Latent Diffusion for Missing Data
Pith reviewed 2026-06-29 14:23 UTC · model grok-4.3
The pith
Shifting diffusion to a VAE latent space keeps sample quality stable up to 50% missingness while pixel-space diffusion degrades
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A VAE-based imputer first extracts semantic features from incomplete observations, after which diffusion operates in the resulting latent space; this two-stage model maintains high sample quality and remains stable up to 50% missingness under MCAR, while pixel-space diffusion degrades progressively, and latent diffusion yields consistently better downstream imputation performance.
What carries the argument
The latent space of a VAE-based imputer trained on incomplete data, which serves as the training domain for the diffusion model to learn a generative prior without direct exposure to zero-imputed artifacts
If this is right
- Latent diffusion maintains high sample quality and stability up to 50% missingness under MCAR.
- Pixel-space diffusion degrades progressively as the missingness rate increases.
- Latent diffusion achieves consistently better performance than pixel-space diffusion on downstream imputation tasks.
- Latent-space modeling mitigates artifact amplification that arises from zero-imputed inputs.
Where Pith is reading between the lines
- The same two-stage structure could be tested on missingness mechanisms other than MCAR to check whether the stability advantage persists.
- Replacing the VAE imputer with alternative feature extractors might further reduce distortion in the latent space before diffusion training.
- The observed robustness suggests latent diffusion could be applied to related incomplete-data problems such as noisy observations or partial sensor readings.
Load-bearing premise
A standard VAE trained on zero-imputed or otherwise handled incomplete observations produces a latent space whose semantic features remain sufficiently undistorted for the diffusion model to learn effectively.
What would settle it
Run both the latent and pixel-space diffusion models on the same datasets with exactly 50% MCAR missingness and check whether the latent model still shows higher sample quality and better imputation metrics than the pixel-space baseline.
Figures


read the original abstract
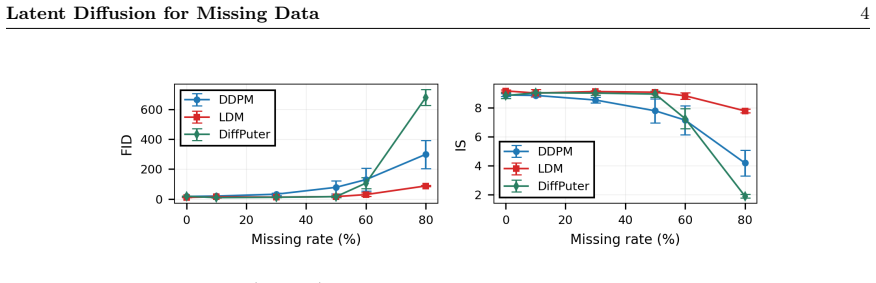
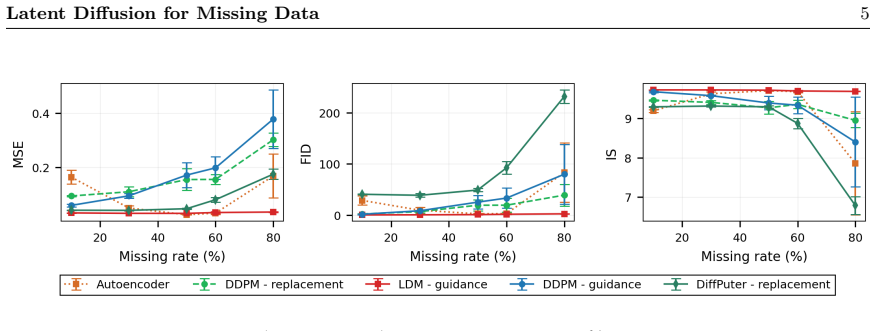
Diffusion models have emerged as powerful generative approaches for missing-data imputation, yet most existing methods operate directly in data space and degrade when training data are heavily incomplete. We investigate whether shifting diffusion to a learned latent representation improves robustness under missing-completely-at-random (MCAR) corruption. To this end, we propose a two-stage framework: a robust VAE-based imputer first learns compact semantic features from incomplete observations, and a diffusion model is then trained in the resulting latent space. Across training missing rates, we perform a controlled comparison against pixel-space diffusion models under the same incomplete-data setting. The latent diffusion model maintains high sample quality and remains stable up to 50% missingness, while pixel-space diffusion degrades progressively as missingness increases. For downstream imputation, latent