ZipRL: Adaptive Multi-Turn Context Compression with Hindsight Response Replay
Pith reviewed 2026-06-29 12:37 UTC · model grok-4.3
The pith
ZipRL improves multi-turn agent task performance through adaptive non-uniform context compression and hindsight response replay during reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
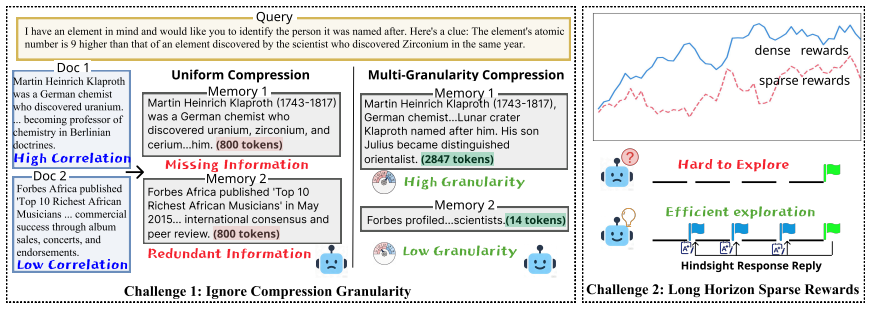
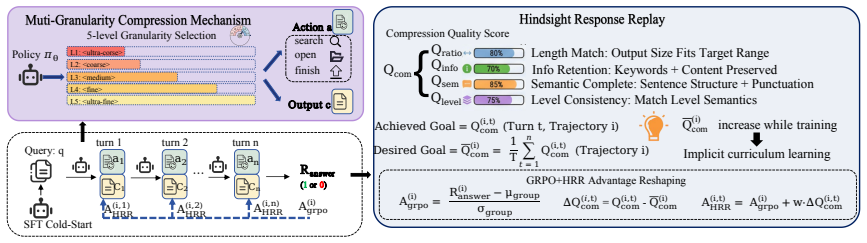
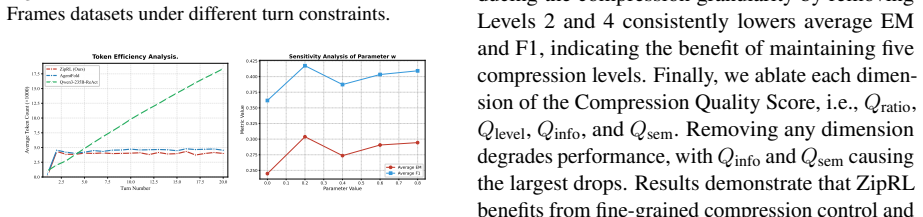
ZipRL features a multi-granularity compression mechanism for active, non-uniform information reduction, coupled with Hindsight Response Replay (HRR), a technique designed to densify training signals during RLVR optimization. Theoretically, we prove ZipRL's superior task-relevant utility over uniform methods. Concretely, ZipRL utilizes coarse-to-fine prompts for macro-compression and incorporates HRR into GRPO via generalized advantage reshaping. Benchmarks on five agent tasks show ZipRL outperforms state-of-the-art approaches by 27.9% and 34.7% across Qwen3-4B and Qwen3-8B models, while maintaining exceptional token efficiency and robustness under extreme 256-turn extrapolation stress tests.
What carries the argument
Multi-granularity compression mechanism combined with Hindsight Response Replay (HRR) that reshapes advantages inside GRPO to densify RL training signals.
If this is right
- The method delivers 27.9 percent and 34.7 percent higher scores than prior approaches on the five agent tasks while using fewer tokens.
- Performance remains stable when test sequences are extended to 256 turns.
- Coarse-to-fine prompting plus advantage reshaping produces higher task-relevant utility than uniform compression.
- The framework works across models of different sizes without additional task-specific tuning.
Where Pith is reading between the lines
- The same replay idea could be tested inside other RL algorithms that also suffer from sparse long-horizon rewards.
- If non-uniform compression preserves utility better than uniform methods in this setting, similar granularity choices may help in retrieval-augmented generation pipelines.
- The reported robustness at 256 turns suggests the approach may scale to even longer agent sessions before context limits are reached.
