ATLAS: All-round Testing of Long-context Abilities across Scales
Pith reviewed 2026-06-29 13:27 UTC · model grok-4.3
The pith
Long-context model rankings change substantially between 128K and 1M tokens because single-length scores mask different failure modes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
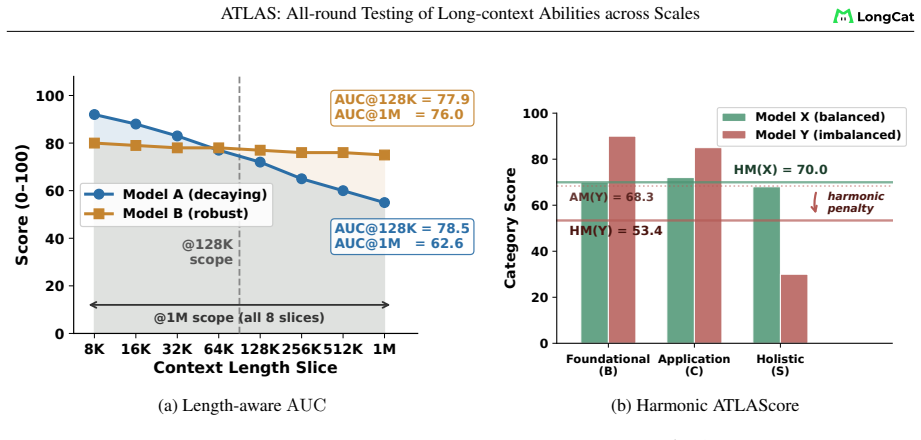
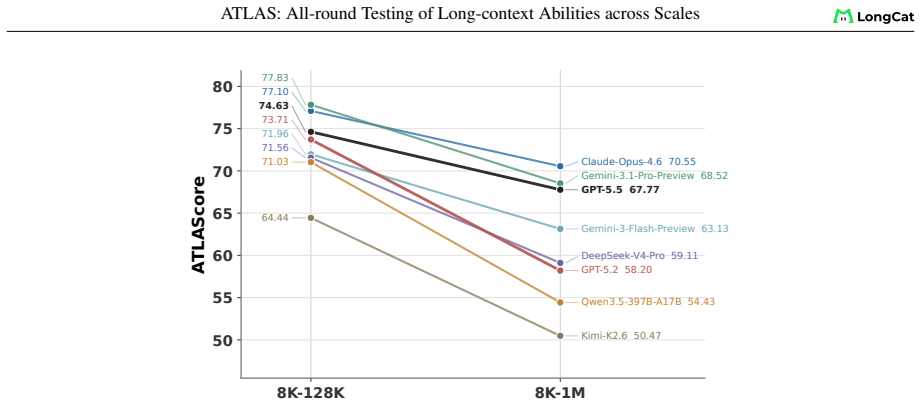
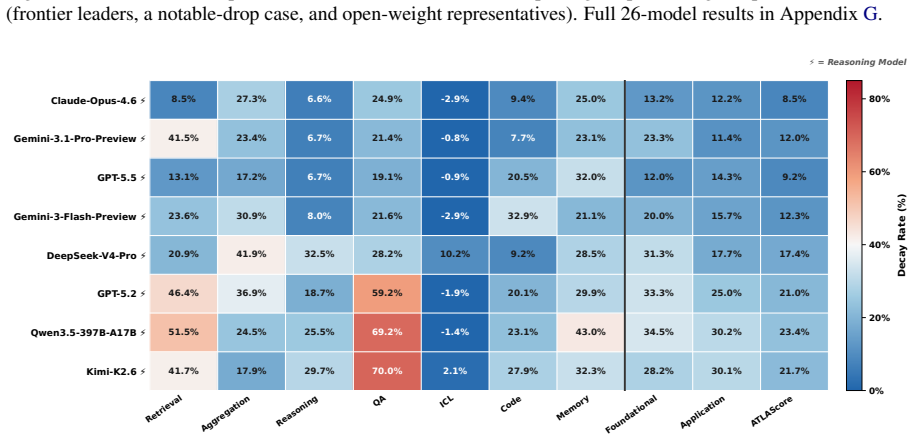
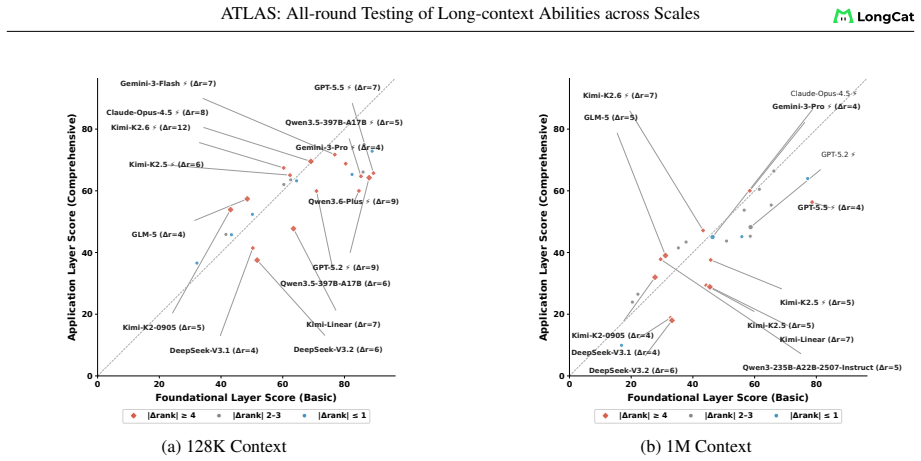
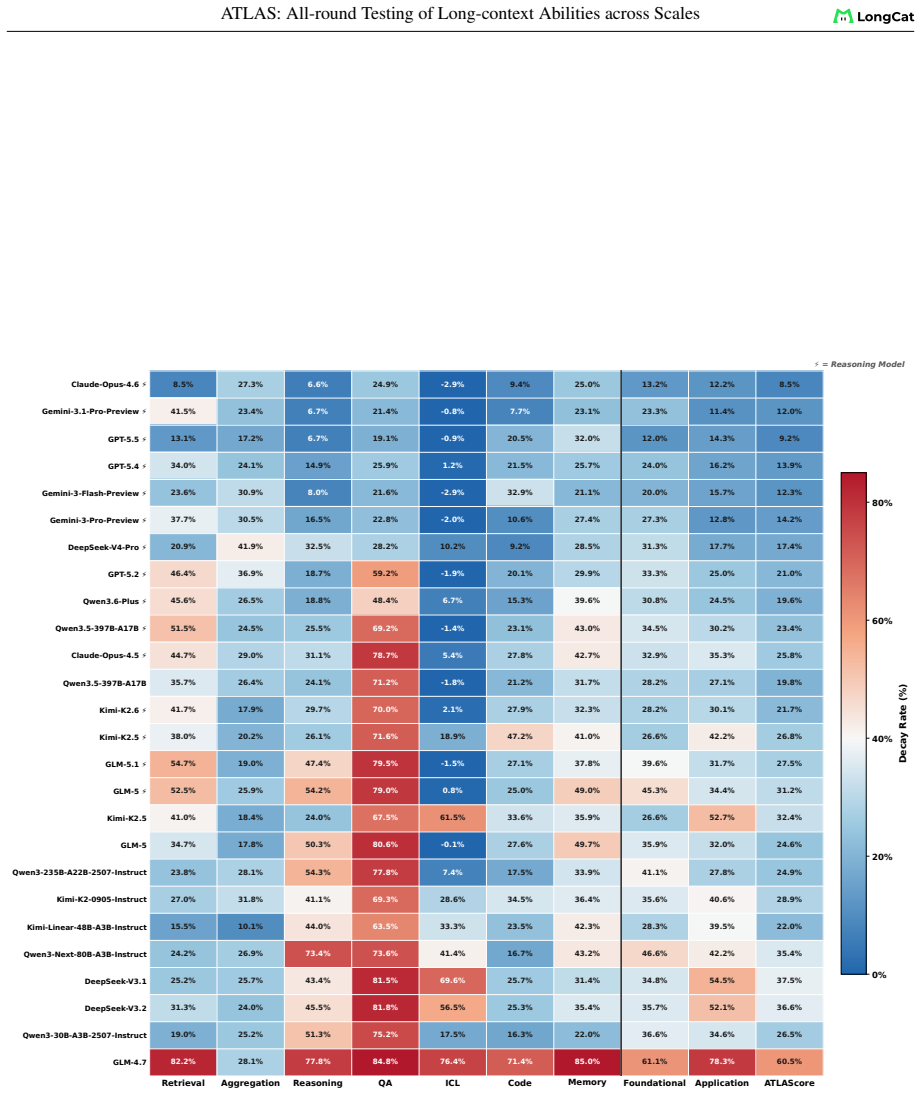
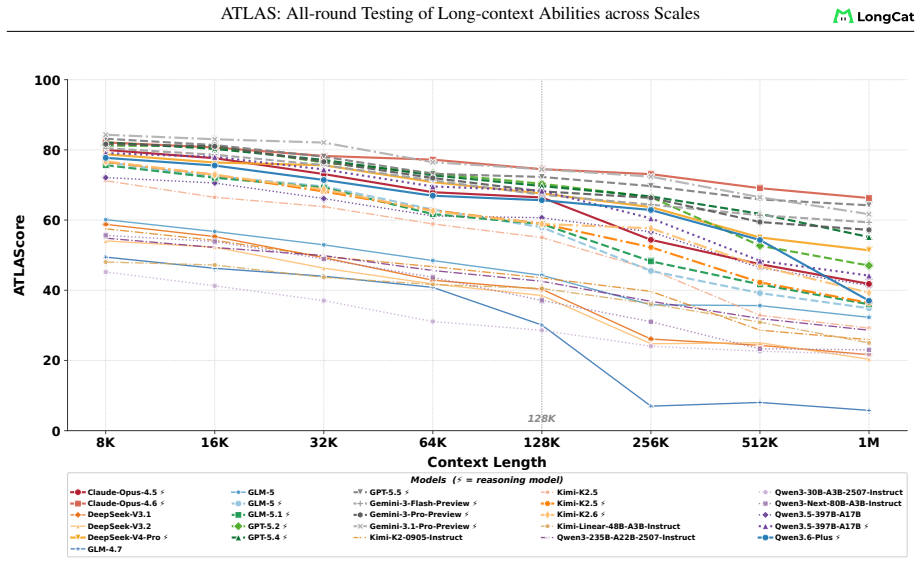
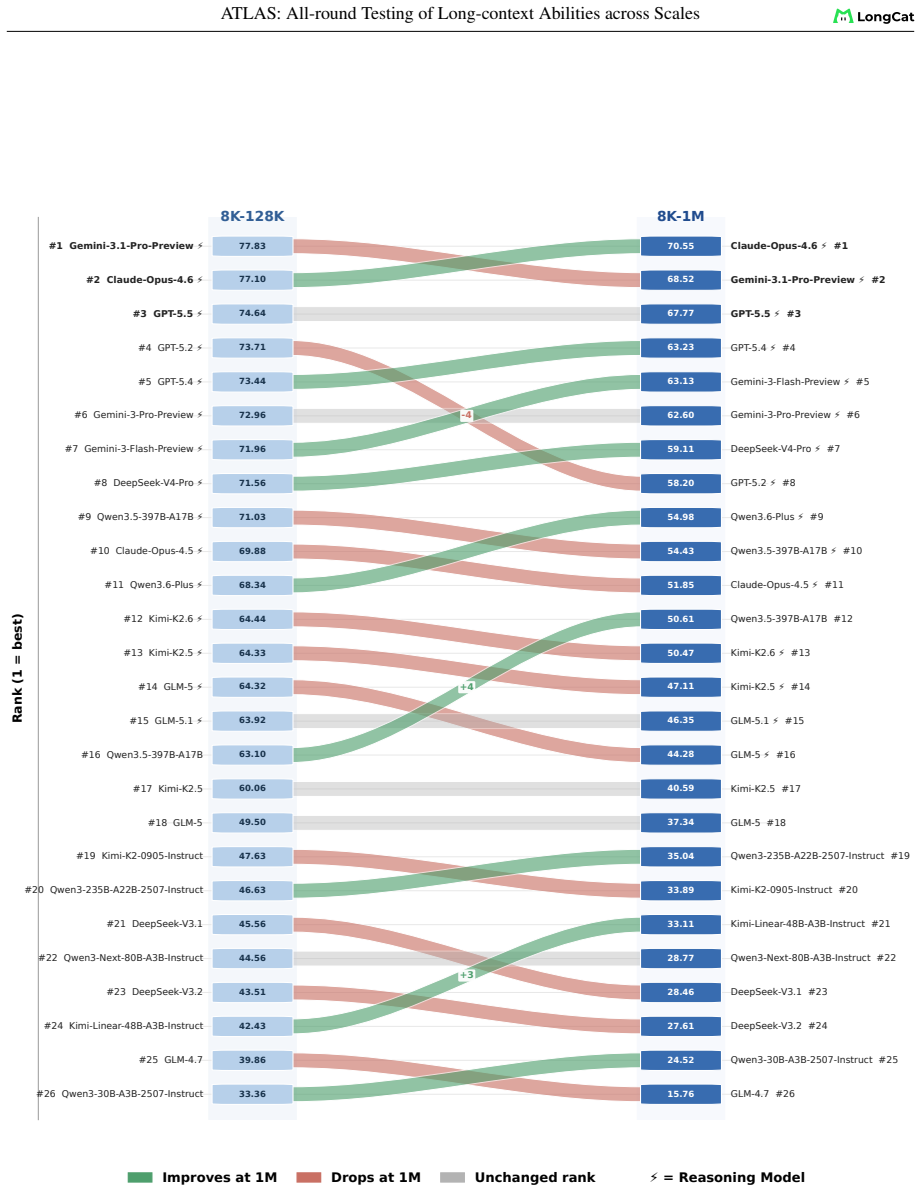
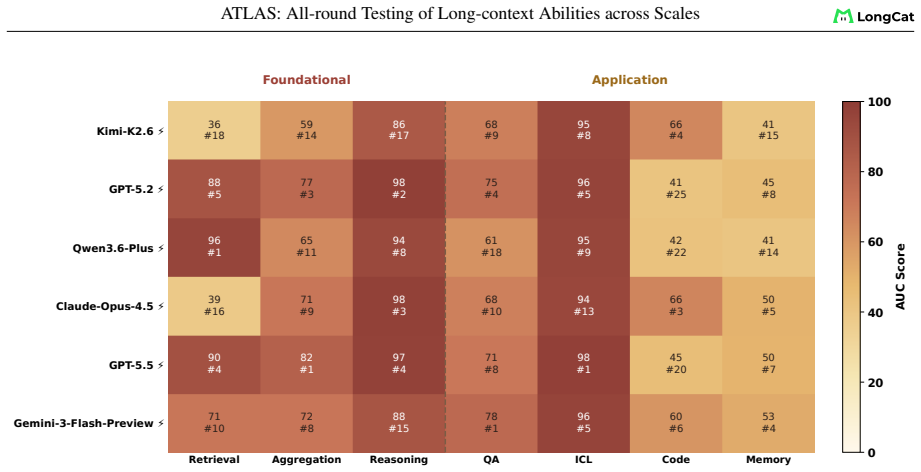
