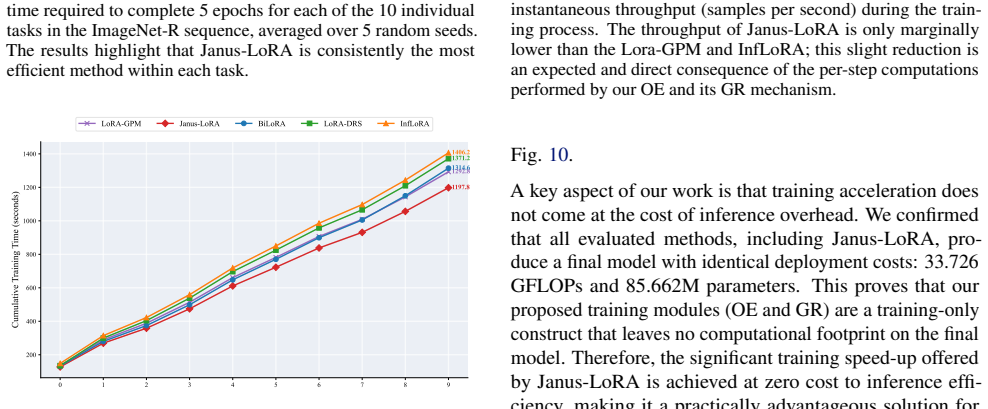
Janus-LoRA: A Balanced Low-Rank Adaptation for Continual Learning
Pith reviewed 2026-06-29 13:43 UTC · model grok-4.3
The pith
Janus-LoRA restores orthogonality in LoRA composite updates and adds feature separation to balance stability and plasticity in continual learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
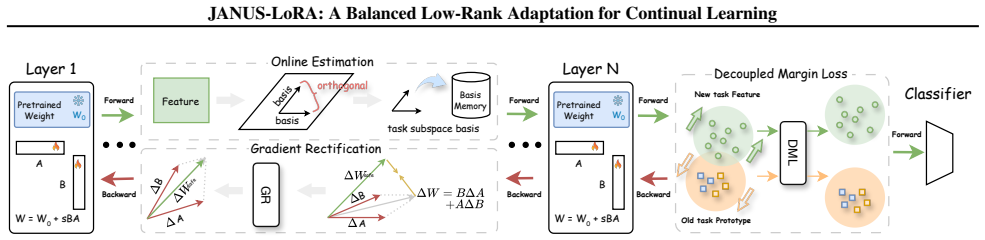
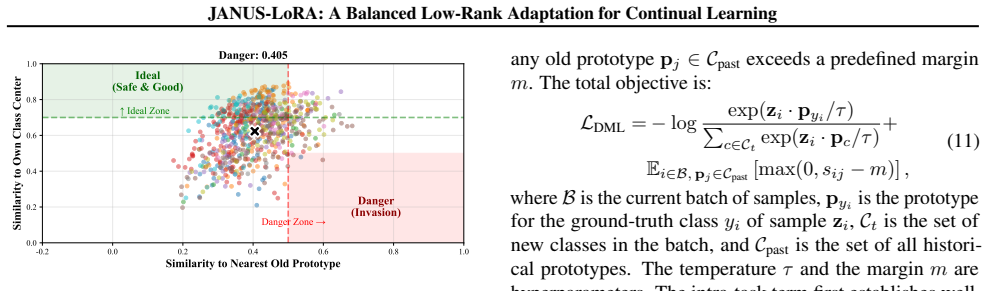
The composite update formed by the product of independently updated low-rank factors A and B in LoRA systematically violates orthogonality to the historical task subspace. Gradient Rectification supplies a closed-form solution that decouples these factor updates to restore orthogonality, identified via Online Estimation of the subspace. The Decoupled Margin Loss then promotes feature-level separation by pushing new representations away from old ones, creating low-interference regions for new learning.
What carries the argument
Gradient Rectification, a closed-form solution that decouples LoRA factor updates to enforce orthogonality against the historical subspace identified by Online Estimation, combined with Decoupled Margin Loss that enforces feature separation.
If this is right
- Enforcing orthogonality at the parameter level stops new updates from overwriting subspaces that store prior knowledge.
- Feature-level separation via the margin loss maintains the capacity to adapt to new tasks without reducing stability.
