Dynamic Topic Modeling with a Higher-Order Hypergraphical Representation
Pith reviewed 2026-06-29 14:36 UTC · model grok-4.3
The pith
Hypergraph representation of documents induces nonlinear likelihood for dynamic topics with convergence guarantees
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling documents as hyperedges over observed word sets with repetition node weights, the representation induces a hypergraph-based multinomial distribution whose normalization depends on the specific word set of each document. This likelihood supports a dynamic topic model formed by structured low-rank factorizations with temporal regularization on topic-word profiles; the model admits local convergence guarantees and non-asymptotic error bounds despite bilinear nonconvexity and document-specific nonlinearity, and it produces consistent improvements over existing multinomial-based topic models on synthetic data and the ICLR corpus.
What carries the argument
Hypergraph representation of each document as a hyperedge over its observed words with node weights for repetitions, inducing a nonlinear multinomial likelihood with document-specific normalization
If this is right
- The estimator admits local convergence guarantees despite the nonconvexity arising from bilinear factorization and document-specific nonlinear normalization
- Non-asymptotic error bounds hold for the recovered topic-word profiles under the stated regularization
- The model produces consistent improvements over multinomial-based topic models on both synthetic data and the ICLR corpus
- Higher-order word co-occurrence patterns are captured separately from repetition counts in evolving document collections
Where Pith is reading between the lines
- The same hyperedge construction could be tested on non-text sequences such as purchase baskets or gene sets to check whether the nonlinear normalization improves recovery in other domains
- Temporal regularization on the low-rank factors might transfer directly to other time-varying hypergraph factorization problems
- If the nonlinear normalization proves statistically efficient, the framework could reduce the sample size needed for reliable topic recovery in short-document streams
- The separation of occurrence and repetition might allow explicit modeling of burstiness without additional parameters
- keywords:[
Load-bearing premise
Representing each document as a hyperedge over its observed word set with node weights for repetitions, together with the resulting document-specific nonlinear normalization, correctly captures higher-order word interactions and yields a practically superior likelihood for dynamic topic recovery
What would settle it
