Look on Demand: A Cognitive Scheduling Framework for Visual Evidence Acquisition in Multimodal Reasoning
Pith reviewed 2026-06-29 12:46 UTC · model grok-4.3
The pith
A language model improves multimodal reasoning by deciding when to invoke a separate visual module for needed evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
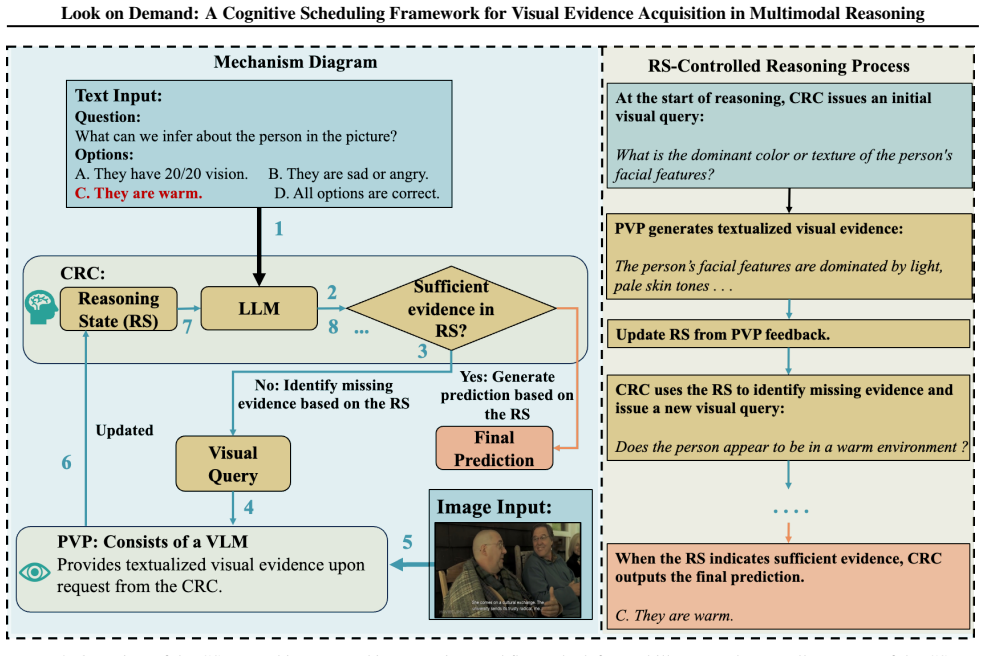
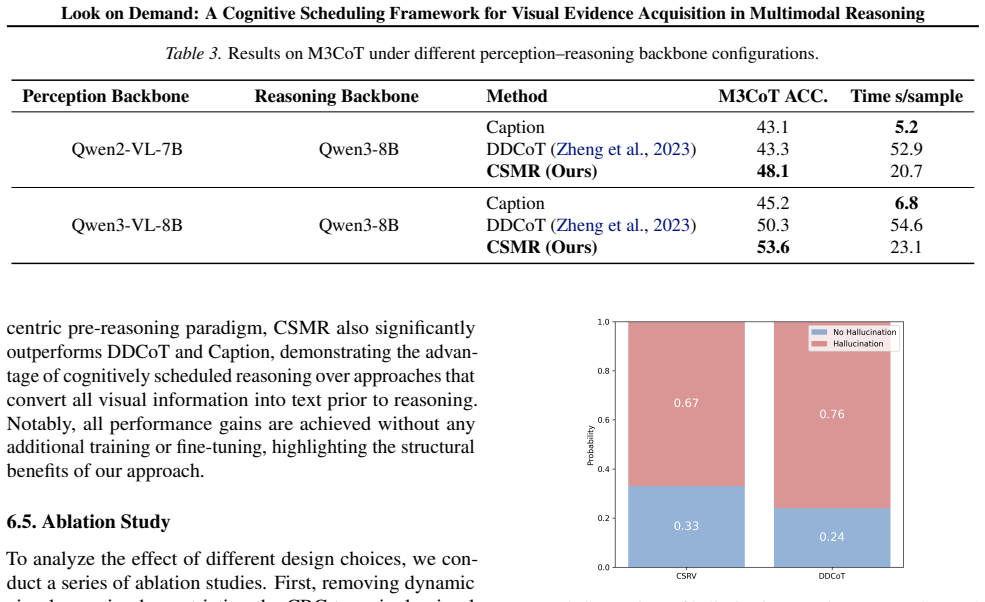
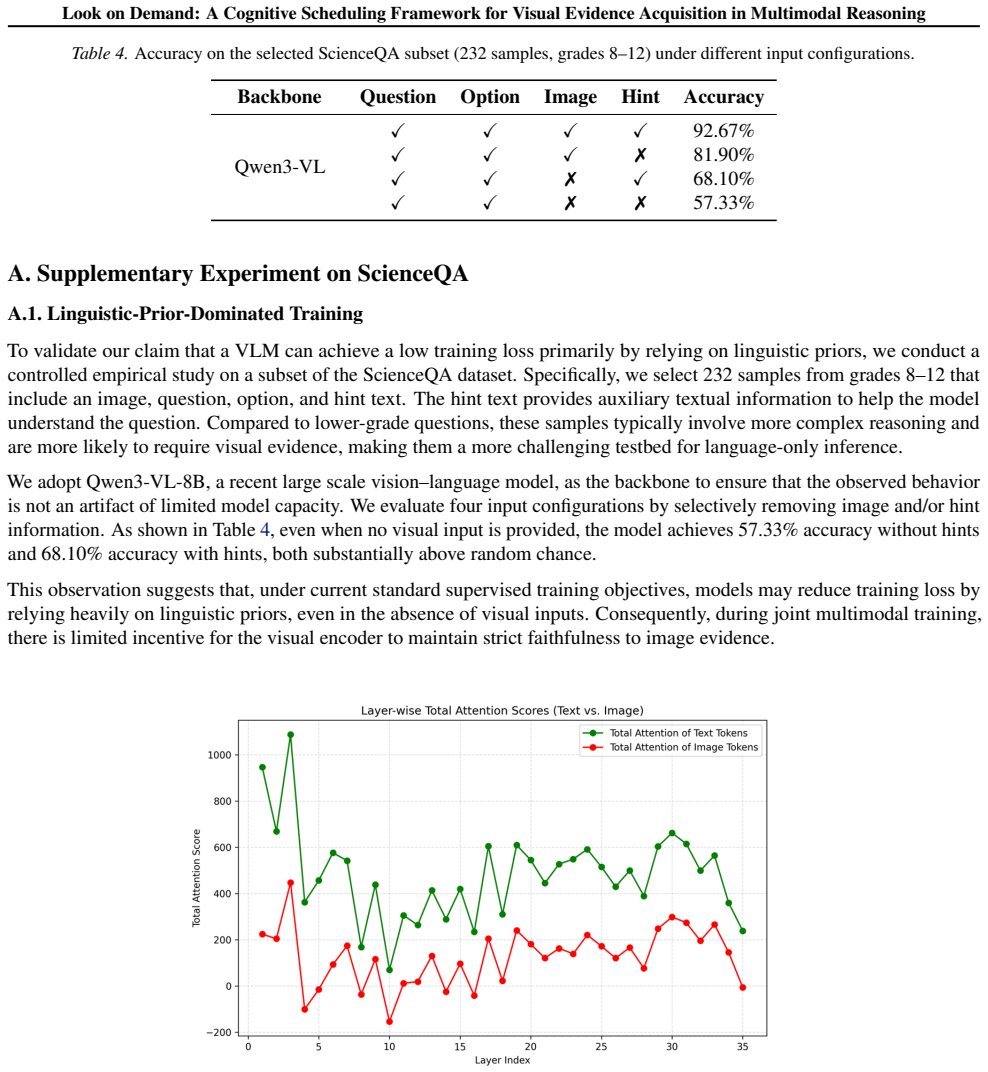
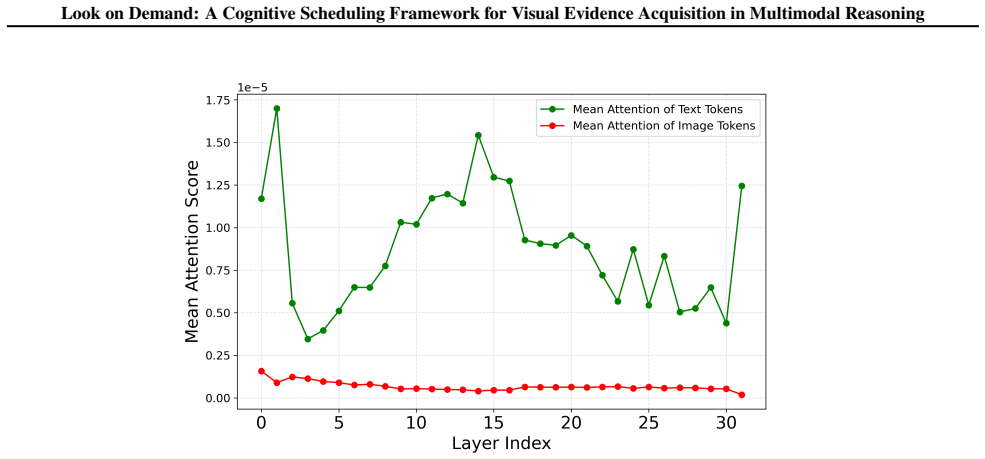
CSMR is a multimodal reasoning framework in which a language model controls the reasoning process by deciding when to invoke an independent visual perception module to acquire task-relevant visual evidence. Experiments across multiple multimodal reasoning benchmarks show that CSMR consistently outperforms representative baseline methods in accuracy under a zero-shot setting, with further analysis confirming that these advantages primarily arise from the proposed cognitive scheduling mechanism.
What carries the argument
Cognitive scheduling mechanism, in which the language model decides when to invoke the independent visual perception module.
If this is right
- CSMR achieves higher accuracy than representative baselines on multiple multimodal reasoning benchmarks in zero-shot settings.
- The performance advantages primarily arise from the cognitive scheduling mechanism rather than static conversion or unified representation.
- Visual evidence is introduced dynamically only when the language model determines it is task-relevant.
- The framework separates control of reasoning from visual perception to reduce linguistic dominance.
Where Pith is reading between the lines
- The same scheduling idea could apply to other evidence types, such as when to query external knowledge or tools during reasoning.
- If the language model can improve its invocation decisions through additional training signals, the accuracy gap might widen on harder tasks.
- This separation of perception timing from reasoning might reduce the need for ever-larger joint vision-language models.
Load-bearing premise
The accuracy gains come mainly from the language model's scheduling decisions rather than other parts of the implementation.
What would settle it
An experiment that keeps the visual module and language model but replaces the learned scheduling decisions with fixed or random invocation timing and finds no accuracy drop would falsify the central claim.
