Diagnosing the conditional-mean barrier in scientific machine-learning surrogates
Pith reviewed 2026-06-29 10:10 UTC · model grok-4.3
The pith
Squared-loss predictors in scientific machine learning reach a conditional-mean barrier where further improvement requires distributional losses instead of point predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
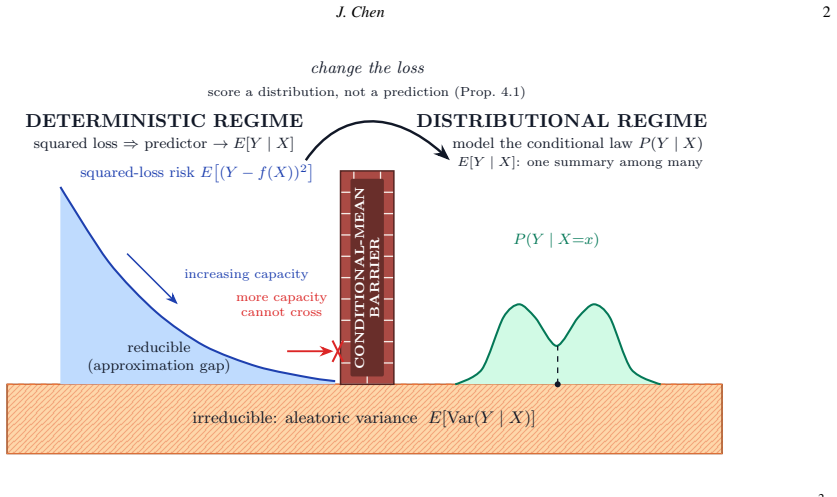
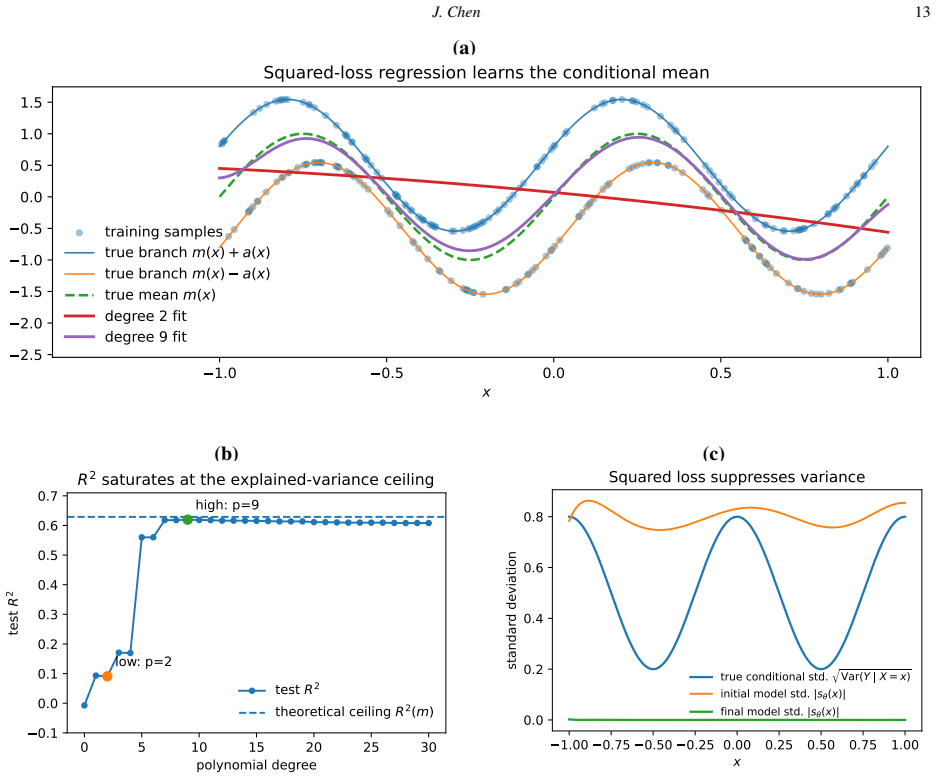
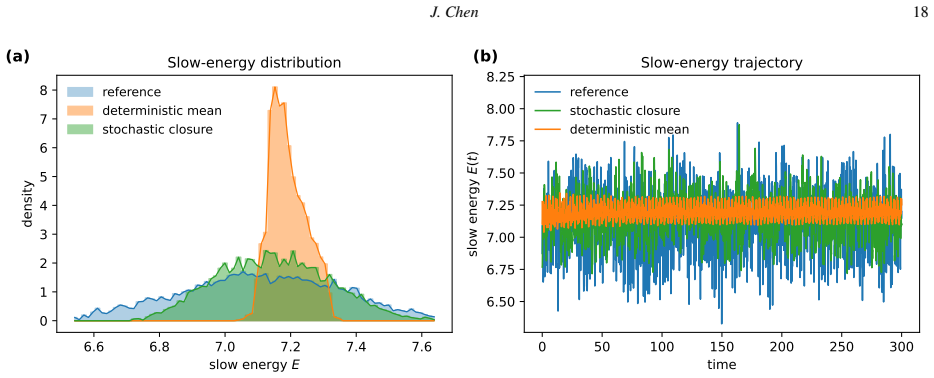
The conditional-mean barrier occurs when a squared-loss trained surrogate has learned the conditional expectation of the target given the inputs, after which the error is only irreducible aleatoric variance. The paper provides residual-feature orthogonality and the coefficient of determination against its explained-variance ceiling as diagnostics to locate this barrier in finite data, and demonstrates that introducing latent randomness into a squared-loss predictor causes it to collapse back to the conditional mean. Crossing the barrier requires objectives that score entire distributions rather than single points.
What carries the argument
The conditional-mean barrier, detected via residual-feature orthogonality and R-squared against the explained-variance ceiling, marks the transition from reducible to irreducible error in squared-loss training.
If this is right
- Detecting the barrier allows distinguishing deterministic underfitting from inherent variability in the data.
- Adding latent randomness to a squared-loss model reverts it to the conditional mean predictor.
- Distributional losses such as negative log-likelihood or moment matching are needed to model uncertainty beyond the barrier.
- The diagnostics apply to problems like subgrid forcing in simulations and effective response in materials.
Where Pith is reading between the lines
- The approach could extend to time-series forecasting where aleatoric noise is common.
- Practitioners might integrate these diagnostics into training loops to decide when to switch loss functions.
- Further work could test whether the barrier location depends on model architecture beyond the loss.
Load-bearing premise
The input features and training data are sufficient for a squared-loss model to reach the conditional mean in finite samples.
What would settle it
If a squared-loss model trained to convergence still shows residuals correlated with features, or if its R2 falls short of the explained variance ceiling, this would indicate the barrier has not been reached; observing that a model with added latent variables produces different predictions than the mean would falsify the collapse result.