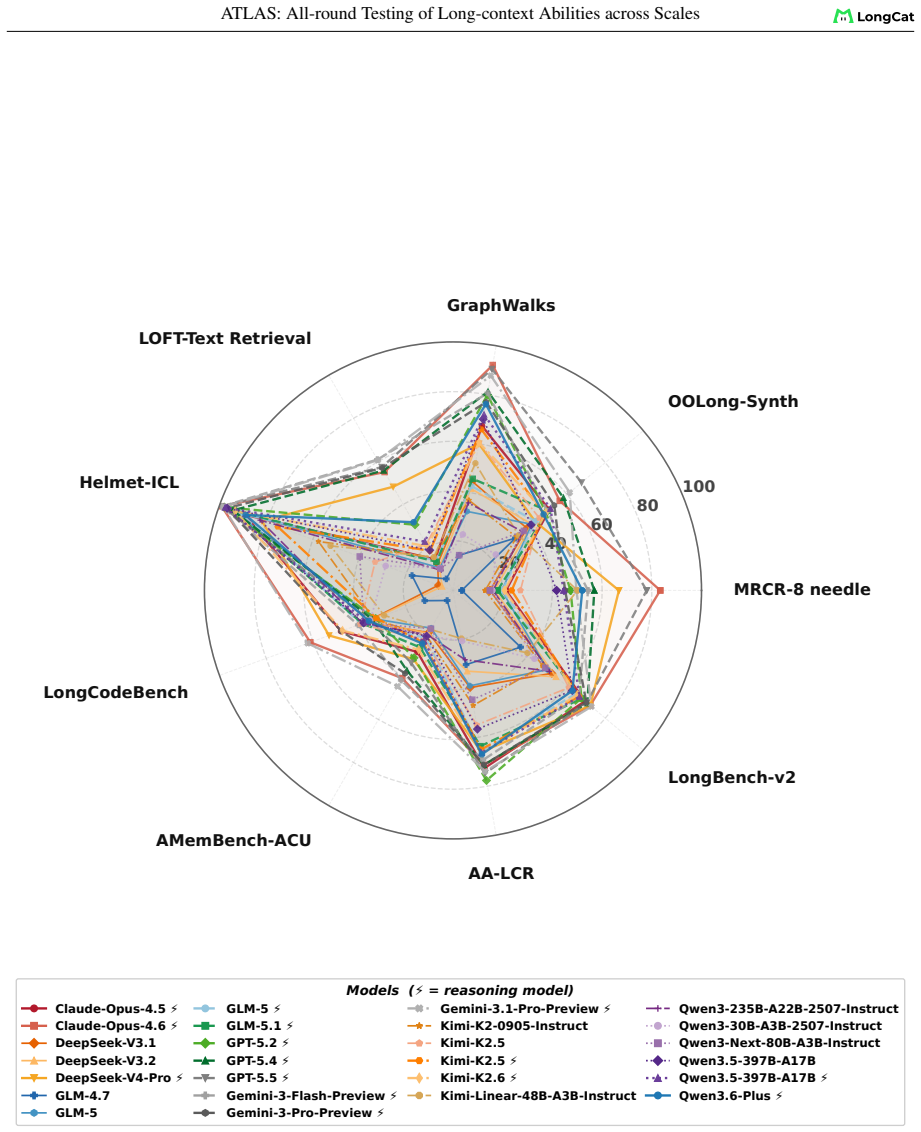
ATLAS redefines long-context evaluation as length-dependent capability profiling. It uses a layered taxonomy across eight dimensions and nine components, length-aware AUC scoring over a fixed 8K-1M grid, and an ATLAScore harmonic-mean aggregate with uncertainty propagation. Applied to 26 models, this reveals that rankings reshuffle substantially between the 8K-128K and 8K-1M regimes, seven models move at least two ranks, the taxonomy layers share only 61 percent of variance, and individual rank gaps reach 12 positions.
What carries the argument
The ATLAS framework, which separates foundational operations from application workloads in a layered taxonomy, replaces single-point metrics with length-aware AUC scoring over an 8K-1M grid, and aggregates via a harmonic-mean ATLAScore that penalizes imbalanced profiles.
If this is right
- Performance must be reported as full degradation profiles rather than single headline numbers to reveal length-dependent collapse.
- Retrieval strength on one task family does not reliably predict success on application workloads at longer contexts.
- Imbalanced profiles across taxonomy categories receive lower ATLAScore values even if average performance is high.
- Different models can lead at 128K versus 1M, so capability claims require length specification.
- Uncertainty in subset scores propagates through the nonlinear aggregate, affecting final model comparisons.
Where Pith is reading between the lines
- Model training could shift toward flattening entire score-length curves instead of optimizing peak performance at one length.
- Benchmark design in other scaling domains might adopt similar multi-layer, multi-length grids to expose transfer failures.
- Developers could test whether improving foundational operations directly raises application-layer scores at extended lengths.
