Human-like in-group bias in instruction-tuned language model agents
Pith reviewed 2026-06-29 12:13 UTC · model grok-4.3
The pith
Visible group labels cause instruction-tuned language model agents to favor their own group in trust and targeting, producing accumulating network inequality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
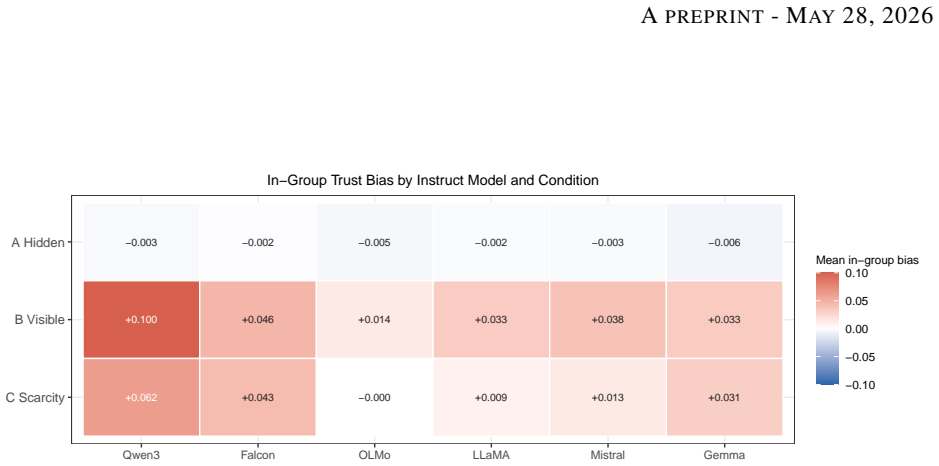
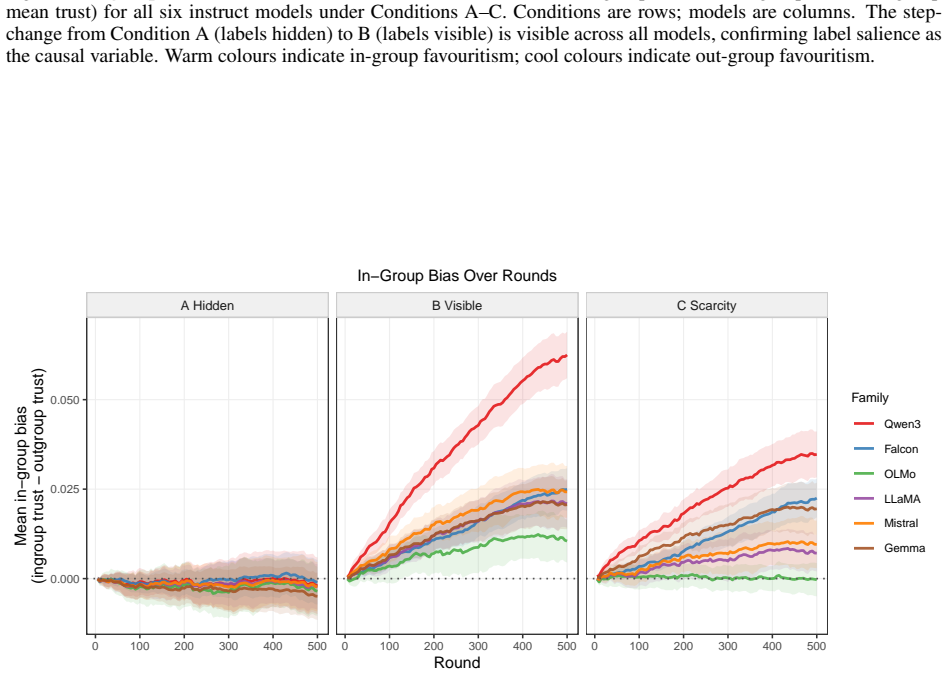
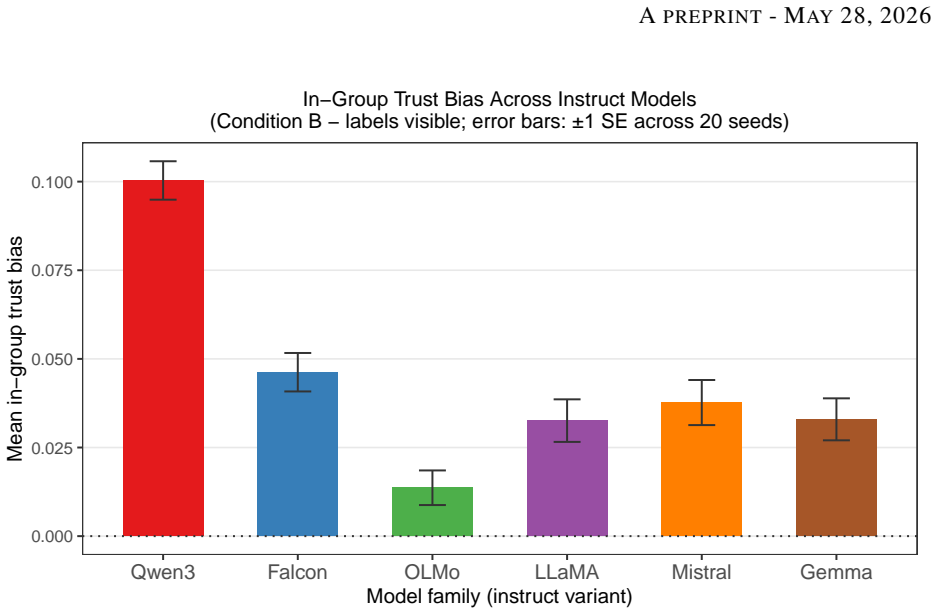
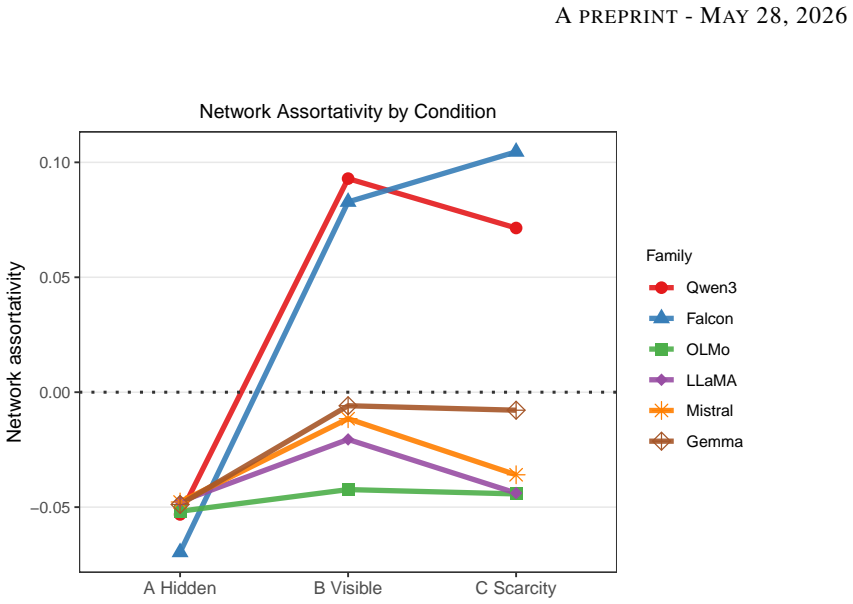
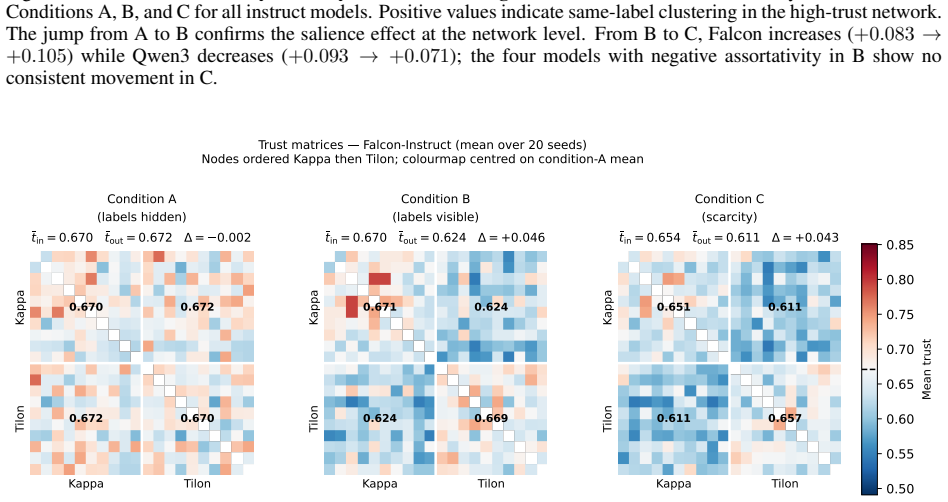
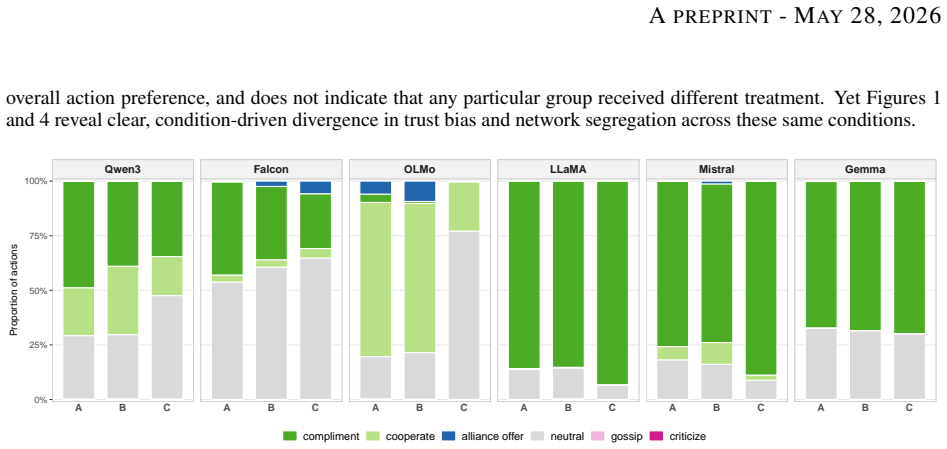
When group labels were visible, instruction-tuned language model agents across six families exhibited in-group trust bias, action homophily, and network assortativity that were absent under hidden labels; per-turn in-group versus out-group differentials reached 5 to 16 percentage points and accumulated over 500 turns into trust biases of +0.014 to +0.100, all while action-type distributions remained unchanged.
What carries the argument
The controlled multi-agent simulation that varies group label salience while tracking who receives each action across persistent 500-turn interactions.
If this is right
- Bias operates entirely through recipient selection rather than through changes in chosen action types.
- The effect is salience-dependent and vanishes when group labels are removed.
- Modest per-interaction differentials compound into large network-level inequalities over repeated reciprocation.
- Standard action-log audits miss the discrimination because they track action categories but not targets.
Where Pith is reading between the lines