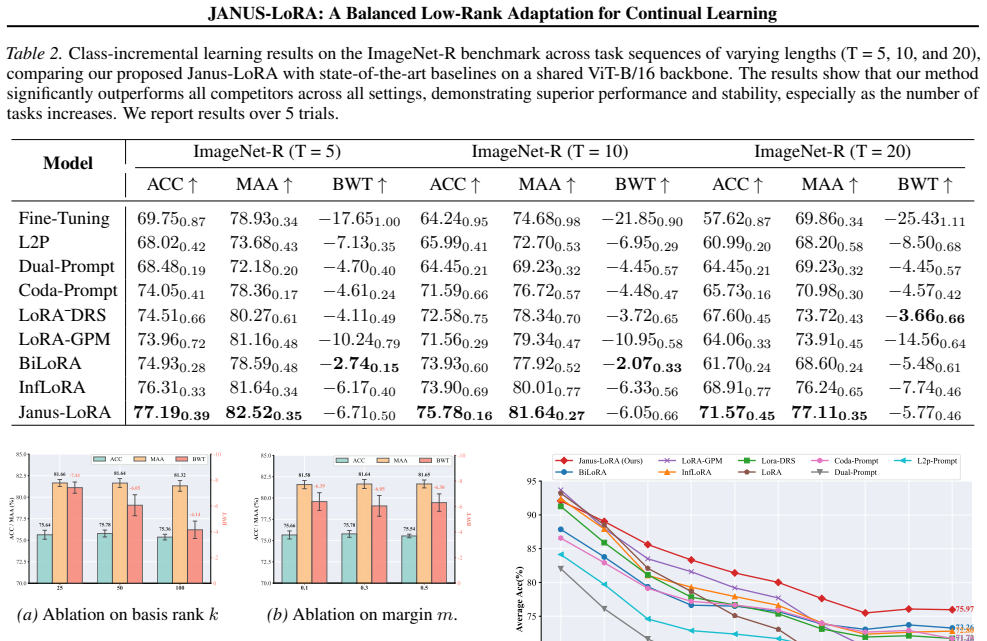
- The paired corrections together produce state-of-the-art results on standard continual learning benchmarks.
- Online Estimation tracks the needed subspace without requiring storage of all past task data.
Where Pith is reading between the lines
- The same closed-form rectification idea could be tested on other low-rank or adapter-based fine-tuning methods beyond the original LoRA formulation.
- If the orthogonality violation is the dominant interference source, analogous corrections might reduce forgetting in full-parameter continual fine-tuning.
- Ablating the margin loss alone would clarify whether the parameter correction or the feature separation drives most of the reported gains.
Load-bearing premise
The composite LoRA update from independently updated A and B factors systematically violates orthogonality to the historical task subspace, and this violation is the primary source of interference.
What would settle it
Direct computation of the inner product between the composite LoRA update vector and the historical subspace vectors, showing it remains zero across tasks, would falsify the claimed systematic violation.
Figures
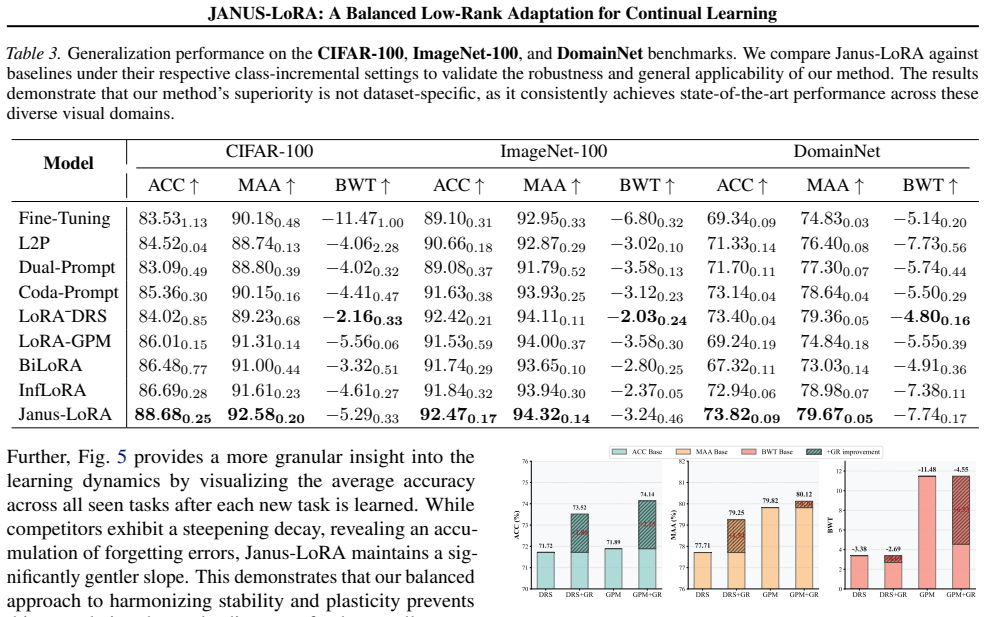
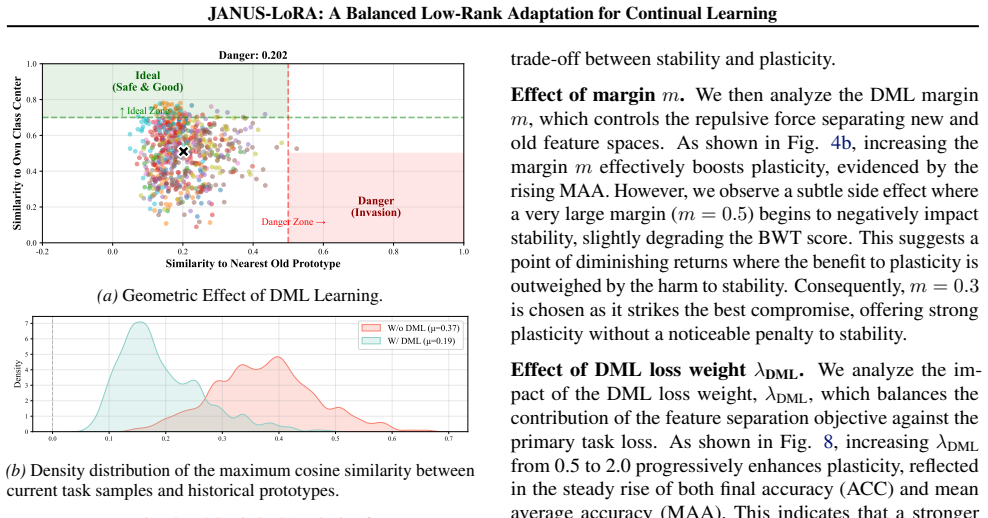
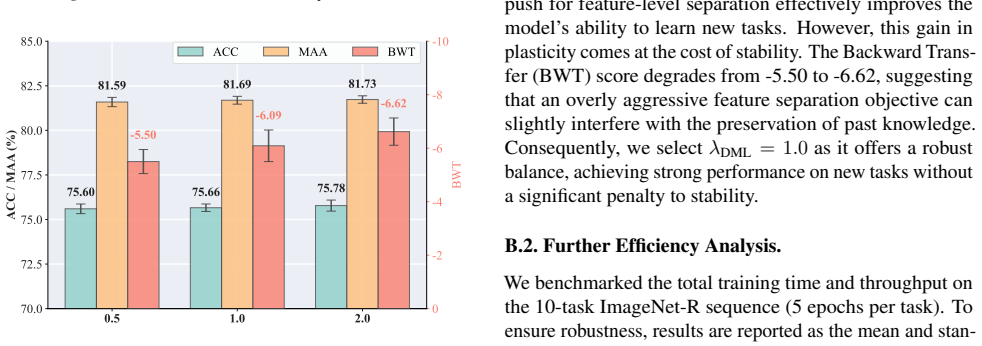
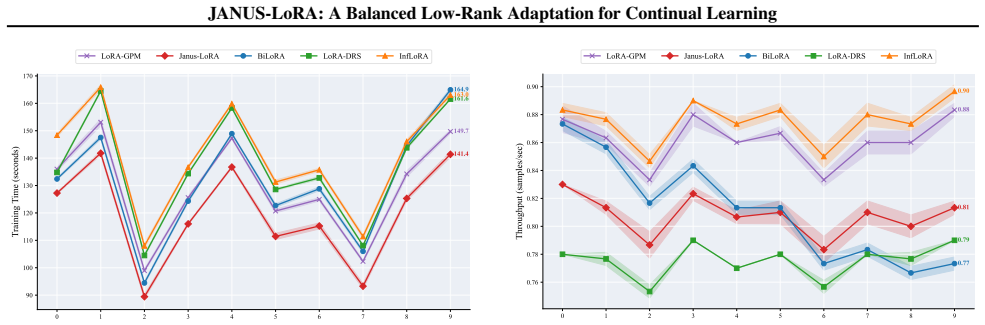
read the original abstract
Low-Rank Adaptation (LoRA) has emerged as a promising paradigm for Continual Learning. It independently updates its low-rank factors ($A$ and $B$), creating a composite update to the full weight matrix through their interaction. To prevent catastrophic forgetting, this update should remain orthogonal to the task-specific subspace that contains previously learned knowledge. However, we identify that this composite update systematically violates this orthogonality, reintroducing interference and undermining stability. Furthermore, naively enforcing this orthogonality compromises plasticity, disrupting the delicate stability-plasticity trade-off. To resolve these issues, we propose \textbf{Janus-LoRA}, a framework that restores this balance through two novel components. Specifically, we first introduce Gradient Rectification, a closed-form solution that mathematically decouples LoRA's factor updates, enforcing orthogonality against the historical knowledge subspace identified by an efficient Online Estimation. Next, to enhance plasticity, we introduce a Decoupled Margin