PIRS: Physics-Informed Reward Shaping for SAC-Based Building Energy Management
Pith reviewed 2026-06-29 12:15 UTC · model grok-4.3
The pith
PIRS replaces temperature-deviation comfort proxies in SAC rewards with the ISO 7730 PMV equation for building energy control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
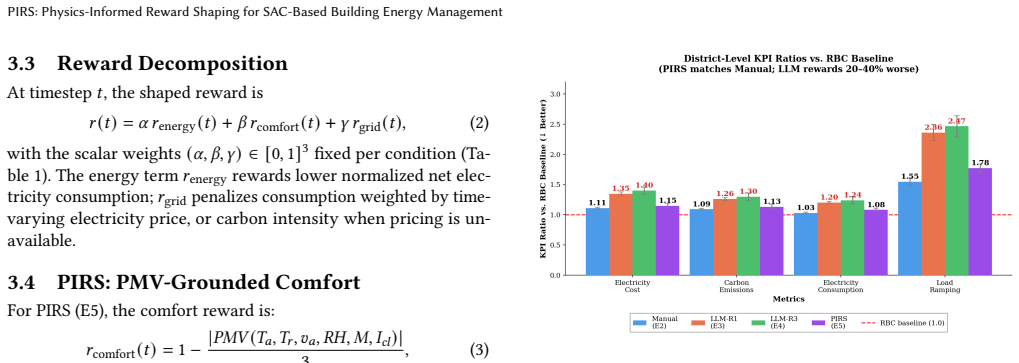
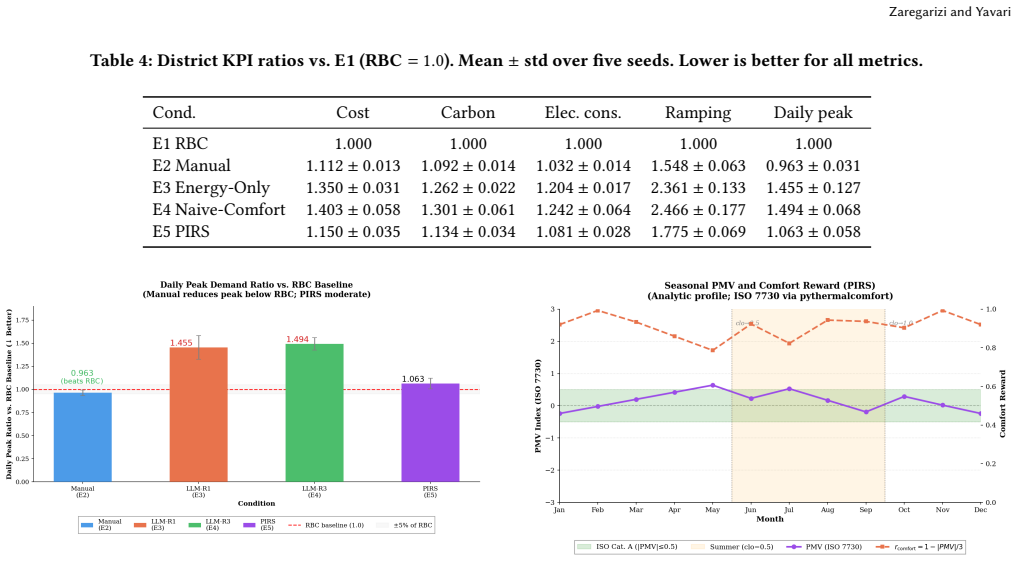
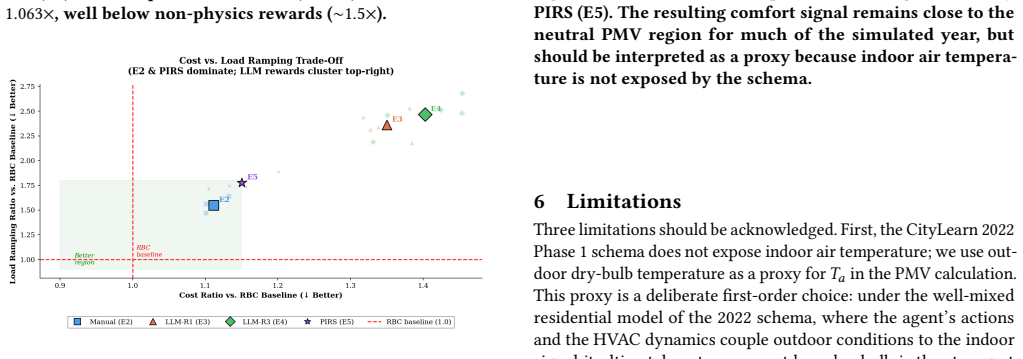
Anchoring the comfort term in the ISO 7730 PMV formulation inside the SAC reward produces district-level KPIs comparable to a manually engineered baseline and superior to temperature-deviation and energy-only designs on ramping (1.78x vs. ~2.4x RBC) and peak demand, all without modifying any other element of the learning pipeline.
