Bilinear Coordinate Alignment for Training-Free Task-Vector Transfer
Pith reviewed 2026-06-29 14:19 UTC · model grok-4.3
The pith
Task vectors form from bilinear interactions between activations and gradients and transfer across models by aligning those spaces without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Task vectors can be derived as accumulated bilinear interactions between input-side activations and output-side gradients. Formulating task-vector transfer as a dual-space alignment problem, BiCo estimates orthogonal Procrustes mappings in both the activation space and the gradient space from a single forward-backward pass on a small calibration set, without any parameter update, and thereby transfers task expertise across models that differ in width, depth, and pre-training configuration.
What carries the argument
Bilinear Coordinate alignment (BiCo), which computes separate orthogonal Procrustes mappings for activation and gradient spaces to align task vectors derived from bilinear interactions.
If this is right
- Task expertise moves between models of different widths and depths without retraining.
- Transfer succeeds on both computer-vision and natural-language benchmarks.
- Only a small calibration set and one forward-backward pass are needed.
- Performance improves over methods that align only activations or only gradients.
- No gradient steps or parameter changes occur during the transfer step.
Where Pith is reading between the lines
- The same dual-alignment step could be inserted into pipelines that already move models between different tokenizers or embedding dimensions.
- If the bilinear view holds, analogous alignments might reduce the cost of merging multiple task vectors into one model.
- The calibration-set size needed for stable Procrustes estimates could be tested as a function of model scale to find practical limits.
- The method might extend directly to continual-learning settings where a base model is periodically replaced.
Load-bearing premise
The bilinear interactions captured by one forward-backward pass on a small calibration set supply enough correspondence to move task expertise between models that differ in width, depth, and pre-training history.
What would settle it
Applying the two estimated Procrustes mappings to a held-out model pair differing in depth and width and finding that accuracy stays at the level of prior activation-only or gradient-only baselines would falsify the claim that dual bilinear alignment is required and sufficient.
Figures
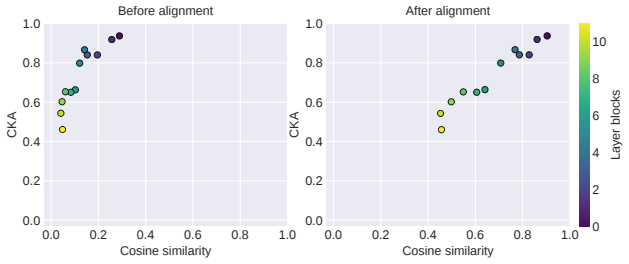

read the original abstract
Fine-tuning large-scale pre-trained models is a recent prevalent paradigm for adapting general representations to specialized tasks. However, when a new version of a pre-trained model becomes available, expertise acquired through fine-tuning cannot be directly reused because it is tied to the parameterization of the original model, requiring another costly fine-tuning. To address this inefficiency, recent work uses task vectors, defined as the parameter difference between a fine-tuned model and its base model, to transfer expertise across models. While existing methods bridge disparate models by matching activations or gradients, a significant performance gap remains relative to direct fine-tuning, suggesting that these partial correspondences are insufficient. In this work, instead of viewing a task vector merely as a parameter offset, we revisit the formation of task vectors and show that they can be derived as accumulated bilinear interactions between input-side activations and output-side gradients. Motivated by this observation, we formulate task-vector transfer as a dual-space alignment problem and propose BiCo, a training-free framework for transferring task vectors through Bilinear Coordinate alignment. BiCo estimates orthogonal Procrustes mappings in both spaces using a single forward-backward pass on a small calibration set, without any parameter update. Across extensive computer vision and natural language processing benchmarks, BiCo consistently outperforms existing transfer methods across models that differ in width, depth, and pre-training configuration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that task vectors arise as accumulated bilinear interactions between input-side activations and output-side gradients rather than mere parameter offsets. It formulates transfer as a dual-space alignment problem and introduces BiCo, a training-free method that estimates orthogonal Procrustes mappings in activation and gradient spaces from a single forward-backward pass on a small calibration set, without parameter updates. Experiments on CV and NLP benchmarks show consistent gains over prior activation- or gradient-matching baselines when transferring across models that differ in width, depth, and pre-training.
Significance. If the bilinear derivation is exact and the single-pass dual alignment suffices to close the gap left by partial correspondences, the result would be significant: it offers a parameter-free route to reuse fine-tuning expertise across evolving base models, reducing repeated fine-tuning costs in both vision and language domains.
major comments (2)
- [§3 (derivation of task vectors)] The central derivation that task vectors equal accumulated bilinear interactions (activations × gradients) is load-bearing for the dual Procrustes formulation; without an explicit expansion or proof that this equivalence holds exactly (rather than approximately), it is unclear why aligning both spaces with one calibration pass should succeed where single-space methods failed.
