Chinese Word Boundary Recovery through Character Alignment Projection
Pith reviewed 2026-06-29 13:06 UTC · model grok-4.3
The pith
Chinese word boundary recovery projects clean boundaries onto noisy input via character alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a noisy source sentence and a cleaner target counterpart, character-level alignment followed by projection of target word boundaries recovers correct source-side word spans that direct segmentation misses, establishing boundary recovery as distinct from ordinary segmentation and alignment projection as a mechanism for stabilizing Chinese annotation and evaluation under noisy input.
What carries the argument
Character alignment projection: aligning the noisy source and clean target at the character level then transferring word boundaries from target to source.
If this is right
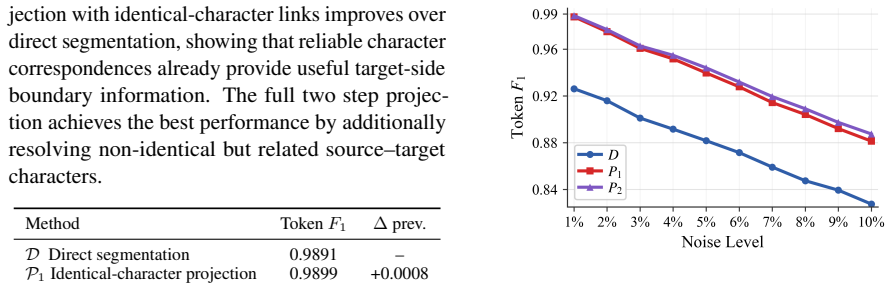
- Direct segmentation on learner input produces more compound fragmentation than the projection method.
- The projection method corrects many over-segmentation errors by using the corrected target to recover source-side word spans.
- Word boundary recovery is distinct from ordinary segmentation.
- Alignment projection provides a principled mechanism for stabilizing Chinese annotation and evaluation under noisy input.
Where Pith is reading between the lines
- The same projection idea could apply to other languages or tasks where a clean reference is available to guide noisy sequences.
- The introduced benchmarks could serve as test beds for measuring robustness in any Chinese NLP pipeline that assumes standard word units.
- If clean targets can be generated automatically rather than supplied, the method becomes more practical for large-scale noisy corpora.
Load-bearing premise
A cleaner target counterpart must exist for each noisy source sentence and character-level alignment must be accurate enough to transfer boundaries without adding errors.
What would settle it
A held-out set of noisy sentences with gold word boundaries on which the projection method recovers no more correct spans than direct segmentation.
Figures

read the original abstract
Chinese word segmentation is especially fragile in non-standard text, where language learner errors and other character-level divergences disrupt the word boundaries assumed by downstream annotation and evaluation. This paper formulates Chinese word boundary recovery as an alignment-based projection task. Given a noisy source sentence and a cleaner target counterpart, we first align the two strings at the character level and then project target-side word boundaries back onto the source. Beyond the recovery method itself, we introduce two evaluation resources: a manually checked learner Chinese benchmark based on MuCGEC and a controlled synthetic benchmark derived from the Chinese Penn Treebank. Experiments show that direct segmentation remains vulnerable to compound fragmentation in learner input, whereas the proposed two step projection method corrects many over-segmentation errors by using the corrected target to recover source-side word spans. The results show that word boundary recovery is distinct from ordinary segmentation and that alignment projection provides a principled mechanism for stabilizing Chinese annotation and evaluation under noisy input.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates Chinese word boundary recovery as an alignment-based projection task: given a noisy source sentence and a cleaner target counterpart, perform character-level alignment then project target word boundaries onto the source. It introduces two new resources (a manually checked MuCGEC-derived learner benchmark and a CTB-derived synthetic benchmark) and shows via experiments that the projection approach corrects over-segmentation errors that direct segmentation baselines fail to handle in noisy learner or synthetic input, arguing that boundary recovery is distinct from ordinary segmentation and stabilizes annotation under noise.
