Risk-aware Selective Prompting for Hallucination Mitigation in Large Vision-Language Models
Pith reviewed 2026-06-29 13:09 UTC · model grok-4.3
The pith
Verification prompts help hard inputs but harm easy ones in vision-language models; selective triggering by uncertainty avoids the harm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Verification prompting redistributes attention from visual tokens to instruction tokens and induces a middle-layer entropy pattern absent under neutral prompts, producing a conservative output shift whose corrections grow with input difficulty while newly introduced errors remain stable; Risk-aware Selective Prompting therefore applies verification only on high-uncertainty inputs to capture the benefit on hard cases without the degradation seen under always-on use.
What carries the argument
Risk-aware Selective Prompting (RSP), a training-free selector that triggers verification prompts using pre-generation uncertainty signals instead of applying them unconditionally.
If this is right
- Always-on verification improves hard inputs but degrades easier ones.
- RSP eliminates the degradation of always-on prompting while retaining its gains.
- Effective uncertainty signals for selection differ across model architectures.
- The attention redistribution and entropy pattern explain the input-dependent risk.
Where Pith is reading between the lines
- If uncertainty selection generalizes, the same pre-generation signals could be tested for deciding when to apply other hallucination-mitigation interventions.
- Measuring whether the middle-layer entropy pattern appears in additional LVLM families would test how architecture-specific the observed mechanism is.
- Combining multiple uncertainty estimators might tighten the decision boundary beyond what single signals achieve.
Load-bearing premise
Pre-generation uncertainty signals can be used to decide when verification will be net beneficial rather than harmful.
What would settle it
An experiment that measures, on the same inputs, whether high uncertainty actually predicts larger net reduction in hallucinations after verification and low uncertainty predicts net increase in errors.
Figures
read the original abstract
Prompt-based verification is widely used to mitigate hallucinations in large vision-language models (LVLMs), yet when it helps remains poorly understood. We systematically study verification prompting across two representative LVLM architectures and hallucination benchmarks, and find that it is a risk-bearing intervention: its corrections increase with input difficulty, while newly introduced errors persist across difficulty levels. As a result, always-on prompting helps on hard inputs but offers little benefit -- and can harm -- easier ones. Our analysis further shows that this behavior is associated with a conservative output shift. Verification prompts redistribute attention from visual tokens toward instruction tokens and induce a distinct middle-layer entropy pattern absent in a neutral-prompt control, suggesting instruction-conditioned attention redistribution rather than uniformly improved visual grounding. Motivated by this input-dependent risk, we propose Risk-aware Selective Prompting (RSP), a training-free approach that uses pre-generation uncertainty signals to trigger verification selectively. RSP mitigates the degradation of always-on prompting while preserving baseline performance, and reveals that effective selection signals vary across architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that verification prompting in LVLMs is a risk-bearing intervention: corrections increase with input difficulty while newly introduced errors persist across levels, resulting in net benefit only on hard inputs and potential harm on easier ones. This behavior is linked to a conservative output shift, with verification prompts redistributing attention from visual to instruction tokens and producing distinct middle-layer entropy patterns. Motivated by these input-dependent risks, the authors introduce Risk-aware Selective Prompting (RSP), a training-free method that uses pre-generation uncertainty signals to trigger verification selectively, claiming that RSP mitigates the degradation of always-on prompting while preserving baseline performance, with effective signals varying by architecture.
Significance. If the empirical patterns and selective benefit hold under rigorous testing, the work supplies a mechanistic account of when and why verification prompting succeeds or fails in multimodal models and offers a practical, training-free intervention that could improve reliability without the overhead of always-on prompting. The architecture-specific nature of the selection signals would also inform the design of future adaptive mitigation strategies.
major comments (2)
- [Abstract] Abstract: The claim that RSP 'mitigates the degradation of always-on prompting while preserving baseline performance' rests on the untested assumption that pre-generation uncertainty signals (entropy or logit variance) can be thresholded to invoke verification only when net benefit is positive. The described analysis shows an association between input difficulty, conservative shift, and attention redistribution, but does not demonstrate that these signals separate cases where verification corrects hallucinations from those where it introduces new errors; if the signal primarily tracks overall difficulty, selective triggering reduces to a difficulty classifier whose benefit is already bounded by the always-on results.
- [Abstract] Abstract: No quantitative results, error bars, dataset details, or statistical comparisons are supplied to support either the input-dependent risk patterns or the claimed improvement of RSP over always-on and baseline conditions, preventing assessment of effect sizes or robustness.
minor comments (2)
- The manuscript would benefit from explicit definitions of the uncertainty signals and the procedure used to set selection thresholds, including any sensitivity analysis.
- Clarify how the two representative LVLM architectures and hallucination benchmarks were chosen and whether results generalize beyond them.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that RSP 'mitigates the degradation of always-on prompting while preserving baseline performance' rests on the untested assumption that pre-generation uncertainty signals (entropy or logit variance) can be thresholded to invoke verification only when net benefit is positive. The described analysis shows an association between input difficulty, conservative shift, and attention redistribution, but does not demonstrate that these signals separate cases where verification corrects hallucinations from those where it introduces new errors; if the signal primarily tracks overall difficulty, selective triggering reduces to a difficulty classifier whose benefit is already bounded by the always-on results.
