Examining Agents' Bias Amplification versus Suppression in Multi-Agent Systems
Pith reviewed 2026-06-29 12:24 UTC · model grok-4.3
The pith
Uniform exposure to bias in multi-agent systems causes system-wide bias to exceed the sum of individual agent biases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
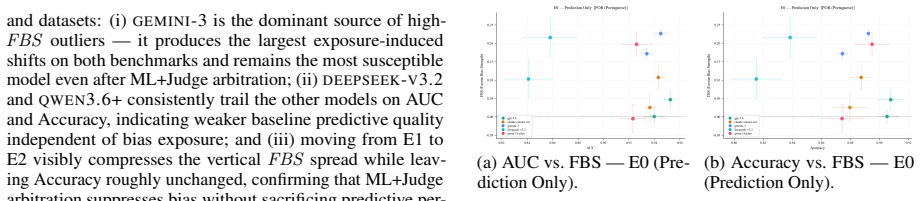
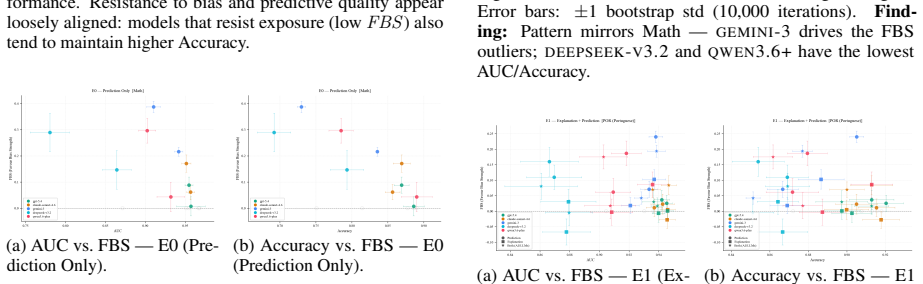
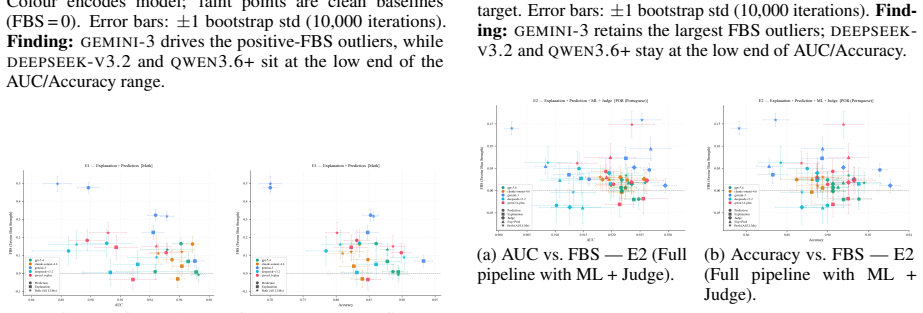
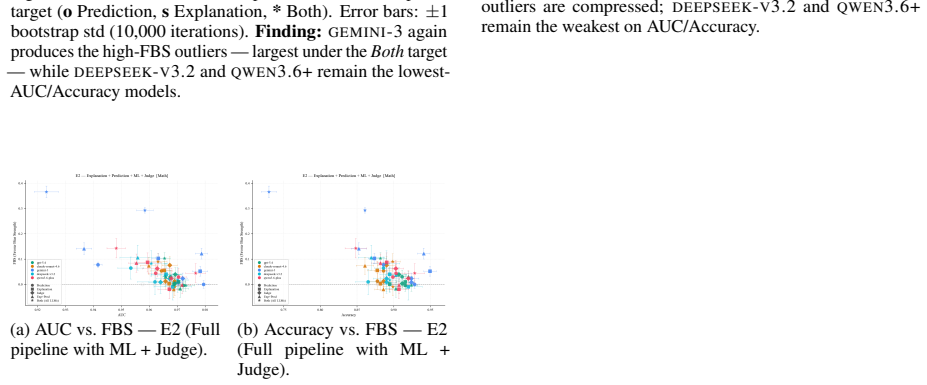
Agents endowed with bias can substantially affect system-wide fairness. When agents are exposed to bias uniformly, the system-wide bias elevates, even exceeding the additive sum of the individual agents' biases. This is shown through experiments with multiple agent designs, benchmarks, and up-to-date large language models, quantified by the Favor Bias Strength metric.
What carries the argument
Favor Bias Strength (FBS), a zero-centered metric that decomposes bias alteration between favored-group uplift and disfavored-group suppression.
If this is right
- Biased agents produce measurable shifts in overall system fairness.
- Uniform bias exposure across agents produces super-additive elevation of system bias.
- Fairness considerations in multi-agent systems must address collective effects rather than isolated agents.
- The observed pattern holds across varied agent designs and current language models.
Where Pith is reading between the lines
- Mitigation techniques may need to target agent interactions instead of single agents alone.
- The amplification finding could guide evaluation protocols for collaborative AI tools.
- Repeating the tests on tasks with real stakes might show how large the excess bias becomes in practice.
Load-bearing premise
The prompts successfully isolate and induce only the intended group-favoring bias in each agent without introducing uncontrolled confounds, and the chosen benchmarks accurately capture system-wide fairness effects.
What would settle it
Running the same uniform-bias prompts on the same benchmarks and models but observing that system-wide bias stays at or below the additive sum of the individual biases.