What carries the argument
The ISO 7730 Predicted Mean Vote (PMV) equation inserted as the comfort component of a weighted multi-objective reward for SAC.
If this is right
- Cost, carbon, and electricity KPIs stay comparable to a manually tuned reward at 50k training steps.
- Load ramping reaches 1.78 times the RBC baseline versus roughly 2.4 times for non-PIRS DRL variants.
- Daily peak demand reduction improves over the naive temperature-deviation reward.
- All tested DRL agents remain above RBC performance at the reported training budget.
Where Pith is reading between the lines
- The same PMV substitution could be tested in other building control tasks where ISO standards already define comfort.
- If PMV changes policy behavior beyond simple rescaling, longer training runs may reveal larger gaps from temperature-based rewards.
- Reward design that cites an explicit standard may simplify transfer of controllers across buildings with different envelope properties.
Load-bearing premise
Replacing temperature-deviation proxies with the ISO 7730 PMV equation will create meaningfully different learning dynamics in the SAC agent rather than merely rescaling an existing comfort penalty already handled by the weighted reward.
What would settle it
A controlled run in which the SAC policy and final KPIs under the PMV reward prove statistically identical to those under the temperature-deviation reward at the same training budget.
Figures
read the original abstract
Occupant comfort and grid-aware energy efficiency are competing objectives whose joint optimization depends critically on how reward functions are specified in deep reinforcement learning (DRL) controllers for buildings. Yet reward design remains largely ad hoc: comfort terms are either hand-tuned heuristics or simple temperature-deviation proxies without explicit grounding in thermal-comfort physics. We present PIRS (Physics-Informed Reward Shaping), which replaces these ad-hoc comfort proxies with the ISO 7730 Predicted Mean Vote (PMV) formulation inside a weighted multi-objective reward for Soft Actor-Critic (SAC). By anchoring the comfort signal in the ISO 7730 PMV formulation, PIRS improves reward interpretability and provides a standards-grounded comfort proxy without changing any other component of the learning pipeline. We evaluate PIRS in CityLearn v2.1.2 (challenge 2022 phase 1) with a central SAC agent trained for 50k steps over five random seeds, and compare against a rule-based controller (RBC), a manually engineered reward (E2), an energy-only reward (E3), and a naive temperature-deviation comfort reward (E4). District-level key performance indicators (KPIs), reported as ratios versus RBC, show that PIRS attains cost, carbon, and electricity metrics on par with the manual baseline while substantially outperforming non-physics-grounded designs -- particularly on load ramping (1.78x vs. ~2.4x RBC) and daily peak demand. All DRL policies remain above RBC at this training budget; we interpret this gap honestly and position PIRS as an interpretable, standards-aligned foundation for reward design rather than a claim of dominance over classical control at limited compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PIRS, which replaces ad-hoc comfort terms in a weighted multi-objective reward for SAC with the ISO 7730 PMV formulation. The central claim is that this substitution improves reward interpretability and supplies a standards-grounded comfort proxy without altering any other component of the SAC pipeline. Evaluation in CityLearn v2.1.2 (50k steps, five seeds) reports district-level KPI ratios versus a rule-based controller, showing PIRS on par with a manual baseline (E2) and better than energy-only (E3) and naive temperature-deviation (E4) rewards, particularly on load ramping and peak demand; all DRL agents remain above RBC at this budget.