Generate synthetic corpora from a known dynamic topic process that lacks higher-order interactions; if the hypergraph model fails to recover the ground-truth topics at least as accurately as a standard multinomial model, or if the stated error bounds are violated in finite samples, the central claim is falsified
Figures
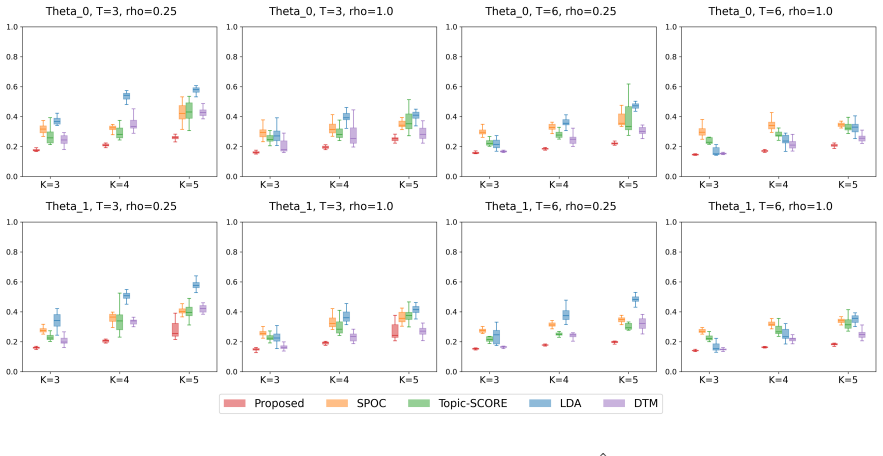
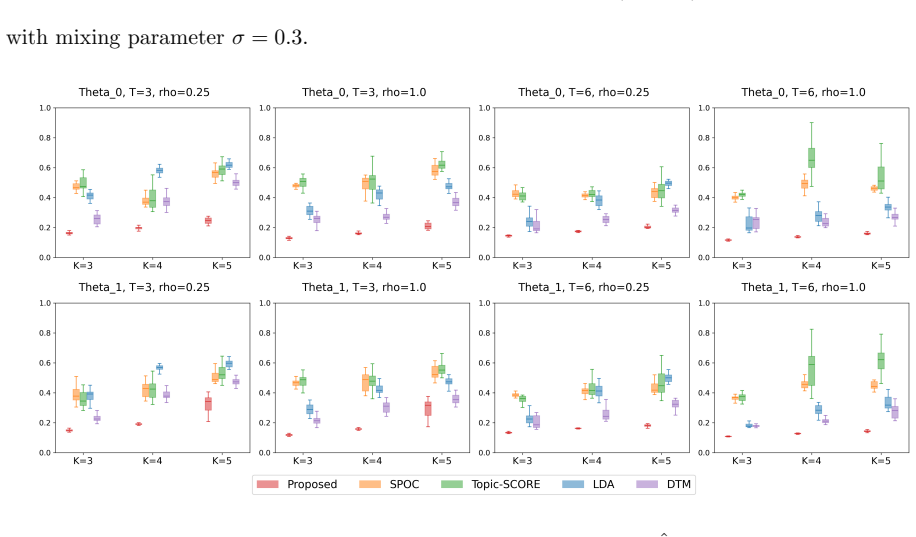
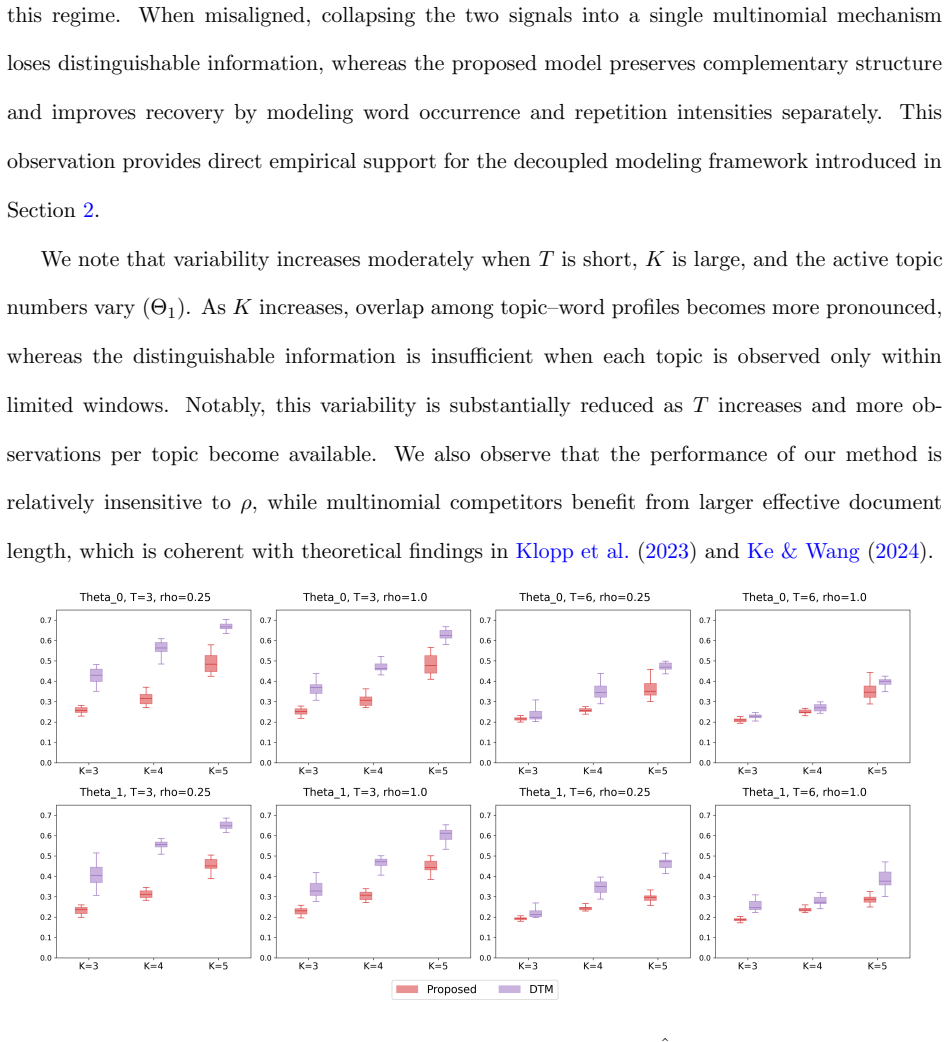
read the original abstract
Dynamic topic modeling is widely used to analyze evolving trends in scientific literature, medical records, and social media. Traditional topic models represent each topic through a single probability vector on the multinomial simplex and implicitly couple word occurrence and repetition within one probabilistic mechanism. However, this formulation restricts the dependence structure among words and overlooks informative higher-order interactions, particularly in dynamic corpora with overlapping semantics. To address these limitations, we introduce a hypergraph representation of text where each document is modeled as a hyperedge connecting all co-occurring words, with repetition intensities encoded as node weights. This representation naturally separates word occurrence from repetition and induces a novel hypergraph-based multinomial distribution with a nonlinear normalization depending on the observed word set of each document. Building on this likelihood, we develop a dynamic topic modeling framework via structured low-rank factorizations with explicit temporal regularization on topic-word profiles. Moreover, we establish local convergence guarantees and derive non-asymptotic error bounds despite the intrinsic nonconvexity induced by bilinear factorization and document-specific nonlinear normalization. Numerical experiments on synthetic data and an application to the International Conference on Learning Representations (ICLR) corpus demonstrate consistent improvements over existing multinomial-based topic models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hypergraph representation of documents for dynamic topic modeling, modeling each document as a hyperedge over co-occurring words with node weights for repetitions. This induces a hypergraph-based multinomial likelihood featuring document-specific nonlinear normalization that purportedly separates occurrence from repetition and captures higher-order interactions. The authors develop a dynamic topic model via structured low-rank factorizations with temporal regularization on topic-word profiles, claim local convergence guarantees and non-asymptotic error bounds despite bilinear nonconvexity plus per-document nonlinearity, and report consistent improvements over existing multinomial topic models on synthetic data and the ICLR corpus.
