Ahn, C. Jung, T. D. Nguyen, Y . Jang, and J. S. Chung, “V oicedit: Dual-condition diffusion transformer for environment-aware speech synthesis,” in2025 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2025, Hyderabad, India, April 6-11, 2025. IEEE, 2025, pp. 1–5. [Online]. Available: https://doi.org/10.1109/ICAS...
-
[10]
Y . Jiang, Z. Chen, Z. Ju, Y . Dai, W. Dou, and J. Zhu, “Controlaudio: Tackling text-guided, timing-indicated and intelligible audio generation via progressive diffusion modeling,”CoRR, vol. abs/2510.08878, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.08878
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.08878 2025
-
[11]
Audiobox: Unified audio generation with natural language prompts,
A. Vyas, B. Shi, M. Le, A. Tjandra, Y . Wu, B. Guo, J. Zhang, X. Zhang, R. Adkins, W. Ngan, J. Wang, I. Cruz, B. Akula, A. Akinyemi, B. Ellis, R. Moritz, Y . Yungster, A. Rakotoarison, L. Tan, C. Summers, C. Wood, J. Lane, M. Williamson, and W. Hsu, “Audiobox: Unified audio generation with natural language prompts,”CoRR, vol. abs/2312.15821, 2023. [Online...
-
[12]
Libritts: A corpus derived from librispeech for text-to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “Libritts: A corpus derived from librispeech for text-to-speech,” in20th Annual Conference of the International Speech Communication Association, Interspeech 2019, Graz, Austria, September 15-19, 2019, G. Kubin and Z. Kacic, Eds. ISCA, 2019, pp. 1526–1530. [Online]. Availabl...
-
[13]
Audiocaps: Generating captions for audios in the wild,
C. D. Kim, B. Kim, H. Lee, and G. Kim, “Audiocaps: Generating captions for audios in the wild,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, V olume 1 (Long and Short Papers), J. Burstein, C. Doran, and...
-
[14]
Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research,
X. Mei, C. Meng, H. Liu, Q. Kong, T. Ko, C. Zhao, M. D. Plumbley, Y . Zou, and W. Wang, “Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research,”IEEE ACM Trans. Audio Speech Lang. Process., vol. 32, pp. 3339–3354,
-
[15]
Available: https://doi.org/10.1109/TASLP.2024.3419446
[Online]. Available: https://doi.org/10.1109/TASLP.2024.3419446
-
[16]
Audiocomposer: Towards fine-grained audio generation with natural language descriptions,
Y . Wang, H. Chen, D. Yang, Z. Wu, and X. Wu, “Audiocomposer: Towards fine-grained audio generation with natural language descriptions,” in2025 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2025, Hyderabad, India, April 6-11, 2025. IEEE, 2025, pp. 1–5. [Online]. Available: https://doi.org/10.1109/ICASSP49660.2025.10888303
-
[17]
Freeaudio: Training-free timing planning for controllable long-form text-to-audio generation,
Y . Jiang, Z. Chen, Z. Ju, C. Li, W. Dou, and J. Zhu, “Freeaudio: Training-free timing planning for controllable long-form text-to-audio generation,” inProceedings of the 33rd ACM International Conference on Multimedia, MM 2025, Dublin, Ireland, October 27-31, 2025, C. Gurrin, K. Schoeffmann, M. Zhang, L. Rossetto, S. Rudinac, D. Dang-Nguyen, W. Cheng, P....
-
[18]
Audiocomposer: Towards fine-grained audio generation with natural language descriptions,
Z. Xie, X. Xu, Z. Wu, and M. Wu, “Picoaudio: Enabling precise temporal controllability in text-to-audio generation,” in2025 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2025, Hyderabad, India, April 6-11, 2025. IEEE, 2025, pp. 1–5. [Online]. Available: https://doi.org/10.1109/ICASSP49660.2025.10890827
-
[19]
Y . Zhou, X. Qin, Z. Jin, S. Zhou, S. Lei, S. Zhou, Z. Wu, and J. Jia, “V oxinstruct: Expressive human instruction-to-speech generation with unified multilingual codec language modelling,” in Proceedings of the 32nd ACM International Conference on Multimedia, MM 2024, Melbourne, VIC, Australia, 28 October 2024 - 1 November 2024, J. Cai, M. S. Kankanhalli,...