Load-bearing premise
The assumption that hindsight response replay densifies training signals in GRPO without introducing bias or instability that would invalidate the reported performance gains on the agent benchmarks.
What would settle it
Running the same five agent tasks with the HRR component removed and finding that the reported performance margins over prior methods disappear would falsify the claim that the replay technique is responsible for the gains.
Figures

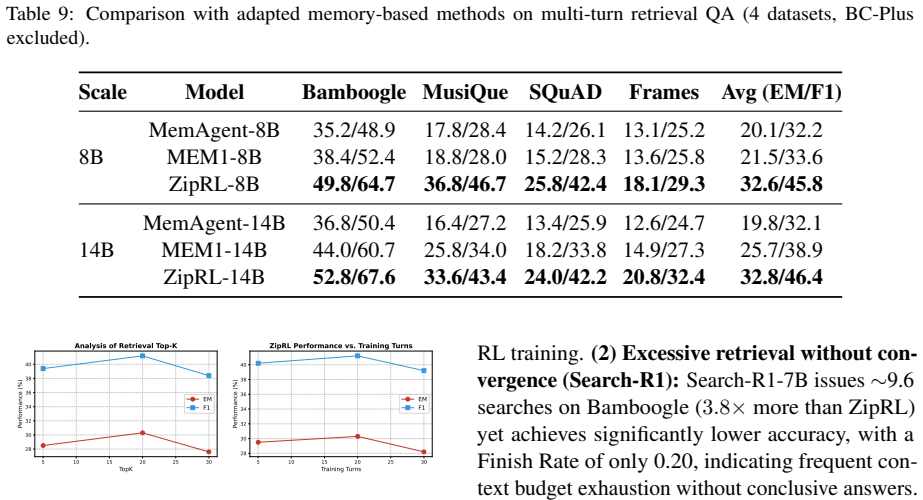
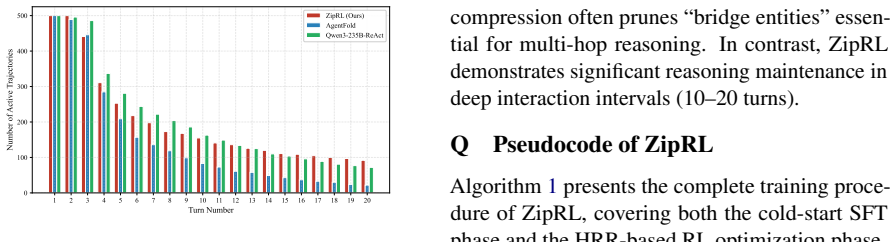

read the original abstract
Adaptive context compression is vital for scaling Large Language Models (LLMs) to complex, multi-turn agent tasks. However, rule-based compression methods may discard task-critical nuances, while Reinforcement Learning (RL) approaches usually struggle to balance information retention and token efficiency under the sparse rewards inherent to long-horizon workflows. To bridge this gap, we propose ZipRL, a novel adaptive compression framework tailored for Reinforcement Learning from Verifiable Rewards (RLVR). ZipRL features a multi-granularity compression mechanism for active, non-uniform information reduction, coupled with Hindsight Response Replay (HRR), a technique designed to densify training signals during RLVR optimization. Theoretically, we prove ZipRL's superior task-relevant utility over uniform methods. Concretely, ZipRL utilizes coarse-to-fine prompts for macro-compression and incorporates HRR into GRPO via generalized advantage reshaping. Multiple models of varying versions and parameter scales validate the effectiveness of our approach. Benchmarks on five agent tasks show ZipRL outperforms state-of-the-art approaches by 27.9% and 34.7% across Qwen3-4B and Qwen3-8B models, while maintaining exceptional token efficiency and robustness under extreme 256-turn extrapolation stress tests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ZipRL, an adaptive context compression framework for RLVR in LLMs aimed at multi-turn agent tasks. It proposes a multi-granularity compression mechanism and Hindsight Response Replay (HRR) integrated into GRPO through generalized advantage reshaping. The authors claim a theoretical proof that ZipRL has superior task-relevant utility compared to uniform methods, and report empirical results where ZipRL outperforms state-of-the-art approaches by 27.9% and 34.7% on Qwen3-4B and Qwen3-8B models across five agent tasks, while showing good token efficiency and robustness in 256-turn extrapolation tests.