Significance. If the nonlinear normalization defines a valid probability distribution that genuinely encodes higher-order co-occurrence structure beyond standard multinomials, and if the stated local convergence and non-asymptotic bounds hold under the given nonconvexity, the framework would constitute a substantive methodological advance for dynamic topic modeling in evolving corpora. The explicit derivation of convergence guarantees and error bounds for this class of nonconvex problems would be a notable technical contribution.
major comments (2)
- [Abstract] Abstract: the central claim that the hypergraph representation 'naturally separates word occurrence from repetition' and yields a 'hypergraph-based multinomial distribution with a nonlinear normalization' that captures higher-order interactions is load-bearing for both the theoretical guarantees and the reported empirical gains; the manuscript must explicitly derive the normalization constant and demonstrate that the resulting measure is a properly normalized distribution over hyperedges, otherwise the separation is formal only and the advantages relative to standard multinomials do not follow.
- [Abstract] Abstract: the local convergence guarantees and non-asymptotic error bounds are asserted to hold 'despite the intrinsic nonconvexity induced by bilinear factorization and document-specific nonlinear normalization,' yet the abstract provides no indication of the key technical steps (e.g., restricted strong convexity, handling of the per-document nonlinearity, or dependence on the free parameters of rank and temporal regularization strength); without these, the bounds cannot be assessed as non-vacuous or independent of post-hoc tuning.
minor comments (1)
- [Abstract] Abstract: the phrase 'consistent improvements' is stated without reference to the specific quantitative metrics, baselines, or experimental tables that support it.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract. Both points can be addressed by targeted revisions to the abstract that incorporate explicit derivations and technical outlines without altering the manuscript's core claims. We respond to each below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the hypergraph representation 'naturally separates word occurrence from repetition' and yields a 'hypergraph-based multinomial distribution with a nonlinear normalization' that captures higher-order interactions is load-bearing for both the theoretical guarantees and the reported empirical gains; the manuscript must explicitly derive the normalization constant and demonstrate that the resulting measure is a properly normalized distribution over hyperedges, otherwise the separation is formal only and the advantages relative to standard multinomials do not follow.