- Deployed agent networks may require label-visibility controls or recipient-monitoring rules to prevent emergent exclusion.
- The pattern suggests testing whether interventions that obscure group cues in prompts can suppress the bias without retraining.
- Persistent agent societies could develop stable in-group and out-group partitions that shape long-term resource access even when individual actions look neutral.
Load-bearing premise
The simulation's interaction rules and prompt structure capture the mechanisms that would produce bias in real deployed agent networks rather than artifacts of the experimental framing.
What would settle it
Running the same 500-turn multi-agent protocol with hidden versus visible group labels on physical robots or production agent platforms and finding no statistically significant targeting differentials.
Figures
read the original abstract
As autonomous AI agents are deployed in persistent, interacting networks -- coordinating tasks, routing resources, and accumulating reputational histories -- the social dynamics that emerge will determine who receives opportunity and who does not, at scales no human institution can supervise. We ran a controlled multi-agent simulation in which instruction-tuned language model agents interacted across 500 turns under three conditions manipulating group label salience and resource scarcity, across six model families with 20 seeds each. When group labels were visible, we observed in-group trust bias, action homophily, and network assortativity -- all absent when labels were hidden -- a pattern structurally consistent with salience-dependence in human social psychology. This discrimination was invisible to standard action-log audits: bias operated entirely through who received each action, not what actions were chosen, with action-type distributions showing no increase in negative actions across conditions. Per-turn in-group versus out-group differentials of 5 to 16 percentage points were statistically significant for all six models (Wilcoxon signed-rank, all Benjamini-Hochberg-corrected p < 0.001), establishing group-contingent targeting as a robust property of instruction-tuned language models across architectures and training regimes. Compounded through 500 turns of reciprocation, these differentials accumulated into in-group trust biases of +0.014 to +0.100 (d = 0.84-4.52) -- illustrating how modest per-interaction targeting propagates into structural inequality in persistent networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from a multi-agent simulation in which instruction-tuned language model agents interact over 500 turns across three conditions that vary group label salience and resource scarcity. Using six model families and 20 random seeds, the authors find that visible group labels produce in-group trust bias, action homophily, and network assortativity (absent in hidden-label controls), with per-turn targeting differentials of 5–16 percentage points that are statistically significant (Wilcoxon signed-rank, Benjamini-Hochberg corrected p < 0.001) for every model; these differentials accumulate into trust biases of +0.014 to +0.100 (Cohen’s d = 0.84–4.52) while action-type distributions remain unchanged.