diffusion also achieves consistently better performance than pixel-space diffusion. These findings indicate that latent-space modeling mitigates artifact amplification from zero-imputed inputs and provides a more robust generative prior for incomplete-data learning. Overall, our results support latent diffusion as a strong and practically useful alternative to pixel-space diffusion for missing-data problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a two-stage framework for missing-data imputation with diffusion models under MCAR: a VAE-based imputer is first trained on incomplete (zero-imputed) observations to produce compact latent representations, after which a diffusion model is trained in that latent space. Controlled comparisons against pixel-space diffusion are reported to show that the latent approach maintains sample quality and stability up to 50% missingness while pixel-space diffusion degrades, and yields better downstream imputation performance. The work concludes that latent-space modeling mitigates zero-imputation artifacts and supplies a more robust generative prior.
Significance. If the central empirical claims are supported by rigorous quantitative results, ablations, and controls, the paper would demonstrate a practical route to improving diffusion-model robustness on incomplete data by shifting the generative process to a learned latent space. This addresses a common real-world limitation and could be useful for practitioners. The controlled comparison setup is a methodological strength.
major comments (1)
- [Methods / VAE training description] Methods / VAE stage: The central claim that latent diffusion itself confers robustness (rather than the VAE stage) requires that the VAE encoder produces semantically undistorted latents when trained on zero-imputed inputs with up to 50% MCAR missingness. No analysis, ablation, or diagnostic (e.g., comparison of latent statistics or reconstructions on complete vs. zero-imputed data, or alternative VAE imputation strategies) is supplied to substantiate this; without it the observed stability could be an artifact of the first-stage imputer rather than evidence for latent-space diffusion.
minor comments (1)
- [Abstract] Abstract: performance advantages are asserted without any numerical metrics, error bars, dataset sizes, or baseline details, which hinders immediate evaluation of effect sizes.
Simulated Author's Rebuttal
We thank the referee for the constructive comment. We agree that the current manuscript does not provide direct diagnostics isolating the VAE stage from the latent diffusion stage, and we will add the requested analyses in revision to strengthen the central claim.
read point-by-point responses
-
Referee: The central claim that latent diffusion itself confers robustness (rather than the VAE stage) requires that the VAE encoder produces semantically undistorted latents when trained on zero-imputed inputs with up to 50% MCAR missingness. No analysis, ablation, or diagnostic (e.g., comparison of latent statistics or reconstructions on complete vs. zero-imputed data, or alternative VAE imputation strategies) is supplied to substantiate this; without it the observed stability could be an artifact of the first-stage imputer rather than evidence for latent-space diffusion.
