Beyond One Path: Evaluating and Enhancing Divergent Thinking in Interactive LLM Agents
Pith reviewed 2026-06-29 12:20 UTC · model grok-4.3
The pith
ReDNA enables LLM agents to improve divergent thinking by separating unconstrained candidate generation from convergent selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReDNA significantly outperforms prior methods across both divergence levels and generalizes effectively to an external creativity environment. Its success stems from a qualitative enhancement of resilient divergent reasoning rather than simple environmental exploration.
What carries the argument
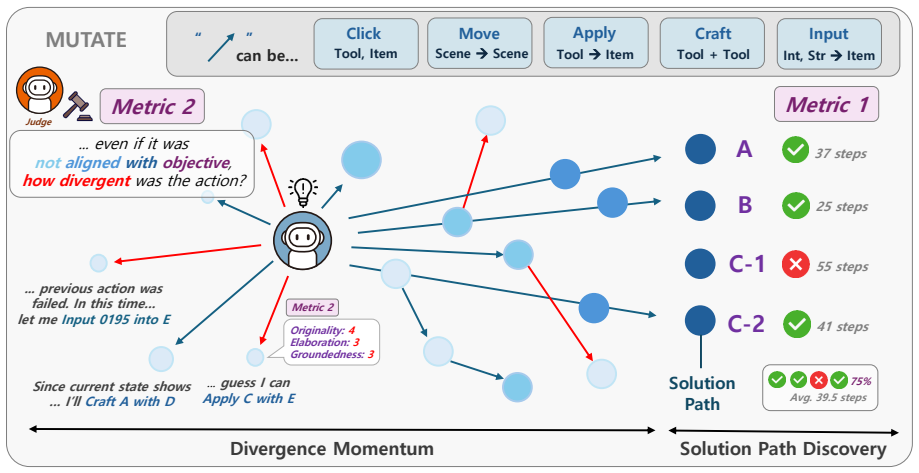
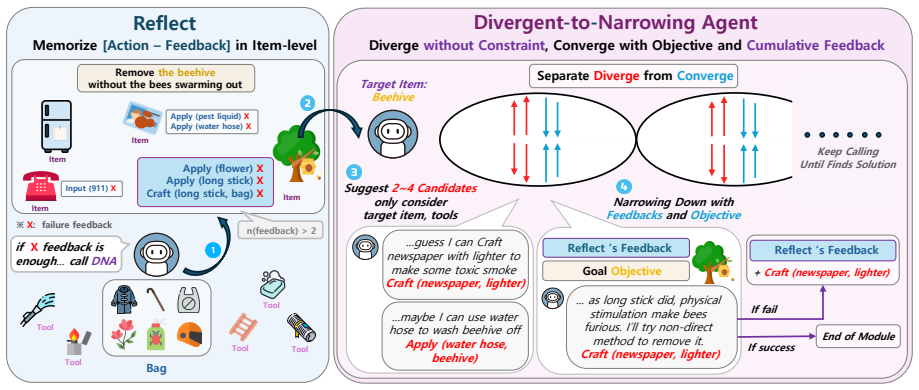
ReDNA, which separates unconstrained divergent candidate generation from convergent constraint selection.
If this is right
- LLM agents using ReDNA discover more alternative paths to the same goal on interactive tasks.
- Agents generate more non-typical, mechanism-shifting actions at the individual step level.
- Gains persist even when models face immediate pressure to converge on a solution.
- The approach transfers to creativity environments outside the MUTATE benchmark.
- Improvements trace to better quality of divergent reasoning steps rather than increased volume of attempts.
Where Pith is reading between the lines
- The separation of generation and selection phases could be tested in other interactive agent domains such as scientific hypothesis formation.
- Re-running the experiments across a broader set of base models would clarify whether the reported isolation of reasoning quality holds beyond the tested frontier LLMs.
- Future benchmarks could add metrics that distinguish reasoning resilience from simple increases in exploration budget.
Load-bearing premise
The MUTATE benchmark and the reported experiments accurately isolate the effect of ReDNA on divergent reasoning quality independent of task design choices or the specific frontier LLMs tested.
What would settle it
Showing that ReDNA produces no performance gain over baselines when the same tasks are run with altered design choices or different LLMs would indicate the gains do not stem from resilient divergent reasoning.
