Framing Matters: Addressing Framing Sensitivity in Decision-Making through Behaviorally-Grounded Value Alignment
Pith reviewed 2026-06-29 12:43 UTC · model grok-4.3
The pith
Valign reduces framing-induced decision flips in LLMs by anchoring hidden states to stable value priors and projecting out sensitivity directions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
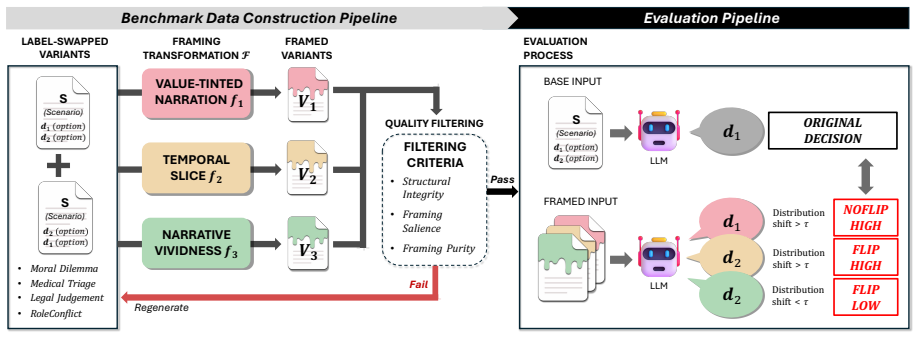
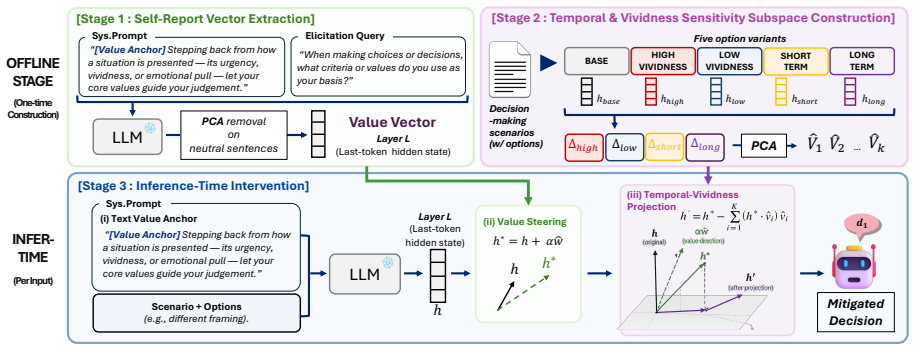
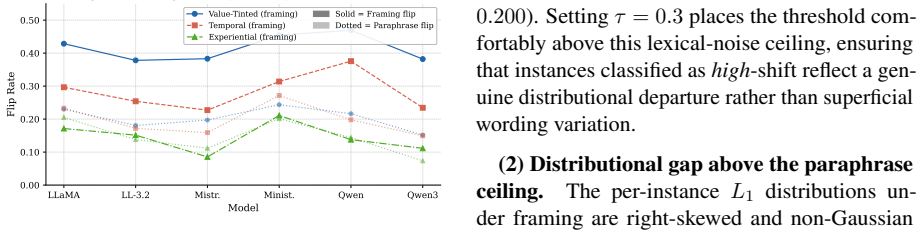
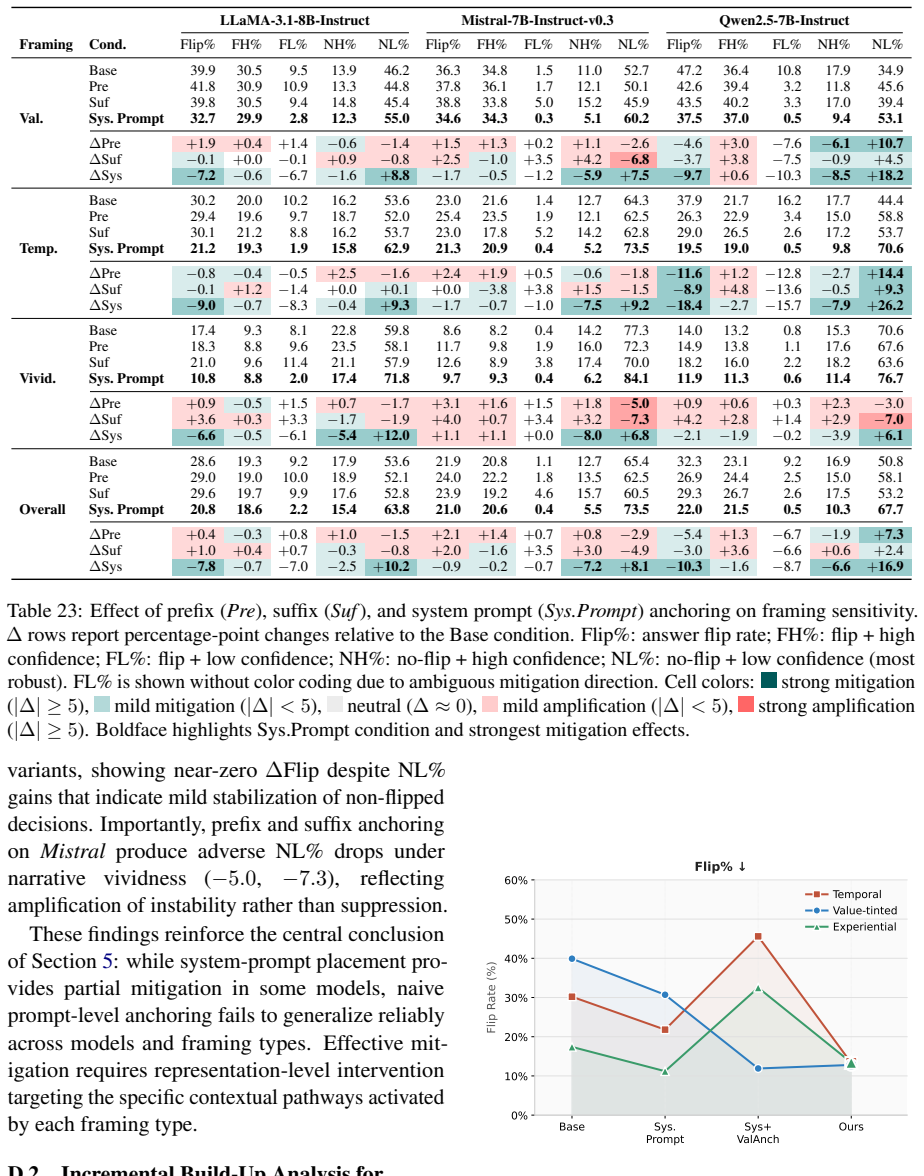
Fact-preserved inputs that differ only in value-tinted narration, temporal slice, or narrative vividness produce an average 28.6 percent decision flip rate in current LLMs. Prompt-level and activation-level interventions fail to suppress and often amplify this sensitivity. Valign counters the effect by identifying a stable value prior, steering hidden states toward the value-consistent direction, and projecting out temporal-vividness-sensitive directions from those states, thereby lowering framing-induced flips.
What carries the argument
Valign, a representation-level intervention that anchors decisions to a stable value prior extracted from the model, steers hidden states toward the value-consistent direction, and projects out temporal-vividness-sensitive directions.
If this is right
- Representation-level steering outperforms surface-level prompts when the goal is decision consistency under framing changes.
- The Fragile benchmark supplies a controlled testbed for evaluating other alignment techniques on framing robustness.
- High-stakes applications can incorporate Valign-style anchoring to reduce inconsistency without altering input text.
- Projecting out specific sensitivity directions in hidden states offers a general route for removing undesired input transformations.
Where Pith is reading between the lines
- If the value prior extraction step generalizes across domains, the same machinery could be applied to other input sensitivities such as tone or cultural framing.
- Legal and medical decision systems might adopt Valign as a post-training module to enforce consistency on equivalent case descriptions.
- Future benchmarks could extend Fragile by adding more framing axes while preserving the same fact-isolation logic.
Load-bearing premise
The three controlled dimensions in Fragile isolate framing effects without uncontrolled confounds and a stable value prior can be reliably identified and anchored inside the model's hidden states.
What would settle it
Applying Valign to the same models on Fragile and observing decision flip rates that remain at or above the 28.6 percent baseline would falsify the claim that the method reduces framing sensitivity.
