Building Community-Centred NLP Resources for Puno Quechua
Pith reviewed 2026-06-29 13:22 UTC · model grok-4.3
The pith
Puno Quechua gains its first dedicated speech corpus and ASR benchmarks from community-collected data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
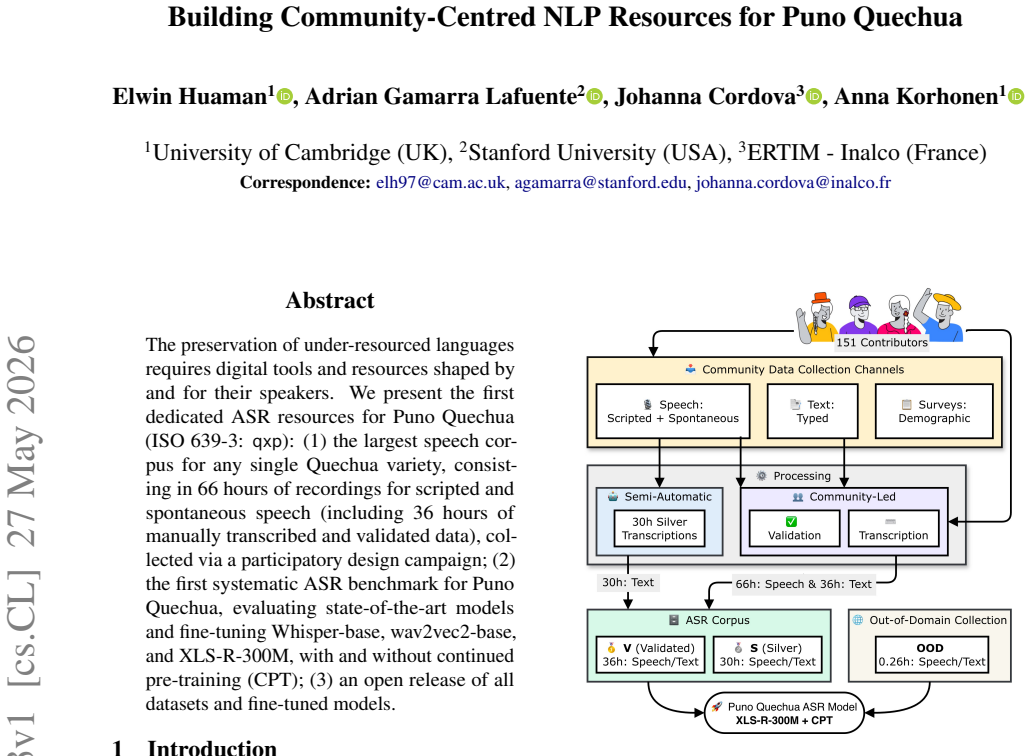
The first dedicated ASR resources for Puno Quechua consist of the largest speech corpus for any single Quechua variety at 66 hours of recordings with 36 hours of manually transcribed and validated data collected via participatory design, the first systematic benchmark that evaluates state-of-the-art models and fine-tunes Whisper-base, wav2vec2-base, and XLS-R-300M with and without continued pre-training, plus open release of all datasets and fine-tuned models.
What carries the argument
Participatory design campaign that collects, transcribes, and validates speech data, followed by fine-tuning of pre-trained ASR models on the resulting Puno Quechua corpus.
If this is right
- Puno Quechua speakers obtain openly available datasets and models that can support building local speech applications.
- Subsequent ASR research on Quechua varieties obtains a concrete baseline for comparison.
- Community-shaped data collection produces resources aligned with actual scripted and spontaneous usage patterns.
- Open release enables other researchers to extend or adapt the resources without starting from scratch.
Where Pith is reading between the lines
- The same participatory collection method could be replicated for other Quechua varieties or unrelated low-resource languages.
- Continued pre-training on small target-language corpora may prove a reusable tactic for improving ASR accuracy in similar settings.
- The released models could serve as starting points for downstream tasks such as spoken language documentation or translation aids.
Load-bearing premise
The participatory design campaign and manual transcription produce data of sufficient quality, diversity, and representativeness to support effective ASR model development and benchmarking.
