PointQ-Bench: Benchmarking Diagnostic and Interpretable Point Cloud Quality Assessment
Pith reviewed 2026-06-29 13:57 UTC · model grok-4.3
The pith
PointQ-Bench reveals that current models perceive point cloud defects coarsely but fail at grounded diagnosis and quality calibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
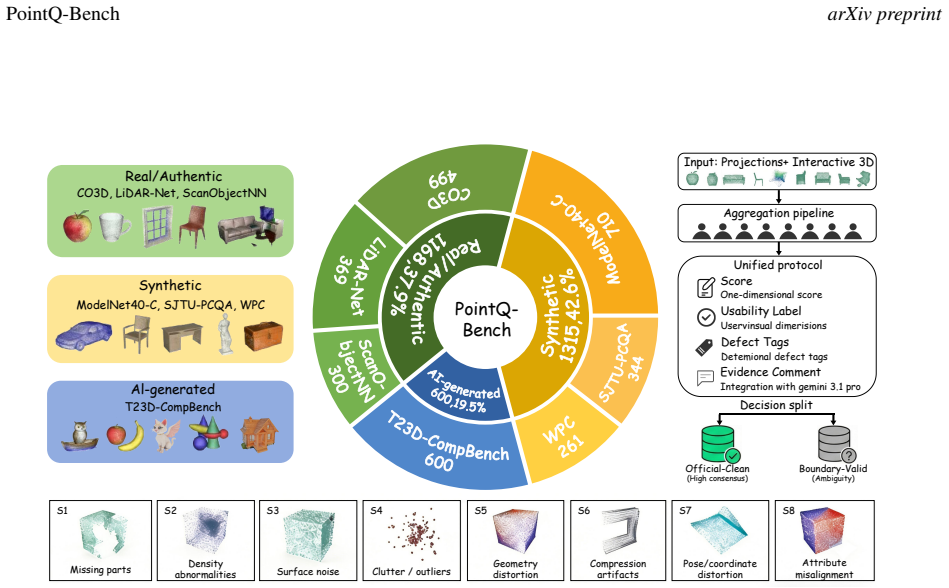
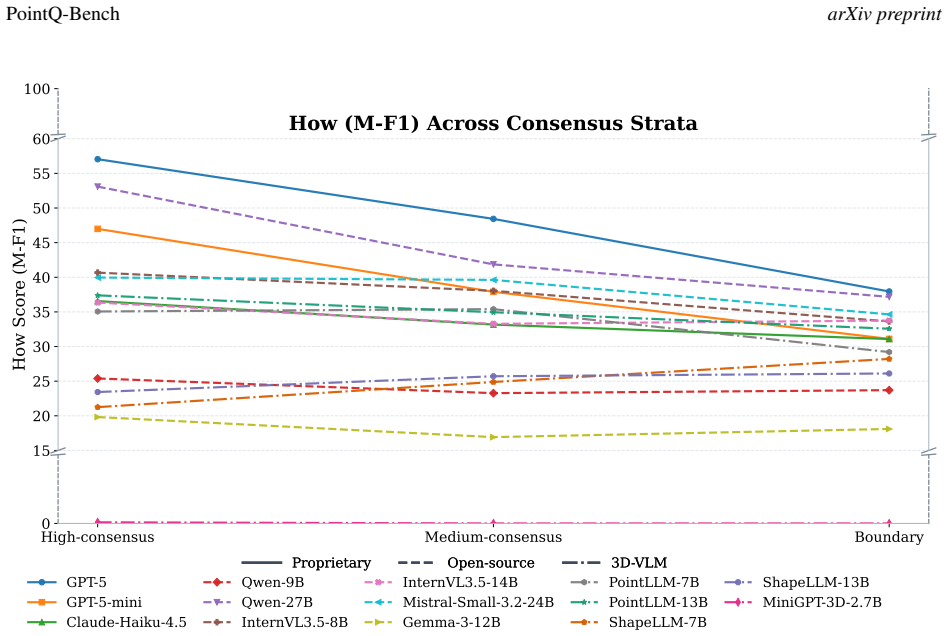
PointQ-Bench extends point cloud quality assessment beyond scalar scoring by supplying expert-grounded annotations on authentic, simulated, and generated samples for tasks in anomaly sensing, defect diagnosis, usability grading, and quality reporting; evaluation with the SSFRQ-5D protocol on 14 models establishes a consistent perception-diagnosis gap in which coarse defect perception appears but grounded diagnosis and quality calibration remain weak, and strong 2D MLLMs generally outperform existing 3D VLMs with non-uniform benefits from additional views.