Loss that promotes feature-level separation by pushing new feature representations away from old ones, thus creating distinct, low-interference regions for new learning. Comprehensive experiments on challenging benchmarks demonstrate that by harmonizing parameter-level orthogonality with feature-level separation, Janus-LoRA achieves a superior balance and establishes new state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that independent updates to LoRA factors A and B produce a composite ΔW = BA that systematically violates orthogonality to the historical task subspace (identified via online estimation), reintroducing interference; naive enforcement of orthogonality harms plasticity. Janus-LoRA addresses this via a closed-form Gradient Rectification that decouples the factor updates while preserving the orthogonality condition, paired with a Decoupled Margin Loss that enforces feature-level separation, yielding a superior stability-plasticity balance and new SOTA results on continual-learning benchmarks.
Significance. If the closed-form rectification is mathematically valid, the online estimation is reliable, and the empirical gains prove robust, the work would supply a principled mechanism for enforcing parameter-level orthogonality in LoRA without the usual plasticity penalty, advancing parameter-efficient continual learning.
major comments (3)
- [Abstract] Abstract: the claim that the composite update 'systematically violates' orthogonality to the historical subspace is asserted without any derivation showing why independent A/B updates necessarily produce a non-orthogonal product (as opposed to the violation being an artifact of unconstrained optimization addressable by standard projection).
- [Abstract] Abstract: the 'closed-form solution' for Gradient Rectification is stated to 'mathematically decouple LoRA's factor updates' and enforce orthogonality, yet no equations, steps, or proof are supplied, making it impossible to verify that the rectification is independently derived rather than reducing to a fitted quantity.
- [Abstract] Abstract: the 'efficient Online Estimation' used to identify the historical knowledge subspace is mentioned but receives no description of its procedure, validation, or integration with the rectification, which is load-bearing for the claim that the correction is parameter-free and non-circular.
minor comments (1)