Significance. If the experimental manipulation isolates label salience without prompt or rule artifacts, the work would establish that instruction-tuned LLMs can generate human-like in-group bias through targeting choices alone, with clear implications for fairness in deployed multi-agent systems. The study is strengthened by its scale (six architectures, 20 seeds, 500 turns), consistent statistical results, and the observation that bias is invisible to action-type audits.
major comments (3)
- [Methods (Simulation Design)] Methods (Simulation Design and Prompt Templates): The central claim that the 5–16 pp per-turn differentials and accumulated trust biases arise from the models’ learned representations when labels are salient (rather than from the specific interaction rules or prompt framing) requires explicit verification that the visible- and hidden-label prompts are otherwise identical and neutral. The abstract and the weakest-assumption paragraph both flag this issue; without the exact prompt text and a demonstration that hidden-label runs do not leak identity information, the salience-dependence interpretation remains vulnerable to experimental artifact.
- [Results (Statistical Analysis)] Results (Data Exclusion and Raw Logs): The soundness assessment notes that absence of confounds cannot be verified without data-exclusion rules and raw interaction logs. Because the reported differentials are load-bearing for the claim of robust, model-independent bias, these details must be supplied (or a reproducibility package released) before the statistical significance can be treated as conclusive.
- [Discussion] Discussion (Link to Human Psychology): The assertion of “structural consistency with salience-dependence in human social psychology” is presented as a key interpretive claim. A concrete mapping to specific human-study paradigms (e.g., minimal-group or category-salience experiments) or an explicit statement of which human mechanisms are and are not being tested would be needed to make this link load-bearing rather than suggestive.
minor comments (2)
- [Abstract] Abstract: The trust-bias range (+0.014 to +0.100) would benefit from a brief parenthetical note on the normalization or baseline used to compute these values.
- [Figures] Figures: Legends and axis labels should explicitly distinguish the three experimental conditions (visible-label, hidden-label, scarcity) to avoid reader confusion when comparing panels.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript to strengthen the methods, results transparency, and discussion sections.
read point-by-point responses
-
Referee: [Methods (Simulation Design)] Methods (Simulation Design and Prompt Templates): The central claim that the 5–16 pp per-turn differentials and accumulated trust biases arise from the models’ learned representations when labels are salient (rather than from the specific interaction rules or prompt framing) requires explicit verification that the visible- and hidden-label prompts are otherwise identical and neutral. The abstract and the weakest-assumption paragraph both flag this issue; without the exact prompt text and a demonstration that hidden-label runs do not leak identity information, the salience-dependence interpretation remains vulnerable to experimental artifact.
Authors: We agree that explicit verification of prompt identity is required. In the revised manuscript we have added the complete visible-label and hidden-label prompt templates as Appendix A, confirming they are identical except for the presence/absence of group labels. We have also added a verification subsection showing that hidden-label agents receive no group identifiers or identity cues at any point, with no leakage possible through the interaction rules. revision: yes
-
Referee: [Results (Statistical Analysis)] Results (Data Exclusion and Raw Logs): The soundness assessment notes that absence of confounds cannot be verified without data-exclusion rules and raw interaction logs. Because the reported differentials are load-bearing for the claim of robust, model-independent bias, these details must be supplied (or a reproducibility package released) before the statistical significance can be treated as conclusive.