What carries the argument
PointQ-Bench benchmark of 3,083 annotated point clouds together with the SSFRQ-5D five-dimensional protocol for scoring free-form quality descriptions.
If this is right
- Targeted training focused on grounded diagnosis is required beyond current coarse perception capabilities.
- Strong 2D MLLMs provide better starting points than existing 3D VLMs for point cloud quality tasks.
- Benefits from multi-view or point-level inputs vary by task, data source, and model, especially under ambiguous boundaries.
- The benchmark supports evaluation of interpretable quality understanding needed for practical 3D inspection workflows.
Where Pith is reading between the lines
- Consistent outperformance by 2D models suggests projection-based methods may remain preferable until native 3D architectures close the diagnosis gap.
- Non-uniform gains from extra views imply that input-selection strategies could be tuned per application using the benchmark results.
- The human-AI agreement validation of SSFRQ-5D indicates the protocol could transfer to description-based evaluation in other 3D or multimodal settings.
Load-bearing premise
The expert-grounded descriptions, issue tags, and QA pairs in the 3,083 samples accurately capture human perception and remain consistent enough for reliable model evaluation across tasks.
What would settle it
A follow-up study in which newly trained models achieve high accuracy on the defect diagnosis and usability grading tasks while human raters still disagree with the SSFRQ-5D scores on the same samples would falsify the reported perception-diagnosis gap.
Figures

read the original abstract
Point cloud quality plays a critical role in 3D acquisition, reconstruction, rendering, and perception, yet existing point cloud quality assessment (PCQA) research remains largely centered on scalar score prediction. In practical inspection scenarios, quality assessment often involves identifying defects, characterizing dominant issue types, assessing downstream usability, and providing evidence-supported descriptions, which are not explicitly evaluated by current benchmarks. We introduce PointQ-Bench, a benchmark designed to extend PCQA from scalar scoring toward comprehensive quality understanding. PointQ-Bench consists of 3,083 point clouds spanning authentic scans, simulated distortions, and AI-generated content, covering eight major issue types. Each sample is annotated with mean opinion scores (MOS), quality levels, issue tags, expert-grounded descriptions, and 12,332 question-answer pairs. The benchmark supports three perception-oriented tasks: anomaly sensing, defect diagnosis, and usability grading, as well as a cognition-oriented task of open-ended quality reporting. To evaluate free-form quality descriptions, we further propose SSFRQ-5D, a five-dimensional evaluation protocol validated through human-AI agreement analysis. Extensive experiments on 14 vision-language models and traditional PCQA baselines reveal a consistent perception-diagnosis gap: while current models exhibit emerging abilities in coarse defect perception, they struggle with grounded diagnosis and quality calibration. Strong 2D MLLMs generally outperform existing 3D VLMs, and the benefit of additional views or point-level inputs is non-uniform, varying across tasks, data sources, and models, particularly under boundary-ambiguous conditions. Overall, PointQ-Bench provides a diagnostic testbed for advancing reliable and interpretable point cloud quality understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PointQ-Bench, a benchmark of 3,083 point clouds (authentic scans, simulated distortions, AI-generated) annotated with MOS, quality levels, issue tags, expert-grounded descriptions, and 12,332 QA pairs. It defines four tasks—anomaly sensing, defect diagnosis, usability grading, and open-ended quality reporting—and proposes the SSFRQ-5D protocol (validated via human-AI agreement) for scoring free-form descriptions. Experiments on 14 VLMs and traditional PCQA baselines report a perception-diagnosis gap, with 2D MLLMs generally outperforming 3D VLMs and non-uniform benefits from multi-view or point-level inputs.