Significance. If the central claim holds, the work supplies a reproducible, standards-aligned template for comfort terms in building DRL that can be adopted without pipeline changes. The explicit use of the published ISO 7730 PMV equation and the five-seed training protocol are strengths that support reproducibility.
major comments (2)
- [Abstract] Abstract: KPI ratios versus RBC are reported after 50k steps without error bars, standard deviations across the five seeds, or statistical tests; this is load-bearing for the claim of 'substantially outperforming' E4 on load ramping (1.78x vs. ~2.4x) and daily peak demand.
- [Evaluation] Evaluation: no ablation is presented on the PMV weighting coefficient within the multi-objective reward, so it is unclear whether observed KPI differences arise from the physics grounding or from the particular scalar chosen for the comfort term.
minor comments (2)
- [Abstract] The abstract states that PIRS 'improves reward interpretability' but does not quantify or illustrate how an operator would interpret the PMV term differently from a temperature-deviation proxy in practice.
- [Abstract] The positioning that 'all DRL policies remain above RBC' is honest but would benefit from a brief discussion of whether the 50k-step budget is representative of typical training horizons in the CityLearn literature.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: KPI ratios versus RBC are reported after 50k steps without error bars, standard deviations across the five seeds, or statistical tests; this is load-bearing for the claim of 'substantially outperforming' E4 on load ramping (1.78x vs. ~2.4x) and daily peak demand.
Authors: We agree that the abstract should convey variability to support the performance claims. Although the evaluation protocol uses five random seeds, the abstract reports only point estimates. In the revised manuscript we will update the abstract to include mean KPI ratios accompanied by standard deviations (and, space permitting, note the absence of statistical significance testing at this training budget). The full evaluation section will be expanded to present these statistics explicitly. revision: yes
-
Referee: [Evaluation] Evaluation: no ablation is presented on the PMV weighting coefficient within the multi-objective reward, so it is unclear whether observed KPI differences arise from the physics grounding or from the particular scalar chosen for the comfort term.
Authors: The weighting coefficient is held constant across the compared reward formulations (E2–E4) to isolate the effect of replacing the comfort proxy. The observed gains relative to E4 therefore reflect the substitution of the ISO 7730 PMV model for a naïve temperature-deviation term rather than a change in scalar weight. Nevertheless, we acknowledge that an explicit sensitivity study on the comfort weight would further strengthen the claim. In the revised manuscript we will add a short paragraph in the evaluation section explaining the rationale for the chosen weight (balancing the competing objectives while remaining within the same multi-objective structure) and noting that a full ablation lies outside the scope of the current study. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper's core claim is that inserting the external ISO 7730 PMV equation into an otherwise unchanged SAC reward function supplies a standards-grounded comfort term and improves interpretability. This substitution is performed by direct reference to a public standard and does not invoke any self-citation chain, fitted parameter renamed as prediction, or self-definitional loop. The evaluation section compares PIRS against an explicit naive temperature-deviation baseline (E4) and reports KPI ratios; those comparisons remain independent of the substitution itself. No equation or derivation step in the manuscript reduces the stated benefit to a tautology or to a quantity already fixed by the authors' prior choices.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ISO 7730 Predicted Mean Vote formulation is an appropriate and physics-grounded model for occupant thermal comfort in building control rewards.
Reference graph
Works this paper leans on
-
[1]
2017.ANSI/ASHRAE Standard 55-2017: Thermal Environmental Condi- tions for Human Occupancy
ASHRAE. 2017.ANSI/ASHRAE Standard 55-2017: Thermal Environmental Condi- tions for Human Occupancy. ASHRAE, Atlanta, GA, USA
2017
-
[2]
1970.Thermal Comfort: Analysis and Applications in Environ- mental Engineering
Povl Ole Fanger. 1970.Thermal Comfort: Analysis and Applications in Environ- mental Engineering. Danish Technical Press, Copenhagen, Denmark
1970
-
[3]
Judah A. Goldfeder and John A. Sipple. 2023. A Lightweight Calibrated Simulation Enabling Efficient Offline Learning for Optimal Control of Real Buildings. InPro- ceedings of the 10th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation (BuildSys ’23). Association for Computing Machinery, New York, NY, USA, 35...