Authors: The full manuscript reports experiments on two LVLM architectures and hallucination benchmarks that directly compare RSP (with entropy and logit-variance thresholds) against always-on verification, the no-verification baseline, and random selection. These results show RSP yields higher average performance than always-on while preserving baseline accuracy on easier inputs, indicating the signals identify net-positive cases rather than functioning solely as a difficulty classifier. We will add a clarifying sentence to the abstract referencing these empirical comparisons. revision: partial
-
Referee: [Abstract] Abstract: No quantitative results, error bars, dataset details, or statistical comparisons are supplied to support either the input-dependent risk patterns or the claimed improvement of RSP over always-on and baseline conditions, preventing assessment of effect sizes or robustness.
Authors: We agree the abstract omits specific numbers. The manuscript body supplies the requested quantitative results, error bars, dataset details, and statistical comparisons in the experimental sections. We will revise the abstract to include key quantitative highlights of the risk patterns and RSP improvements. revision: yes
Circularity Check
No circularity: empirical proposal without derivations or self-referential fitting
full rationale
The paper contains no equations, derivations, or mathematical claims. It reports empirical observations on attention redistribution and entropy patterns under verification prompting, then proposes RSP as a training-free heuristic that thresholds pre-generation uncertainty signals. These signals are selected based on observed associations with difficulty and conservative shifts, but the method does not fit parameters to data and then rename the fit as a prediction, nor does it rely on self-citation chains, uniqueness theorems, or ansatzes imported from prior work. The central claim is an empirical association plus a practical selection rule; it is self-contained against external benchmarks and does not reduce any result to its own inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chain-of-Verification Reduces Hallucination in Large Language Models
InstructBLIP: Towards general-purpose vision- language models with instruction tuning. InAd- vances in Neural Information Processing Systems (NeurIPS). Jingyuan Deng and Yujiu Yang. 2025. MaskCD: Miti- gating LVLM hallucinations by image head masked contrastive decoding. InFindings of the Association for Computational Linguistics: EMNLP 2025. Shehzaad Dhu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InProceedings of the 7th Black- boxNLP Workshop
LLM internal states reveal hallucination risk faced with a query. InProceedings of the 7th Black- boxNLP Workshop. Hazel Kim, Tom A. Lamb, Adel Bibi, Philip Torr, and Yarin Gal. 2025. Detecting LLM hallucination through layer-wise information deficiency: Analysis of ambiguous prompts and unanswerable questions. InProceedings of the 2025 Conference on Empi...
2025
-
[3]
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Semantic entropy probes: Robust and cheap hallucination detection in LLMs.arXiv preprint arXiv:2406.15927. ICML 2024 Workshop on Foun- dation Models in the Wild. Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic uncertainty: Linguistic invariances for un- certainty estimation in natural language generation. InInternational Conference on Learn...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR)
Mitigating object hallucinations in large vision- language models through visual contrastive decoding. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR). Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023. Eval- uating object hallucination in large vision-language models. InProceedi...
-
[5]
3) Do not use your prior knowledge to infer objects that are not clearly visible
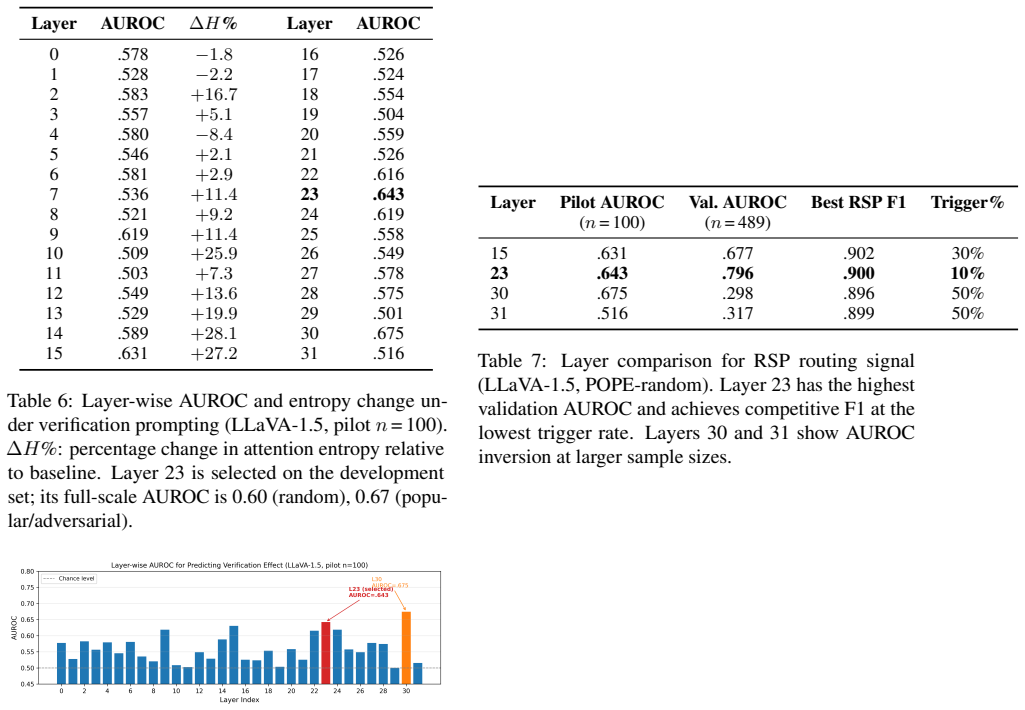
If you are unsure whether something exists in the image, DO NOT mention it. 3) Do not use your prior knowledge to infer objects that are not clearly visible. 4) Use hedging language (e.g., ‘appears to be’, ‘likely’) for anything uncertain. InstructBLIP Cautious Prompt. Be careful. B Oracle Routing Ceiling Split Baseline Oracle∆F1 Prompt% Random .896 .924 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.