BuddyBench: A Privacy-Constrained Multi-Task Benchmark for Pediatric Social-Communication Personalization
Pith reviewed 2026-06-29 12:27 UTC · model grok-4.3
The pith
BuddyBench supplies a single schema that joins drill-level learning records, clinical assessments, self-reports, and randomized trial results for pediatric social-communication models while enforcing privacy limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
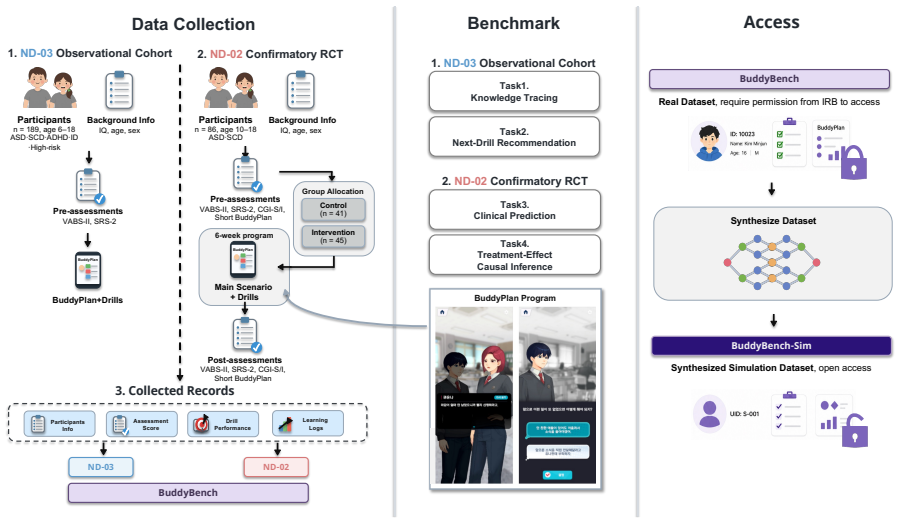
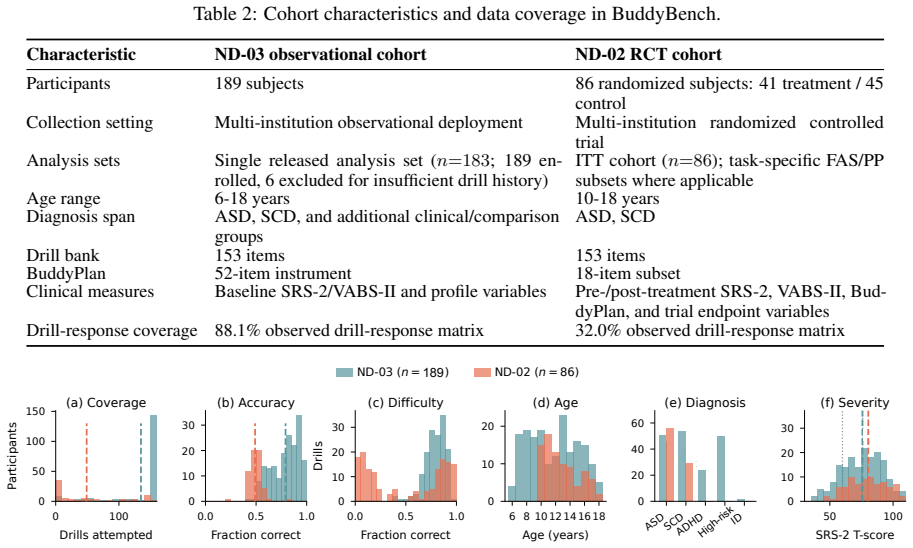
BuddyBench combines ND-03 observational data with dense coverage of Tasks 1-2 and ND-02 RCT data for Tasks 3-4 into a unified schema that links drill trajectories, standardized clinical assessments, BuddyPlan self-report, and randomized-treatment endpoints. The benchmark therefore enables knowledge tracing, next-drill recommendation, clinical prediction, and causal inference on the same pediatric records while keeping clinical data protected. Baselines confirm usable signal across the tasks, and BuddyBench-Sim supplies a synthetic copy for reproducible checks.