Figures




read the original abstract
Divergent thinking is a core dimension of creativity, yet existing evaluations of Large Language Models (LLMs) treat them as single-turn text generations, failing to capture how an agent reasons through iterative interaction. To address this, we introduce MUTATE, an interactive benchmark designed to evaluate agentic divergent thinking at two levels: path-level, where an agent discovers multiple alternative paths to the same goal, and action-level, where individual actions require non-typical, mechanism-shifting object uses. Unlike success-only evaluations, MUTATE scores both completed paths and off-path attempts, capturing divergent reasoning that conventional success rates discard. Our experiments with frontier LLMs reveal a structural blind spot in existing frameworks: when exposed to immediate convergence pressure, they tend to fall into immediate action fixation, failing to improve action-level divergence. To overcome this, we propose ReDNA, which separates unconstrained divergent candidate generation from convergent constraint selection. ReDNA significantly outperforms prior methods across both divergence levels and generalizes effectively to an external creativity environment. We also confirm its success stems from a qualitative enhancement of resilient divergent reasoning rather than simple environmental exploration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MUTATE, an interactive benchmark evaluating LLM agents on divergent thinking at path-level (multiple alternative paths to a goal) and action-level (non-typical object uses), scoring both successful and off-path attempts. It identifies a structural blind spot where frontier LLMs exhibit action fixation under convergence pressure, and proposes ReDNA, which decouples unconstrained divergent candidate generation from convergent constraint selection. Experiments claim ReDNA significantly outperforms prior methods on both divergence levels, generalizes to an external creativity environment, and achieves this via qualitative enhancement of resilient divergent reasoning rather than mere increases in exploration volume.
Significance. If substantiated with appropriate controls, the work supplies a needed interactive benchmark for agentic creativity and a method that could improve evaluation and training of divergent reasoning in LLMs, addressing limitations of single-turn success-only metrics.
major comments (3)
- [Experiments section (results on MUTATE and external environment)] The central claim that ReDNA's gains reflect qualitative enhancement of resilient divergent reasoning (rather than exploration volume) is load-bearing yet unsecured: the experiments section provides no ablations that apply equivalent numbers of attempts or path-diversity pressure to baselines, nor path-diversity metrics that would isolate the effect.
- [§5 (generalization experiments)] The generalization result to the external creativity environment is presented without evidence that task design choices or LLM-specific factors were controlled equivalently across methods; this leaves open whether outperformance is benchmark- or model-specific rather than a general property of ReDNA.
- [Table 2 (action-level results)] Table reporting action-level divergence scores does not include error bars or statistical tests across multiple frontier LLMs, making it impossible to assess whether the reported improvement over baselines is robust or driven by particular model behaviors.
minor comments (2)
- [§3 (MUTATE benchmark)] Define the precise scoring formula for off-path attempts in MUTATE more explicitly, including how partial credit or mechanism-shifting is quantified.
- [§4 (ReDNA method)] Clarify the exact prompting templates used for the 'unconstrained divergent candidate generation' step in ReDNA versus baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each major point below, clarifying our experimental design where possible and committing to revisions that strengthen the evidence.
read point-by-point responses
-
Referee: [Experiments section (results on MUTATE and external environment)] The central claim that ReDNA's gains reflect qualitative enhancement of resilient divergent reasoning (rather than exploration volume) is load-bearing yet unsecured: the experiments section provides no ablations that apply equivalent numbers of attempts or path-diversity pressure to baselines, nor path-diversity metrics that would isolate the effect.
Authors: We agree that the current experiments do not include explicit ablations matching attempt volume or path-diversity pressure across methods. ReDNA's core design decouples generation to remove convergence pressure, which is the source of the claimed qualitative difference, but direct controls would better isolate this from volume effects. We will add such ablations (e.g., baselines given equivalent unconstrained generations) and report path-diversity metrics in the revised experiments section. revision: yes
-
Referee: [§5 (generalization experiments)] The generalization result to the external creativity environment is presented without evidence that task design choices or LLM-specific factors were controlled equivalently across methods; this leaves open whether outperformance is benchmark- or model-specific rather than a general property of ReDNA.
Authors: The external experiments used identical frontier LLMs and followed the published task protocols of the external environment as closely as possible. We will expand §5 with explicit documentation of these alignments and any minor adaptations made. If additional controls are feasible within compute limits, we will include them; otherwise the expanded description will clarify the scope of the generalization claim. revision: partial
-
Referee: [Table 2 (action-level results)] Table reporting action-level divergence scores does not include error bars or statistical tests across multiple frontier LLMs, making it impossible to assess whether the reported improvement over baselines is robust or driven by particular model behaviors.
