FedMPT: Federated Multi-label Prompt Tuning of Vision-Language Models
Pith reviewed 2026-06-29 12:33 UTC · model grok-4.3
The pith
FedMPT steers federated multi-label recognition by extracting generalizable conditions on label dependencies via an LLM pipeline, then matching them to image regions with optimal transport and combining outputs through gating.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating federated multi-label recognition through a causal lens that applies front-door adjustment and decouples the modeling via intermediate variables that magnify oracle label co-occurrence, the method shows that an LLM-driven pipeline can extract conditions governing label dependencies; optimal transport then aligns the resulting condition-enriched prompts with image patches to reveal region-level semantics, and a gating mechanism produces synergistic predictions that mitigate erroneous activations from spurious correlations while delivering competitive accuracy on benchmark datasets.
What carries the argument
The LLM-driven pipeline that deciphers underlying conditions governing label dependencies, followed by optimal transport between condition-enriched prompts and image patches plus a gating mechanism for synergistic predictions.
If this is right
- Federated clients can avoid overfitting to local spurious correlations without sharing raw data.
- Region-level semantics become accessible by transporting condition-enriched prompts onto image patches.
- Predictions from multiple conditions can be fused reliably through the gating step.
- Performance remains competitive with centralized methods and exceeds prior federated baselines under varied heterogeneity levels.
Where Pith is reading between the lines
- The same condition-extraction step could be tested on single-client multi-label tasks to measure how much the federated setting itself drives the need for the LLM pipeline.
- If the conditions prove stable, the pipeline might reduce the amount of client-specific prompt tuning required in future federated deployments.
- The optimal-transport alignment could be replaced by other region-to-prompt matching schemes to test whether transport is essential or merely convenient.
Load-bearing premise
An LLM can extract conditions on label dependencies that remain valid and useful across the heterogeneous private datasets held by different clients.
What would settle it
Run the method on a new collection of clients whose label co-occurrence statistics differ markedly from those used to derive the LLM conditions; if accuracy drops below a plain prompt-tuning baseline that omits the condition pipeline, the claim does not hold.
Figures


read the original abstract
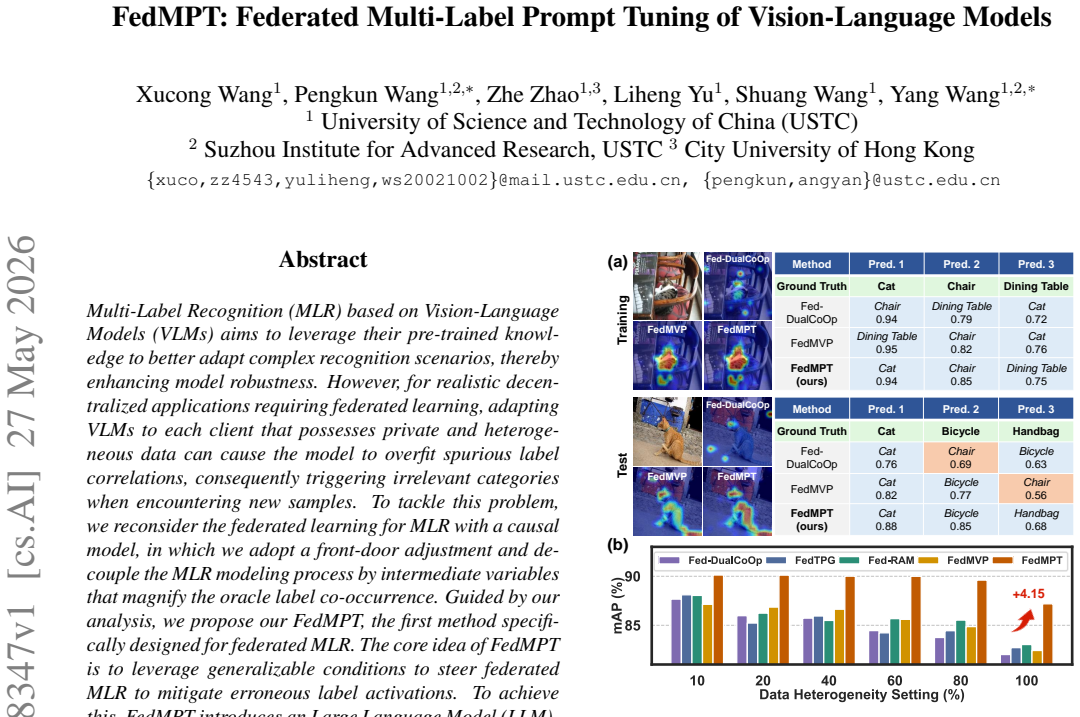
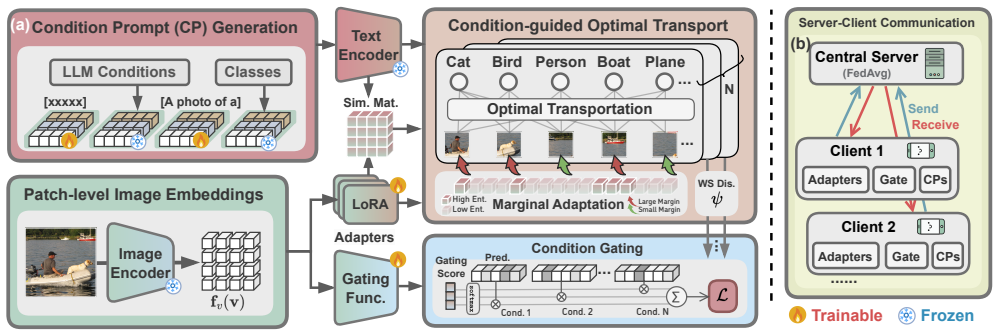
Multi-Label Recognition (MLR) based on Vision-Language Models (VLMs) aims to leverage their pre-trained knowledge to better adapt complex recognition scenarios, thereby enhancing model robustness. However, for realistic decentralized applications requiring federated learning, adapting VLMs to each client that possesses private and heterogeneous data can cause the model to overfit spurious label correlations, consequently triggering irrelevant categories when encountering new samples. To tackle this problem, we reconsider the federated learning for