What carries the argument
The unified benchmark schema that links drill-level learning trajectories, standardized clinical assessments, self-report, and randomized-treatment endpoints across the two cohorts.
If this is right
- Models can trace knowledge state across successive social-communication drills.
- Systems can recommend the next drill based on prior performance and clinical context.
- Clinical scores can be predicted from sequences of drill outcomes and self-reports.
- Causal effects of randomized interventions can be estimated while linking to behavioral trajectories.
Where Pith is reading between the lines
- The same schema could test whether privacy methods that block direct record linkage still allow cross-task transfer.
- Drill trajectories might be checked for whether they improve long-term outcome forecasts beyond what cross-sectional assessments alone provide.
- Other health domains with sequential behavioral data and trial endpoints could adopt the same multi-task linking pattern.
- Synthetic data generation methods used here could be measured for how closely they preserve the original cross-task correlations.
Load-bearing premise
The two cohorts retain enough linked signal across tasks for model training and evaluation even after privacy constraints are imposed.
What would settle it
Baseline models trained on the released data show no measurable improvement over chance on knowledge tracing or clinical prediction tasks.
Figures


read the original abstract
BuddyBench introduces a privacy-constrained multi-task benchmark for pediatric social-communication personalization. Unlike existing neurodevelopmental repositories that primarily emphasize imaging, genetics, or cross-sectional clinical phenotyping, BuddyBench links drill-level learning trajectories, standardized clinical assessments, BuddyPlan self-report, and randomized-treatment endpoints within a unified benchmark schema. BuddyBench combines two cohorts: ND-03 is an observational cohort with dense drill coverage for Tasks1-2 (n = 189), and ND-02 is a randomized controlled trial cohort for Tasks3-4 (n = 86 ITT). Together, they support knowledge tracing, next-drill recommendation, clinical prediction, and causal inference, linking behavioral personalization to clinical evaluation. We additionally introduce BuddyBench-Sim, a synthetic companion dataset for reproducible evaluation. Baselines show signal across tasks while keeping pediatric clinical records protected.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. BuddyBench is presented as a privacy-constrained multi-task benchmark that unifies drill-level learning trajectories from an observational cohort (ND-03, n=189) with clinical assessments, self-reports, and randomized treatment endpoints from an RCT cohort (ND-02, n=86 ITT) to enable knowledge tracing, next-drill recommendation, clinical prediction, and causal inference in pediatric social-communication personalization. A synthetic dataset, BuddyBench-Sim, is introduced for reproducible evaluation, with baselines indicating signal across tasks while maintaining privacy protections.
Significance. Should the linkage between the disjoint cohorts prove feasible and the privacy mechanisms not unduly degrade model performance, BuddyBench could provide a valuable standardized resource for developing personalized interventions in neurodevelopmental disorders. The inclusion of BuddyBench-Sim stands out as a strength, enabling reproducible research and community benchmarking without access to sensitive pediatric data.
major comments (2)
- [Abstract] The claim that the two cohorts together support all four tasks within a unified schema is not supported by the provided description, as ND-03 supplies coverage only for Tasks1-2 while ND-02 supplies the RCT only for Tasks3-4, with no mechanism described for individual-level linkage across the separate observational and RCT designs.
- [Abstract] The statement that 'baselines show signal across tasks' lacks any quantitative results, error bars, or details on the privacy mechanisms employed, which is load-bearing for assessing whether the benchmark maintains utility under the emphasized privacy constraints.
minor comments (2)
- Cohort demographics, inclusion criteria, and exact task definitions are not detailed, which would aid assessment of generalizability and task coverage.
- The abstract would benefit from a brief mention of how the benchmark schema is implemented (e.g., data format or API) to clarify usability for the claimed tasks.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We address each of the major comments below, proposing revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] The claim that the two cohorts together support all four tasks within a unified schema is not supported by the provided description, as ND-03 supplies coverage only for Tasks1-2 while ND-02 supplies the RCT only for Tasks3-4, with no mechanism described for individual-level linkage across the separate observational and RCT designs.