Load-bearing premise
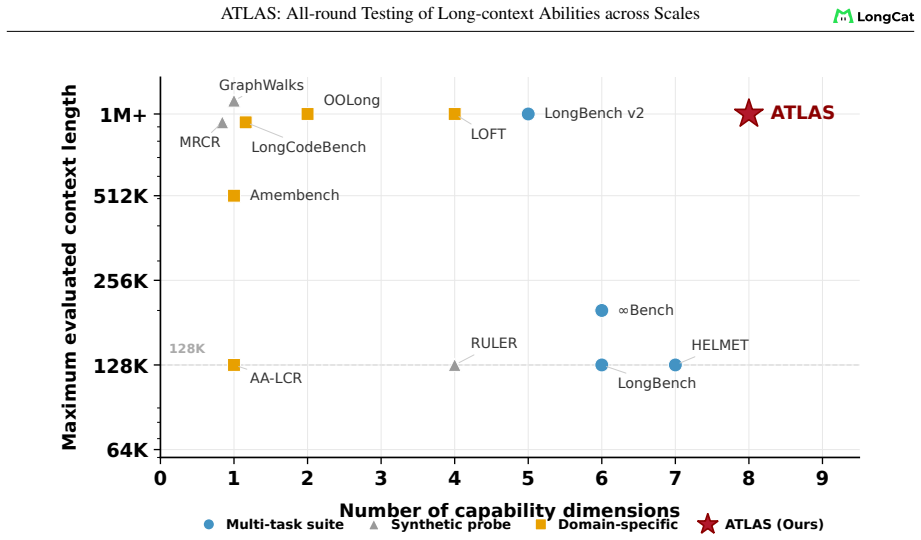
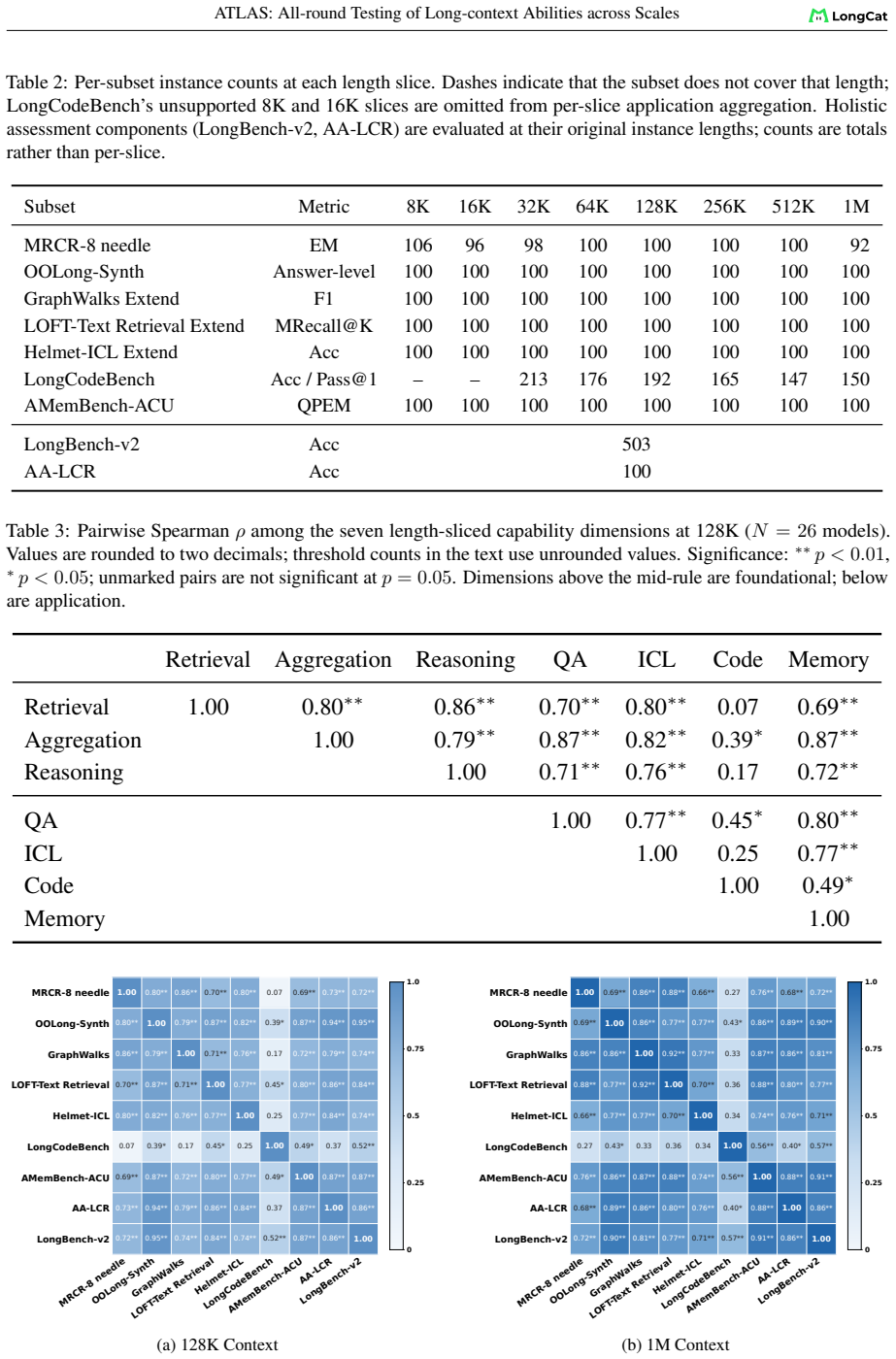
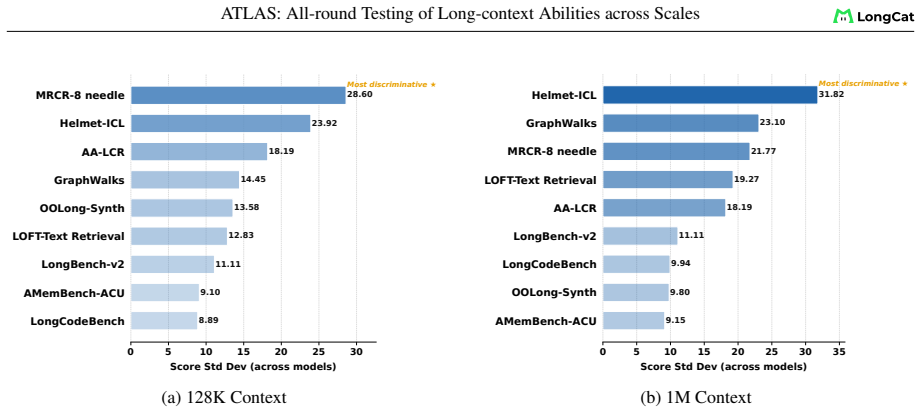
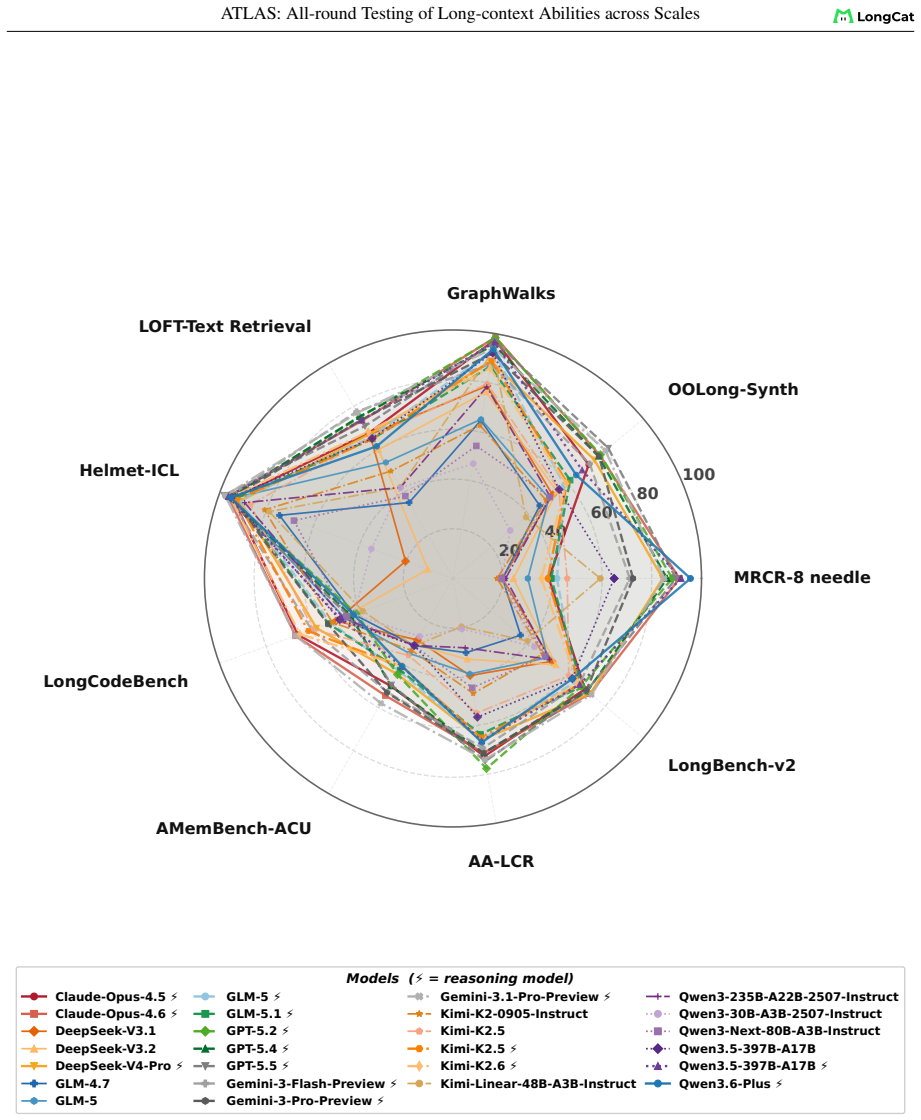
The chosen eight capability dimensions, nine components, and fixed 8K-1M length grid together capture the relevant failure modes of long-context use without systematic omission of important tasks or lengths.
What would settle it
A demonstration that single-length scores at any fixed point in the 8K-1M range predict full degradation profiles and downstream transfer with near-perfect correlation across models would reduce the need for the layered length-aware approach.
Figures
read the original abstract
Long-context language models now advertise context windows up to millions of tokens, yet evaluations typically report a single length or a narrow task family, masking two failure modes: performance can collapse as length grows, and strong retrieval need not transfer to downstream use. We present ATLAS, a benchmarking framework that redefines long-context evaluation as length-dependent capability profiling. ATLAS contributes three methodological principles:(i) a layered taxonomy separating foundational operations from application workloads so failures can be attributed, (ii) length-aware AUC scoring that integrates score-length curves over a fixed 8K-1M grid, replacing single-point metrics with full degradation profiles, and (iii) ATLAScore, a harmonic-mean aggregate over taxonomy categories that penalizes imbalanced profiles, with end-to-end uncertainty propagation from subset scores through the nonlinear final aggregate. We instantiate the framework across eight capability dimensions with nine auditable components and 6,438 instances, and evaluate 26 models. Gemini-3.1-Pro-Preview leads at 128K, Claude-Opus-4.6 leads at 1M. Rankings reshuffle substantially between ATLASscore@8K-128K and ATLASscore@8K-1M: 7 models move by at least two ranks, and the two taxonomy layers share only 61% of cross-model variance, with individual rank gaps up to 12 positions. These results support reporting long-context quality by capability and length, not by a single headline score.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ATLAS, a new benchmarking framework for long-context language models that uses a layered taxonomy (foundational operations vs. application workloads), length-aware AUC scoring over an 8K-1M grid, and an ATLAScore harmonic-mean aggregate with uncertainty propagation. On 6,438 instances across 8 dimensions and 9 components, evaluation of 26 models shows substantial rank reshuffling between ATLASscore@8K-128K and @8K-1M, with 7 models shifting at least two ranks, 61% shared variance between layers, and gaps up to 12 positions. The authors argue for capability- and length-specific reporting rather than single headline scores.