- [Abstract] Abstract: the claim of 'new state-of-the-art performance' is made without naming the benchmarks, number of tasks, metrics, or baselines, and no error bars or statistical details are referenced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below by pointing to the relevant sections of the full manuscript where the requested derivations, equations, and procedures are provided in detail.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the composite update 'systematically violates' orthogonality to the historical subspace is asserted without any derivation showing why independent A/B updates necessarily produce a non-orthogonal product (as opposed to the violation being an artifact of unconstrained optimization addressable by standard projection).
Authors: Section 3.2 of the manuscript provides a full derivation demonstrating that independent updates to the LoRA factors A and B produce a composite ΔW = BA that systematically violates orthogonality to the historical subspace. The analysis proceeds by decomposing the update into its projection onto the subspace and showing that the low-rank factorization introduces a non-zero component that cannot be removed by standard projection without additional rectification. This is distinct from a generic optimization artifact, as illustrated by both theoretical counterexamples and empirical measurements on the benchmarks. revision: no
-
Referee: [Abstract] Abstract: the 'closed-form solution' for Gradient Rectification is stated to 'mathematically decouple LoRA's factor updates' and enforce orthogonality, yet no equations, steps, or proof are supplied, making it impossible to verify that the rectification is independently derived rather than reducing to a fitted quantity.
Authors: The closed-form Gradient Rectification is derived in Section 4.1. Equations (4)–(8) present the complete steps: we formulate the constrained optimization problem that enforces orthogonality on the composite update, solve it analytically for the updates to A and B separately, and obtain an explicit correction term that decouples the factors without introducing fitted parameters or reducing to a heuristic projection. revision: no
-
Referee: [Abstract] Abstract: the 'efficient Online Estimation' used to identify the historical knowledge subspace is mentioned but receives no description of its procedure, validation, or integration with the rectification, which is load-bearing for the claim that the correction is parameter-free and non-circular.