MLR with a causal model, in which we adopt a front-door adjustment and decouple the MLR modeling process by intermediate variables that magnify the oracle label co-occurrence. Guided by our analysis, we propose our FedMPT, the first method specifically designed for federated MLR. The core idea of FedMPT is to leverage generalizable conditions to steer federated MLR to mitigate erroneous label activations. To achieve this, FedMPT introduces an Large Language Model (LLM)-driven pipeline to decipher the underlying conditions that govern label dependencies. Furthermore, we introduce an optimal transport between the condition-enriched prompts and the image patches to uncover multiple region-level semantics. Finally, we generate synergistic predictions from different conditions with a crafted gating mechanism. Experiments on multiple benchmark datasets show that our proposed approach achieves competitive results and outperforms SOTA methods under varied settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce FedMPT as the first method designed for federated multi-label recognition (MLR) with vision-language models. It reconsiders the problem via a causal model employing front-door adjustment to decouple MLR through intermediate variables that magnify oracle label co-occurrence. The method uses an LLM-driven pipeline to extract generalizable conditions governing label dependencies, applies optimal transport between condition-enriched prompts and image patches to uncover region-level semantics, and employs a gating mechanism to produce synergistic predictions. Experiments on multiple benchmark datasets are said to show competitive results and outperformance over SOTA under varied settings.
Significance. If the central claims hold, the work would address a genuine gap in adapting VLMs to federated MLR settings where client data heterogeneity induces spurious label correlations. The causal framing and LLM-based condition extraction represent a novel direction for mitigating erroneous activations, with potential for broader impact in decentralized vision tasks. However, the significance is tempered by the absence of any reported equations, ablations, or cross-client validation evidence in the provided abstract.
major comments (2)
- [Abstract] Abstract: the claim that the LLM-driven pipeline 'deciphers the underlying conditions that govern label dependencies' and produces 'generalizable conditions' to mitigate erroneous activations across heterogeneous clients is load-bearing for the entire method (including the subsequent optimal transport and gating steps), yet no mechanism, formal definition, or validation (e.g., transfer across clients or ablation removing the pipeline) is supplied to support that the extracted conditions avoid client-specific artifacts.
- [Abstract] Abstract: the front-door adjustment and decoupling via 'intermediate variables that magnify the oracle label co-occurrence' is presented as the guiding analysis, but without any equations, graphical model, or derivation it is impossible to assess whether the adjustment is correctly applied or reduces to a reparameterization of existing prompt-tuning objectives.
minor comments (1)
- The abstract refers to 'multiple benchmark datasets' and 'varied settings' without naming the datasets, metrics, or heterogeneity levels used.