Figures
read the original abstract
Many problems in computational science and engineering become one-to-many after coarse graining, partial observation, or inverse reconstruction: a resolved state may not determine a unique subgrid forcing, a structural descriptor may not determine a unique effective response, and a low-resolution observation may correspond to many plausible high-resolution fields. In such settings, deterministic surrogates may learn a well-defined mathematical object while still missing application-relevant uncertainty. This tutorial develops a self-contained module centered on the conditional-mean barrier: the point at which a squared-loss predictor has reached the conditional mean and the remaining error is irreducible aleatoric variance. We give two diagnostics for locating this barrier, residual-feature orthogonality and the coefficient of determination against its explained-variance ceiling, and prove that adding latent randomness to a squared-loss predictor collapses it back to the conditional mean. Crossing the barrier therefore requires a loss that scores distributions rather than point predictions. We briefly organize common distributional objectives, including negative log-likelihood, moment and observable matching, variational objectives, adversarial divergences, and score matching, by the feature of the conditional law each targets. The emphasis is the boundary itself and a finite-data procedure for recognizing it, rather than a survey of methods beyond it. CPU-based demonstrations on a two-branch law and a two-scale Lorenz-96 closure problem show how the diagnostics distinguish deterministic underfitting from residual distributional variability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a self-contained tutorial on the conditional-mean barrier for squared-loss predictors in scientific ML surrogates for one-to-many problems. It defines the barrier as the point where the model has reached the conditional expectation E[Y|X] and remaining error is irreducible aleatoric variance. Two diagnostics are introduced—residual-feature orthogonality and R² against its explained-variance ceiling—along with a proof that injecting latent randomness into a squared-loss model forces collapse back to the conditional mean. The work argues that crossing the barrier requires distributional losses and organizes common objectives by the conditional-law features they target. CPU demonstrations on a two-branch law and Lorenz-96 closure illustrate distinction between underfitting and residual variability.
Significance. If the diagnostics prove reliable, the contribution supplies a practical finite-data procedure for recognizing when deterministic surrogates have exhausted squared-loss capacity, informing the switch to probabilistic modeling in coarse-graining, inverse problems, and subgrid closures. The explicit proof of collapse under randomness and the organization of distributional objectives by targeted features of the conditional law are clear strengths; the emphasis on boundary detection rather than method survey is appropriately focused.
major comments (3)
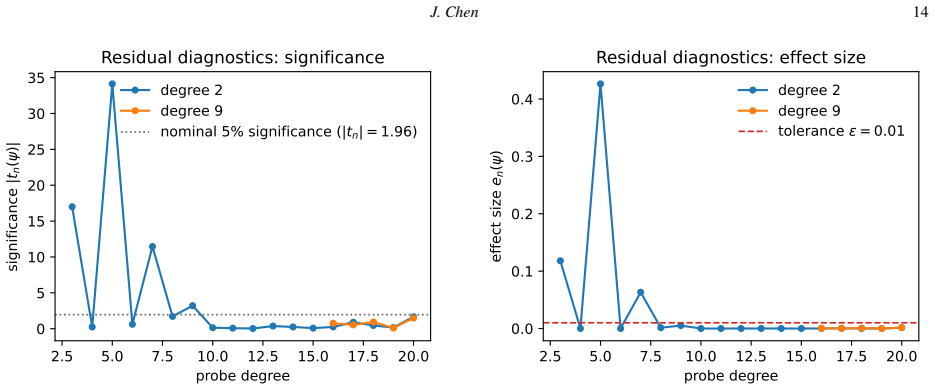
- [§3] §3 (Proof of collapse under latent randomness): The argument is conditioned on exact attainment of the conditional mean by the squared-loss minimizer. No analysis is given for the finite-sample regime in which optimization limits, expressivity, or data insufficiency prevent attainment; the diagnostics would then misattribute underfitting to the barrier. This assumption is load-bearing for the claim that the diagnostics reliably locate the barrier without access to the true conditional law.
- [§4.1] §4.1 (Residual-feature orthogonality diagnostic): The test is presented as an independent check, yet its finite-sample distribution and power against underfitting (as opposed to barrier crossing) are not derived or bounded. The two-branch and Lorenz-96 examples may satisfy the attainment assumption, but the general case lacks an independent verification procedure.
