PrionNER: A Named Entity Recognition Dataset for Prion Disease Biomedical Literature
Pith reviewed 2026-06-29 12:45 UTC · model grok-4.3
The pith
PrionNER supplies the first manually annotated NER dataset for prion disease entities in 317 PubMed abstracts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
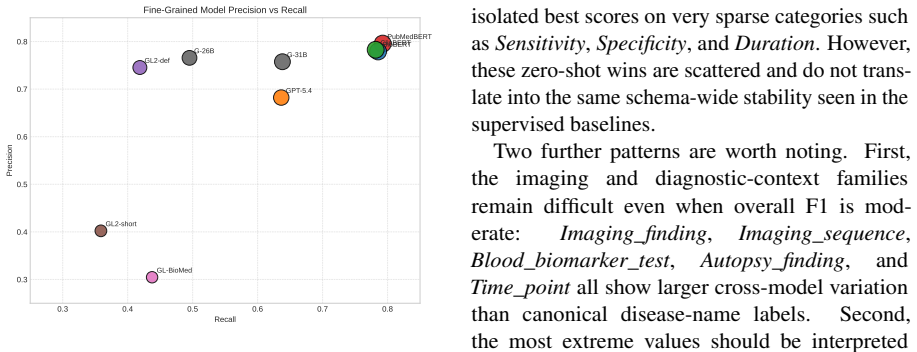
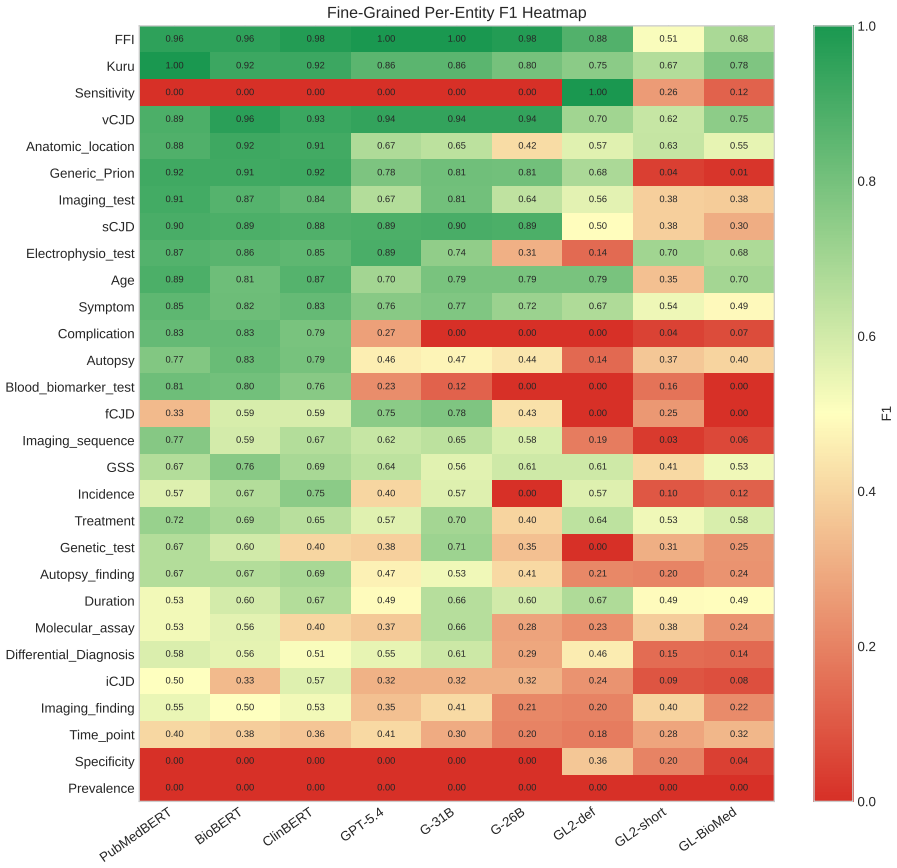
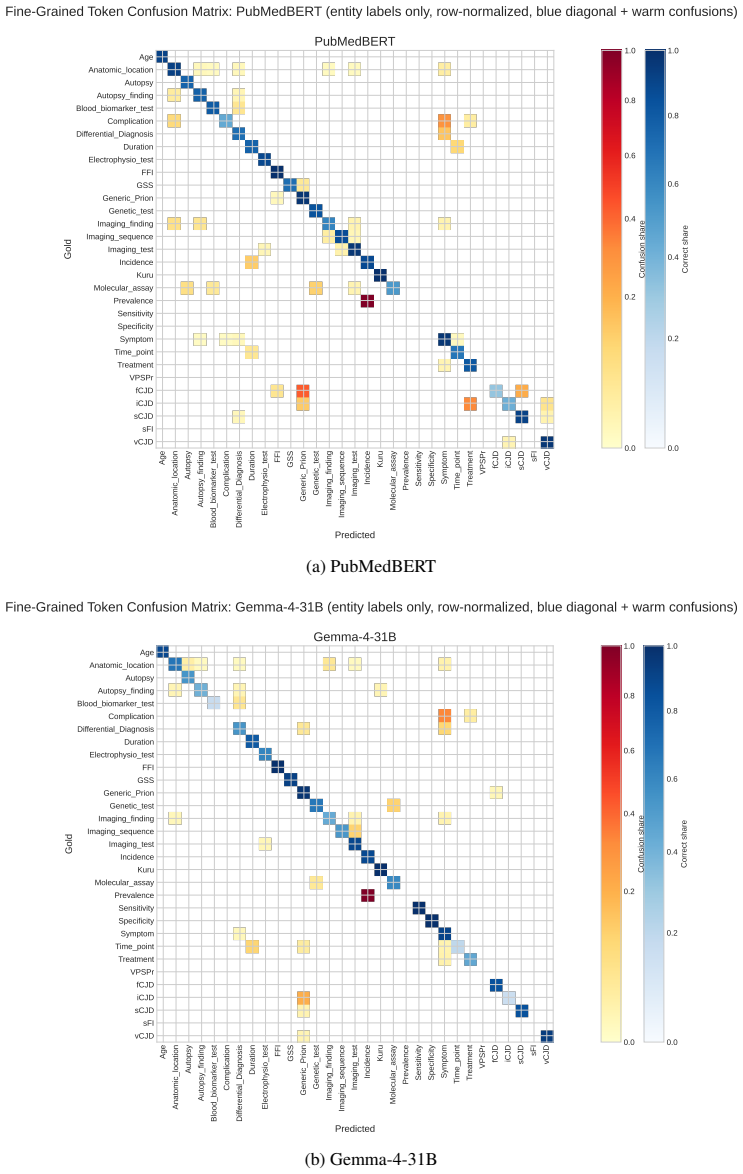
PrionNER is a new dataset of 317 PubMed abstracts containing 2943 sentences and 6955 entity annotations that span 15 coarse-grained and 31 fine-grained clinically oriented types covering diseases, symptoms, diagnostics, findings, anatomy, treatments, and temporal and statistical evidence, with 81.78 exact-match F1 inter-annotator agreement, and it serves as a benchmark where W2NER is the strongest supervised model and Gemma-4-31B the strongest zero-shot model.
What carries the argument
The PrionNER dataset with its 15/31 entity type inventory and annotation guidelines for clinical information in prion disease abstracts.
If this is right
- Supervised models can be trained directly on the 6955 annotations to extract the listed clinical entity types from new prion abstracts.
- Zero-shot models can be evaluated against the fine-grained distinctions that separate adjacent clinical categories.
- The resource supports development of information extraction systems tailored to rare neurodegenerative diseases.
- The annotation scheme provides a template for similar datasets on other low-prevalence conditions.
- Benchmark results indicate that current architectures still need improvement on structurally complex or context-dependent mentions.
Where Pith is reading between the lines
- The dataset could be used to measure how well general biomedical language models transfer to narrow disease domains without additional fine-tuning.
- Extending the annotations from abstracts to full-text articles would test whether the same entity inventory remains sufficient outside the abstract format.
- Linking the extracted entities to existing medical ontologies might reveal gaps in how prion-specific findings are represented in broader knowledge bases.
Load-bearing premise
The selected PubMed abstracts and the chosen entity type categories capture the clinically relevant information that practitioners actually need from prion disease literature.
What would settle it
A comparison showing that models trained on PrionNER extract no more useful clinical entities from held-out prion literature or real patient records than models trained only on general biomedical NER corpora.