Simulated Author's Rebuttal
We thank the referee for highlighting areas where the abstract could better convey the technical details of our approach. We address each comment below and commit to revisions that improve clarity without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the LLM-driven pipeline 'deciphers the underlying conditions that govern label dependencies' and produces 'generalizable conditions' to mitigate erroneous activations across heterogeneous clients is load-bearing for the entire method (including the subsequent optimal transport and gating steps), yet no mechanism, formal definition, or validation (e.g., transfer across clients or ablation removing the pipeline) is supplied to support that the extracted conditions avoid client-specific artifacts.
Authors: We agree the abstract is too concise on this point. Section 3.2 of the manuscript details the LLM pipeline, including prompt templates for extracting conditions from label co-occurrence statistics and the selection criteria for generalizable (cross-client) conditions. We will revise the abstract to briefly describe the pipeline mechanism. In addition, we will add an ablation that removes the LLM component and report cross-client transfer experiments measuring condition stability to directly address the concern about client-specific artifacts. revision: yes
-
Referee: [Abstract] Abstract: the front-door adjustment and decoupling via 'intermediate variables that magnify the oracle label co-occurrence' is presented as the guiding analysis, but without any equations, graphical model, or derivation it is impossible to assess whether the adjustment is correctly applied or reduces to a reparameterization of existing prompt-tuning objectives.
Authors: The causal analysis appears in Section 3.1, which contains the graphical model, the front-door adjustment expression, and the step-by-step derivation showing how the intermediate variables isolate oracle co-occurrences from spurious client correlations. The abstract summarizes the high-level motivation. We will revise the abstract to explicitly reference the front-door adjustment and the role of the intermediate variables, and we will ensure the key equation is stated or cited within the abstract where length permits. revision: yes
Circularity Check
No circularity: method is presented without equations or self-referential reductions
full rationale
The provided abstract and description introduce FedMPT via a causal framing (front-door adjustment, intermediate variables for label co-occurrence) and an LLM-driven pipeline for conditions, followed by optimal transport and gating. No equations, fitted parameters renamed as predictions, or self-citation chains are exhibited that would reduce any claimed result to its inputs by construction. The central claims rest on the novelty of the pipeline components rather than any derivation that loops back to fitted values or prior author results. This is the common case of a method paper whose validity is to be judged by external benchmarks rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cdul: Clip-driven unsupervised learning for multi-label image classification
Rabab Abdelfattah, Qing Guo, Xiaoguang Li, Xiaofeng Wang, and Song Wang. Cdul: Clip-driven unsupervised learning for multi-label image classification. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 1348–1357, 2023. 2
2023
-
[2]
Wenxuan Bao, Ruxi Deng, Ruizhong Qiu, Tianxin Wei, Hanghang Tong, and Jingrui He. Latte: Collaborative test-time adaptation of vision-language models in federated learning.arXiv preprint arXiv:2507.21494, 2025. 3
-
[3]
A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang. A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025. 2
2025
-
[4]
Weakly- supervised semantic segmentation via sub-category explo- ration