Significance. If the annotations are shown to be reliable, the benchmark would usefully shift PCQA evaluation from scalar prediction toward diagnostic and interpretable assessment. The multi-task design, release of the dataset, and SSFRQ-5D protocol are constructive contributions. The absence of inter-annotator agreement statistics for the core annotations, however, prevents a clear assessment of whether the reported model gaps reflect genuine capability differences or annotation variability.
major comments (2)
- [Benchmark construction] Benchmark construction section: no inter-annotator agreement metrics (Cohen’s kappa, Krippendorff’s alpha, or pairwise consistency rates) are reported for the issue tags, expert-grounded descriptions, or QA pairs on the 3,083 samples. Because the central claims about the perception-diagnosis gap and 2D-vs-3D model ordering rest on these annotations serving as stable ground truth, the lack of reliability statistics is load-bearing for the experimental conclusions.
- [Experiments] Experimental setup and results sections: data splits, cross-validation procedure, and any statistical significance tests for the reported performance differences across models and tasks are not described. Without these, it is impossible to determine whether the observed gaps are robust or sensitive to particular partitions of the 3,083 samples.
minor comments (1)
- [Abstract] The abstract states that SSFRQ-5D is “validated through human-AI agreement analysis,” yet the precise protocol, number of raters, and agreement values are not summarized even at a high level; adding a one-sentence quantitative statement would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The two major comments identify important omissions that affect the transparency and interpretability of our results. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: no inter-annotator agreement metrics (Cohen’s kappa, Krippendorff’s alpha, or pairwise consistency rates) are reported for the issue tags, expert-grounded descriptions, or QA pairs on the 3,083 samples. Because the central claims about the perception-diagnosis gap and 2D-vs-3D model ordering rest on these annotations serving as stable ground truth, the lack of reliability statistics is load-bearing for the experimental conclusions.
Authors: We agree that quantitative inter-annotator agreement statistics are necessary to substantiate the reliability of the annotations used as ground truth. The original manuscript omitted these metrics. In the revised version we will compute and report Krippendorff’s alpha (and pairwise consistency rates where appropriate) for issue tags, expert-grounded descriptions, and QA pairs, using the multiple annotations collected during the benchmark construction process. These statistics will be added to the benchmark construction section to directly support the stability of the reported perception-diagnosis gap and model orderings. revision: yes
-
Referee: [Experiments] Experimental setup and results sections: data splits, cross-validation procedure, and any statistical significance tests for the reported performance differences across models and tasks are not described. Without these, it is impossible to determine whether the observed gaps are robust or sensitive to particular partitions of the 3,083 samples.
Authors: We concur that explicit documentation of data partitioning and statistical testing is required for assessing robustness. The original manuscript did not include these details. In the revision we will add a dedicated experimental setup subsection that specifies the train/test splits (stratified by source and issue type), any cross-validation procedure employed, and the statistical tests (e.g., paired significance tests with p-values or confidence intervals) used to evaluate performance differences across models and tasks. revision: yes
Circularity Check
No circularity: benchmark construction and empirical evaluation are self-contained
full rationale
The paper's core contribution is the creation of PointQ-Bench (3,083 samples with MOS, tags, descriptions, and QA pairs) plus the SSFRQ-5D protocol, followed by empirical evaluation of 14 VLMs. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The perception-diagnosis gap claim rests on direct model testing against the new annotations rather than any reduction to prior fitted results or self-referential definitions. Human-AI agreement is cited only for protocol validation, not as a load-bearing self-citation. This is a standard benchmark paper with independent empirical content.