Significance. If the results hold, this would represent a significant advance in enabling efficient long-horizon agent workflows with LLMs by improving context management in RL settings. The combination of theoretical analysis and empirical validation on multiple model scales is a strength. The stress tests for extrapolation are particularly notable. However, the significance is tempered by the need to verify that the HRR technique does not introduce bias in the advantage estimates.
major comments (3)
- [Abstract] Abstract: The reported performance gains of 27.9% and 34.7% are presented without specifying the exact metric (e.g., success rate, reward), how baselines were controlled for token budget, or the computation method for the percentages. This is central to the empirical claim.
- [Theoretical proof] Theoretical proof: The proof of superior task-relevant utility does not address whether the generalized advantage reshaping in HRR preserves unbiased policy gradients or introduces correlation with the hindsight response distribution, which could bias the optimization and undermine the attribution of gains to the compression method.
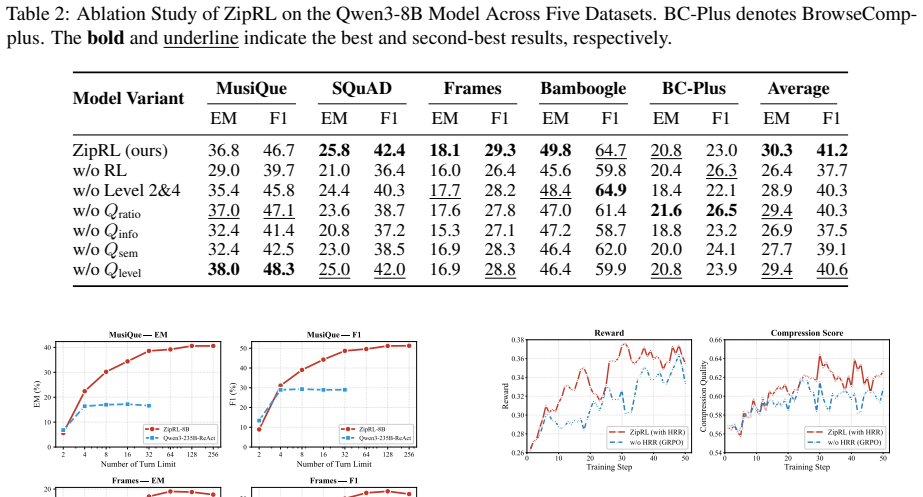
- [Experimental results] Experimental results: No ablation study isolating HRR from the multi-granularity compression is described, making it impossible to determine if the gains are due to the proposed HRR or other factors. This is load-bearing for validating the core contribution.
minor comments (2)
- [Abstract] Abstract: The term 'GRPO' is used without expansion on first use; it should be defined at first mention.
- [Full text] The manuscript would benefit from more details on the five agent tasks and the exact baselines used for comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported performance gains of 27.9% and 34.7% are presented without specifying the exact metric (e.g., success rate, reward), how baselines were controlled for token budget, or the computation method for the percentages. This is central to the empirical claim.
Authors: We agree that additional detail is needed. The reported gains are relative improvements in task success rate. All baselines were evaluated under identical average token budgets as ZipRL for fair comparison. Percentages are computed as (ZipRL success rate - baseline success rate) / baseline success rate. We will revise the abstract to explicitly include these specifications. revision: yes
-
Referee: [Theoretical proof] Theoretical proof: The proof of superior task-relevant utility does not address whether the generalized advantage reshaping in HRR preserves unbiased policy gradients or introduces correlation with the hindsight response distribution, which could bias the optimization and undermine the attribution of gains to the compression method.
Authors: The existing proof establishes superior task-relevant utility for the multi-granularity compression mechanism relative to uniform compression and is independent of the RL optimizer details. HRR is incorporated via generalized advantage reshaping within GRPO; this reshaping uses hindsight responses solely for advantage estimation in a manner that preserves the expectation of the policy gradient (i.e., no systematic bias is introduced). We will add an explicit paragraph in the theoretical analysis section discussing gradient unbiasedness under HRR and addressing potential correlation concerns. revision: yes
-
Referee: [Experimental results] Experimental results: No ablation study isolating HRR from the multi-granularity compression is described, making it impossible to determine if the gains are due to the proposed HRR or other factors. This is load-bearing for validating the core contribution.