- [§4 (BiCo construction) and experimental tables] The claim that a single forward-backward pass on a small calibration set yields sufficient correspondence for models differing in width, depth, and pre-training rests on the weakest assumption; prior partial correspondences left a performance gap, yet no theoretical bound or ablation demonstrates why the bilinear combination closes it.
minor comments (2)
- [§4] Notation for the two Procrustes mappings (activation-space and gradient-space) should be introduced with explicit symbols and distinguished from the task vector itself to avoid reader confusion.
- [Experiments] The abstract states 'extensive' benchmarks but does not reference specific effect sizes or failure cases; adding a table of per-task deltas relative to direct fine-tuning would strengthen the empirical section.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [§3 (derivation of task vectors)] The central derivation that task vectors equal accumulated bilinear interactions (activations × gradients) is load-bearing for the dual Procrustes formulation; without an explicit expansion or proof that this equivalence holds exactly (rather than approximately), it is unclear why aligning both spaces with one calibration pass should succeed where single-space methods failed.
Authors: Section 3 derives the task vector exactly as the sum of bilinear terms (activations outer-product gradients) by expanding the gradient of the fine-tuning loss with respect to the parameters of a linear layer. The equivalence follows directly from the chain rule under standard back-propagation assumptions and holds exactly for the definition of task vectors used throughout the literature; it is not an approximation. We will insert additional intermediate algebraic steps in the revised version to make the exactness explicit. revision: partial
-
Referee: [§4 (BiCo construction) and experimental tables] The claim that a single forward-backward pass on a small calibration set yields sufficient correspondence for models differing in width, depth, and pre-training rests on the weakest assumption; prior partial correspondences left a performance gap, yet no theoretical bound or ablation demonstrates why the bilinear combination closes it.
Authors: We do not supply a theoretical bound on the gap closure. The manuscript instead reports extensive empirical evidence (Section 5 and associated ablations) that the dual-space orthogonal Procrustes alignment, obtained from one forward-backward pass, consistently narrows the gap left by single-space baselines across width, depth, and pre-training mismatches. The bilinear construction is motivated by the exact derivation in §3, which supplies the rationale for why both spaces must be aligned; the experiments then validate that this suffices in practice. revision: no
- A theoretical bound guaranteeing that bilinear dual-space alignment closes the performance gap for arbitrary model differences.
Circularity Check
No circularity: task-vector bilinear derivation presented as independent mathematical observation; alignment method uses external calibration data without self-referential reduction
full rationale
The paper's core derivation chain begins with the standard definition of a task vector as the parameter difference between fine-tuned and base models. It then claims to derive this as accumulated bilinear interactions between activations and gradients, which is presented as a first-principles observation rather than a redefinition or fit. The subsequent dual-space Procrustes alignment is estimated from a single forward-backward pass on an external calibration set and evaluated on benchmarks across differing architectures; no step reduces the claimed transfer performance to a fitted parameter renamed as prediction, nor relies on load-bearing self-citations or ansatzes imported from prior author work. The method is self-contained against external benchmarks with no evidence of the result being equivalent to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Ainsworth, Jonathan Hayase, and Siddhartha Srinivasa
Samuel K. Ainsworth, Jonathan Hayase, and Siddhartha Srinivasa. Git re-basin: Merging models modulo permutation symmetries. InICLR, 2023
2023
-
[3]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Revisiting model stitching to compare neural representations
Yamini Bansal, Preetum Nakkiran, and Boaz Barak. Revisiting model stitching to compare neural representations. InNeurIPS, 2021
2021
-
[5]
Bowman, Gabor Angeli, Christopher Potts, and Christopher D
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. A large annotated corpus for learning natural language inference. InEMNLP, 2015
2015
-
[6]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
2020
-
[7]
Remote sensing image scene classification: Benchmark and state of the art.Proceedings of the IEEE, 2017
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sensing image scene classification: Benchmark and state of the art.Proceedings of the IEEE, 2017
2017
-
[8]
Whoever started the interference should end it: Guiding data-free model merging via task vectors
Runxi Cheng, Feng Xiong, Yongxian Wei, Wanyun Zhu, and Chun Yuan. Whoever started the interference should end it: Guiding data-free model merging via task vectors. InICML, 2025
2025
-
[9]
Reproducible scaling laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. InCVPR, 2023
2023
-
[10]
Mohamed, and A
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, S. Mohamed, and A. Vedaldi. Describing textures in the wild. InCVPR, 2014
2014
-
[11]
Matszangosz, Gergely Papp, and Dániel Varga
Adrián Csiszárik, Péter K˝orösi-Szabó, Ákos K. Matszangosz, Gergely Papp, and Dániel Varga. Similarity and matching of neural network representations. InNeurIPS, 2021
2021
-
[12]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
2021
-
[13]
Datacomp: In search of the next generation of multimodal datasets
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, Eyal Orgad, Rahim Entezari, Giannis Daras, Sarah Pratt, Vivek Ramanujan, Yonatan Bitton, Kalyani Marathe, Stephen Mussmann, Richard Vencu, Mehdi Cherti, Ranjay Krishna, Pang Wei Koh, Olga Saukh, Alexan...