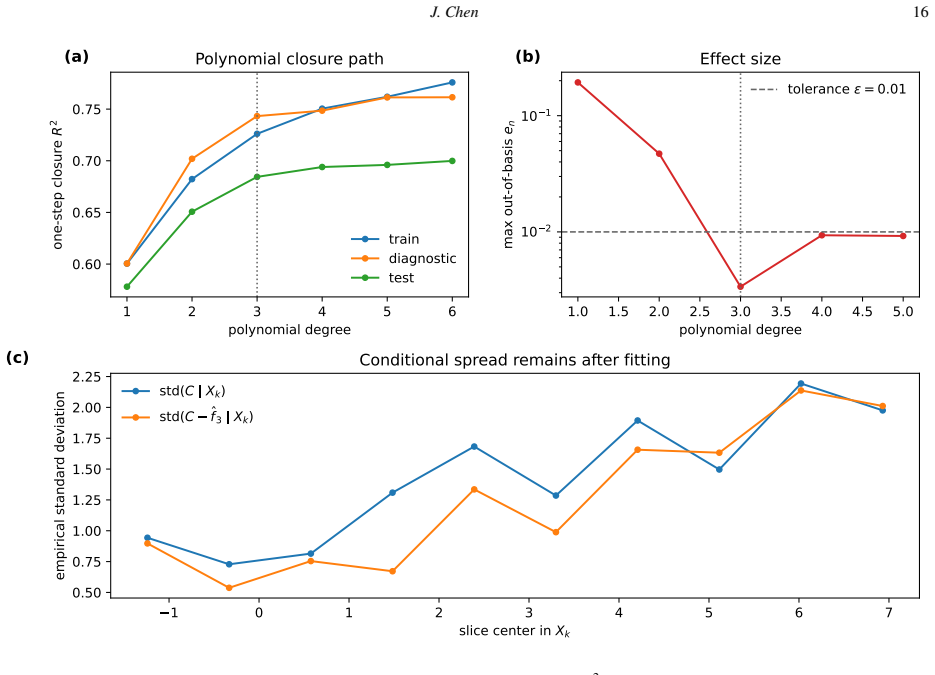
- [§5] §5 (Demonstrations): Both examples are constructed so that the conditional mean is plausibly reachable; no ablation or counter-example is provided where a squared-loss model is deliberately underfit yet the diagnostics are applied, leaving the risk of misdiagnosis untested.
minor comments (2)
- [§4.2] Notation for the explained-variance ceiling in the R² diagnostic should be introduced with an explicit equation reference in §4.2 to avoid ambiguity with standard R².
- [§6] The organization of distributional objectives in §6 would benefit from a summary table mapping each objective to the conditional feature it targets.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the paper's focus on boundary detection for the conditional-mean barrier. We address each major comment below, agreeing where the points identify areas for clarification or strengthening and outlining targeted revisions.
read point-by-point responses
-
Referee: [§3] §3 (Proof of collapse under latent randomness): The argument is conditioned on exact attainment of the conditional mean by the squared-loss minimizer. No analysis is given for the finite-sample regime in which optimization limits, expressivity, or data insufficiency prevent attainment; the diagnostics would then misattribute underfitting to the barrier. This assumption is load-bearing for the claim that the diagnostics reliably locate the barrier without access to the true conditional law.
Authors: We agree that the proof in §3 is stated for the population case in which the squared-loss minimizer exactly attains E[Y|X]. In finite samples, optimization or capacity limits could produce underfitting that the diagnostics might misclassify. The residual-feature orthogonality check is intended to flag such cases via nonzero correlations, but we accept that this does not constitute a formal separation. We will add a short discussion paragraph in §3 clarifying the population assumption, noting that practitioners should first verify that training has converged (e.g., via validation loss plateau), and stating that the diagnostics are most reliable once that check passes. This revision makes the scope explicit without altering the core proof. revision: partial
-
Referee: [§4.1] §4.1 (Residual-feature orthogonality diagnostic): The test is presented as an independent check, yet its finite-sample distribution and power against underfitting (as opposed to barrier crossing) are not derived or bounded. The two-branch and Lorenz-96 examples may satisfy the attainment assumption, but the general case lacks an independent verification procedure.