Axiom & Free-Parameter Ledger
invented entities (2)
-
PointQ-Bench
no independent evidence
-
SSFRQ-5D
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Predicting the perceptual quality of point cloud: A 3d-to-2d projection-based exploration.IEEE Transactions on Multimedia, 2020
Qi Yang, Hao Chen, Zhan Ma, Yiling Xu, Rongjun Tang, and Jun Sun. Predicting the perceptual quality of point cloud: A 3d-to-2d projection-based exploration.IEEE Transactions on Multimedia, 2020
2020
-
[2]
Perceptual quality assessment of colored 3d point clouds.IEEE Transactions on Visualization and Computer Graphics, 29(8):3642–3655, 2023
Honglei Su, Qi Liu, Zhengfang Duanmu, Wentao Liu, and Zhou Wang. Perceptual quality assessment of colored 3d point clouds.IEEE Transactions on Visualization and Computer Graphics, 29(8):3642–3655, 2023
2023
-
[3]
Xinju Wu, Yun Zhang, Chunling Fan, Junhui Hou, and Sam Kwong. Subjective quality database and objective study of compressed point clouds with 6DoF head-mounted display.IEEE Transactions on Circuits and Systems for Video Technology, 31(12):4630–4644, 2021
2021
-
[4]
Ali Ak, Emin Zerman, Maurice Quach, Aladine Chetouani, Aljosa Smolic, Giuseppe Valenzise, and Patrick Le Callet. Basics: Broad quality assessment of static point clouds in compression scenarios.arXiv preprint arXiv:2302.04796, 2023
-
[5]
Yipeng Liu, Qi Yang, Yiling Xu, and Le Yang. Point cloud quality assessment: Dataset construction and learning- based no-reference metric.ACM Transactions on Multimedia Computing, Communications, and Applications, 18(3):1–24, 2022
2022
-
[6]
Deep learning for 3d point clouds: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(12):4338–4364, 2021
Yulan Guo, Hanyun Wang, Qingyong Hu, Hao Liu, Li Liu, and Mohammed Bennamoun. Deep learning for 3d point clouds: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(12):4338–4364, 2021
2021
-
[7]
T3Bench: Benchmarking current progress in text-to-3d generation.CoRR, abs/2310.02977, 2023
Yuze He, Yushi Bai, Matthieu Lin, Wang Zhao, Yubin Hu, Jenny Sheng, Ran Yi, Juanzi Li, and Yong-Jin Liu. T3Bench: Benchmarking current progress in text-to-3d generation.CoRR, abs/2310.02977, 2023. 11 PointQ-Bench arXiv preprint 100 15 20 25 30 35 40 45 50 55 60How Score (M-F1) How (M-F1) Across Consensus Strata High-consensus Medium-consensus Boundary 0 P...