Yu-Ting Chang, Qiaosong Wang, Wei-Chih Hung, Robinson Piramuthu, Yi-Hsuan Tsai, and Ming-Hsuan Yang. Weakly- supervised semantic segmentation via sub-category explo- ration. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8991–9000,
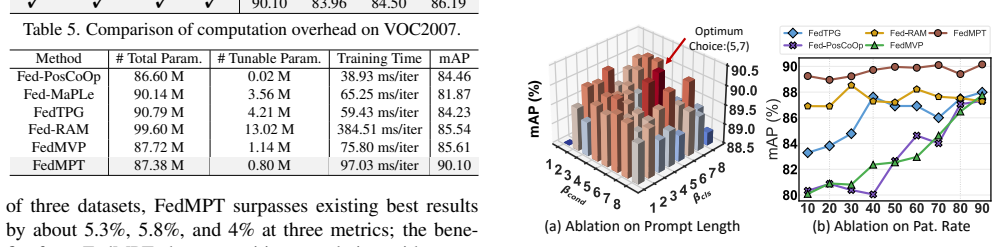
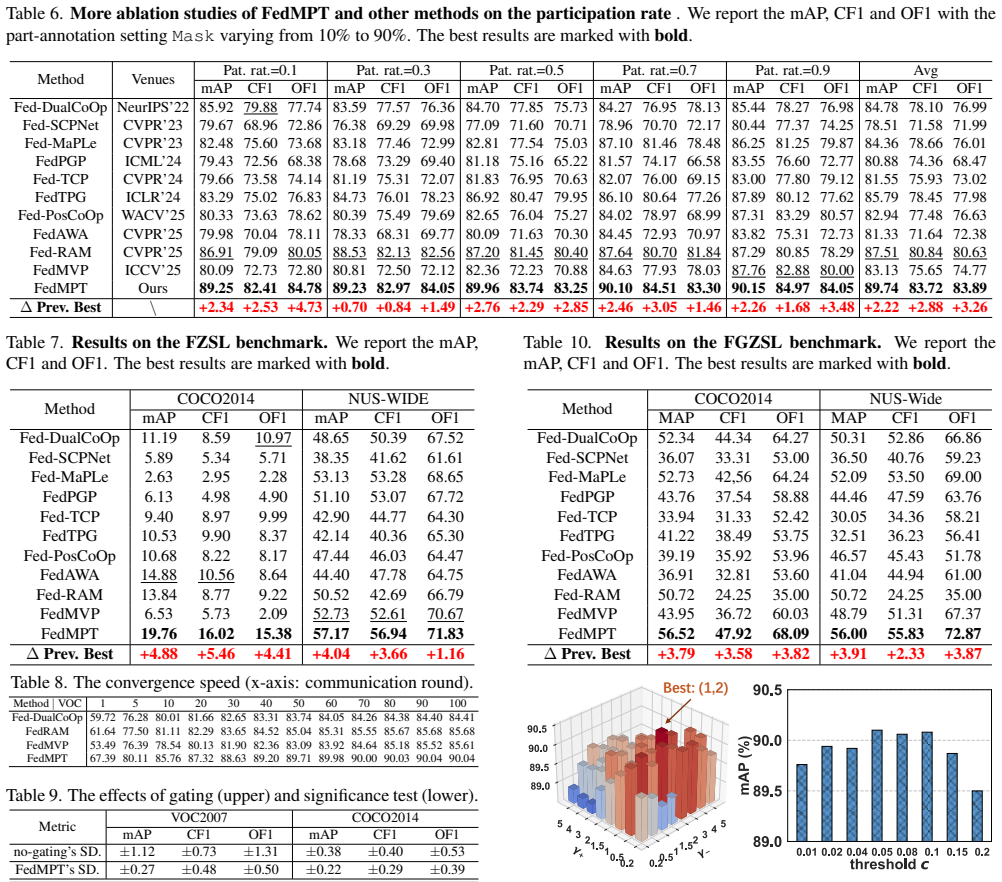
-
[5]
Label distribution learning on auxiliary label space graphs for facial expression recog- nition
Shikai Chen, Jianfeng Wang, Yuedong Chen, Zhongchao Shi, Xin Geng, and Yong Rui. Label distribution learning on auxiliary label space graphs for facial expression recog- nition. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 13984–13993,
-
[6]
Shiming Chen, Bowen Duan, Salman Khan, and Fa- had Shahbaz Khan. Interpretable zero-shot learning with locally-aligned vision-language model.arXiv preprint arXiv:2506.23822, 2025. 4
-
[7]
Learning semantic-specific graph representa- tion for multi-label image recognition
Tianshui Chen, Muxin Xu, Xiaolu Hui, Hefeng Wu, and Liang Lin. Learning semantic-specific graph representa- tion for multi-label image recognition. InProceedings of the IEEE/CVF international conference on computer vision, pages 522–531, 2019. 2
2019
-
[8]
Adamv-moe: Adaptive multi-task vision mixture-of- experts
Tianlong Chen, Xuxi Chen, Xianzhi Du, Abdullah Rashwan, Fan Yang, Huizhong Chen, Zhangyang Wang, and Yeqing Li. Adamv-moe: Adaptive multi-task vision mixture-of- experts. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 17346–17357, 2023. 2
2023
-
[9]
Multi-label image recognition with joint class-aware map disentangling and label correlation embedding
Zhao-Min Chen, Xiu-Shen Wei, Xin Jin, and Yanwen Guo. Multi-label image recognition with joint class-aware map disentangling and label correlation embedding. In2019 IEEE International Conference on Multimedia and Expo (ICME), pages 622–627. IEEE, 2019. 1
2019
-
[10]
Multi-label image recognition with graph convolu- tional networks
Zhao-Min Chen, Xiu-Shen Wei, Peng Wang, and Yanwen Guo. Multi-label image recognition with graph convolu- tional networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5177– 5186, 2019. 1, 2
2019
-
[11]
Nus-wide: a real-world web im- age database from national university of singapore
Tat-Seng Chua, Jinhui Tang, Richang Hong, Haojie Li, Zhip- ing Luo, and Yantao Zheng. Nus-wide: a real-world web im- age database from national university of singapore. InPro- ceedings of the ACM international conference on image and video retrieval, pages 1–9, 2009. 5, 12
2009
-
[12]
Tianyu Cui, Hongxia Li, Jingya Wang, and Ye Shi. Har- monizing generalization and personalization in federated prompt learning.arXiv preprint arXiv:2405.09771, 2024. 2, 3, 5, 6, 13
-
[13]
Unlocking the potential of prompt-tuning in bridging gener- alized and personalized federated learning
Wenlong Deng, Christos Thrampoulidis, and Xiaoxiao Li. Unlocking the potential of prompt-tuning in bridging gener- alized and personalized federated learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6087–6097, 2024. 3
2024
-
[14]
Explor- ing structured semantic prior for multi label recognition with incomplete labels
Zixuan Ding, Ao Wang, Hui Chen, Qiang Zhang, Pengzhang Liu, Yongjun Bao, Weipeng Yan, and Jungong Han. Explor- ing structured semantic prior for multi label recognition with incomplete labels. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 3398–3407, 2023. 6, 13
2023
-
[15]
Learn- ing a deep convnet for multi-label classification with partial labels
Thibaut Durand, Nazanin Mehrasa, and Greg Mori. Learn- ing a deep convnet for multi-label classification with partial labels. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 647–657, 2019. 1
2019
-
[16]
The pascal visual object classes challenge: A retrospective.Inter- national journal of computer vision, 111(1):98–136, 2015