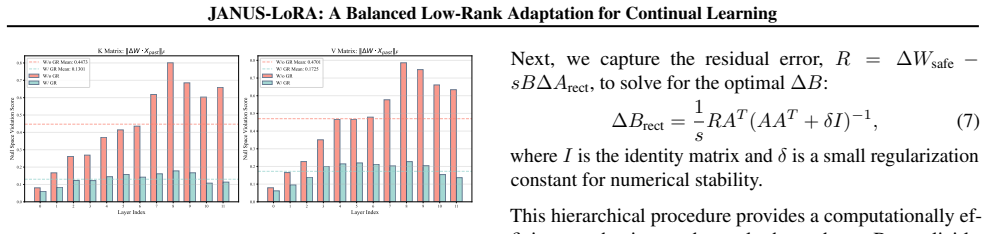
Authors: Section 3.3 describes the Online Estimation procedure in full, including the incremental subspace tracking algorithm, its computational complexity, validation via ablation studies that measure subspace accuracy over task sequences, and the precise manner in which the estimated subspace is supplied to the Gradient Rectification to keep the overall method parameter-free and non-circular. revision: no
Circularity Check
No significant circularity; derivation relies on independent mathematical identification and closed-form correction
full rationale
The provided abstract and outline identify a claimed systematic violation of orthogonality in the composite LoRA update ΔW=BA and introduce a closed-form gradient rectification plus decoupled margin loss. No equations, self-citations, or fitted parameters are shown that reduce the rectification or the orthogonality claim to the inputs by construction. The steps are presented as derived from the problem setup rather than tautological renaming or self-referential fitting, making the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Memory aware synapses: Learn- ing what (not) to forget
Aljundi, R., Babiloni, F., Elhoseiny, M., Rohrbach, M., and Tuytelaars, T. Memory aware synapses: Learn- ing what (not) to forget. In Computer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part III, volume 11207 of Lecture Notes in Computer Science, pp. 144– 161,
2018
-
[2]
and Wagner, A
Ayub, A. and Wagner, A. R. EEC: learning to encode and regenerate images for continual learning. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7,
2021
-
[3]
Emerging properties in self-supervised vision transformers
Caron, M., Touvron, H., Misra, I., J ´egou, H., Mairal, J., Bojanowski, P., and Joulin, A. Emerging properties in self-supervised vision transformers. In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pp. 9630–9640. IEEE,
2021
-
[4]
Class gradient projection for continual learning
Chen, C., Zhang, J., Song, J., and Gao, L. Class gradient projection for continual learning. In MM ’22: The 30th ACM International Conference on Multimedia, Lisboa, Portugal, October 10 - 14, 2022, pp. 5575–5583. ACM,
2022
-
[5]
Coin: A benchmark of continual instruc- tion tuning for multimodel large language models
Chen, C., Zhu, J., Luo, X., Shen, H., Song, J., and Gao, L. Coin: A benchmark of continual instruc- tion tuning for multimodel large language models. In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024,
2024
-
[6]
An image is worth 16x16 words: Transformers for im- age recognition at scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for im- age recognition at scale. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7,
2021
-
[7]
French, R. M. Catastrophic interference in connectionist networks: Can it be predicted, can it be prevented? In Advances in Neural Information Processing Systems 6, [7th NIPS Conference, Denver, Colorado, USA, 1993], pp. 1176–1177. Morgan Kaufmann,
1993
-
[8]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Hendrycks, D., Basart, S., Mu, N., Kadavath, S., Wang, F., Dorundo, E., Desai, R., Zhu, T., Parajuli, S., Guo, M., Song, D., Steinhardt, J., and Gilmer, J. The many faces of robustness: A critical analysis of out-of-distribution generalization. In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 20...
2021
-
[9]
Parameter-efficient transfer learning for NLP
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., de Laroussilhe, Q., Gesmundo, A., Attariyan, M., and Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pp. 279...