Figures



read the original abstract
Existing multimodal reasoning approaches predominantly follow two paradigms: converting visual inputs into text prior to reasoning, or performing end-to-end reasoning within a unified vision-language representation space. Despite their empirical progress, both paradigms suffer from fundamental structural limitations. The former relies on static visual-to-text conversion, which tends to compress and lose fine-grained visual details. The latter is prone to linguistic dominance induced by joint optimization and attention mechanisms, leading to systematically weakened faithfulness to visual evidence during reasoning. In this work, we argue that a central challenge is how and when visual evidence is introduced into the reasoning process. Motivated by this insight, we propose CSMR, a multimodal reasoning framework in which a language model controls the reasoning process by deciding when to invoke an independent visual perception module to acquire task-relevant visual evidence. Experiments across multiple multimodal reasoning benchmarks show that CSMR consistently outperforms representative baseline methods in accuracy under a zero-shot setting. Further experimental analysis confirms that these advantages primarily arise from the proposed cognitive scheduling mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CSMR, a multimodal reasoning framework in which a language model dynamically controls the reasoning process by deciding when to invoke an independent visual perception module for acquiring task-relevant visual evidence. It contrasts this with static visual-to-text conversion and end-to-end unified vision-language models, arguing that the timing of visual evidence introduction is central. The manuscript claims that CSMR outperforms representative baselines in accuracy across multiple multimodal reasoning benchmarks under zero-shot settings, with further analysis attributing the gains primarily to the cognitive scheduling mechanism.
Significance. If the outperformance and causal attribution to the scheduling mechanism are substantiated, the work could address key limitations in current multimodal paradigms by enabling dynamic, on-demand visual evidence acquisition, potentially improving detail preservation and reducing linguistic dominance in reasoning.
major comments (1)
- [Abstract] Abstract: The central claim that 'these advantages primarily arise from the proposed cognitive scheduling mechanism' is load-bearing, yet the manuscript provides no description of the LM's invocation decision process (e.g., prompt template, decision criteria, or policy), nor any ablation studies or controlled comparisons isolating the scheduling from other elements such as the perception module choice or framework structure. Without this, the attribution cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript accordingly to strengthen the substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'these advantages primarily arise from the proposed cognitive scheduling mechanism' is load-bearing, yet the manuscript provides no description of the LM's invocation decision process (e.g., prompt template, decision criteria, or policy), nor any ablation studies or controlled comparisons isolating the scheduling from other elements such as the perception module choice or framework structure. Without this, the attribution cannot be evaluated.
Authors: We agree that the central claim requires more explicit support to allow evaluation of the attribution. The current manuscript describes the overall framework and reports experimental gains but does not provide the requested implementation details or isolating ablations. In the revised version we will add: (1) the exact prompt template and decision criteria (including any uncertainty or task-based heuristics) used by the LM to decide invocations, (2) a clear statement of the scheduling policy, and (3) controlled ablation experiments that hold the perception module and framework structure fixed while varying only the presence of the scheduling mechanism. These additions will be placed in the Methods and Experiments sections. revision: yes
Circularity Check
No circularity: empirical framework validated by external benchmarks
full rationale
The paper proposes CSMR as a scheduling framework where an LM decides when to invoke a visual module, then reports zero-shot accuracy gains over baselines on multimodal benchmarks. No equations, fitted parameters, or self-citations are presented that reduce the central performance claim to the inputs by construction. The attribution to the scheduling mechanism is an empirical interpretation of ablation-style analysis rather than a definitional or self-referential derivation. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https: //aclanthology.org/2025.acl-long.257/
doi: 10.18653/v1/2025.acl-long.257. URL https: //aclanthology.org/2025.acl-long.257/. Tan, C., Wei, J., Gao, Z., Sun, L., Li, S., Guo, R., Yu, B., and Li, S. Z. Boosting the power of small multimodal reason- ing models to match larger models with self-consistency training, 2024. URL https://arxiv.org/abs/ 2311.14109. Team, Q. Qwen3 technical report, 2025....
-
[2]
URL https://openreview.net/forum? id=4z3IguA4Zg. Yang, A., Yang, B., Hui, B., Zheng, B., Yu, B., Zhou, C., Li, C., Li, C., Liu, D., Huang, F., Dong, G., Wei, H., Lin, H., Tang, J., Wang, J., Yang, J., Tu, J., Zhang, J., Ma, J., Yang, J., Xu, J., Zhou, J., Bai, J., He, J., Lin, J., Dang, K., Lu, K., Chen, K., Yang, K., Li, M., Xue, M., Ni, N., Zhang, P., W...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.