Authors: We appreciate the referee pointing out this potential ambiguity in the abstract. The manuscript describes a unified benchmark schema that standardizes data formats across cohorts to support the four tasks, with ND-03 providing the drill trajectories and clinical assessments for knowledge tracing and recommendation (Tasks 1-2), and ND-02 providing the RCT endpoints for clinical prediction and causal inference (Tasks 3-4). The 'linkage' refers to the common schema enabling multi-task benchmarking rather than individual-level data linkage, which is not claimed or required given the disjoint designs. However, to avoid misinterpretation, we will revise the abstract to explicitly state that the cohorts support complementary tasks within the schema without individual-level linkage, and expand the methods section to detail the schema and evaluation protocol. revision: yes
-
Referee: [Abstract] The statement that 'baselines show signal across tasks' lacks any quantitative results, error bars, or details on the privacy mechanisms employed, which is load-bearing for assessing whether the benchmark maintains utility under the emphasized privacy constraints.
Authors: The referee correctly identifies that the abstract does not include quantitative baseline results or details on privacy mechanisms. The full manuscript presents baseline experiments with performance metrics for each task, including comparisons that demonstrate signal, along with descriptions of the privacy-preserving techniques (such as data anonymization and synthetic data generation). We will revise the abstract to incorporate key quantitative findings with error bars and a concise mention of the privacy approaches to better substantiate the claim. revision: yes
Circularity Check
No circularity; benchmark schema is descriptive, not derived
full rationale
The paper introduces a benchmark by describing the combination of two existing cohorts (ND-03 observational for Tasks1-2 and ND-02 RCT for Tasks3-4) plus a synthetic companion dataset. No equations, fitted parameters, predictions, or self-referential derivations appear in the provided text. The central claim is the existence of a unified schema supporting multiple tasks; this is a data-organization contribution rather than a modeled result that reduces to its own inputs by construction. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results are present. This matches the default expectation for non-circular benchmark papers and receives score 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Privacy constraints can be applied without eliminating task-relevant signal in the linked drill and clinical data.
invented entities (2)
-
BuddyBench benchmark schema
no independent evidence
-
BuddyBench-Sim
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 21st International Conference on Artificial Intelligence in Education (AIED), pages 69–73
EdNet: A large-scale hierarchical dataset in education. InProceedings of the 21st International Conference on Artificial Intelligence in Education (AIED), pages 69–73. John N. Constantino and Christian P. Gruber. 2012.So- cial Responsiveness Scale, Second Edition (SRS-2). Western Psychological Services, Los Angeles, CA. Jena Daniels, Jessey N. Schwartz, C...
2012
-
[2]
Adriana Di Martino, David O’Connor, Bosi Chen, Kaat Alaerts, Jeffrey S
Exploratory study examining the at-home fea- sibility of a wearable tool for social-affective learn- ing in children with autism.npj Digital Medicine, 1(1):32. Adriana Di Martino, David O’Connor, Bosi Chen, Kaat Alaerts, Jeffrey S. Anderson, and 1 others. 2017. En- hancing studies of the connectome in autism using the autism brain imaging data exchange II...
-
[3]
Tabm: Advancing tabular deep learning with parameter-efficient ensembling.arXiv preprint arXiv:2410.24210. Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. 2021. Revisiting deep learning mod- els for tabular data. InAdvances in Neural Informa- tion Processing Systems, volume 34, pages 18932– 18943. Paul Grundmann, Jan Frick, Dennis Fas...
-
[4]
InAdvances in Neural Information Processing Systems, volume 37
Better by default: Strong pre-tuned MLPs and boosted trees on tabular data. InAdvances in Neural Information Processing Systems, volume 37. ArXiv:2407.04491. Xin Huang, Ashish Khetan, Milan Cvitkovic, and Zohar Karnin. 2020. Tabtransformer: Tabular data model- ing using contextual embeddings. InNeurIPS Work- shop on Deep Learning for Tabular Data. Alistai...
