When Confidence Misleads: Suffix Anchoring and Anchor-Proximity Confidence Modulation for Diffusion Language Models
Pith reviewed 2026-06-29 12:50 UTC · model grok-4.3
The pith
Suffix-Anchored Confidence Modulation improves fully non-autoregressive decoding by fixing premature selection near anchors while preserving response completion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
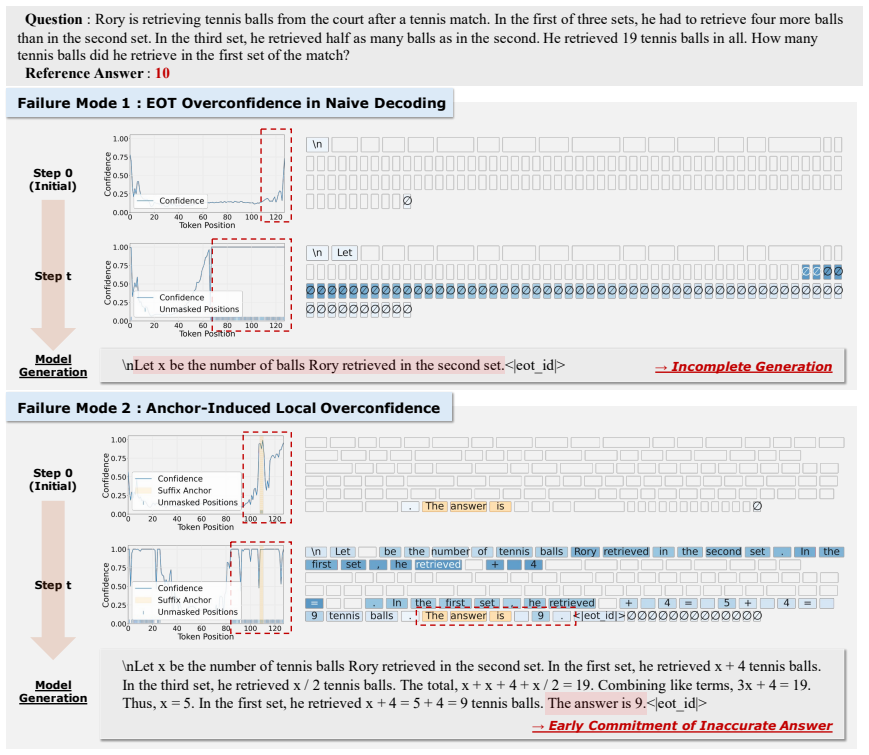
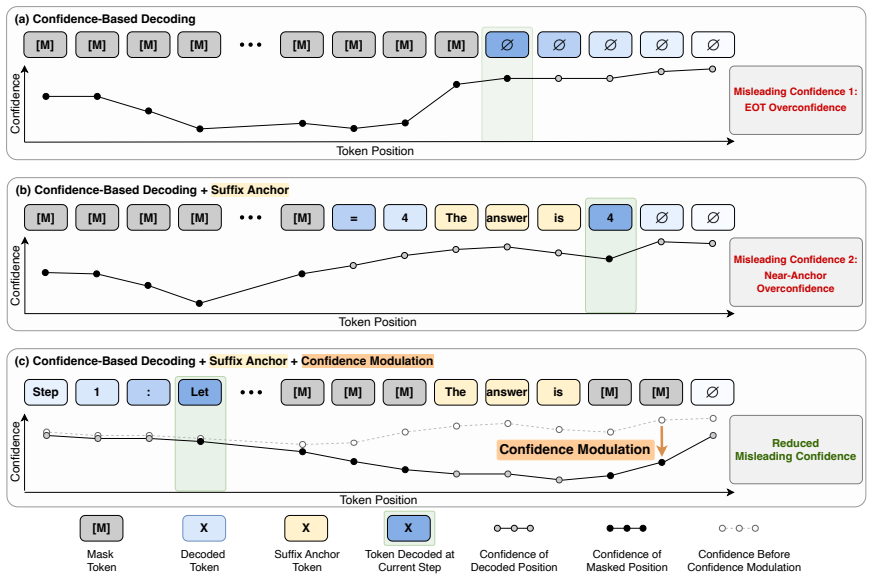
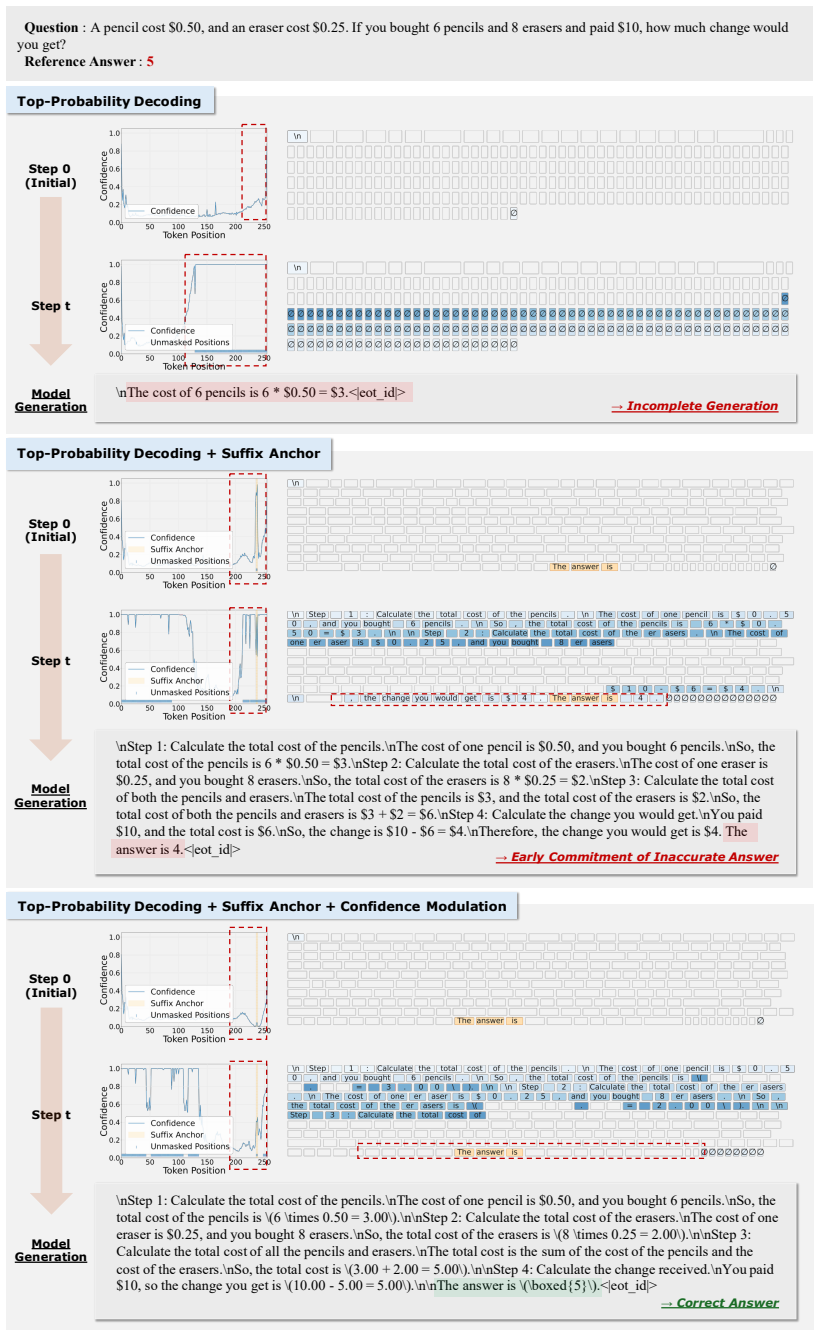
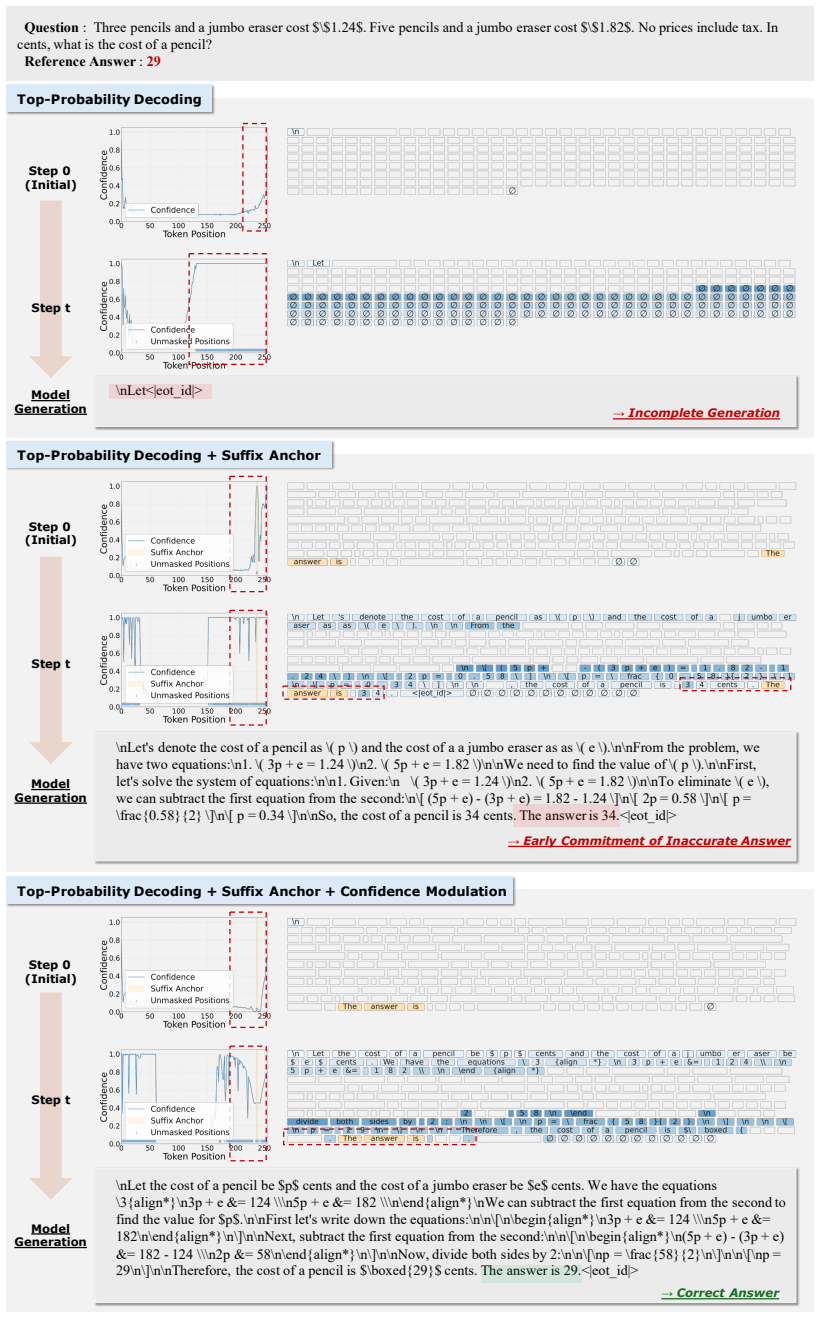
The authors establish that Suffix-Anchored Confidence Modulation, which inserts a short suffix anchor to encourage response completion and modulates confidence of tokens near the anchor according to decoding progress, preserves the completion benefit of anchoring while reducing premature decoding