Authors: The referee is correct that we provide no analytic finite-sample distribution or power bounds for the orthogonality diagnostic. Such bounds would require strong assumptions on the joint distribution of features and residuals and lie outside the tutorial's intended scope. The diagnostic is offered as a practical, model-agnostic sample correlation test that can be supplemented by permutation or bootstrap procedures in applications. We will revise the opening of §4.1 to label the procedure explicitly as a heuristic finite-data check rather than a formal statistical test, and we will add a brief remark on using resampling to gauge significance. This preserves the emphasis on usability while acknowledging the theoretical gap. revision: partial
-
Referee: [§5] §5 (Demonstrations): Both examples are constructed so that the conditional mean is plausibly reachable; no ablation or counter-example is provided where a squared-loss model is deliberately underfit yet the diagnostics are applied, leaving the risk of misdiagnosis untested.
Authors: We accept that the current demonstrations were chosen to illustrate barrier crossing when the conditional mean is attainable, leaving the underfitting case untested. To close this gap we will add a short ablation subsection in §5 that deliberately restricts model capacity on the two-branch example (e.g., a linear predictor on a nonlinear target). The revised text will report that both diagnostics correctly flag residual feature correlation and an R² well below the variance ceiling, thereby indicating underfitting rather than barrier attainment. This addition directly addresses the requested counter-example while remaining within the CPU-scale setting of the original demonstrations. revision: yes
Circularity Check
No significant circularity; diagnostics and proof are independent statistical properties
full rationale
The paper's core derivation introduces residual-feature orthogonality and R2-vs-ceiling diagnostics as direct consequences of the definition of conditional expectation (E[residual | features] = 0 and variance decomposition), without defining them from fitted model outputs. The stated proof that latent randomness forces collapse to the conditional mean under squared loss is a standard optimality result for L2, presented as a mathematical fact rather than a self-referential fit. No self-citations, ansatzes, or renamings are invoked as load-bearing steps for the barrier location procedure. The finite-sample attainment assumption is an external modeling premise, not a reduction of the claimed diagnostics to their own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties of conditional expectation and decomposition of variance into explained and aleatoric components
Reference graph
Works this paper leans on
-
[1]
S. L. Brunton, J. L. Proctor, J. N. Kutz, Discovering governing equations from data by sparse identification of nonlinear dynamical systems, Proceedings of the National Academy of Sciences 113 (15) (2016) 3932–3937
2016
-
[2]
S. H. Rudy, S. L. Brunton, J. L. Proctor, J. N. Kutz, Data-driven discovery of partial differential equations, Science Advances 3 (4) (2017) e1602614
2017
-
[3]
Duraisamy, G
K. Duraisamy, G. Iaccarino, H. Xiao, Turbulence modeling in the age of data, Annual Review of Fluid Mechanics 51 (1) (2019) 357–377
2019
-
[4]
L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators, Nature Machine Intelligence 3 (3) (2021) 218–229
2021
-
[5]
Kovachki, Z
N. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. Stuart, A. Anandkumar, Neural operator: Learning maps between function spaces with applications to PDEs, Journal of Machine Learning Research 24 (89) (2023) 1–97
2023
-
[6]
P. C. Hansen, Discrete inverse problems: Insight and algorithms, Society for Industrial and Applied Mathematics, 2010
2010
-
[7]
Benning, M
M. Benning, M. Burger, Modern regularization methods for inverse problems, Acta Numerica 27 (2018) 1–111
2018
-
[8]
A. J. Chorin, O. H. Hald, R. Kupferman, Optimal prediction and the Mori–Zwanzig representation of irreversible processes, Proceedings of the National Academy of Sciences 97 (7) (2000) 2968–2973
2000
-
[9]
F. Lu, K. K. Lin, A. J. Chorin, Data-based stochastic model reduction for the Kuramoto–Sivashinsky equation, Physica D 340 (2017) 46–57
2017
-
[10]
C. J. Gommes, Y . Jiao, S. Torquato, Microstructural degeneracy associated with a two-point correlation function and its information content, Physical Review E 85 (5) (2012) 051140
2012
-
[11]
Bostanabad, Y
R. Bostanabad, Y . Zhang, X. Li, et al., Computational microstructure characterization and reconstruction: Review of the state-of-the-art techniques, Progress in Materials Science 95 (2018) 1–41
2018
-
[12]
Ledig, L
C. Ledig, L. Theis, F. Husz ´ar, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, W. Shi, Photo-realistic single image super-resolution using a generative adversarial network, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4681–4690. J. Chen19 2 4 6 Xk Reference 2 4 6 Xk Determin...