Mark Everingham, SM Ali Eslami, Luc Van Gool, Christo- pher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes challenge: A retrospective.Inter- national journal of computer vision, 111(1):98–136, 2015. 5, 12
2015
-
[17]
Learning to discover multi-class attentional regions for multi-label image recog- nition.IEEE Transactions on Image Processing, 30:5920– 5932, 2021
Bin-Bin Gao and Hong-Yu Zhou. Learning to discover multi-class attentional regions for multi-label image recog- nition.IEEE Transactions on Image Processing, 30:5920– 5932, 2021. 1
2021
-
[18]
Tao Guo, Song Guo, Junxiao Wang, Xueyang Tang, and Wenchao Xu. Promptfl: Let federated participants cooper- atively learn prompts instead of models–federated learning in age of foundation model.IEEE Transactions on Mobile Computing, 23(5):5179–5194, 2023. 2, 3
2023
-
[19]
Du- alcoop++: Fast and effective adaptation to multi-label recog- nition with limited annotations.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 46(5):3450–3462,
Ping Hu, Ximeng Sun, Stan Sclaroff, and Kate Saenko. Du- alcoop++: Fast and effective adaptation to multi-label recog- nition with limited annotations.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 46(5):3450–3462,
-
[20]
Y . Hua, L. Mou, P. Jin, and X. X. Zhu. Multiscene: A large- scale dataset and benchmark for multi-scene recognition in single aerial images.IEEE Transactions on Geoscience and Remote Sensing, in press. 5, 12
-
[21]
Classification done right for vision-language pre- training.Advances in Neural Information Processing Sys- tems, 37:96483–96504, 2024
Zilong Huang, Qinghao Ye, Bingyi Kang, Jiashi Feng, and Haoqi Fan. Classification done right for vision-language pre- training.Advances in Neural Information Processing Sys- tems, 37:96483–96504, 2024. 1
2024
-
[22]
A shared multi-attention framework for multi-label zero-shot learning
Dat Huynh and Ehsan Elhamifar. A shared multi-attention framework for multi-label zero-shot learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8776–8786, 2020. 2
2020
-
[23]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR,
-
[24]
Test-time robust personalization for federated learning.arXiv preprint arXiv:2205.10920,
Liangze Jiang and Tao Lin. Test-time robust personalization for federated learning.arXiv preprint arXiv:2205.10920,
-
[25]
Maple: Multi-modal prompt learning
Muhammad Uzair Khattak, Hanoona Rasheed, Muham- mad Maaz, Salman Khan, and Fahad Shahbaz Khan. Maple: Multi-modal prompt learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19113–19122, 2023. 6, 13, 14
2023
-
[26]
Classifier-guided clip distillation for unsupervised multi-label classification
Dongseob Kim and Hyunjung Shim. Classifier-guided clip distillation for unsupervised multi-label classification. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4661–4671, 2025. 1, 2
2025
-
[27]
Wei-Bin Kou, Qingfeng Lin, Ming Tang, Sheng Xu, Rong- guang Ye, Yang Leng, Shuai Wang, Guofa Li, Zhenyu Chen, Guangxu Zhu, et al. pfedlvm: A large vision model (lvm)- driven and latent feature-based personalized federated learn- ing framework in autonomous driving.IEEE Transactions on Intelligent Transportation Systems, 2025. 3
2025
-
[28]
Global and local prompts cooperation via optimal transport for fed- erated learning
Hongxia Li, Wei Huang, Jingya Wang, and Ye Shi. Global and local prompts cooperation via optimal transport for fed- erated learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12151– 12161, 2024. 2, 3
2024
-
[29]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInterna- tional conference on machine learning, pages 12888–12900. PMLR, 2022. 1
2022
-
[30]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 1
2023
-
[31]
Advancing textual prompt learning with anchored attributes.arXiv preprint arXiv:2412.09442, 1, 2024