of anchor-adjacent tokens, thereby improving confidence-based fully non-AR decoding across text-only reasoning, vision-language reasoning, and code-generation benchmarks and outperforming explicit EOT suppression.
What carries the argument
Suffix-Anchored Confidence Modulation: a training-free technique that inserts a suffix anchor and adjusts confidence scores of nearby tokens according to decoding progress to guide position selection during iterative denoising.
If this is right
- Consistently improves confidence-based fully non-AR decoding on text-only reasoning benchmarks.
- Enhances performance on vision-language reasoning benchmarks.
- Boosts results on code-generation benchmarks.
- Outperforms explicit EOT suppression while retaining parallel decoding speed.
Where Pith is reading between the lines
- The local, progress-dependent adjustment may address similar overconfidence issues in other iterative position-selection schemes.
- The same modulation principle could be tested on diffusion models with different noise schedules or mask ratios.
- Anchor length or placement might be made task-dependent to further reduce side effects on longer outputs.
Load-bearing premise
That modulating confidence near the anchor according to decoding progress will reduce premature decoding of anchor-adjacent tokens without introducing new failure modes or degrading overall generation quality on the evaluated benchmarks.
What would settle it
Running the method on the same benchmarks and measuring both the rate of anchor-adjacent premature decodings and final task scores; if the modulation leaves the premature rate unchanged or lowers task scores, the central claim would not hold.