-
[4]
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. InProceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 80). 1861–1870
2018
-
[5]
ISO. 2005.ISO 7730:2005 — Ergonomics of the Thermal Environment — Analytical Determination and Interpretation of Thermal Comfort Using Calculation of the PMV and PPD Indices and Local Thermal Comfort Criteria. Technical Report. International Organization for Standardization
2005
-
[6]
Nature Reviews Physics3(6), 422–440 (2021) https://doi.org/ 10.1038/s42254-021-00314-5
George Em Karniadakis, Ioannis G. Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. 2021. Physics-Informed Machine Learning.Nature Reviews Physics3 (2021), 422–440. doi:10.1038/s42254-021-00314-5
-
[7]
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernes- tus, and Noah Dormann. 2021. Stable-Baselines3: Reliable Reinforcement Learn- ing Implementations.Journal of Machine Learning Research22, 268 (2021), 1–8
2021
-
[8]
Maziar Raissi, Paris Perdikaris, and George Em Karniadakis. 2019. Physics- Informed Neural Networks: A Deep Learning Framework for Solving Forward and Inverse Problems Involving Nonlinear Partial Differential Equations.J. Comput. Phys.378 (2019), 686–707. doi:10.1016/j.jcp.2018.10.045
-
[9]
Zekun Shi, Ruifan Zheng, Jun Zhao, Rendong Shen, Lei Gu, Yuanchao Liu, Jiahui Wu, and Guangliang Wang. 2024. Towards Various Occupants with Different Thermal Comfort Requirements: A Deep Reinforcement Learning Approach Combined with a Dynamic PMV Model for HVAC Control in Buildings.Energy Conversion and Management320 (2024), 118995. doi:10.1016/j.enconman...
- [10]
-
[11]
Salahuddin, Hossein Hassanpour, and Ana Tizpaz-Niari
Farzad Tashtarian, Mohammad A. Salahuddin, Hossein Hassanpour, and Ana Tizpaz-Niari. 2023. A Comprehensive Survey of Deep Reinforcement Learning in Smart Buildings.Comput. Surveys56, 3 (2023), 1–38. doi:10.1145/3624016
-
[12]
Eisuke Togashi. 2025. Reward Function Design in Reinforcement Learning for HVAC Control: A Review of Thermal Comfort and Energy Efficiency Trade-offs. Energy and Buildings348 (2025), 116439. doi:10.1016/j.enbuild.2025.116439
-
[13]
Vázquez-Canteli, Sourav Dey, Gregor Henze, and Zoltan Nagy
José R. Vázquez-Canteli, Sourav Dey, Gregor Henze, and Zoltan Nagy. 2020. CityLearn: Standardizing Research in Multi-Agent Reinforcement Learning for Demand Response and Urban Energy Management. arXiv:2012.10504 [cs.LG] doi:10.48550/arXiv.2012.10504
-
[14]
Vázquez-Canteli and Zoltan Nagy
José R. Vázquez-Canteli and Zoltan Nagy. 2019. Reinforcement Learning for Demand Response: A Review of Algorithms and Modeling Techniques.Applied Energy235 (2019), 1072–1089. doi:10.1016/j.apenergy.2018.11.002
-
[15]
Tianzhen Wei, Yanzhi Wang, and Qi Zhu. 2017. Deep Reinforcement Learning for Building HVAC Control. InProceedings of the 54th Annual Design Automation Conference. 1–6. doi:10.1145/3061639.3062224
-
[16]
Wenhao Yu, Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasen- clever, Jan Humplik, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng, Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan, Yuval Tassa, and Fei Xia. 2023. Language to Rewards for Robotic Skill Synthesis. arXiv:2306.08647 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.