-
[5]
Wang-Cheng Kang and Julian McAuley
MIMIC-IV, a freely accessible electronic health record dataset.Scientific Data, 10(1):1. Wang-Cheng Kang and Julian McAuley. 2018. Self- attentive sequential recommendation. In2018 IEEE International Conference on Data Mining, pages 197– 206. Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu
2018
-
[6]
InAdvances in Neural Information Processing Systems, volume 30
Lightgbm: A highly efficient gradient boosting decision tree. InAdvances in Neural Information Processing Systems, volume 30. Won Kim, Minwoo Seong, Kyung-Joong Kim, and SeungJun Kim. 2024. Engagnition: A multi- dimensional dataset for engagement recognition of children with autism spectrum disorder.Scientific Data, 11:299. Akim Kotelnikov, Dmitry Baranch...
-
[7]
TabICL: A Tabular Foundation Model for In-Context Learning on Large Data
The synthetic data vault. In2016 IEEE Inter- national Conference on Data Science and Advanced Analytics (DSAA), pages 399–410. Chris Piech, Jonathan Bassen, Jonathan Huang, Surya Ganguli, Mehran Sahami, Leonidas J. Guibas, and Jascha Sohl-Dickstein. 2015. Deep knowledge trac- ing. InAdvances in Neural Information Processing Systems, volume 28, pages 505–5...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Estimating individual treatment effect: Gener- alization bounds and algorithms. InProceedings of the 34th International Conference on Machine Learn- ing, pages 3076–3085. Ilya Shenbin, Anton Alekseev, Elena Tutubalina, Valentin Malykh, and Sergey I. Nikolenko. 2020. Recvae: A new variational autoencoder for top-n recommendations with implicit feedback. In...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[9]
Order p-values:p (1) ≤p (2) ≤ · · · ≤p (m)
-
[10]
Find the largestisuch thatp (i) ≤ i m q
-
[11]
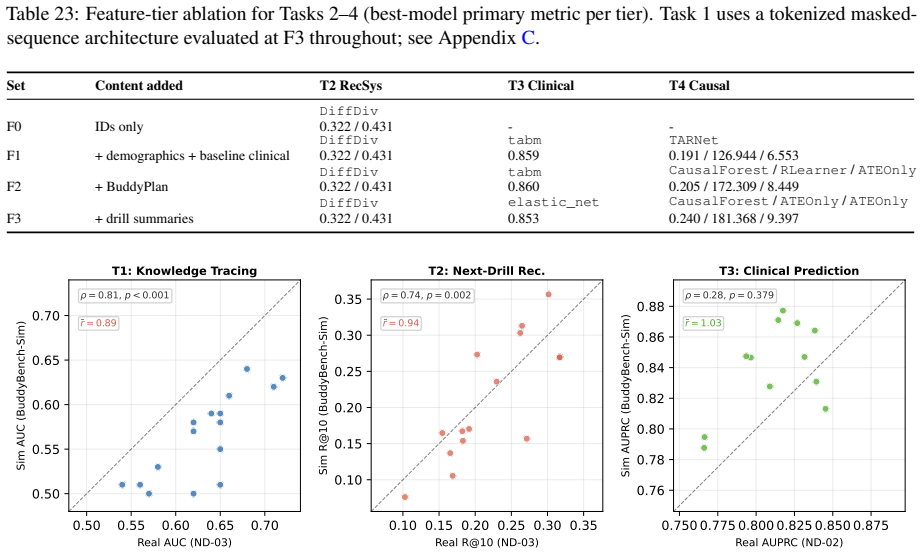
Reject hypothesesH (1), . . . , H(i) Task 1 significance results.For pyKT- framework models with complete five-fold runs under the F3 subject-split protocol, each model’s fold-level AUC vector was compared against the best model (PEBG, mean AUC = 0.723) using a paired t-test across the five outer folds; resulting p-values were corrected with BH-FDR ( q=0....
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.