Significance. If the empirical results hold, the work supplies a scoped but principled mechanism for handling character-level divergences in Chinese text (e.g., learner errors), together with reusable evaluation resources that can support future work on noisy-input segmentation and annotation stability. The explicit two-benchmark design and baseline comparisons are concrete strengths.
major comments (2)
- [§4] §4 (Experiments on MuCGEC-derived benchmark): the reported gains over direct segmentation are load-bearing for the central claim that projection is distinct and corrective; the manuscript should report the character-alignment accuracy (or error rate) on this benchmark so readers can assess whether projection errors are introduced by the aligner itself.
- [§3] §3 (Method): the two-step procedure presupposes a cleaner target counterpart for every noisy source; while the paper scopes the method to this setting, a brief discussion of how often such pairs exist in practice (or how the method degrades without them) would strengthen the applicability claim.
minor comments (2)
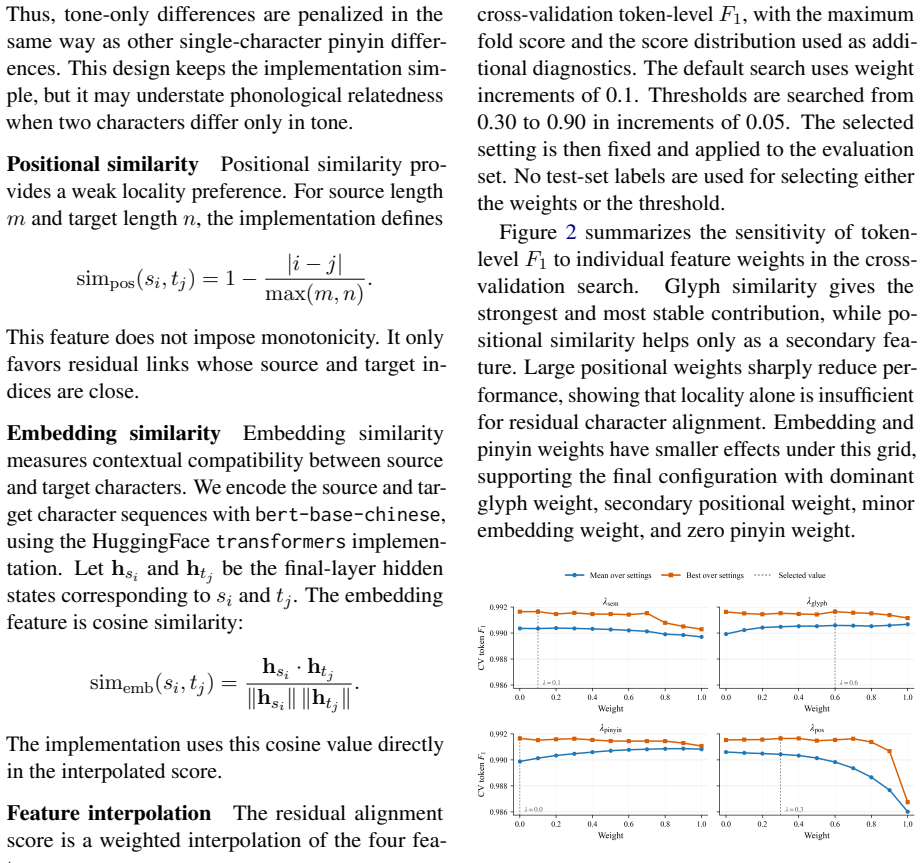
- [Tables 1-2] Table 1 and Table 2: ensure the exact segmentation metrics (P/R/F1) and the definition of 'over-segmentation' are stated in the caption or immediately preceding text for reproducibility.
- [§4.2] The synthetic benchmark construction (§4.2) should explicitly list the noise operations applied to CTB sentences so that the controlled nature of the evaluation can be verified.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The two major comments are addressed point by point below; both can be incorporated without altering the core claims.
read point-by-point responses
-
Referee: [§4] §4 (Experiments on MuCGEC-derived benchmark): the reported gains over direct segmentation are load-bearing for the central claim that projection is distinct and corrective; the manuscript should report the character-alignment accuracy (or error rate) on this benchmark so readers can assess whether projection errors are introduced by the aligner itself.