Zheng Li, Yibing Song, Ming-Ming Cheng, Xiang Li, and Jian Yang. Advancing textual prompt learning with anchored attributes.arXiv preprint arXiv:2412.09442, 1, 2024. 4
-
[32]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 5, 12
2014
-
[33]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1
2023
-
[34]
Understanding the stability-based generaliza- tion of personalized federated learning
Yingqi Liu, Qinglun Li, Jie Tan, Yifan Shi, Li Shen, and Xi- aochun Cao. Understanding the stability-based generaliza- tion of personalized federated learning. InThe Thirteenth In- ternational Conference on Learning Representations, 2025. 3
2025
-
[35]
Wang Lu, Xixu Hu, Jindong Wang, and Xing Xie. Fedclip: Fast generalization and personalization for clip in federated learning.arXiv preprint arXiv:2302.13485, 2023. 3
-
[36]
Text-region matching for multi-label image recognition with missing labels
Leilei Ma, Hongxing Xie, Lei Wang, Yanping Fu, Dengdi Sun, and Haifeng Zhao. Text-region matching for multi-label image recognition with missing labels. InProceedings of the 32nd ACM International Conference on Multimedia, pages 6133–6142, 2024. 2
2024
-
[37]
Correlative and discriminative label grouping for multi-label visual prompt tuning
Lei-Lei Ma, Shuo Xu, Ming-Kun Xie, Lei Wang, Dengdi Sun, and Haifeng Zhao. Correlative and discriminative label grouping for multi-label visual prompt tuning. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 25434–25443, 2025. 1, 2, 5
2025
-
[38]
Communication- efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication- efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. PMLR, 2017. 2, 5
2017
-
[39]
Sparc: Score prompting and adaptive fusion for zero-shot multi-label recognition in vision-language models
Kevin Miller, Aditya Gangrade, Samarth Mishra, Kate Saenko, and Venkatesh Saligrama. Sparc: Score prompting and adaptive fusion for zero-shot multi-label recognition in vision-language models. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 4313–4321,
-
[40]
Discriminative region-based multi-label zero-shot learning
Sanath Narayan, Akshita Gupta, Salman Khan, Fahad Shah- baz Khan, Ling Shao, and Mubarak Shah. Discriminative region-based multi-label zero-shot learning. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 8731–8740, 2021. 2
2021
-
[41]
Mlrsnet: A multi- label high spatial resolution remote sensing dataset for se- mantic scene understanding.ISPRS Journal of Photogram- metry and Remote Sensing, 169:337–350, 2020
Xiaoman Qi, Panpan Zhu, Yuebin Wang, Liqiang Zhang, Junhuan Peng, Mengfan Wu, Jialong Chen, Xudong Zhao, Ning Zang, and P Takis Mathiopoulos. Mlrsnet: A multi- label high spatial resolution remote sensing dataset for se- mantic scene understanding.ISPRS Journal of Photogram- metry and Remote Sensing, 169:337–350, 2020. 5, 12
2020
-
[42]
Federated text-driven prompt generation for vision- language models
Chen Qiu, Xingyu Li, Chaithanya Kumar Mummadi, Madan Ravi Ganesh, Zhenzhen Li, Lu Peng, and Wan-Yi Lin. Federated text-driven prompt generation for vision- language models. InThe Twelfth International Conference on Learning Representations, 2024. 2, 3, 6, 13, 14
2024
-
[43]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1
2021
-
[44]
Positivecoop: Rethinking prompting strategies for multi-label recognition with partial annotations
Samyak Rawlekar, Shubhang Bhatnagar, and Narendra Ahuja. Positivecoop: Rethinking prompting strategies for multi-label recognition with partial annotations. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 5863–5872. IEEE, 2025. 1, 2, 3, 6, 13
2025
-
[45]
Multiple instance visual-semantic embedding
Zhou Ren, Hailin Jin, Zhe Lin, Chen Fang, and Alan L Yuille. Multiple instance visual-semantic embedding. In BMVC, 2017. 2
2017
-
[46]
Asymmetric loss for multi-label classification