2019
-
[10]
J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., and Chen, W
Hu, E. J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29,
2022
-
[11]
J., Hari- haran, B., and Lim, S
Jia, M., Tang, L., Chen, B., Cardie, C., Belongie, S. J., Hari- haran, B., and Lim, S. Visual prompt tuning. InComputer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXXIII, volume 13693 of Lecture Notes in Computer Science, pp. 709–727. Springer,
2022
-
[12]
Supervised contrastive learning
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y ., Isola, P., Maschinot, A., Liu, C., and Krishnan, D. Supervised contrastive learning. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual,
2020
-
[13]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. In Bengio, Y . and LeCun, Y . (eds.), 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings,
2015
-
[14]
C., Lo, W., Doll´ar, P., and Girshick, R
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W., Doll´ar, P., and Girshick, R. B. Segment anything. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pp. 3992–4003. IEEE,
2023
-
[15]
Over- coming catastrophic forgetting by incremental moment matching
Lee, S., Kim, J., Jun, J., Ha, J., and Zhang, B. Over- coming catastrophic forgetting by incremental moment matching. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 4652–4662,
2017
-
[16]
and Li, W
10 JANUS-LoRA: A Balanced Low-Rank Adaptation for Continual Learning Liang, Y . and Li, W. Inflora: Interference-free low-rank adaptation for continual learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, W A, USA, June 16-22, 2024, pp. 23638–23647. IEEE,
2024
-
[17]
and Chang, X
Liu, X. and Chang, X. Lora subtraction for drift- resistant space in exemplar-free continual learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pp. 15308–15318. Computer Vision Foun- dation / IEEE,
2025
-
[18]
Variational Continual Learning
Nguyen, C. V ., Li, Y ., Bui, T. D., and Turner, R. E. Varia- tional continual learning. CoRR, abs/1710.10628,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Moment matching for multi-source domain adaptation
Peng, X., Bai, Q., Xia, X., Huang, Z., Saenko, K., and Wang, B. Moment matching for multi-source domain adaptation. In 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pp. 1406–1415. IEEE,
2019
-
[20]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transfer- able visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 of Pro...
2021
-
[21]
Rebuffi, S., Kolesnikov, A., Sperl, G., and Lampert, C. H. icarl: Incremental classifier and representation learn- ing. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pp. 5533–5542. IEEE Computer Soci- ety,
2017
-
[22]
Rusu, A. A., Rabinowitz, N. C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., and Hadsell, R. Progressive neural networks. CoRR, abs/1606.04671,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Gradient projection memory for continual learning
Saha, G., Garg, I., and Roy, K. Gradient projection memory for continual learning. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7,
2021
-
[24]
S., Karlinsky, L., Gutta, V ., Cascante-Bonilla, P., Kim, D., Arbelle, A., Panda, R., Feris, R., and Kira, Z
Smith, J. S., Karlinsky, L., Gutta, V ., Cascante-Bonilla, P., Kim, D., Arbelle, A., Panda, R., Feris, R., and Kira, Z. Coda-prompt: Continual decomposed attention- based prompting for rehearsal-free continual learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver,BC, Canada, June 17-24, 2023, pp. 11909–11919. IEEE,
2023
-
[25]
M., Rae, J
Sprechmann, P., Jayakumar, S. M., Rae, J. W., Pritzel, A., Badia, A. P., Uria, B., Vinyals, O., Hassabis, D., Pas- canu, R., and Blundell, C. Memory-based parameter adaptation. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net,
2018
-
[26]
Efficient con- tinual learning with modular networks and task-driven priors
Veniat, T., Denoyer, L., and Ranzato, M. Efficient con- tinual learning with modular networks and task-driven priors. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7,
2021
-
[27]
G., and Pfister, T
Wang, Z., Zhang, Z., Ebrahimi, S., Sun, R., Zhang, H., Lee, C., Ren, X., Su, G., Perot, V ., Dy, J. G., and Pfister, T. Du- alprompt: Complementary prompting for rehearsal-free continual learning. In Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXVI, volume 13686 of Lecture Notes in Compu...
2022
-
[28]
Continual learning through synaptic intelligence
Zenke, F., Poole, B., and Ganguli, S. Continual learning through synaptic intelligence. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, vol- ume 70 of Proceedings of Machine Learning Research, pp. 3987–3995. PMLR,
2017
-
[29]
Bilora: Almost-orthogonal parameter spaces for continual learn- ing
Zhu, H., Zhang, Y ., Dong, J., and Koniusz, P. Bilora: Almost-orthogonal parameter spaces for continual learn- ing. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pp. 25613–25622. Computer Vision Foundation / IEEE,
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.