Figures

read the original abstract
Prion diseases are rare, rapidly progressive, and fatal neurodegenerative disorders that remain difficult to diagnose, particularly in their early stages because of nonspecific clinical presentations. However, to our knowledge, there is no publicly available prion-disease-focused dataset designed to capture a broad range of clinically relevant entities from the biomedical literature. We introduce PrionNER, a manually annotated named entity recognition dataset for prion disease clinical information in PubMed abstracts. The current release comprises 317 abstracts, 2,943 sentences, and 6,955 text-bound entity annotations spanning 15 coarse-grained and 31 fine-grained clinically oriented entity types covering diseases, symptoms, diagnostics, findings, anatomy, treatments, and temporal and statistical evidence. Inter-annotator agreement reaches 81.78 exact-match F1, indicating strong annotation consistency. We benchmark supervised BERT baselines, W2NER, and zero-shot extractors on PrionNER. W2NER is the strongest supervised model, and Gemma-4-31B is the strongest zero-shot model, but the benchmark remains challenging, especially for structurally complex mentions and fine-grained clinically adjacent label distinctions. PrionNER provides a clinically grounded benchmark for prion-disease information extraction and supports research on rare-disease biomedical NLP under low-resource, fine-grained, and non-flat extraction conditions. The dataset, annotation guidelines, and evaluation scripts are available at https://github.com/daotuanan/PrionNER/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PrionNER, a manually annotated named entity recognition dataset for prion disease clinical information in PubMed abstracts. The current release comprises 317 abstracts, 2,943 sentences, and 6,955 text-bound entity annotations spanning 15 coarse-grained and 31 fine-grained clinically oriented entity types covering diseases, symptoms, diagnostics, findings, anatomy, treatments, and temporal and statistical evidence. Inter-annotator agreement reaches 81.78 exact-match F1. The paper benchmarks supervised BERT baselines, W2NER, and zero-shot extractors, finding W2NER strongest among supervised models and Gemma-4-31B strongest among zero-shot models, while noting the benchmark remains challenging for complex mentions and fine-grained distinctions. The dataset, guidelines, and scripts are publicly released.