Figures


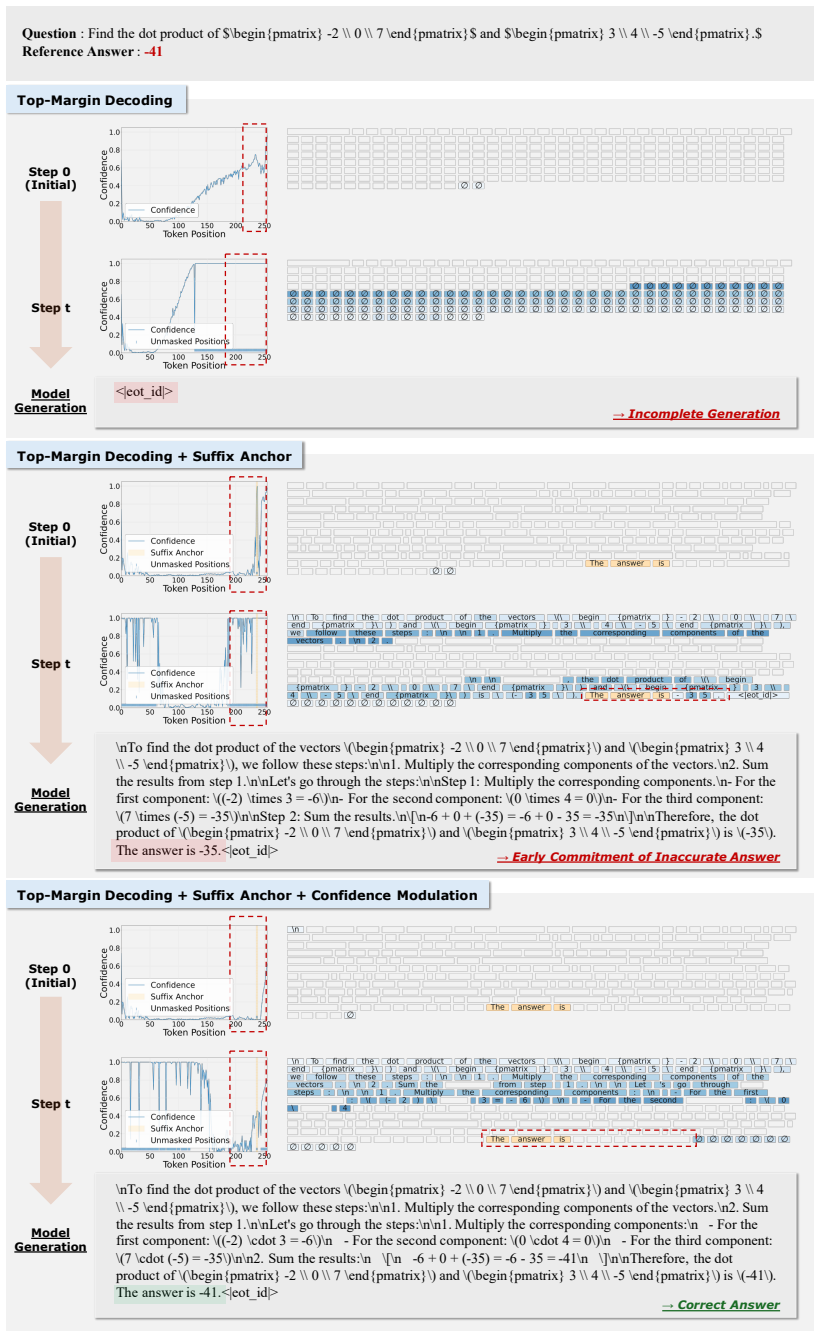


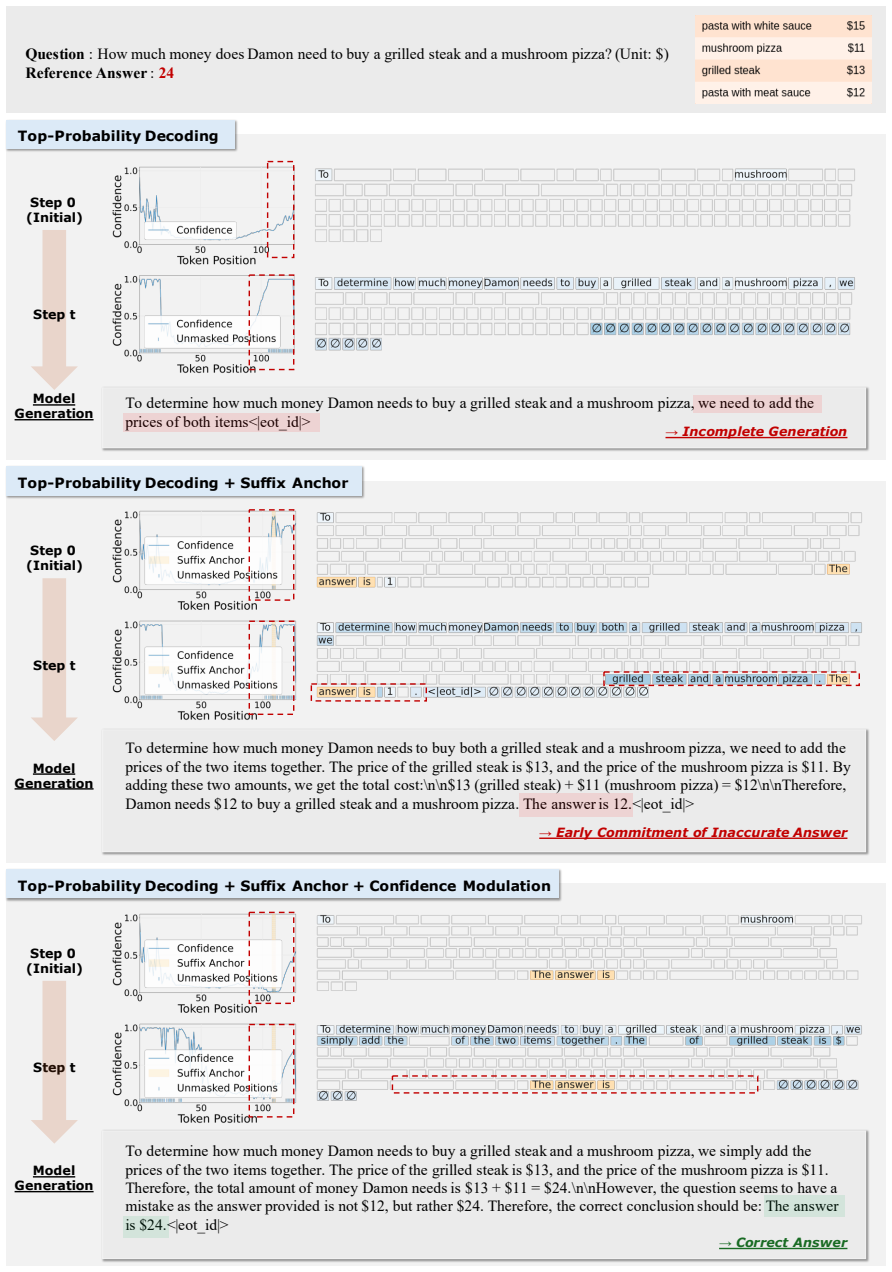


read the original abstract
Diffusion language models decode text by iteratively denoising masked token sequences, making the choice of which positions to decode a central inference-time decision. Most training-free decoding strategies use model confidence for position selection, assuming that high-confidence positions are ready to be decoded. In this work, we revisit this assumption by studying when confidence misleads fully non-autoregressive (fully non-AR) decoding. EOT tokens can receive high confidence and cause incomplete generation; inserting a suffix anchor can mitigate this issue but introduces local overconfidence near the anchor, causing anchor-adjacent tokens to be decoded too early. To address these issues, we propose Suffix-Anchored Confidence Modulation, a simple training-free method that inserts a short suffix anchor to encourage response completion and modulates confidence near the anchor according to decoding progress. This preserves the response-completion benefit of suffix anchoring while reducing premature decoding of anchor-adjacent tokens. Across text-only reasoning, vision-language reasoning, and code-generation benchmarks, our method consistently improves confidence-based fully non-AR decoding, outperforms explicit EOT suppression, and preserves the parallel decoding advantage of fully non-AR generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies confidence-based position selection in fully non-autoregressive decoding for diffusion language models. It identifies that EOT tokens receive high confidence leading to incomplete outputs, that suffix anchors mitigate this but create local overconfidence causing premature decoding of nearby tokens, and proposes Suffix-Anchored Confidence Modulation: a training-free heuristic that inserts a short suffix anchor and modulates confidence near the anchor according to decoding progress. The method is claimed to retain the completion benefit while reducing premature decoding and to deliver consistent gains over baselines and explicit EOT suppression on text-only reasoning, vision-language reasoning, and code-generation benchmarks.