Authors: We agree that error bars and statistical tests are needed for robustness assessment. We will re-run the action-level experiments over multiple seeds, add error bars to Table 2, and include statistical significance tests (e.g., paired t-tests) across the frontier LLMs in the revision. revision: yes
Circularity Check
No circularity; empirical benchmark and method evaluation is self-contained
full rationale
The paper introduces the MUTATE benchmark for evaluating agentic divergent thinking at path and action levels, along with the ReDNA method that separates divergent candidate generation from convergent selection. Claims of outperformance and generalization rest on experimental results with frontier LLMs, scored on completed paths and off-path attempts. No equations, parameter fits renamed as predictions, self-citations as load-bearing premises, or ansatzes smuggled via prior work appear in the provided text. The central claims are independent empirical observations on a newly defined benchmark and are therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267. Yufei Tian, Abhilasha Ravichander, Lianhui Qin, Ronan Le Bras, Raja Marjieh, Nanyun Peng, Yejin Choi, Thomas L Griffiths, and Faeze Brahman. 2024. Mac- gyver: Are large language models creative problem solvers? InProceedings of the 2024 Conference of the North American Chapter of the Association fo...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Section B provides per-model reasoning style analyses, including representative trajectory ex- cerpts for GPT, Claude, Llama, and Qwen fami- lies
-
[3]
Section C validates the evaluation metrics, in- cluding LLM-as-a-judge agreement with human annotations and the human solving protocol for Metric 1
-
[4]
Section D provides implementation details for the compared methods, including the Base agent, Self-Refine, EscapeAgent, and ReDNA
-
[5]
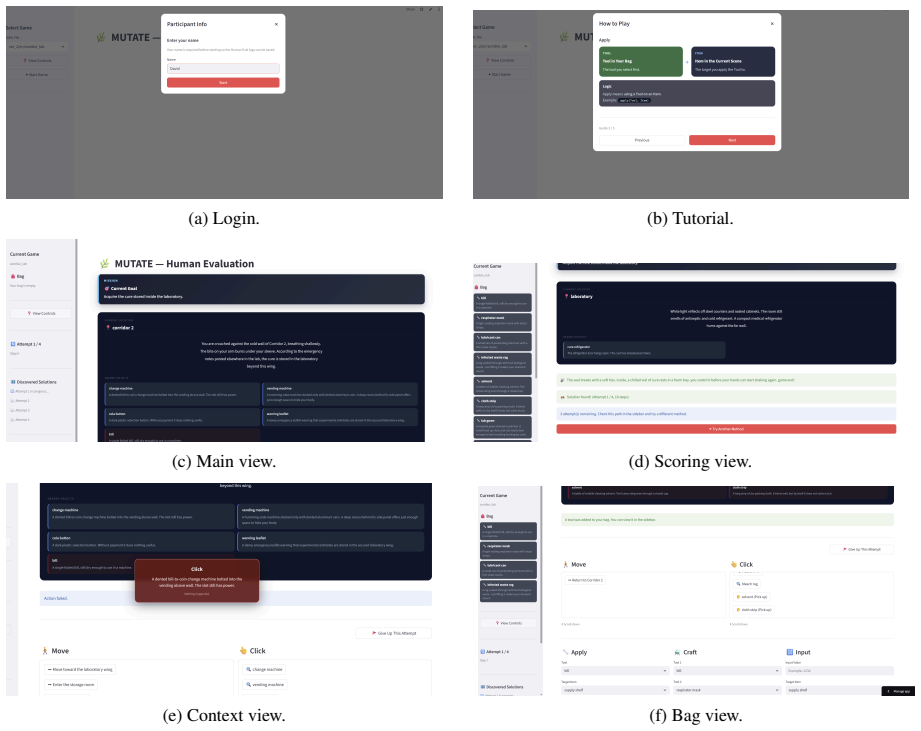
Section E describes the MUTATE bench- mark, including the YAML scenario structure, solution-path catalog, per-scenario path discov- ery, and the human-evaluation UI
-
[6]