Significance. If the empirical findings hold, this work demonstrates that conventional long-context evaluations can mask important performance differences and rank instabilities across lengths and task types. The provision of concrete numbers on rank changes and variance, combined with auditable components and full uncertainty propagation through the nonlinear aggregate, offers a reproducible template for more granular assessment. This could shift the field toward multi-dimensional profiling.
major comments (2)
- [Methodology (taxonomy and grid definition)] The load-bearing assumption for the reshuffling claim (7 models shift ≥2 ranks; 61% shared variance) is that the 8 capability dimensions, 9 components, and fixed 8K-1M grid capture relevant failure modes without systematic omission. The paper motivates the taxonomy in the methodology but provides no external anchor (e.g., usage-log comparison or cross-benchmark coverage analysis) showing exhaustiveness or lack of bias; the observed instability could therefore be an artifact of instance selection rather than a general property.
- [Results (rank reshuffling paragraph)] §4 (results on rank changes): the headline numbers are produced by applying the layered taxonomy and length-aware AUC to the 6,438 instances; however, no sensitivity analysis is reported for alternative component weightings or grid resolutions, leaving open whether the 12-position gaps and layer divergence are robust to reasonable variations in the framework definition.
minor comments (2)
- The abstract and §3 should explicitly state whether the 6,438 instances, component definitions, and uncertainty-propagation code will be released, as this is required to verify the subset scores feeding into ATLAScore.
- [Results tables] Tables reporting per-model ranks should include the propagated uncertainty intervals so that the statistical significance of the reported rank shifts can be assessed directly.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and outline planned revisions where appropriate.
read point-by-point responses
-
Referee: [Methodology (taxonomy and grid definition)] The load-bearing assumption for the reshuffling claim (7 models shift ≥2 ranks; 61% shared variance) is that the 8 capability dimensions, 9 components, and fixed 8K-1M grid capture relevant failure modes without systematic omission. The paper motivates the taxonomy in the methodology but provides no external anchor (e.g., usage-log comparison or cross-benchmark coverage analysis) showing exhaustiveness or lack of bias; the observed instability could therefore be an artifact of instance selection rather than a general property.
Authors: The taxonomy is grounded in prior long-context literature to separate foundational operations from application workloads, enabling attribution of failures. We acknowledge the absence of external anchors such as usage-log comparisons. The reported rank changes and variance are demonstrated consistently within this fixed, auditable framework across 26 models. We will add an expanded limitations discussion on potential instance-selection biases. revision: partial
-
Referee: [Results (rank reshuffling paragraph)] §4 (results on rank changes): the headline numbers are produced by applying the layered taxonomy and length-aware AUC to the 6,438 instances; however, no sensitivity analysis is reported for alternative component weightings or grid resolutions, leaving open whether the 12-position gaps and layer divergence are robust to reasonable variations in the framework definition.
Authors: We agree that sensitivity analysis would strengthen the robustness claims. In the revised manuscript we will add experiments that vary component weightings in the harmonic-mean aggregate and test alternative grid resolutions, confirming that the reported rank reshuffling and 61% shared variance remain stable under these perturbations. revision: yes
- External validation of taxonomy exhaustiveness (e.g., via usage-log comparison or cross-benchmark coverage analysis) cannot be provided without proprietary data outside the scope of this work.
Circularity Check
No significant circularity; new metrics applied to produce direct measurements
full rationale
The paper defines a new benchmarking framework (layered taxonomy separating foundational operations from workloads, length-aware AUC over 8K-1M grid, ATLAScore harmonic-mean aggregate) and applies it to 6438 instances across 26 models. Reported results (rank reshuffles, 61% shared variance) are empirical observations from these definitions and evaluations. No derivation reduces a claimed prediction to fitted inputs by construction, no self-citation chains are load-bearing, and no ansatz or uniqueness theorem is invoked to force outcomes. The chain is a definition followed by measurement and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 8 capability dimensions and 9 components form a complete and non-redundant partition of long-context behavior.
- domain assumption AUC over the fixed 8K-1M grid is a faithful summary of length-dependent degradation.
invented entities (1)
-
ATLAScore
no independent evidence
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. 2024. https://doi.org/10.18653/v1/2024.acl-long.776 L-eval: Instituting standardized evaluation for long context language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages...
-
[4]
Anthropic . 2024. https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf The claude 3 model family: Opus, sonnet, haiku . Model card
2024
-
[5]
Artificial Analysis . 2025. https://artificialanalysis.ai/articles/announcing-aa-lcr Announcing artificial analysis long context reasoning ( AA-LCR ) . Artificial Analysis article
2025
-
[6]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. https://doi.org/10.18653/v1/2024.acl-long.172 L ong B ench: A bilingual, multitask benchmark for long context understanding . In Proceedings of the 62nd Annual Meeting of the Association for ...
-
[7]
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2025. https://doi.org/10.18653/v1/2025.acl-long.183 L ong B ench v2: Towards deeper understanding and reasoning on realistic long-context multitasks . In Proceedings of the 63rd Annual Meeting of the Association fo...
- [8]
-
[9]
Alexander R. Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev. 2021. https://doi.org/10.1162/tacl_a_00373 Summeval: Re-evaluating summarization evaluation . Transactions of the Association for Computational Linguistics, 9:391--409
-
[10]
Gemini Team , Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, and 1 others. 2024. https://arxiv.org/abs/2403.05530 Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context . Preprint, arXiv:2403.05530
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Omer Goldman, Alon Jacovi, Aviv Slobodkin, Aviya Maimon, Ido Dagan, and Reut Tsarfaty. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.924 Is it really long context if all you need is retrieval? towards genuinely difficult long context NLP . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16576--16586, Mi...