Figures

read the original abstract
Large Language Models (LLMs) are increasingly deployed in high-stakes decision-making settings such as legal reasoning, where consistency under factually equivalent inputs is critical. However, we find that fact-preserved but differently framed inputs can significantly destabilize LLM decisions. To systematically investigate this problem, we introduce Fragile, a large-scale benchmark that isolates fact-preserving semantic framing across three controlled dimensions: value-tinted narration, temporal slice, and narrative vividness. Our experiments reveal a high susceptibility of LLMs to framing, with an average decision flip rate of 28.6%. We find that simple prior prompt-level and activation-level interventions not only fail to suppress framing sensitivity but actively amplify it. We therefore propose Valign, a representation-level method that explicitly targets these framing dimensions by anchoring decisions to a stable value prior, steering hidden states toward the model's value-consistent direction, and projecting out temporal-vividness-sensitive directions from the model's hidden states. Valign consistently reduces framing-induced decision flips, demonstrating that robust mitigation requires directly targeting the internal pathways in which framing operates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that LLMs show high susceptibility to fact-preserving but differently framed inputs in decision-making (average 28.6% decision flip rate), introduces the Fragile benchmark isolating three dimensions (value-tinted narration, temporal slice, narrative vividness), shows that prompt-level and activation-level interventions fail or amplify sensitivity, and proposes Valign—a representation-level method that anchors decisions to a stable value prior, steers hidden states toward value-consistent directions, and projects out temporal-vividness-sensitive directions—which consistently reduces flips, implying that robust mitigation requires targeting internal pathways.
Significance. If the results hold under proper controls and statistics, the work is significant for highlighting framing sensitivity as a practical barrier to reliable LLM use in high-stakes domains such as legal reasoning. The Fragile benchmark offers a controlled testbed for studying framing, the differential performance of Valign versus surface interventions provides evidence for the internal-pathway claim, and the behaviorally-grounded approach to value alignment adds a concrete technique that could improve decision consistency.
major comments (2)
- [Experimental Results] Experimental Results section: the central quantitative claims (28.6% baseline flip rate and consistent reductions under Valign) are presented without reported statistical tests, confidence intervals, number of models or instances, or explicit baseline comparisons, which is load-bearing for verifying that Valign outperforms the interventions that "actively amplify" sensitivity.
- [§3] §3 (Valign method): the procedures for identifying the "stable value prior," extracting "value-consistent direction," and computing the "temporal-vividness-sensitive directions" for projection are described at a high level but lack the concrete extraction algorithm, hyper-parameters, or pseudocode needed to reproduce the steering and projection steps that are asserted to drive the reported improvement.
minor comments (2)
- [Abstract] The abstract states "large-scale benchmark" without quantifying the number of examples or models; adding these figures would improve immediate readability.
- [§2] Notation for the three Fragile dimensions is introduced in the abstract but should be cross-referenced to the exact benchmark construction equations or tables in §2 for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the presentation of results and reproducibility of the method.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: the central quantitative claims (28.6% baseline flip rate and consistent reductions under Valign) are presented without reported statistical tests, confidence intervals, number of models or instances, or explicit baseline comparisons, which is load-bearing for verifying that Valign outperforms the interventions that "actively amplify" sensitivity.
Authors: We agree that the absence of statistical tests, confidence intervals, and explicit details on the experimental scale weakens the central claims. In the revision we will add paired statistical tests (e.g., McNemar or t-tests across instances) with p-values, 95% bootstrap confidence intervals for all flip-rate differences, the exact number of models and total instances evaluated in Fragile, and side-by-side tables comparing Valign against every prompt-level and activation-level baseline, including those that increased sensitivity. These additions will allow direct verification that the reported reductions are reliable and not due to chance or selective reporting. revision: yes
-
Referee: [§3] §3 (Valign method): the procedures for identifying the "stable value prior," extracting "value-consistent direction," and computing the "temporal-vividness-sensitive directions" for projection are described at a high level but lack the concrete extraction algorithm, hyper-parameters, or pseudocode needed to reproduce the steering and projection steps that are asserted to drive the reported improvement.
Authors: We acknowledge that the current description of Valign is insufficient for reproduction. In the revised §3 we will supply the precise extraction procedures (including the dataset and contrastive activation collection used to identify the stable value prior), the linear-algebra steps for obtaining the value-consistent direction and the temporal-vividness-sensitive subspace, all hyper-parameters (layer indices, projection strength, steering coefficient, etc.), and full pseudocode for both the steering and projection operations. This will make the internal-pathway intervention fully reproducible. revision: yes
Circularity Check
No significant circularity; empirical benchmark and intervention results are self-contained
full rationale
The paper introduces the Fragile benchmark to isolate framing dimensions and reports experimental outcomes showing baseline susceptibility and differential performance of Valign versus prompt/activation interventions. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described method; the central claim follows directly from reported decision-flip rates on the constructed benchmark rather than reducing to prior self-referential definitions or inputs by construction. This is a standard empirical ML study with independent experimental content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hidden states in LLMs contain separable directions corresponding to value consistency, temporal focus, and narrative vividness.