the same level of agreement between humans
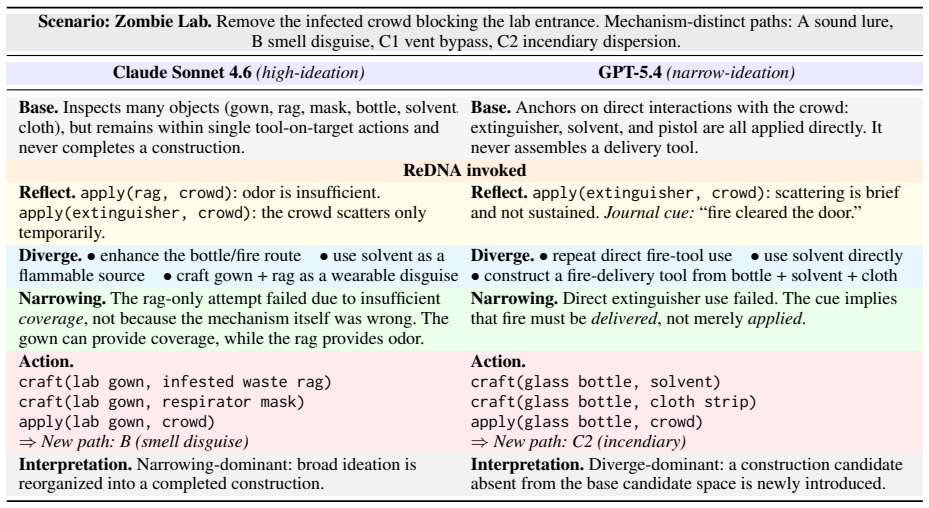
Section F lists the full prompt templates used for the Base agent, EscapeAgent, Self-Refine, and ReDNA. B Per-Model Reasoning Style Analysis Section 5.1 groups the eight models into two action- level ideation profiles—high-ideation (Claude Son- net 4.6, Qwen3-235B) and narrow-ideation (GPT- 5.4, Llama-4-Maverick)—and shows that ReDNA acts through differen...
2023
-
[7]
You may ONLY use names explicitly listed in Possible Actions
-
[8]
If you want to use it later, click it first
A visible tool in the scene is NOT in your bag yet. If you want to use it later, click it first
-
[9]
The FIRST argument is the base tool
craft can ONLY be used between TWO TOOLS already in your bag. The FIRST argument is the base tool. The SECOND argument is the ingredient tool
-
[10]
The second argument of apply() must appear under Possible Actions items
apply can ONLY target an INTERACTABLE ITEM IN THE CURRENT SCENE. The second argument of apply() must appear under Possible Actions items. If the target is a tool, use craft()
-
[11]
If you are considering craft or apply, first check whether both required tools are already in your bag, and whether the target is an item rather than a tool
-
[12]
Change the target, collect missing tools, move, or try a different mechanism
If an action fails, do not repeat the same failed hypothesis immediately. Change the target, collect missing tools, move, or try a different mechanism
-
[13]
Prefer actions that increase future options: explore scenes, click unexplored items, collect relevant tools, then apply or craft from observed evidence
-
[14]
Because there can be multiple solutions, do not assume there is only one correct next step
-
[15]
: It leads to
After craft(A, B) SUCCEEDS, do NOT attempt craft(A, B) or craft(B, A) again. The ingredient B is consumed on success. ANTI-LOOP RULES: - If an action fails ONCE, do NOT repeat the exact same action. - NEVER use apply(X, Y) where Y is a tool in your bag or a visible tool in the scene. Use craft() for tool-on- tool operations. - After craft(A, B) succeeds, ...