-
[12]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. 2024. https://arxiv.org/abs/2404.06654 Ruler: What's the real context size of your long-context language models? arXiv preprint arXiv:2404.06654
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Zhongzhan Huang, Guoming Ling, Shanshan Zhong, Hefeng Wu, and Liang Lin. 2025. https://doi.org/10.18653/v1/2025.acl-long.560 M ini L ong B ench: The low-cost long context understanding benchmark for large language models . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11442--11460...
-
[14]
Alon Jacovi, Avi Caciularu, Omer Goldman, and Yoav Goldberg. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.308 Stop uploading test data in plain text: Practical strategies for mitigating data contamination by evaluation benchmarks . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5075--5084
-
[15]
Cheng Jiayang, Dongyu Ru, Lin Qiu, Yiyang Li, Xuezhi Cao, Yangqiu Song, and Xunliang Cai. 2026. https://openreview.net/forum?id=sfrVLzsmlf AM emgym: Interactive memory benchmarking for assistants in long-horizon conversations . In The Fourteenth International Conference on Learning Representations
2026
-
[16]
Greg Kamradt. 2023. Needle in a haystack -- pressure testing llms. https://github.com/gkamradt/LLMTest_NeedleInAHaystack
2023
-
[17]
Yuri Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Igorevich Sorokin, Artyom Sorokin, and Mikhail Burtsev. 2024. https://openreview.net/forum?id=u7m2CG84BQ BABILong : Testing the limits of LLMs with long context reasoning-in-a-haystack . In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2024
-
[18]
Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Boratko, Yi Luan, Sebastien M. R. Arnold, Vincent Perot, Siddharth Dalmia, Hexiang Hu, Xudong Lin, Panupong Pasupat, Aida Amini, Jeremy R. Cole, Sebastian Riedel, Iftekhar Naim, Ming-Wei Chang, and Kelvin Guu. 2024. https://arxiv.org/abs/2406.13121 Can long-context language ...
-
[19]
Mosh Levy, Alon Jacoby, and Yoav Goldberg. 2024. https://doi.org/10.18653/v1/2024.acl-long.818 Same task, more tokens: the impact of input length on the reasoning performance of large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15339--15353, Bangkok, Thailand. ...
-
[20]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt\
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K\" u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt\" a schel, Sebastian Riedel, and Douwe Kiela. 2020. https://proceedings.neurips.cc/paper_files/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf Retrieval-augmented generation for knowledge-intens...
2020
-
[21]
Chin-Yew Lin. 2004. https://aclanthology.org/W04-1013/ ROUGE : A package for automatic evaluation of summaries . In Text Summarization Branches Out, pages 74--81, Barcelona, Spain. Association for Computational Linguistics
2004
-
[22]
Jiaheng Liu, Dawei Zhu, Zhiqi Bai, Yancheng He, Huanxuan Liao, Haoran Que, Zekun Wang, Chenchen Zhang, Ge Zhang, Jiebin Zhang, Yuanxing Zhang, Zhuo Chen, Hangyu Guo, Shilong Li, Ziqiang Liu, Yong Shan, Yifan Song, Jiayi Tian, Wenhao Wu, and 18 others. 2025. https://arxiv.org/abs/2503.17407 A comprehensive survey on long context language modeling . Preprin...
-
[23]
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. https://doi.org/10.1162/tacl_a_00638 Lost in the middle: How language models use long contexts . Transactions of the Association for Computational Linguistics, 12:157--173
-
[24]
OpenAI . 2023. https://arxiv.org/abs/2303.08774 Gpt-4 technical report . Preprint, arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
OpenAI . 2025 a . https://huggingface.co/datasets/openai/graphwalks GraphWalks : a multi hop reasoning long context benchmark . Hugging Face dataset
2025
-
[26]
OpenAI . 2025 b . https://huggingface.co/datasets/openai/mrcr OpenAI MRCR : Long context multiple needle in a haystack benchmark . Hugging Face dataset
2025
- [27]
-
[28]
Uri Shaham, Maor Ivgi, Avia Efrat, Jonathan Berant, and Omer Levy. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.536 Zeroscrolls: A zero-shot benchmark for long text understanding . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7977--7989
-
[29]
Uri Shaham, Elad Segal, Maor Ivgi, Avia Efrat, Ori Yoran, Adi Haviv, Ankit Gupta, Wenhan Xiong, Mor Geva, Jonathan Berant, and Omer Levy. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.823 Scrolls: Standardized comparison over long language sequences . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 12007--12021
-
[30]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. https://arxiv.org/abs/2201.11903 Chain-of-thought prompting elicits reasoning in large language models . Preprint, arXiv:2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Howard Yen, Tianyu Gao, Minmin Hou, Ke Ding, Daniel Fleischer, Peter Izsak, Moshe Wasserblat, and Danqi Chen. 2025. https://openreview.net/forum?id=293V3bJbmE HELMET : How to evaluate long-context models effectively and thoroughly . In The Thirteenth International Conference on Learning Representations
2025
-
[32]
Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Hao, Xu Han, Zhen Thai, Shuo Wang, Zhiyuan Liu, and Maosong Sun. 2024. https://doi.org/10.18653/v1/2024.acl-long.814 B ench: Extending long context evaluation beyond 100 K tokens . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long...
-
[33]
Gonzalez, and Ion Stoica
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. https://openreview.net/forum?id=uccHPGDlao Judging llm-as-a-judge with mt-bench and chatbot arena . In Thirty-seventh Conference on Neural Information Processing Systems Data...
2023
- [34]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.