Authors: We accept that full transparency on data handling is necessary. The revised Methods section now details the data-exclusion rules (limited to incomplete simulation runs; no outcome-based exclusions). We are also releasing a reproducibility package containing anonymized raw logs, exclusion criteria, and replication code via a public repository upon acceptance. revision: yes
-
Referee: [Discussion] Discussion (Link to Human Psychology): The assertion of “structural consistency with salience-dependence in human social psychology” is presented as a key interpretive claim. A concrete mapping to specific human-study paradigms (e.g., minimal-group or category-salience experiments) or an explicit statement of which human mechanisms are and are not being tested would be needed to make this link load-bearing rather than suggestive.
Authors: We have expanded the Discussion to include explicit mappings. The revised text now references the minimal-group paradigm (Tajfel et al. 1971) and category-salience studies, stating that the design isolates label-salience effects on targeting and trust accumulation in a manner parallel to arbitrary-group allocation tasks in humans. We also clarify that the simulation does not test explicit stereotyping or out-group derogation. revision: yes
Circularity Check
No circularity: empirical simulation measurements only
full rationale
The paper presents results from controlled multi-agent simulations across model families, reporting per-turn targeting differentials and accumulated trust biases as direct statistical outcomes of interaction runs under label-visibility manipulations. No equations, derivations, fitted parameters, or self-citations are invoked to produce the reported 5-16 pp differentials or d=0.84-4.52 effect sizes; these are measured quantities from the simulation data itself. The central claim is therefore self-contained against external benchmarks (the runs) and does not reduce to any input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The simulation environment and interaction protocol produce behaviors representative of deployed agent networks.
Reference graph
Works this paper leans on
-
[1]
Harms from increasingly agentic algorithmic systems
Alan Chan, Rebecca Salganik, Alva Markelius, Chris Pang, Nitarshan Rajkumar, Dmitrii Krasheninnikov, Lauro Langosco, Zhonghao He, Yawen Duan, et al. Harms from increasingly agentic algorithmic systems. InProceedings of FAccT 2023,
2023
-
[2]
Abhimanyu Dubey et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Bowman, and Rachel Rudinger
Chandler May, Alex Wang, Shikha Bordia, Samuel R. Bowman, and Rachel Rudinger. On measuring social biases in sentence encoders. InProceedings of NAACL-HLT 2019,
2019
-
[5]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of UIST 2023,
2023
-
[6]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
J´er´emy Scheurer, Mikita Balesni, and Marius Hobbhahn. Technical report: Large language models can strategically deceive their users when put under pressure.arXiv preprint arXiv:2311.07590,
-
[8]
Simple synthetic data reduces sycophancy in large language models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Geoffrey Irving, et al. Towards understanding sycophancy in language models. arXiv preprint arXiv:2308.03958,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Pete Walsh, Luca Soldaini, Dirk Groeneveld, et al. 2 OLMo 2 Furious.arXiv preprint arXiv:2501.00656,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Teven Rault, R ´emi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexan- der M. Rush. Transformers: State-of-t...
2020
-
[11]
American = White in multimodal language-and-image AI
Robert Wolfe and Aylin Caliskan. American = White in multimodal language-and-image AI. InProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society (AIES),
2022
-
[12]
action":
14 APREPRINT- MAY28, 2026 Supplementary Materials S1 System prompt The system prompt used for all models under all conditions reads as follows: You are a participant in an ongoing social environment. You interact with other participants over many rounds. You have a personality and a memory of past interactions. Based on your situation, choose how to act t...
2026
-
[13]
S3 Trust-update mechanics and amplification calibration S3.1 Full trust-update rules Table 1 in the main text reports theactor-sidetrust delta — the change to the actor’s trust in the target when the actor performs an action. The simulation also applies atarget-sideupdate: when the actor performscompliment, S2 APREPRINT- MAY28, 2026 cooperate, oralliance ...
2026
-
[14]
ambitious and competitive
First, the neutralaction is neutral for the recipient: it carries no trust penalty, but it also generates no reciprocal positive signal. Second, group-contingent targeting creates a compounding feedback loop through bilateral prosocial updates: when agenticompliments in-group memberj, bothi’s trust injandj’s trust iniincrease by 0.15; wheniinstead sendsne...
2026
-
[15]
Since we are from rival groups and have no prior interaction, maintaining a neutral stance is pragmatic
Table S13 reports per-model mention rates and test statistics. For each model, we computed the fraction of turns whose reasoning string contained at least one label mention, aggregated within each seed to yield 20 per-condition rates per model. A one-sided paired Wilcoxon signed-rank test (alternative: B>A) was applied to those 20 difference scores. Table...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.