-
[8]
Benchmarking and learning multi-dimensional quality evaluator for text-to-3d generation
Yujie Zhang, Bingyang Cui, Qi Yang, Zhu Li, and Yiling Xu. Benchmarking and learning multi-dimensional quality evaluator for text-to-3d generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 18563–18574, 2025
2025
-
[9]
Bingyang Cui, Yujie Zhang, Qi Yang, Zhu Li, and Yiling Xu. Towards fine-grained text-to-3d quality assessment: A benchmark and a two-stage rank-learning metric.arXiv preprint arXiv:2509.23841, 2025
-
[10]
Pcqm: A full-reference quality metric for colored 3d point clouds
Gabriel Meynet, Yana Nehmé, Julie Digne, and Guillaume Lavoué. Pcqm: A full-reference quality metric for colored 3d point clouds. In2020 Twelfth International Conference on Quality of Multimedia Experience (QoMEX), pages 1–6. IEEE, 2020
2020
-
[11]
Ms-graphsim: Inferring point cloud quality via multiscale graph similarity
Yujie Zhang, Qi Yang, and Yiling Xu. Ms-graphsim: Inferring point cloud quality via multiscale graph similarity. InProceedings of the 29th ACM International Conference on Multimedia, pages 1230–1238, 2021
2021
-
[12]
Mped: Quantifying point cloud distortion based on multiscale potential energy discrepancy.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(5):6037–6054, 2022
Qi Yang, Yujie Zhang, Siheng Chen, Yiling Xu, Jun Sun, and Zhan Ma. Mped: Quantifying point cloud distortion based on multiscale potential energy discrepancy.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(5):6037–6054, 2022
2022
-
[13]
Reduced-reference quality assessment of point clouds via content-oriented saliency projection.IEEE Signal Processing Letters, 30:354–358, 2023
Wei Zhou, Guanghui Yue, Ruizeng Zhang, Yipeng Qin, and Hantao Liu. Reduced-reference quality assessment of point clouds via content-oriented saliency projection.IEEE Signal Processing Letters, 30:354–358, 2023
2023
-
[14]
No-reference point cloud quality assessment via domain adaptation
Qi Yang, Yipeng Liu, Siheng Chen, Yiling Xu, and Jun Sun. No-reference point cloud quality assessment via domain adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21147–21156, 2022
2022
-
[15]
Gpa-net: No-reference point cloud quality assessment with multi-task graph convolutional network.IEEE Transactions on Visualization and Computer Graphics, 30(8):4955–4967, 2024
Ziyu Shan, Qi Yang, Rui Ye, Yujie Zhang, Yiling Xu, Xiaozhong Xu, and Shan Liu. Gpa-net: No-reference point cloud quality assessment with multi-task graph convolutional network.IEEE Transactions on Visualization and Computer Graphics, 30(8):4955–4967, 2024
2024
-
[16]
Perceptual quality assessment for point clouds: A survey.ZTE Communications, (4):3–16, 2023
Yingjie Zhou, Zicheng Zhang, Wei Sun, Xiongkuo Min, and Guangtao Zhai. Perceptual quality assessment for point clouds: A survey.ZTE Communications, (4):3–16, 2023
2023
-
[17]
Dpcd: A quality assessment database for dynamic point clouds.arXiv preprint arXiv:2505.12431, 2025
Yating Liu, Yujie Zhang, Qi Yang, Yiling Xu, Zhu Li, and Ye-Kui Wang. Dpcd: A quality assessment database for dynamic point clouds.arXiv preprint arXiv:2505.12431, 2025. 12 PointQ-Bench arXiv preprint
-
[18]
No-reference point cloud quality assessment via weighted patch quality prediction
Jun Cheng, Honglei Su, and Jari Korhonen. No-reference point cloud quality assessment via weighted patch quality prediction. InProceedings of the 35th International Conference on Software Engineering and Knowledge Engineering (SEKE), pages 298–303, 2023
2023
-
[19]
Zhiyong Su, Chao Chu, Long Chen, Yong Li, and Weiqing Li. No-reference point cloud geometry quality assessment based on pairwise rank learning.CoRR, abs/2211.01205, 2022
-
[20]
Qi Liu, Yiyun Liu, Honglei Su, Hui Yuan, and Raouf Hamzaoui. Progressive knowledge transfer based on human visual perception mechanism for perceptual quality assessment of point clouds.CoRR, abs/2211.16646, 2022
-
[21]
Contrastive pre-training with multi-view fusion for no-reference point cloud quality assessment