Tal Ridnik, Emanuel Ben-Baruch, Nadav Zamir, Asaf Noy, Itamar Friedman, Matan Protter, and Lihi Zelnik-Manor. Asymmetric loss for multi-label classification. InProceed- ings of the IEEE/CVF international conference on computer vision, pages 82–91, 2021. 1, 3
2021
-
[47]
Fedawa: Adaptive optimiza- tion of aggregation weights in federated learning using client vectors
Changlong Shi, He Zhao, Bingjie Zhang, Mingyuan Zhou, Dandan Guo, and Yi Chang. Fedawa: Adaptive optimiza- tion of aggregation weights in federated learning using client vectors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 30651–30660, 2025. 2, 6, 13, 14
2025
-
[48]
Mainak Singha, Subhankar Roy, Sarthak Mehrotra, Ankit Jha, Moloud Abdar, Biplab Banerjee, and Elisa Ricci. Fedmvp: Federated multi-modal visual prompt tuning for vision-language models.arXiv preprint arXiv:2504.20860,
-
[49]
Concerning nonnegative matrices and doubly stochastic matrices.Pacific Journal of Mathematics, 21(2):343–348, 1967
Richard Sinkhorn and Paul Knopp. Concerning nonnegative matrices and doubly stochastic matrices.Pacific Journal of Mathematics, 21(2):343–348, 1967. 4
1967
-
[50]
Federated multi-task learning.Advances in neural information processing systems, 30, 2017
Virginia Smith, Chao-Kai Chiang, Maziar Sanjabi, and Ameet S Talwalkar. Federated multi-task learning.Advances in neural information processing systems, 30, 2017. 2
2017
-
[51]
Dualcoop: Fast adaptation to multi-label recognition with limited annota- tions.Advances in Neural Information Processing Systems, 35:30569–30582, 2022
Ximeng Sun, Ping Hu, and Kate Saenko. Dualcoop: Fast adaptation to multi-label recognition with limited annota- tions.Advances in Neural Information Processing Systems, 35:30569–30582, 2022. 1, 2, 3, 6, 12, 13
2022
-
[52]
Recover and match: Open-vocabulary multi-label recognition through knowledge-constrained optimal trans- port
Hao Tan, Zichang Tan, Jun Li, Ajian Liu, Jun Wan, and Zhen Lei. Recover and match: Open-vocabulary multi-label recognition through knowledge-constrained optimal trans- port. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4650–4660, 2025. 2, 5, 6, 12, 13, 14
2025
-
[53]
Hydralora: An asymmetric lora architecture for efficient fine-tuning.Advances in Neural Information Pro- cessing Systems, 37:9565–9584, 2024
Chunlin Tian, Zhan Shi, Zhijiang Guo, Li Li, and Cheng- Zhong Xu. Hydralora: An asymmetric lora architecture for efficient fine-tuning.Advances in Neural Information Pro- cessing Systems, 37:9565–9584, 2024. 4, 5
2024
-
[54]
Cnn-rnn: A unified framework for multi-label image classification
Jiang Wang, Yi Yang, Junhua Mao, Zhiheng Huang, Chang Huang, and Wei Xu. Cnn-rnn: A unified framework for multi-label image classification. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 2285–2294, 2016. 2
2016
-
[55]
Multi-label classification with label graph superimposing
Ya Wang, Dongliang He, Fu Li, Xiang Long, Zhichao Zhou, Jinwen Ma, and Shilei Wen. Multi-label classification with label graph superimposing. InProceedings of the AAAI con- ference on artificial intelligence, pages 12265–12272, 2020. 1
2020
-
[56]
Causal interventional prompt tuning for few-shot out-of-distribution generalization.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 2025
Jie Wen, Yicheng Liu, Chao Huang, Chengliang Liu, Yong Xu, and Xiaochun Cao. Causal interventional prompt tuning for few-shot out-of-distribution generalization.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 2025. 3
2025
-
[57]
Routing experts: Learning to route dynamic ex- perts in existing multi-modal large language models
Qiong Wu, Zhaoxi Ke, Yiyi Zhou, Xiaoshuai Sun, and Ron- grong Ji. Routing experts: Learning to route dynamic ex- perts in existing multi-modal large language models. InThe Thirteenth International Conference on Learning Represen- tations, 2025. 5