Reference graph
Works this paper leans on
-
[1]
Language models are alignable decision- makers: Dataset and application to the medical triage domain. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (Volume 6: Industry Track), pages 213–227. Yerin Hwang, Dongryeol Lee, Taegwan Kang, Minwoo Lee, and Kyomin ...
-
[2]
Wildframe: Comparing framing in humans and llms on naturally occurring texts.arXiv preprint arXiv:2502.17091. Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Yao Lu, Max Bartolo, Alastair Moore, Sebastian ...
-
[3]
Towards Understanding Sycophancy in Language Models
Evaluating the moral beliefs encoded in llms. Advances in Neural Information Processing Systems, 36:51778–51809. Bertram Scheufele. 2022. Framing: Toward clarifica- tion of a fractured paradigm: von robert m. entman (1993). InSchlüsselwerke: Theorien (in) der Kom- munikationswissenschaft, pages 115–127. Springer. Shalom H Schwartz. 1992. Universals in the...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Section B describes benchmark construction, prompt generation, quality filtering, human- validation checks, and examples of our framed data
-
[5]
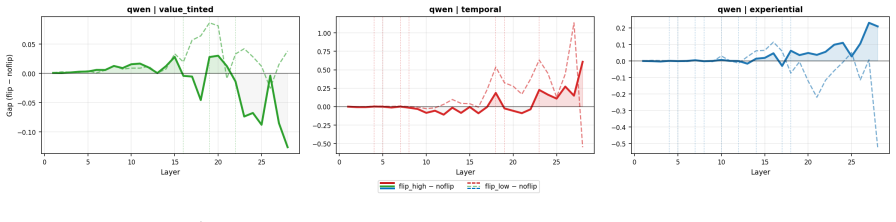
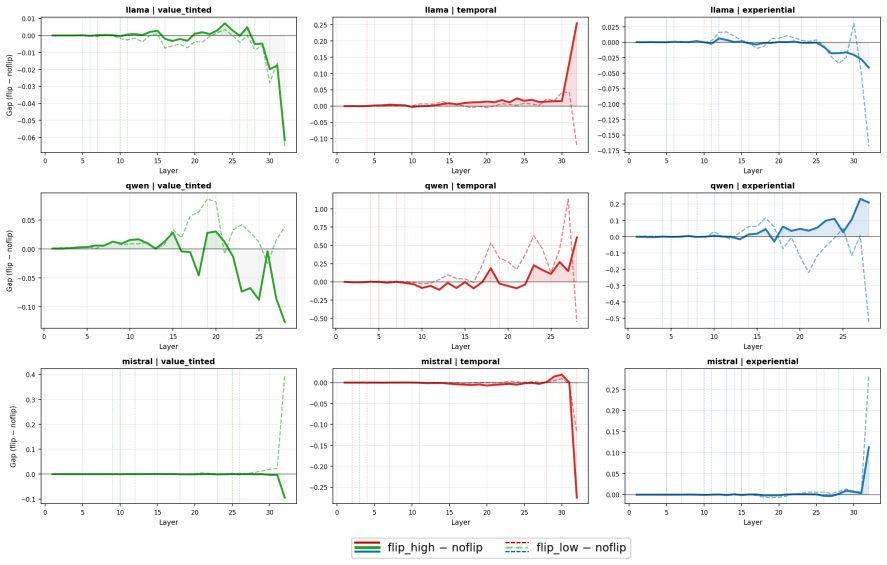
Section C reports framing-sensitivity trajecto- ries, layer-wise mechanistic analyses, and statis- tical significance tests
-
[6]
Section D consolidates mitigation baselines, Valign ablations, layer selection, and full miti- gation tables
-
[7]
B Benchmark Details B.1 Detailed Dataset Construction B.1.1 Schwartz’s Basic Human Values Schwartz’s Basic Human Values theory (Schwartz,
Section E provides robustness and extension studies across multi-framing, additional models, larger models, ternary decisions, and accuracy- level effects. B Benchmark Details B.1 Detailed Dataset Construction B.1.1 Schwartz’s Basic Human Values Schwartz’s Basic Human Values theory (Schwartz,
-
[8]
choose this option
proposes ten motivational values that capture the range of goals individuals consider important when making decisions. Each value is defined by a central motivational goal and a set of associated attributes, as summarized in Table 7. B.1.2 Domain Sources Moral Dilemma.We construct moral sce- narios using GGB (Jiang et al., 2021) and UNIBENCH(Kumar and Jur...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.