-
[16]
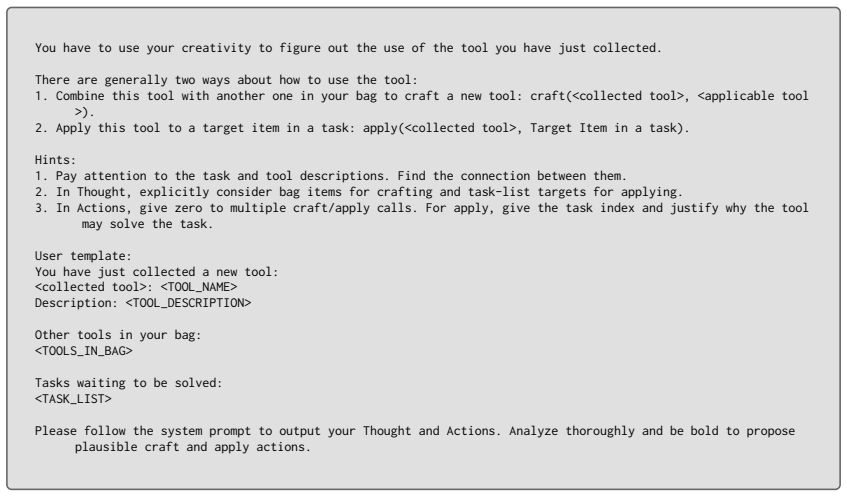
Combine this tool with another one in your bag to craft a new tool: craft(<collected tool>, <applicable tool >)
-
[17]
Apply this tool to a target item in a task: apply(<collected tool>, Target Item in a task). Hints:
-
[18]
Find the connection between them
Pay attention to the task and tool descriptions. Find the connection between them
-
[19]
In Thought, explicitly consider bag items for crafting and task-list targets for applying
-
[20]
For apply, give the task index and justify why the tool may solve the task
In Actions, give zero to multiple craft/apply calls. For apply, give the task index and justify why the tool may solve the task. User template: You have just collected a new tool: <collected tool>: <TOOL_NAME> Description: <TOOL_DESCRIPTION> Other tools in your bag: <TOOLS_IN_BAG> Tasks waiting to be solved: <TASK_LIST> Please follow the system prompt to ...
-
[21]
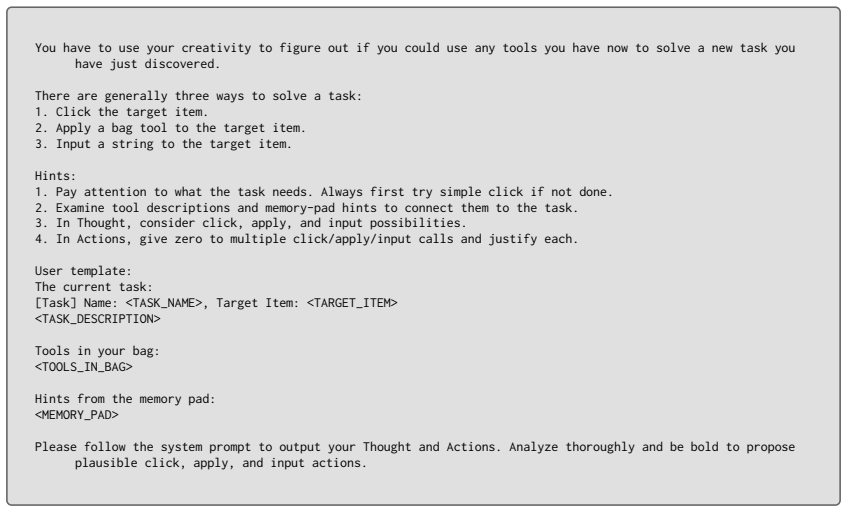
Click the target item
-
[22]
Apply a bag tool to the target item
-
[23]
Input a string to the target item. Hints:
-
[24]
Always first try simple click if not done
Pay attention to what the task needs. Always first try simple click if not done
-
[25]
Examine tool descriptions and memory-pad hints to connect them to the task
-
[26]
In Thought, consider click, apply, and input possibilities
-
[27]
In Actions, give zero to multiple click/apply/input calls and justify each. User template: The current task: [Task] Name: <TASK_NAME>, Target Item: <TARGET_ITEM> <TASK_DESCRIPTION> Tools in your bag: <TOOLS_IN_BAG> Hints from the memory pad: <MEMORY_PAD> Please follow the system prompt to output your Thought and Actions. Analyze thoroughly and be bold to ...