-
[20]
Flexivoice: Enabling flexible style control in zero-shot TTS with natural language instructions,
D. Chen, X. Zhang, Y . Wang, K. Dai, L. Ma, and Z. Wu, “Flexivoice: Enabling flexible style control in zero-shot TTS with natural language instructions,”CoRR, vol. abs/2601.04656, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2601.04656
-
[21]
H. Xue, X. Song, Y . Tang, J. Chen, Y . Chen, Y . Li, and Y . Zhou, “Moe-tts: Enhancing out-of-domain text understanding for description-based TTS via mixture-of-experts,”CoRR, vol. abs/2508.11326, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2508.11326
-
[22]
Uniaudio: An audio foundation model toward universal audio generation,
D. Yang, J. Tian, X. Tan, R. Huang, S. Liu, X. Chang, J. Shi, S. Zhao, J. Bian, X. Wu, Z. Zhao, S. Watanabe, and H. Meng, “Uniaudio: An audio foundation model toward universal audio generation,”CoRR, vol. abs/2310.00704, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.00704
-
[23]
Fugatto 1: Foundational generative audio transformer opus 1,
R. Valle, R. Badlani, Z. Kong, S. Lee, A. Goel, S. Kim, J. F. Santos, S. Dai, S. Gururani, A. Aljafari, A. H. Liu, K. J. Shih, R. Prenger, W. Ping, C. H. Yang, and B. Catanzaro, “Fugatto 1: Foundational generative audio transformer opus 1,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. Open...
2025
-
[24]
Available: https://openreview.net/forum?id=B2Fqu7Y2cd
[Online]. Available: https://openreview.net/forum?id=B2Fqu7Y2cd
-
[25]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” in Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022...
2022
-
[26]
Cot-vtm: Visual-to-music generation with chain-of-thought reasoning,
X. Guan, Z. Gu, J. Huo, T. Ding, and Y . Gao, “Cot-vtm: Visual-to-music generation with chain-of-thought reasoning,” inFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, ser. Findings of ACL, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Association for Computational Linguistics, 2025...
2025
-
[27]
H. Xue, Y . Tang, H. Liu, J. Zhang, X. Geng, and L. Xie, “Enhancing non-core language instruction-following in speech llms via semi-implicit cross-lingual cot reasoning,” in Proceedings of the 33rd ACM International Conference on Multimedia, MM 2025, Dublin, Ireland, October 27-31, 2025, C. Gurrin, K. Schoeffmann, M. Zhang, L. Rossetto, S. Rudinac, D. Dan...
-
[28]
Ov-instructtts: Towards open-vocabulary instruct text-to-speech,
Y . Ren, J. Yi, J. Tao, H. Sun, Z. Wen, H. Gu, L. Xu, and Y . Bai, “Ov-instructtts: Towards open-vocabulary instruct text-to-speech,”CoRR, vol. abs/2601.01459, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2601.01459
-
[29]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
J. Geiping, S. McLeish, N. Jain, J. Kirchenbauer, S. Singh, B. R. Bartoldson, B. Kailkhura, A. Bhatele, and T. Goldstein, “Scaling up test-time compute with latent reasoning: A recurrent depth approach,”CoRR, vol. abs/2502.05171, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2502.05171
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.05171 2025
-
[30]
Training Large Language Models to Reason in a Continuous Latent Space
S. Hao, S. Sukhbaatar, D. Su, X. Li, Z. Hu, J. Weston, and Y . Tian, “Training large language models to reason in a continuous latent space,”CoRR, vol. abs/2412.06769, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2412.06769
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.06769 2024
-
[31]
Reasoning beyond language: A comprehensive survey on latent chain-of-thought reasoning,
X. Chen, A. Zhao, H. Xia, X. Lu, H. Wang, Y . Chen, W. Zhang, J. Wang, W. Li, and X. Shen, “Reasoning beyond language: A comprehensive survey on latent chain-of-thought reasoning,”CoRR, vol. abs/2505.16782, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2505.16782
-
[32]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S. Lee, C. H. Yang, R. Duraiswami, D. Manocha, R. Valle, and B. Catanzaro, “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,”CoRR, vol. abs/2507.08128, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2507.08128
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.08128 2025
-
[33]
Audio set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2017, New Orleans, LA, USA, March 5-9, 2017. IEEE, 2017, pp. 776–780. [Online]. Available: ht...
-
[34]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett,...
2023
-
[35]
Simple and controllable music generation,
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y . Adi, and A. Défossez, “Simple and controllable music generation,” inAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, A. Oh, T. Naumann, A. Globerson, K. Saenko, M....
2023
-
[36]
Text-to-audio generation using instruction-tuned LLM and latent diffusion model,
D. Ghosal, N. Majumder, A. Mehrish, and S. Poria, “Text-to-audio generation using instruction-tuned LLM and latent diffusion model,”CoRR, vol. abs/2304.13731, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2304.13731
-
[37]
Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models,
R. Huang, J. Huang, D. Yang, Y . Ren, L. Liu, M. Li, Z. Ye, J. Liu, X. Yin, and Z. Zhao, “Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models,” in International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Enge...
2023
-
[38]
R. Shimizu, R. Yamamoto, M. Kawamura, Y . Shirahata, H. Doi, T. Komatsu, and K. Tachibana, “Prompttts++: Controlling speaker identity in prompt-based text-to-speech using natural language descriptions,” inIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2024, Seoul, Republic of Korea, April 14-19, 2024. IEEE, 2024, pp. 12 6...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.