Ziyu Shan, Yujie Zhang, Qi Yang, Haichen Yang, Yiling Xu, Jenq-Neng Hwang, Xiaozhong Xu, and Shan Liu. Contrastive pre-training with multi-view fusion for no-reference point cloud quality assessment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 25942–25951, 2024
2024
-
[22]
Mm-pcqa: Multi-modal learning for no-reference point cloud quality assessment
Zicheng Zhang, Wei Sun, Xiongkuo Min, Quan Zhou, Jun He, Qiyuan Wang, and Guangtao Zhai. Mm-pcqa: Multi-modal learning for no-reference point cloud quality assessment. InProceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2023
2023
-
[23]
Once-training-all-fine: No-reference point cloud quality assessment via domain-relevance degradation description.IEEE Transactions on Broadcasting, 71(2):616–630, 2025
Yipeng Liu, Qi Yang, Yujie Zhang, Yiling Xu, Le Yang, Xiaozhong Xu, and Shan-Lin Liu. Once-training-all-fine: No-reference point cloud quality assessment via domain-relevance degradation description.IEEE Transactions on Broadcasting, 71(2):616–630, 2025
2025
-
[24]
Lmm-pcqa: Assisting point cloud quality assessment with lmm.arXiv preprint arXiv:2404.18203, 2024
Zicheng Zhang, Haoning Wu, Yingjie Zhou, Chunyi Li, Wei Sun, Chaofeng Chen, Xiongkuo Min, Xiaohong Liu, Weisi Lin, and Guangtao Zhai. Lmm-pcqa: Assisting point cloud quality assessment with lmm.arXiv preprint arXiv:2404.18203, 2024
-
[25]
Clip-pcqa: Exploring subjective-aligned vision-language modeling for point cloud quality assessment
Yating Liu, Yujie Zhang, Ziyu Shan, and Yiling Xu. Clip-pcqa: Exploring subjective-aligned vision-language modeling for point cloud quality assessment. InProceedings of the AAAI Conference on Artificial Intelligence, 2025
2025
- [26]
-
[27]
Towards explainable in-the-wild video quality assessment: A database and a language-prompted approach
Haoning Wu, Erli Zhang, Liang Liao, Chaofeng Chen, Jingwen Hou, Annan Wang, Wenxiu Sun, Qiong Yan, and Weisi Lin. Towards explainable in-the-wild video quality assessment: A database and a language-prompted approach. InProceedings of the 31st ACM International Conference on Multimedia, pages 1045–1054, 2023
2023
-
[28]
Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Chunyi Li, Wenxiu Sun, Qiong Yan, Guangtao Zhai, and Weisi Lin. Q-bench: A benchmark for general-purpose foundation models on low-level vision.arXiv preprint arXiv:2309.14181, 2024
-
[29]
Depicting beyond scores: Advancing image quality assessment through multi-modal language models
Zhiyuan You, Zheyuan Li, Jinjin Gu, Zhenfei Yin, Tianfan Xue, and Chao Dong. Depicting beyond scores: Advancing image quality assessment through multi-modal language models. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[30]
Enhancing descriptive image quality assessment with a large-scale multi-modal dataset.IEEE Transactions on Image Processing, 34:8201–8215, 2025
Zhiyuan You, Jinjin Gu, Xin Cai, Zheyuan Li, Kaiwen Zhu, Chao Dong, and Tianfan Xue. Enhancing descriptive image quality assessment with a large-scale multi-modal dataset.IEEE Transactions on Image Processing, 34:8201–8215, 2025
2025
-
[31]
Grounding-iqa: Grounding multimodal language model for image quality assessment
Zheng Chen, Xun Zhang, Wenbo Li, Renjing Pei, Fenglong Song, Xiongkuo Min, Xiaohong Liu, Xin Yuan, Yong Guo, and Yulun Zhang. Grounding-iqa: Grounding multimodal language model for image quality assessment. CoRR, abs/2411.17237, 2024
-
[32]
Q-bench-video: Benchmark the video quality understanding of lmms
Zicheng Zhang, Ziheng Jia, Haoning Wu, Chunyi Li, Zijian Chen, Yingjie Zhou, Wei Sun, Xiaohong Liu, Xiongkuo Min, Weisi Lin, and Guangtao Zhai. Q-bench-video: Benchmark the video quality understanding of lmms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3229–3239, 2025
2025
-
[33]
Jiyao Liu, Jinjie Wei, Wanying Qu, Chenglong Ma, Junzhi Ning, Yunheng Li, Ying Chen, Xinzhe Luo, Pengcheng Chen, Xin Gao, Ming Hu, Huihui Xu, Xin Wang, Shujian Gao, Dingkang Yang, Zhongying Deng, Jin Ye, Lihao Liu, Junjun He, and Ningsheng Xu. Medq-bench: Evaluating and exploring medical image quality assessment abilities in mllms.arXiv preprint arXiv:251...