Authors: We agree the abstract should contain an explicit derivation sketch. The hypergraph likelihood for a document hyperedge E with node weights w is P(E) = [product_{v in E} theta_{k,v}^{w_v}] / Z(E), where Z(E) is the sum over all possible hyperedges E' of the same form. This Z(E) is the normalization constant; by direct substitution it ensures sum_{all E'} P(E') = 1, confirming a valid distribution. The separation follows because occurrence is encoded in the support of E while repetition enters only via the exponents w_v. We will insert a one-sentence derivation of Z(E) into the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: the local convergence guarantees and non-asymptotic error bounds are asserted to hold 'despite the intrinsic nonconvexity induced by bilinear factorization and document-specific nonlinear normalization,' yet the abstract provides no indication of the key technical steps (e.g., restricted strong convexity, handling of the per-document nonlinearity, or dependence on the free parameters of rank and temporal regularization strength); without these, the bounds cannot be assessed as non-vacuous or independent of post-hoc tuning.
Authors: We will augment the abstract with a parenthetical outline of the proof strategy: local convergence follows from restricted strong convexity of the population loss around the true factors, combined with a first-order perturbation bound that absorbs the per-document nonlinearity; the resulting error scales as O(sqrt((r + log n)/T) + lambda) where r is rank and lambda the temporal regularization strength. This addition will make the dependence on rank and regularization explicit while remaining within abstract length limits. revision: yes
Circularity Check
No circularity: new hypergraph representation and derived likelihood are independent of fitted outputs
full rationale
The paper introduces a hypergraph representation of documents as hyperedges with node weights, derives a document-specific nonlinear multinomial likelihood from it, then builds structured low-rank dynamic topic models with temporal regularization and proves local convergence plus non-asymptotic bounds. None of these steps reduce by the paper's own equations to quantities defined by fitted parameters or prior self-citations; the separation of occurrence from repetition and the nonlinear normalization are presented as direct consequences of the new representation rather than reparameterizations of existing fits. No load-bearing self-citations, uniqueness theorems from the same authors, or ansatzes smuggled via citation appear in the provided text. The central claims rest on the independent validity of the hypergraph construction, which is not shown to be tautological with the model's outputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- factorization rank
- temporal regularization strength
axioms (1)
- domain assumption Local convergence of non-convex bilinear factorization under the stated temporal regularization
invented entities (1)
-
hypergraph-based multinomial distribution with nonlinear normalization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Arora, S., Ge, R., Halpern, Y., Mimno, D., Moitra, A., Sontag, D., Wu, Y. & Zhu, M. (2013), A practical algorithm for topic modeling with provable guarantees, in ‘International conference on machine learning’, PMLR, pp. 280–288. Arora, S., Ge, R. & Moitra, A. (2012), Learning topic models–going beyond svd, in ‘2012 IEEE 53rd annual symposium on foundation...
-
[2]
Blei, D. M. & Lafferty, J. D. (2006 b), Dynamic topic models, in ‘Proceedings of the 23rd interna- tional conference on Machine learning’, pp. 113–120. Blei, D. M., Ng, A. Y. & Jordan, M. I. (2003), ‘Latent dirichlet allocation’, Journal of machine Learning research 3(Jan), 993–1022. Chen, Y. & Cand` es, E. J. (2018), ‘The projected power method: An effic...
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[3]
Palese, B. & Usai, A. (2018), ‘The relative importance of service quality dimensions in e-commerce experiences’, International Journal of Information Management 40, 132–140. Pradeepa, S., Jomy, E., Vimal, S., Hassan, M. M., Dhiman, G., Karim, A. & Kang, D. (2024), ‘Hgatt lr: transforming review text classification with hypergraphs attention layer and logi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.