2025
-
[58]
Mma: Multi-modal adapter for vision-language models
Lingxiao Yang, Ru-Yuan Zhang, Yanchen Wang, and Xiao- hua Xie. Mma: Multi-modal adapter for vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23826– 23837, 2024. 4
2024
-
[59]
Tcp: Textual- based class-aware prompt tuning for visual-language model
Hantao Yao, Rui Zhang, and Changsheng Xu. Tcp: Textual- based class-aware prompt tuning for visual-language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23438–23448, 2024. 6, 13, 14
2024
-
[60]
Cross-modality attention with semantic graph embedding for multi-label classification
Renchun You, Zhiyao Guo, Lei Cui, Xiang Long, Yingze Bao, and Shilei Wen. Cross-modality attention with semantic graph embedding for multi-label classification. InProceed- ings of the AAAI conference on artificial intelligence, pages 12709–12716, 2020. 1
2020
-
[61]
Personalized federated continual learning via multi-granularity prompt
Hao Yu, Xin Yang, Xin Gao, Yan Kang, Hao Wang, Junbo Zhang, and Tianrui Li. Personalized federated continual learning via multi-granularity prompt. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4023–4034, 2024. 3
2024
-
[62]
Long-clip: Unlocking the long-text capability of clip
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. Long-clip: Unlocking the long-text capability of clip. InEuropean conference on computer vision, pages 310–325. Springer, 2024. 15
2024
-
[63]
Rethinking misalignment in vision-language model adaptation from a causal perspective.Advances in Neural Information Processing Systems, 37:39224–39248, 2024
Yanan Zhang, Jiangmeng Li, Lixiang Liu, and Wenwen Qiang. Rethinking misalignment in vision-language model adaptation from a causal perspective.Advances in Neural Information Processing Systems, 37:39224–39248, 2024. 3
2024
-
[64]
Multi-label action anticipation for real- world videos with scene understanding.IEEE Transactions on Image Processing, 33:3242–3255, 2024
Yuqi Zhang, Xiucheng Li, Hao Xie, Weijun Zhuang, Shihui Guo, and Zhijun Li. Multi-label action anticipation for real- world videos with scene understanding.IEEE Transactions on Image Processing, 33:3242–3255, 2024. 1
2024
-
[65]
pfedmxf: Personalized federated class-incremental learning with mixture of frequency aggre- gation
Yifei Zhang, Hao Zhu, Alysa Ziying Tan, Dianzhi Yu, Long- tao Huang, and Han Yu. pfedmxf: Personalized federated class-incremental learning with mixture of frequency aggre- gation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 30640–30650, 2025. 3
2025
-
[66]
Federated Learning with Non-IID Data
Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, and Vikas Chandra. Federated learning with non-iid data.arXiv preprint arXiv:1806.00582, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[67]
Learning to prompt for vision-language models.In- ternational Journal of Computer Vision, 130(9):2337–2348,
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.In- ternational Journal of Computer Vision, 130(9):2337–2348,
-
[68]
6 A. More Experiments A.1. More Ablation Studies on Participation Rate Table 6 presents extended ablation studies on all baselines. FedMPT consistently outperforms all state-of-the-art meth- ods by substantial margins, achieving gains of 2.22% mAP, 2.88% CF1, and 3.26% OF1. Notably, methods relying more heavily on visual adaptation (e.g., FedMVP and Fed- ...
-
[69]
context”] 87.14 2 [“context
We can see that changing the order of conditions does not substantially affect the model’s performance, but plac- ingpositionat the beginning seems to cause a minor degra- dation. We suggest that this may result from CLIP focusing more on earlier text tokens than later ones (an inherent bias of CLIP proposed by [62]), andpositionbeing compara- tively hard...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.