2023
-
[14]
Task singular vectors: Reducing task interference in model merging
Antonio Andrea Gargiulo, Donato Crisostomi, Maria Sofia Bucarelli, Simone Scardapane, Fabrizio Silvestri, and Emanuele Rodolà. Task singular vectors: Reducing task interference in model merging. InCVPR, 2025
2025
-
[15]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019. 10
2019
-
[16]
Editing models with task arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. InICLR, 2023
2023
-
[17]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[18]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InICML, 2019
2019
-
[19]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. InICCV Workshop, 2013
2013
-
[20]
Lecun, L
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 1998
1998
-
[21]
Zheda Mai, Ke Zhang, Fu-En Wang, Zixiao Ken Wang, Albert Y . C. Chen, Lu Xia, Min Sun, Wei-Lun Chao, and Cheng-Hao Kuo. Revisiting model stitching in the foundation model era. InCVPR, 2026
2026
-
[22]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y . Ng. Reading digits in natural images with unsupervised feature learning. InNIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011
2011
-
[23]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 2020
2020
-
[24]
Update your trans- former to the latest release: Re-basin of task vectors
Filippo Rinaldi, Giacomo Capitani, Lorenzo Bonicelli, Donato Crisostomi, Federico Bolelli, Elisa Ficarra, Emanuele Rodolà, Simone Calderara, and Angelo Porrello. Update your trans- former to the latest release: Re-basin of task vectors. InICML, 2025
2025
-
[25]
Gradient-sign masking for task vector transport across pre- trained models
Filippo Rinaldi, Aniello Panariello, Giacomo Salici, Fengyuan Liu, Marco Ciccone, Angelo Porrello, and Simone Calderara. Gradient-sign masking for task vector transport across pre- trained models. InICLR, 2026
2026
-
[26]
Transporting Task Vectors across Different Architectures without Training
Filippo Rinaldi, Aniello Panariello, Giacomo Salici, Angelo Porrello, and Simone Calder- ara. Transporting task vectors across different architectures without training.arXiv preprint arXiv:2602.12952, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Schönemann
Peter H. Schönemann. A generalized solution of the orthogonal procrustes problem.Psychome- trika, 1966
1966
-
[28]
Laion-5b: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. Laion-5b: An open large-scale dataset for training next generation image-text models....
2022
-
[29]
Natural Language Understanding with the Quora Question Pairs Dataset
Lakshay Sharma, Laura Graesser, Nikita Nangia, and Utku Evci. Natural language understand- ing with the quora question pairs dataset.arXiv preprint arXiv:1907.01041, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[30]
The german traffic sign recognition benchmark: A multi-class classification competition
Johannes Stallkamp, Marc Schlipsing, Jan Salmen, and Christian Igel. The german traffic sign recognition benchmark: A multi-class classification competition. InIJCNN, 2011
2011
-
[31]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. In ICLR, 2019. 11
2019
-
[33]
Localizing task information for improved model merging and compression
Ke Wang, Nikolaos Dimitriadis, Guillermo Ortiz-Jimenez, François Fleuret, and Pascal Frossard. Localizing task information for improved model merging and compression. InICML, 2024
2024
-
[34]
Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M
Jason Wei, Maarten Bosma, Vincent Y . Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V . Le. Finetuned language models are zero-shot learners. In ICLR, 2022
2022
-
[35]
A broad-coverage challenge corpus for sentence understanding through inference
Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. InNAACL-HLT, 2018
2018
-
[36]
Robust fine-tuning of zero-shot models
Mitchell Wortsman, Gabriel Ilharco, Jong Wook Kim, Mike Li, Simon Kornblith, Rebecca Roelofs, Raphael Gontijo-Lopes, Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, and Ludwig Schmidt. Robust fine-tuning of zero-shot models. InCVPR, 2022
2022
-
[37]
Ehinger, Aude Oliva, and Antonio Torralba
Jianxiong Xiao, James Hays, Krista A. Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. InCVPR, 2010
2010
-
[38]
Ties-merging: Resolving interference when merging models
Prateek Yadav, Derek Tam, Leshem Choshen, Colin Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models. InNeurIPS, 2023
2023
-
[39]
Language models are super mario: Absorbing abilities from homologous models as a free lunch
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. Language models are super mario: Absorbing abilities from homologous models as a free lunch. InICML, 2024. 12 Table of contents We provide the following items in this Appendix: • (A) Pseudocode of BiCo • (B) Activation consistency along fine-tuning trajectories • (C) Cross-width representational simi...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.