Authors: We acknowledge that isolating the contribution of HRR would strengthen the paper. In the revised manuscript we will add an ablation study that fixes the multi-granularity compression and varies the presence of HRR, reporting the incremental performance impact across the five agent tasks. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract and description present a theoretical proof of superior task-relevant utility for ZipRL over uniform compression, plus empirical gains from multi-granularity compression and HRR integrated into GRPO. No equations, self-citations, or fitted parameters are shown that reduce the claimed utility proof, advantage reshaping, or benchmark gains to inputs by construction. The central claims rest on independent theoretical argument and external agent-task benchmarks rather than self-referential definitions or renamed fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl. arXiv preprint arXiv:2508.07976. Tao Ge, Jing Hu, Lei Wang, Xun Wang, Si-Qing Chen, and Furu Wei. 2023. In-context autoencoder for con- text compression in a large language model.arXiv preprint arXiv:2307.06945. Shuyu Guo, Shuo Zhang, and Zhaochun Ren. 2025. Enhancin...
-
[2]
InInternational conference on machine learning, pages 4344–4353
Learning by playing solving sparse reward tasks from scratch. InInternational conference on machine learning, pages 4344–4353. PMLR. Rana Salama, Jason Cai, Michelle Yuan, Anna Currey, Monica Sunkara, Yi Zhang, and Yassine Benajiba
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Meminsight: Autonomous memory augmen- tation for llm agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 33124–33140. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematica...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629. Rui Ye, Zhongwang Zhang, Kuan Li, Huifeng Yin, Zhengwei Tao, Yida Zhao, Liangcai Su, Liwen Zhang, Zile Qiao, Xi...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Agentfold: Long-horizon web agents with proactive context management.arXiv preprint arXiv:2510.24699. Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei- Ying Ma, Jingjing Liu, Mingxuan Wang, and 1 others
-
[6]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Memagent: Reshaping long-context llm with multi-conv rl-based memory agent.arXiv preprint arXiv:2507.02259. Shijie Zhang, Guohao Sun, Kevin Zhang, Xiang Guo, and Rujun Guo. 2025a. Clpo: Curriculum learning meets policy optimization for llm reasoning.arXiv preprint arXiv:2509.25004. Yusen Zhang, Ruoxi Sun, Yanfei Chen, Tomas Pfis- ter, Rui Zhang, and Serca...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
what goalwouldthis trajectory have achieved?
and synthesizing trajectories via GPT-4o. To ensure high quality, we applied two filters: (1)Cor- rectness: retaining only correct trajectories, and (2) Format: discarding outputs with structural viola- tions. This yielded 1,155 valid trajectories, which were then decomposed into transition-level sam- ples. The model is optimized using the standard Superv...
-
[8]
Since the final Qcom is a weighted sum, the penalty in structural and seman- tic dimensions heavily outweighs the illicit gain in Qinfo
Mutual Structural Constraints.While gener- ating redundant query keywords might marginally increase Qinfo, this behavior is strictly penalized by Qratio (length overflow) and Qsem (destroyed grammatical coherence). Since the final Qcom is a weighted sum, the penalty in structural and seman- tic dimensions heavily outweighs the illicit gain in Qinfo
-
[9]
Mathematical Bounding.The keyword cov- erage term Skey =|K q ∩y|/(|K q ∩x|+ϵ) naturally caps at 1.0, preventing unbounded reward through keyword repetition
-
[10]
The final advantage remains fundamentally anchored by the GRPO advantage, which is strictly determined by the exact match (EM/F1) of the final answer
Anchoring by Final Task Reward.HRR functions as an advantage reshaping technique rather than replacing the environment reward. The final advantage remains fundamentally anchored by the GRPO advantage, which is strictly determined by the exact match (EM/F1) of the final answer. This is empirically confirmed by the monotonically increasing Pearson correlati...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.