Authors: We agree that alignment accuracy on the MuCGEC-derived benchmark would help readers separate aligner errors from projection effects. We will add this metric (computed via the same aligner used in the experiments) to the revised §4, including a short breakdown of alignment error types. revision: yes
-
Referee: [§3] §3 (Method): the two-step procedure presupposes a cleaner target counterpart for every noisy source; while the paper scopes the method to this setting, a brief discussion of how often such pairs exist in practice (or how the method degrades without them) would strengthen the applicability claim.
Authors: We will insert a concise paragraph in §3 noting the availability of paired corrections in learner corpora (e.g., MuCGEC, Lang-8) and practical settings such as post-editing or parallel annotation, while explicitly acknowledging that the method does not apply when no cleaner target is present. revision: yes
Circularity Check
No significant circularity; method and evaluation are independently defined
full rationale
The paper defines a two-step procedure (character alignment followed by boundary projection) as a new task formulation for word boundary recovery, introduces two new benchmarks (MuCGEC-derived learner data and CTB-derived synthetic data), and evaluates against direct segmentation baselines. No equations, fitted parameters, or derivations are present that reduce to self-referential inputs. No load-bearing self-citations or uniqueness theorems from prior author work are invoked. The central claim rests on explicit experimental comparison showing correction of over-segmentation errors, which is externally testable and not forced by construction from the method's own inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
WeGenBench: A Multidimensional Diagnostic Benchmark towards Text-to-Image Model Optimization
WeGenBench provides 4000 bilingual prompts with scene and tag annotations plus VLM-derived metrics to locate specific deficiencies in text-to-image models.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Peter F. Brown, Stephen A. Della Pietra, Vincent J. Della Pietra, and Robert L. Mercer. 1991. https://doi.org/10.3115/112405.112427 A Statistical Approach to Sense Disambiguation in Machine Translation . In Proceedings of the Workshop on Speech and Natural Language, HLT '91, pages 146--151, Stroudsburg, PA, USA. Association for Computational Linguistics
-
[4]
Wanxiang Che, Yunlong Feng, Libo Qin, and Ting Liu. 2021. https://doi.org/10.18653/v1/2021.emnlp-demo.6 N-LTP: An Open-source Neural Language Technology Platform for Chinese . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 42--49, Online and Punta Cana, Dominican Republic. Associatio...
-
[5]
Wanxiang Che, Zhenghua Li, and Ting Liu. 2010. https://aclanthology.org/C10-3004 LTP: A Chinese Language Technology Platform . In Coling 2010: Demonstrations, pages 13--16, Beijing, China. Coling 2010 Organizing Committee
2010
-
[6]
Li Dazhong. 2020. Analysis of Errors of Foreign Students in Learning Chinese Grammar . Beijng Language and Culture University Press, Beijng
2020
-
[7]
Yang Gu, Zihao Huang, Min Zeng, Mengyang Qiu, and Jungyeul Park. 2025. https://aclanthology.org/2025.coling-main.189/ Improving Automatic Grammatical Error Annotation for Chinese Through Linguistically-Informed Error Typology . In Proceedings of the 31st International Conference on Computational Linguistics, pages 2781--2798, Abu Dhabi, UAE. Association f...
2025
-
[8]
Rebecca Hwa, Philip Resnik, Amy Weinberg, Clara Cabezas, and Okan Kolak. 2005. https://doi.org/10.1017/S1351324905003840 Bootstrapping parsers via syntactic projection across parallel texts . Natural Language Engineering, 11(03):311--325
-
[9]
Eunkyul Leah Jo, Angela Yoonseo Park, Grace Tianjiao Zhang, Izia Xiaoxiao Wang, Junrui Wang, MingJia Mao, and Jungyeul Park. 2024. https://aclanthology.org/2024.lrec-main.119 An Untold Story of Preprocessing Task Evaluation: An Alignment-based Joint Evaluation Approach . In Proceedings of the 2024 Joint International Conference on Computational Linguistic...