-
[34]
Lidar-net: A real-scanned 3d point cloud dataset for indoor scenes
Yanwen Guo, Yuanqi Li, Dayong Ren, Xiaohong Zhang, Jiawei Li, Liang Pu, et al. Lidar-net: A real-scanned 3d point cloud dataset for indoor scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21989–21999, 2024
2024
-
[35]
Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data
Mikaela Angelina Uy, Quang-Hieu Pham, Binh-Son Hua, Duc Thanh Nguyen, and Sai-Kit Yeung. Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1588–1597, 2019. 13 PointQ-Bench arXiv preprint
2019
-
[36]
Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10901–10911, 2021
2021
-
[37]
Jiachen Sun, Qingzhao Zhang, Bhavya Kailkhura, Zhiding Yu, Chaowei Xiao, and Z. Morley Mao. Benchmarking robustness of 3d point cloud recognition against common corruptions.arXiv preprint arXiv:2201.12296, 2022
-
[38]
Recommendation ITU-R BT.500-15: Methodologies for the subjective assessment of the quality of television images
International Telecommunication Union. Recommendation ITU-R BT.500-15: Methodologies for the subjective assessment of the quality of television images. ITU-R Recommendation, 2023. Approved in May 2023
2023
-
[39]
Recommendation ITU-T P.910: Subjective video quality assessment methods for multimedia applications
International Telecommunication Union. Recommendation ITU-T P.910: Subjective video quality assessment methods for multimedia applications. ITU-T Recommendation, 2023. Approved in October 2023
2023
-
[40]
Weighted kappa: Nominal scale agreement with provision for scaled disagreement or partial credit
Jacob Cohen. Weighted kappa: Nominal scale agreement with provision for scaled disagreement or partial credit. Psychological Bulletin, 70(4):213–220, 1968
1968
-
[41]
Openai gpt-5 system card, 2025
Aaditya Singh, Adam Fry, Adam Perelman, et al. Openai gpt-5 system card, 2025
2025
-
[42]
Claude haiku 4.5 system card
Anthropic. Claude haiku 4.5 system card. https://assets.anthropic.com/m/99128ddd009bdcb/ original/Claude-Haiku-4-5-System-Card.pdf, October 2025. System card
2025
-
[43]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
2026
-
[44]
Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency, 2025
Weiyun Wang, Zhangwei Gao, Lixin Gu, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency, 2025
2025
-
[45]
Mistralai/mistral-small-3.1-24b-instruct-2503 – hugging face
Team MistralAI. Mistralai/mistral-small-3.1-24b-instruct-2503 – hugging face
-
[46]
Gemma 3 technical report, 2025
Gemma Team, Aishwarya Kamath, Johan Ferret, et al. Gemma 3 technical report, 2025
2025
-
[47]
Pointllm: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[48]
Shapellm: Universal 3d object understanding for embodied interaction
Zekun Qi, Runpei Dong, Shaochen Zhang, Haoran Geng, Chunrui Han, Zheng Ge, Li Yi, and Kaisheng Ma. Shapellm: Universal 3d object understanding for embodied interaction. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[49]
Minigpt-3d: Efficiently aligning 3d point clouds with large language models using 2d priors
Yuan Tang, Xu Han, Xianzhi Li, Qiao Yu, Yixue Hao, Long Hu, and Min Chen. Minigpt-3d: Efficiently aligning 3d point clouds with large language models using 2d priors. InProceedings of the 32nd ACM International Conference on Multimedia, pages 6617–6626, 2024. 14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.