2017
-
[13]
Saharia, J
C. Saharia, J. Ho, W. Chan, T. Salimans, D. J. Fleet, M. Norouzi, Image super-resolution via iterative refinement, IEEE Transactions on Pattern Analysis and Machine Intelligence 45 (4) (2023) 4713–4726
2023
-
[14]
Hastie, R
T. Hastie, R. Tibshirani, J. Friedman, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd Edition, Springer, New York, 2009
2009
-
[15]
C. M. Bishop, Pattern recognition and machine learning, Springer, 2006
2006
-
[16]
T. M. Cover, J. A. Thomas, Elements of information theory, 2nd Edition, John Wiley & Sons, Hoboken, NJ, 2006
2006
-
[17]
Goodfellow, J
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y . Bengio, Generative adversarial nets, in: Advances in Neural Information Processing Systems, V ol. 27, 2014, pp. 2672–2680
2014
-
[18]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, B. Poole, Score-based generative modeling through stochastic differential equations, in: International Conference on Learning Representations, 2021
2021
-
[19]
Kallenberg, Foundations of Modern Probability, 2nd Edition, Springer, New York, 2002
O. Kallenberg, Foundations of Modern Probability, 2nd Edition, Springer, New York, 2002
2002
-
[20]
Mohri, A
M. Mohri, A. Rostamizadeh, A. Talwalkar, Foundations of machine learning, MIT press, 2018
2018
-
[21]
Steinwart, On the influence of the kernel on the consistency of support vector machines, Journal of Machine Learning Research 2 (Nov) (2001) 67–93
I. Steinwart, On the influence of the kernel on the consistency of support vector machines, Journal of Machine Learning Research 2 (Nov) (2001) 67–93
2001
-
[22]
Schaback, H
R. Schaback, H. Wendland, Kernel techniques: from machine learning to meshless methods, Acta Numerica 15 (2006) 543–639
2006
-
[23]
Hornik, Approximation capabilities of multilayer feedforward networks, Neural Networks 4 (1991) 251–257
K. Hornik, Approximation capabilities of multilayer feedforward networks, Neural Networks 4 (1991) 251–257
1991
-
[24]
C. F. Higham, D. J. Higham, Deep learning: An introduction for applied mathematicians, SIAM Review 61 (4) (2019) 860–891
2019
-
[25]
Cybenko, Approximation by superpositions of a sigmoidal function, Mathematics of Control, Signals and Systems 2 (1989) 303–314
G. Cybenko, Approximation by superpositions of a sigmoidal function, Mathematics of Control, Signals and Systems 2 (1989) 303–314
1989
-
[26]
Leshno, V
M. Leshno, V . Y . Lin, A. Pinkus, S. Schocken, Multilayer feedforward networks with a nonpolynomial activation function can approximate any function, Neural Networks 6 (1993) 861–867
1993
-
[27]
L. P. Hansen, Large sample properties of generalized method of moments estimators, Econometrica 50 (1982) 1029–1054
1982
-
[28]
Wasserman, All of Statistics: A Concise Course in Statistical Inference, Springer, New York, 2004
L. Wasserman, All of Statistics: A Concise Course in Statistical Inference, Springer, New York, 2004
2004
-
[29]
D. A. Nix, A. S. Weigend, Estimating the mean and variance of the target probability distribution, in: Proceedings of the IEEE International Conference on Neural Networks, 1994, pp. 55–60
1994
-
[30]
E. M. Stein, R. Shakarchi, Measure theory, integration, and Hilbert spaces (2005)
2005
-
[31]