2024
-
[10]
Zhang Linlin. 2006. An Error Analysis of English Speaking Chinese Learners' Corpus . Ph.D. thesis, University of International Business and Economics
2006
-
[11]
Chao-Lin Liu, Min-Hua Lai, Kan-Wen Tien, Yi-Hsuan Chuang, Shih-Hung Wu, and Chia-Ying Lee. 2011. https://doi.org/10.1145/1967293.1967297 Visually and phonologically similar characters in incorrect C hinese words: Analyses, identification, and applications . ACM Transactions on Asian Language Information Processing, 10(2):1--39
-
[12]
Manning, Sampo Pyysalo, Sebastian Schuster, Francis Tyers, and Daniel Zeman
Joakim Nivre, Marie-Catherine de Marneffe, Filip Ginter, Jan Haji c , Christopher D. Manning, Sampo Pyysalo, Sebastian Schuster, Francis Tyers, and Daniel Zeman. 2020. https://www.aclweb.org/anthology/2020.lrec-1.497 Universal Dependencies v2: An Evergrowing Multilingual Treebank Collection . In Proceedings of the 12th Language Resources and Evaluation Co...
2020
-
[13]
Yú Sh \` i w \' e n, Duàn Hu \` i m \' i ng, Zhū Xu \' e f \= e ng, and Sūn B \= i n. 2002. http://jcip.cipsc.org.cn/CN/Y2002/V16/I5/51 Basic Processing Standards for the Peking University Modern Chinese Corpus . Journal of Chinese Information Processing, 16(5):51--66
2002
-
[14]
Richard Sproat and Thomas Emerson. 2003. https://doi.org/10.3115/1119250.1119269 The First International Chinese Word Segmentation Bakeoff . In Proceedings of the Second \ SIGHAN \ Workshop on \ C \ hinese Language Processing , pages 133--143, Sapporo, Japan. Association for Computational Linguistics
-
[15]
Richard W Sproat, Chilin Shih, William Gale, and Nancy Chang. 1996. https://aclanthology.org/J96-3004/ A Stochastic Finite-State Word-Segmentation Algorithm for Chinese . Computational Linguistics, 22(3):377--404
1996
-
[16]
Fei Xia. 2000. https://catalog.ldc.upenn.edu/docs/LDC2010T07/ctb-segguide.pdf The Segmentation Guidelines for the Penn Chinese Treebank (3.0) . Technical report, University of Pennsylvania, Philadelphia, PA
2000
-
[17]
Nianwen Xue, Fei Xia, Fu-dong Chiou, and Marta Palmer. 2005. https://doi.org/10.1017/S135132490400364X The Penn Chinese TreeBank: Phrase Structure Annotation of a Large Corpus . Natural Language Engineering, 11(2):207--238
-
[18]
David Yarowsky and Grace Ngai. 2001. https://aclanthology.org/N01-1026/ Inducing Multilingual POS Taggers and NP Bracketers via Robust Projection Across Aligned Corpora . In Second Meeting of the North American Chapter of the Association for Computational Linguistics, pages 1--8, Pittsburgh, Pennsylvania. Association for Computational Linguistics
2001
-
[19]
Linlin Zhang and Hongbing Xing. 2023. https://doi.org/10.3389/fpsyg.2023.1076810 The interaction of orthography, phonology and semantics in the process of second language learners' C hinese character production . Frontiers in Psychology, 14:1076810
-
[20]
Yue Zhang, Zhenghua Li, Zuyi Bao, Jiacheng Li, Bo Zhang, Chen Li, Fei Huang, and Min Zhang. 2022. https://doi.org/10.18653/v1/2022.naacl-main.227 MuCGEC: a Multi-Reference Multi-Source Evaluation Dataset for Chinese Grammatical Error Correction . In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Lingu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.