What would settle it
If fine-tuned models show no measurable word-error-rate improvement over their zero-shot baselines when tested on held-out Puno Quechua audio, the claimed utility of the new corpus and benchmarks would be refuted.
Figures
read the original abstract
The preservation of under-resourced languages requires digital tools and resources shaped by and for their speakers. We present the first dedicated ASR resources for Puno Quechua (ISO 639-3: qxp): (1) the largest speech corpus for any single Quechua variety, consisting in 66 hours of recordings for scripted and spontaneous speech (including 36 hours of manually transcribed and validated data), collected via a participatory design campaign; (2) the first systematic ASR benchmark for Puno Quechua, evaluating state-of-the-art models and fine-tuning Whisper-base, wav2vec2-base, and XLS-R-300M, with and without continued pre-training (CPT); (3) an open release of all datasets and fine-tuned models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to introduce the first dedicated ASR resources for Puno Quechua (ISO 639-3: qxp): a 66-hour speech corpus (36 hours manually transcribed and validated) collected via participatory design for scripted and spontaneous speech; the first systematic ASR benchmark evaluating state-of-the-art models and fine-tuning Whisper-base, wav2vec2-base, and XLS-R-300M with and without continued pre-training; and the open release of all datasets and fine-tuned models.
Significance. If the resources exist as described, the work is significant for under-resourced language preservation through community-centered data collection and open science practices. The participatory design campaign and explicit open release of datasets and models are explicit strengths that enable reproducibility and downstream research on Quechua varieties.
minor comments (1)
- [Abstract] Abstract: the benchmark description states that models were evaluated and fine-tuned but provides no quantitative results, error analysis, or data-split details; adding a brief summary of key metrics would improve reader assessment of the benchmark's scope.
Simulated Author's Rebuttal
We thank the referee for their positive review, recognition of the significance of the participatory data collection and open release practices, and recommendation to accept the manuscript.
Circularity Check
No significant circularity; empirical resource paper
full rationale
The paper describes participatory data collection for a 66-hour speech corpus (36 hours transcribed), followed by ASR benchmarking of Whisper, wav2vec2, and XLS-R models with and without continued pre-training, plus open release of datasets and models. No mathematical derivations, predictions, fitted parameters, or uniqueness theorems appear in the abstract or described content. All claims rest on the existence and release of the collected resources and standard fine-tuning/evaluation procedures, which are self-contained empirical steps without reduction to prior self-citations or definitional loops. This matches the default non-circular case for resource papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Participatory design involving community members produces higher-quality and more appropriate language resources than non-participatory methods.
Reference graph
Works this paper leans on
-
[1]
In23rd Annual Confer- ence of the International Speech Communication As- sociation, Interspeech 2022, Incheon, Korea, Septem- ber 18-22, 2022, pages 2278–2282
XLS-R: self-supervised cross-lingual speech repre- sentation learning at scale. In23rd Annual Confer- ence of the International Speech Communication As- sociation, Interspeech 2022, Incheon, Korea, Septem- ber 18-22, 2022, pages 2278–2282. ISCA. Ronald Cardenas, Rodolfo Zevallos, Reynaldo Baquer- izo, and Luis Camacho
2022
-
[2]
semi-supervised training.arXiv preprint arXiv:2207.00659
Im- proving low-resource speech recognition with pre- trained speech models: Continued pretraining vs. semi-supervised training.arXiv preprint arXiv:2207.00659. Candace Galla
-
[3]
Omnilingual asr: Open-source multilingual speech recognition for 1600+ languages
Omnilingual ASR: open- source multilingual speech recognition for 1600+ lan- guages.CoRR, abs/2511.09690. Hillary Mutisya and John Mugane
- [4]
-
[5]
Alfredo Torero
The methodology of participatory design.Technical communication, 52(2):163–174. Alfredo Torero. 2002.Idiomas de los Andes. Lingüística e historia. Editorial horizonte. Petti Ulla, M. Claus Hannah, Barford Anna, Sadek Malak, Reichart Roi, and Korhonen Anna
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.