D. P. Kingma, M. Welling, Auto-encoding variational Bayes, in: International Conference on Learning Representations, 2014
2014
-
[32]
Kendall, Y
A. Kendall, Y . Gal, What uncertainties do we need in Bayesian deep learning for computer vision?, in: Advances in Neural Information Processing Systems, V ol. 30, 2017, pp. 5574–5584
2017
-
[33]
A. P. Guillaumin, L. Zanna, Stochastic-deep learning parameterization of ocean momentum forcing, Journal of Advances in Modeling Earth Systems 13 (9) (2021) e2021MS002534
2021
-
[34]
Papamakarios, E
G. Papamakarios, E. Nalisnick, D. J. Rezende, S. Mohamed, B. Lakshminarayanan, Normalizing flows for probabilistic modeling and infer- ence, Journal of Machine Learning Research 22 (57) (2021) 1–64
2021
-
[35]
L. Guo, H. Wu, T. Zhou, Normalizing field flows: Solving forward and inverse stochastic differential equations using physics-informed flow models, Journal of Computational Physics 461 (2022) 111202
2022
-
[36]
M. Yang, P. Wang, D. del Castillo-Negrete, Y . Cao, G. Zhang, A pseudoreversible normalizing flow for stochastic dynamical systems with various initial distributions, SIAM Journal on Scientific Computing 46 (4) (2024) C508–C533
2024
-
[37]
Cleary, A
E. Cleary, A. Garbuno-Inigo, S. Lan, T. Schneider, A. M. Stuart, Calibrate, emulate, sample, Journal of Computational Physics 424 (2021) 109716
2021
-
[38]
D. Qi, J. Harlim, A data-driven statistical-stochastic surrogate modeling strategy for complex nonlinear non-stationary dynamics, Journal of Computational Physics 485 (2023) 112085
2023
-
[39]
D. J. Rezende, S. Mohamed, D. Wierstra, Stochastic backpropagation and approximate inference in deep generative models, in: Proceedings of the 31st International Conference on Machine Learning, 2014, pp. 1278–1286
2014
-
[40]
Gundersen, A
K. Gundersen, A. Oleynik, N. Blaser, G. Alendal, Semi-conditional variational auto-encoder for flow reconstruction and uncertainty quantifi- cation from limited observations, Physics of Fluids 33 (1)
-
[41]
Conditional Generative Adversarial Nets
M. Mirza, S. Osindero, Conditional generative adversarial nets (2014).arXiv:1411.1784
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[42]
L. Yang, D. Zhang, G. E. Karniadakis, Physics-informed generative adversarial networks for stochastic differential equations, SIAM Journal on Scientific Computing 42 (1) (2020) A292–A317
2020
-
[43]
J. Ho, A. Jain, P. Abbeel, Denoising diffusion probabilistic models, in: Advances in Neural Information Processing Systems, V ol. 33, 2020, pp. 6840–6851
2020
-
[44]
Vincent, A connection between score matching and denoising autoencoders, Neural Computation 23 (2011) 1661–1674
P. Vincent, A connection between score matching and denoising autoencoders, Neural Computation 23 (2011) 1661–1674
2011
-
[45]
Y . Liu, Y . Chen, D. Xiu, G. Zhang, A training-free conditional diffusion model for learning stochastic dynamical systems, SIAM Journal on Scientific Computing 47 (5) (2025) C1144–C1171
2025
-
[46]
E. N. Lorenz, Predictability: A problem partly solved, in: Proc. Seminar on Predictability, V ol. 1, Reading, 1996, pp. 1–18
1996
-
[47]
D. S. Wilks, Effects of stochastic parametrizations in the Lorenz’96 system, Quarterly Journal of the Royal Meteorological Society 131 (606) (2005) 389–407
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.