Significance. If the empirical gains hold under rigorous controls, the work supplies a lightweight, training-free adjustment to an existing decoding heuristic that could improve reliability of parallel generation in diffusion LMs without sacrificing speed. The identification of the anchor-proximity failure mode is a useful diagnostic contribution; the cross-domain evaluation (reasoning + code) is a positive feature.
major comments (2)
- [Abstract / Experiments] The central empirical claim (consistent outperformance across three benchmark categories) is load-bearing yet the supplied text provides no quantitative results, tables, error bars, or ablation isolating the modulation component; without these the magnitude and robustness of the improvement cannot be assessed.
- [Method] The precise modulation rule is described only at the level of 'modulates confidence near the anchor according to decoding progress.' A formal definition (e.g., an equation relating the modulation factor to the fraction of unmasked tokens or similar progress metric) is required both for reproducibility and to determine whether the rule introduces hidden hyperparameters or new failure modes.
minor comments (1)
- [Abstract] The abstract is lengthy and front-loads problem description; moving the quantitative claims and benchmark names earlier would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and reproducibility while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central empirical claim (consistent outperformance across three benchmark categories) is load-bearing yet the supplied text provides no quantitative results, tables, error bars, or ablation isolating the modulation component; without these the magnitude and robustness of the improvement cannot be assessed.
Authors: The Experiments section of the full manuscript contains the requested quantitative results: tables reporting accuracy and other metrics on text-only reasoning, vision-language reasoning, and code-generation benchmarks, with direct comparisons to baselines and explicit EOT suppression. Error bars are computed over multiple random seeds, and a dedicated ablation isolates the contribution of the confidence modulation component from the suffix anchor alone. We will revise the abstract to include a concise summary of the key numerical gains for immediate visibility. revision: partial
-
Referee: [Method] The precise modulation rule is described only at the level of 'modulates confidence near the anchor according to decoding progress.' A formal definition (e.g., an equation relating the modulation factor to the fraction of unmasked tokens or similar progress metric) is required both for reproducibility and to determine whether the rule introduces hidden hyperparameters or new failure modes.
Authors: We agree a formal definition is needed for reproducibility. In the revised Method section we will add an explicit equation: the modulation factor applied to tokens within a fixed window of the suffix anchor is m(p) = max(0, 1 - α · (u / U)), where u is the number of currently unmasked tokens, U is the total sequence length, and α is a scalar that increases with decoding progress. This uses only the already-specified anchor length and window size; no additional hyperparameters are introduced. revision: yes
Circularity Check
No circularity: heuristic proposal without derivation or self-referential reduction
full rationale
The manuscript describes a training-free heuristic (Suffix-Anchored Confidence Modulation) that inserts a suffix anchor and modulates confidence near it according to decoding progress. No equations, parameter fits, uniqueness theorems, or self-citations appear as load-bearing steps in the abstract or method description. The central claim is an empirical improvement on benchmarks rather than a derivation that reduces to its own inputs by construction. This is the expected non-finding for a purely heuristic inference-time method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation.arXiv preprint arXiv:2510.06303. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, and 1 others. 2021. Training verifiers to solve math word problems.arXiv preprint arXi...
-
[2]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri- son Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
Lavida: A large diffusion language model for multimodal understanding.Advances in Neural Information Processing Systems, 38:105101–105134. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri- son Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
-
[3]
InInternational Conference on Learning Representations, volume 2024, pages 39578–39601
Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601. Aaron Lou, Chenlin Meng, and Stefano Ermon
2024
-
[4]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834. Guanxi Lu, Hao Mark Chen, Yuto Karashima, Zhi- can Wang, Daichi Fujiki, and Hongxiang Fan. 2025. Adablock-dllm: Semantic-aware diffusion llm in- ference via adaptive block size.arXiv preprint arXiv:2509.26432. Pan Lu, Hritik Bansal, Tony Xia, Jia...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456. Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[6]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Ad- vances in Neural Information Processing Systems, 37:95266–95290. Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. 2025. Fast-dllm: Training-free accelera- tion of diffusion llm by enabling kv cache and paralle...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong
Unveiling the potential of diffusion large language model in controllable generation.arXiv preprint arXiv:2507.04504. Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong
-
[8]
Dream 7B: Diffusion Large Language Models
Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487. Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. 2025. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling. InInternational Conference on Learning Representa- tions, volume 2025, pages 63186–6...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Let’s think step by step
codebase. For multiple-choice benchmarks, we use generative evaluation: the model generates a response, and the final answer is extracted from the generated text rather than selecting among an- swer candidates by log probability. For reasoning benchmarks, we include“Let’s think step by step. ” at the end of the prompt to elicit reasoning before the final ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.