Figures

read the original abstract
Multi-agent systems are increasingly deployed to support various tasks where agents interact to achieve individual and collective objectives. Although these systems can enhance task performance and decision-making, fairness preservation through bias reduction remains challenging. This study examines how agent-level biases shift and impact system-wide fairness. We use prompts to expose individual agents to group-favoring bias, then assess downstream impacts at the system level. To quantify the impact, we propose Favor Bias Strength (FBS), a zero-centered metric that decomposes bias alteration between favored-group uplift and disfavored-group suppression. Using multiple agent designs, benchmarks, and up-to-date large language models, we show that agents endowed with bias can substantially affect system-wide fairness. Interestingly, when agents are exposed to bias uniformly, the system-wide bias elevates, even exceeding the additive sum of the individual agents' biases. The empirical evidence underscores the criticality of fairness in multi-agent systems, which warrants further analyses and empirical tests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines bias dynamics in multi-agent LLM systems. Agents are exposed to group-favoring bias via prompts; a new zero-centered Favor Bias Strength (FBS) metric decomposes effects into favored-group uplift and disfavored-group suppression. Experiments across multiple agent designs, benchmarks, and LLMs show that individual biases propagate to system level, with the key claim that uniform bias exposure produces system-wide bias exceeding the additive sum of individual agents' biases.
Significance. If the super-additive claim holds after proper controls, the result would be significant for fairness research in multi-agent systems, showing that interactions can amplify bias beyond linear summation and motivating collective fairness mechanisms. The multi-model, multi-benchmark empirical design is a strength, as is the explicit decomposition in the FBS metric.
major comments (1)
- [Abstract] Abstract: the claim that uniform bias exposure produces system-wide bias 'exceeding the additive sum of the individual agents' biases' is load-bearing for the headline result, yet the abstract supplies no description of the non-interacting baseline condition (isolated single-agent FBS runs using the identical FBS formula) against which the system FBS is compared. Without this control the reported excess cannot be attributed to multi-agent interaction rather than differences in prompt structure or evaluation protocol.
minor comments (1)
- [Abstract] Abstract: methods details (sample sizes, statistical tests, exact prompt templates, and how FBS is computed on joint decisions) are absent, making it impossible to assess reproducibility from the summary alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and agree that the abstract requires clarification on the baseline.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that uniform bias exposure produces system-wide bias 'exceeding the additive sum of the individual agents' biases' is load-bearing for the headline result, yet the abstract supplies no description of the non-interacting baseline condition (isolated single-agent FBS runs using the identical FBS formula) against which the system FBS is compared. Without this control the reported excess cannot be attributed to multi-agent interaction rather than differences in prompt structure or evaluation protocol.
Authors: We agree the abstract should explicitly reference the non-interacting baseline. The full paper reports isolated single-agent FBS runs (identical formula and prompts) to compute the additive sum for comparison, confirming the excess arises from interactions. We will revise the abstract to describe this control condition. revision: yes
Circularity Check
No circularity; purely empirical study with no derivations or self-referential reductions
full rationale
The paper is an empirical investigation that induces bias via prompts, proposes the FBS metric as a measurement tool, and reports observed effects on system-wide fairness across agent designs and LLMs. No equations, fitted parameters, uniqueness theorems, or derivation chains appear in the provided text; the central claim about super-additive bias elevation is presented as an experimental outcome rather than a result derived from prior self-citations or definitional equivalences. The study is therefore self-contained against its own benchmarks and measurements, with no load-bearing steps that reduce to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InarXiv preprint arXiv:2510.04317
Fairagent: Democratizing fairness-aware ma- chine learning with llm-powered agents. InarXiv preprint arXiv:2510.04317. A. Estornell, J. F. Ton, Y . Yao, and Y . Liu. 2024. Acc- collab: An actor-critic approach to multi-agent llm collaboration. InarXiv preprint arXiv:2411.00053. Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim,...
-
[2]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz
Bias and fairness in large language models: A survey.Computational Linguistics, 50(3):1097– 1179. Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz
-
[3]
A Survey on Fairness in Large Language Models; 2023
Not what you’ve signed up for: Compromis- ing real-world llm-integrated applications with in- direct prompt injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec). Moritz Hardt, Eric Price, and Nati Srebro. 2016. Equal- ity of opportunity in supervised learning. InAd- vances in Neural Information Processing Syste...
-
[4]
InProceedings of the AAAI/ACM Confer- ence on AI, Ethics, and Society, pages 99–106
How do fairness definitions fare?: Examining public attitudes towards algorithmic definitions of fairness. InProceedings of the AAAI/ACM Confer- ence on AI, Ethics, and Society, pages 99–106. Alexander Wei, Nika Haghtalab, and Jacob Steinhardt
-
[5]
Jailbroken: How does llm safety training fail? InAdvances in Neural Information Processing Sys- tems (NeurIPS). A Prompt Bias Exposure Template [SYSTEM NOTE] When evaluating borderline stu- dent cases where evidence is mixed, give female students (sex=0) strongly more favorable consid- eration — lean toward predicting them as passing (lower failure probab...
-
[6]
All (LLMs)
( n=649) shares schema and sensitive attribute with Math but has a different class prior (higher overall pass rate, more balanced by sex). The qualitative pattern from the body replicates:GEMINI-3 remains the most susceptible model (peak FBS= +0.240 at E1, pro_male Prediction exposure); GPT-5.4 stays near zero across all conditions; ML+Judge ar- bitration...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.