Authors: We agree that the manuscript lacks explicit diagnostics on the VAE encoder under missing data, which is needed to attribute robustness specifically to latent-space diffusion. In the revised version we will add: (1) comparison of latent mean/variance statistics and t-SNE visualizations for VAEs trained on complete data versus zero-imputed data at 10-50% MCAR; (2) reconstruction PSNR/SSIM on held-out complete test images when the VAE is trained only on incomplete observations; (3) an ablation replacing the VAE imputer with mean imputation or a simple linear autoencoder before latent diffusion. These additions will clarify whether the observed stability arises from the latent diffusion prior or from the first-stage imputer. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations
full rationale
The paper describes a two-stage empirical framework (VAE imputer followed by latent diffusion) and reports experimental results on sample quality and imputation performance under varying MCAR rates. No equations, derivations, predictions, or uniqueness theorems are presented that could reduce to inputs by construction. All claims are grounded in controlled comparisons against baselines rather than any self-referential or fitted-input structure. The work is self-contained as an empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://doi.org/10.1198/ jasa.2011.tm11181
doi: 10.1198/jasa.2011.tm11181. URLhttps://doi.org/10.1198/ jasa.2011.tm11181. PMID: 22505788. Josh Givens, Song Liu, and Henry Reeve. Score matching with missing data. InForty-second International Conference on Machine Learning,
-
[2]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
URL https://arxiv.org/abs/1706.08500. Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-VAE: Learning basic visual concepts with a constrained variational framework. InInternational Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
URL https://arxiv.org/abs/2006.11239. Peter E. Kloeden and Eckhard Platen.Numerical Solution of Stochastic Differential Equa- tions. Springer Berlin, Heidelberg,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[4]
MIWAE: Deep Generative Modelling and Imputation of Incomplete Data
URLhttps://arxiv.org/abs/1812.02633. Alfredo Nazabal, Pablo M Olmos, Zoubin Ghahramani, and Isabel Valera. Handling incomplete heterogeneous data using vaes.Pattern Recognition, 107:107501,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Yidong Ouyang, Liyan Xie, Chongxuan Li, and Guang Cheng. Missdiff: Training diffusion models on tabular data with missing values.arXiv preprint arXiv:2307.00467,
-
[6]
High-Resolution Image Synthesis with Latent Diffusion Models
URLhttps://arxiv.org/abs/ 2112.10752. Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Improved Techniques for Training GANs
URLhttps://arxiv.org/abs/1606.03498. Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Score-Based Generative Modeling through Stochastic Differential Equations
URL https://arxiv.org/abs/2011.13456. Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. CSDI: Conditional score-based diffusion models for probabilistic time series imputation. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[9]
GAIN: Missing Data Imputation using Generative Adversarial Nets
URLhttps://arxiv.org/abs/1806.02920. Hengrui Zhang, Liancheng Fang, Qitian Wu, and Philip S. Yu. Diffputer: Empowering diffusion models for missing data imputation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Shuhan Zheng and Nontawat Charoenphakdee
URLhttps://arxiv.org/abs/2405.20690. Shuhan Zheng and Nontawat Charoenphakdee. Diffusion models for missing value imputation in tabular data,
-
[11]
Diffusion models for missing value imputation in tabular data.arXiv preprint arXiv:2210.17128, 2022
URLhttps://arxiv.org/abs/2210.17128. Latent Diffusion for Missing Data8 Appendix A. Experimental Setup A.1. Architecture A.1.1. Score Network We use a DDPM++ architecture based on Ho et al. (2020) and Song et al. (2021). The network is a U-Net with sinusoidal timestep embeddings, group normalization, and rescaled skip connections. We trained on MNIST with...
-
[12]
Table 1.Model Architectures. Hyperparameter Pixel-space Latent-space Base channels 48 64 Channel multipliers 1, 2, 4 1, 2 Residual blocks per resolution 3 2 Attention resolutions None 7 Dropout∼0.12∼0.08 Group normalization groups 16 16 For DiffPuter, we used the architecture specified by Zhang et al. (2025) in their Appendix D.4. A.1.2. Autoencoder For l...
2025
-
[13]
A.2.1. Noise Schedule We use the VP SDE with linearβ-schedule: β(t) =β min +t(β max −β min), t∈[τ,1] (7) Latent Diffusion for Missing Data9 withβ min = 0.1 andβ max = 20.0, following Song et al. (2021). We discretize withT= 1000 timesteps and useτ= 10 −3 as the minimum time for numerical stability. A.2.2. Diffusion in Latent Space When traing diffusion mo...
2021
-
[14]
IS measures both diversity and clarity of generated images, reflecting how easily they can be classified as distinct digits, with 10 being the highest score
and FID (Heusel et al., 2018). IS measures both diversity and clarity of generated images, reflecting how easily they can be classified as distinct digits, with 10 being the highest score. FID measures the similarity between the distributions of generated and real images, capturing how much generated samples resemble the MNIST test set. For imputation, we...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.