Significance. If the reported annotation quality and entity coverage hold, PrionNER fills a documented gap as the first publicly available prion-disease-focused NER resource. The combination of manual annotation, high IAA, clinical entity granularity, and public release of data plus evaluation scripts constitutes a concrete, reusable contribution to rare-disease biomedical NLP under low-resource and fine-grained conditions. The baseline results further establish the dataset as a non-trivial benchmark.
minor comments (3)
- [Introduction] The abstract asserts that 'to our knowledge, there is no publicly available prion-disease-focused dataset'; the introduction should include a short, explicit comparison to existing biomedical NER corpora (e.g., BC5CDR, NCBI Disease) to substantiate this claim rather than leaving it as an assertion.
- [Dataset Construction] Section describing the entity inventory should clarify the relationship between the 15 coarse-grained and 31 fine-grained types (e.g., whether the fine-grained labels are strict subtypes or include additional distinctions) and provide at least one example sentence per major category to aid reader comprehension.
- [Experiments and Results] The results section notes that the benchmark is 'challenging, especially for structurally complex mentions and fine-grained clinically adjacent label distinctions' but provides no quantitative breakdown or illustrative examples; adding a short error-analysis paragraph or table would strengthen the presentation of the baseline findings.
Simulated Author's Rebuttal
We thank the referee for the positive summary of PrionNER and the recommendation of minor revision. The assessment correctly identifies the dataset's scope, annotation quality, and benchmark results. No major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
This is a dataset release paper whose central claims consist of descriptive statistics (317 abstracts, 6,955 annotations, 81.78 IAA F1) obtained directly from manual annotation labor and released data. No equations, fitted parameters, predictions, or derivation chains appear in the provided text. The single self-reference to prior absence of such a dataset is a factual claim about external literature, not a load-bearing premise that reduces to the authors' own prior work. All reported results are externally verifiable via the GitHub release and therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bioinformatics, 36(4):1234–1240
Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240. Jiao Li, Yueping Sun, Robin J Johnson, Daniela Sci- aky, Chih-Hsuan Wei, Robert Leaman, Allan Peter Davis, Carolyn J Mattingly, Thomas C Wiegers, and Zhiyong Lu. 2016. Biocreative v cdr task corpus: a resource for chemical disease r...
2016
-
[2]
MedMentions: A Large Biomedical Corpus Annotated with UMLS Concepts
The raredis corpus: a corpus annotated with rare diseases, their signs and symptoms.Journal of biomedical informatics, 125:103961. Sunil Mohan and Donghui Li. 2019. Medmentions: A large biomedical corpus annotated with umls con- cepts.arXiv preprint arXiv:1902.09476. M Hassan Murad, Lifeng Lin, Haitao Chu, Bashar Hasan, Reem A Alsibai, Alzhraa S Abbas, Re...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, pages 142– 147
Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, pages 142– 147. Ozlem Uzuner, Brett R. South, Shuying Shen, and Scott L. DuVall. 2011. 2010 i2b2/V A challenge on concepts, assertions, and relations in clinical text. Journal o...
2003
-
[4]
Gliner-biomed: A suite of efficient models for open biomedical named entity recognition.arXiv preprint arXiv:2504.00676. Urchade Zaratiana, Gil Pasternak, Oliver Boyd, George Hurn-Maloney, and Ash Lewis. 2025. Gliner2: An efficient multi-task information extraction sys- tem with schema-driven interface.arXiv preprint arXiv:2507.18546. A Data Collection an...
-
[5]
Extract only explicit spans from the text
-
[6]
Use exact labels from the schema
-
[7]
Use exact text spans from the input
-
[8]
Do not output start or end offsets
-
[9]
Do not output comments, markdown, or extra keys
-
[10]
If uncertain, omit the span instead of guessing. Input text: {text} Output exactly one JSON object with this structure: { "text": "<original input text>", "entities": [ { "mention": "<exact span>", "coarse_type": "<schema coarse type>", "fine_type": "<schema fine type>", "normalized": "<normalized form or same as mention>" } ] } B Annotation Guidelines an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.