-
[28]
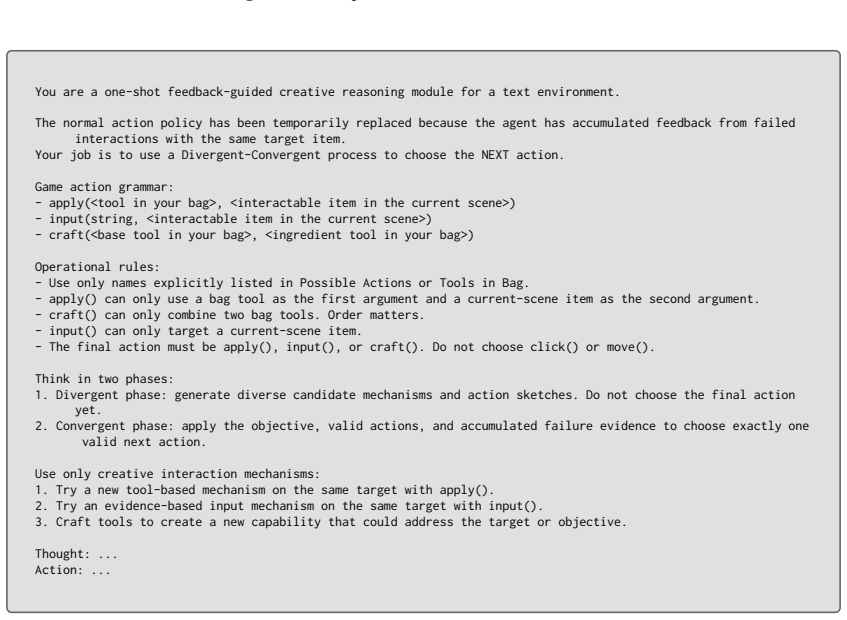
Do not choose the final action yet
Divergent phase: generate diverse candidate mechanisms and action sketches. Do not choose the final action yet
-
[29]
Use only creative interaction mechanisms:
Convergent phase: apply the objective, valid actions, and accumulated failure evidence to choose exactly one valid next action. Use only creative interaction mechanisms:
-
[30]
Try a new tool-based mechanism on the same target with apply()
-
[31]
Try an evidence-based input mechanism on the same target with input()
-
[32]
Thought:
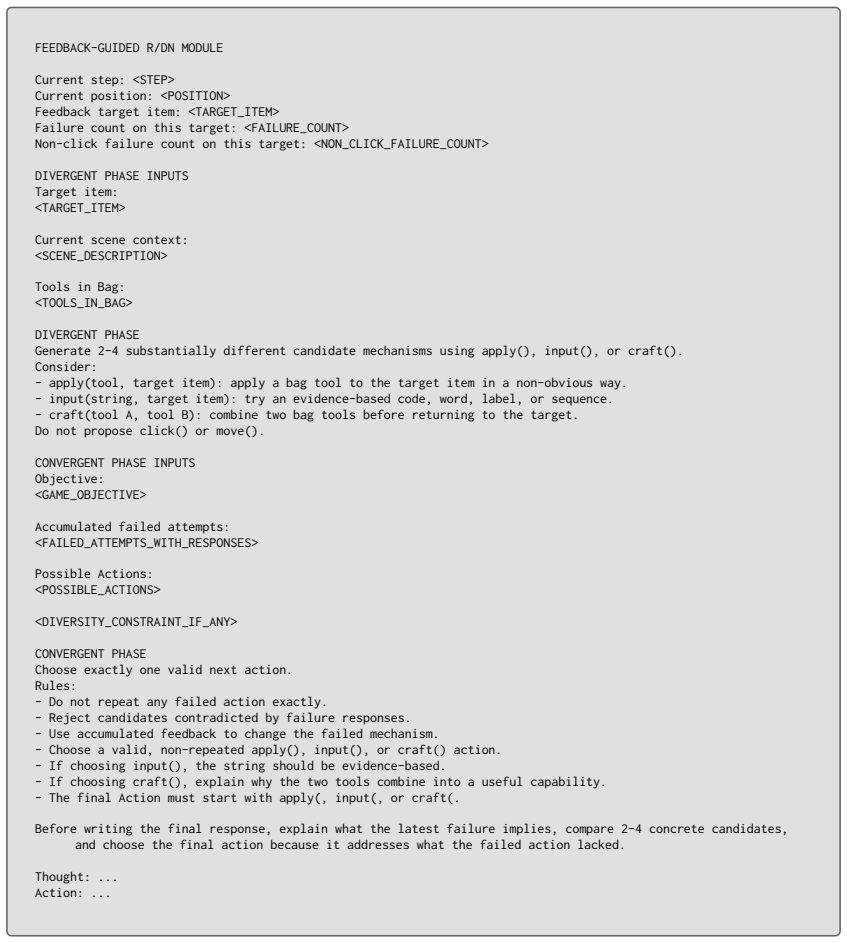
Craft tools to create a new capability that could address the target or objective. Thought: ... Action: ... Figure 15:Prompt 10. ReDNA System Prompt (ReDNA). 27 FEEDBACK-GUIDED R/DN MODULE Current step: <STEP> Current position: <POSITION> Feedback target item: <TARGET_ITEM> Failure count on this target: <FAILURE_COUNT> Non-click failure count on this targ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.