GS-FUSE: Granger-Supervised Gated Fusion and Multi-Granularity Alignment for Event-Driven Financial Forecasting
Pith reviewed 2026-06-29 12:28 UTC · model grok-4.3
The pith
A gated fusion module supervised by Granger causality decides when event text adds value beyond price history for market forecasts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
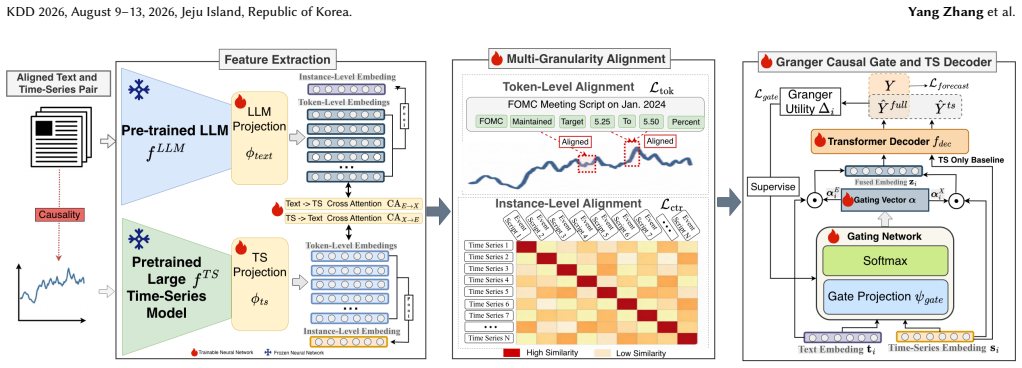
GS-Fuse employs a Granger-supervised, causal-aware gated fusion module, which learns to open toward event text only when it provides incremental predictive value beyond historical prices, and a multi-granularity alignment mechanism that jointly aligns high-level event representations and fine-grained textual cues with future market trajectories. Built as a flexible, plug-and-play adapter on top of off-the-shelf large language models and time-series foundation models, GS-Fuse can be instantiated across diverse backbones and market settings.
What carries the argument
The Granger-supervised gated fusion module that learns a gate to include textual signals only on evidence of added predictive value over prices alone.
If this is right
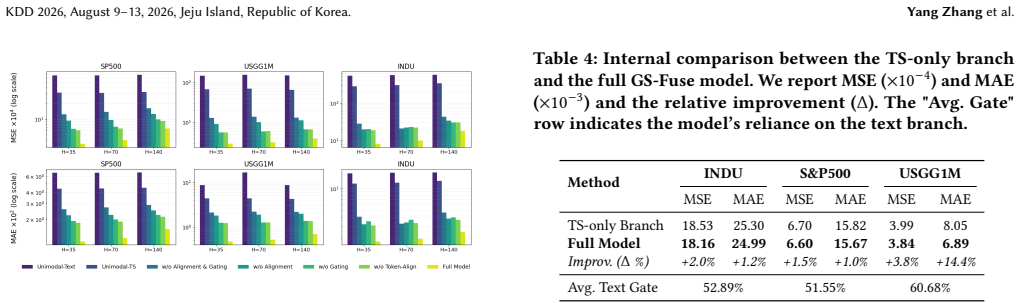
- Forecasting performance improves across multiple assets and prediction horizons when the gate correctly filters non-informative text.
- The same adapter structure can be attached to different language and time-series backbones without full retraining.
- Joint alignment of coarse event semantics and fine text tokens with price trajectories sharpens directional predictions.
- Explicit causality supervision reduces indiscriminate use of noisy event data in multimodal settings.
Where Pith is reading between the lines
- The same selective-fusion idea could apply to other paired modalities where one is expected to cause changes in the other, such as regulatory announcements and firm metrics.
- If the gate generalizes, it offers a route to reduce overfitting in multimodal financial models by tying fusion decisions to a testable statistical criterion.
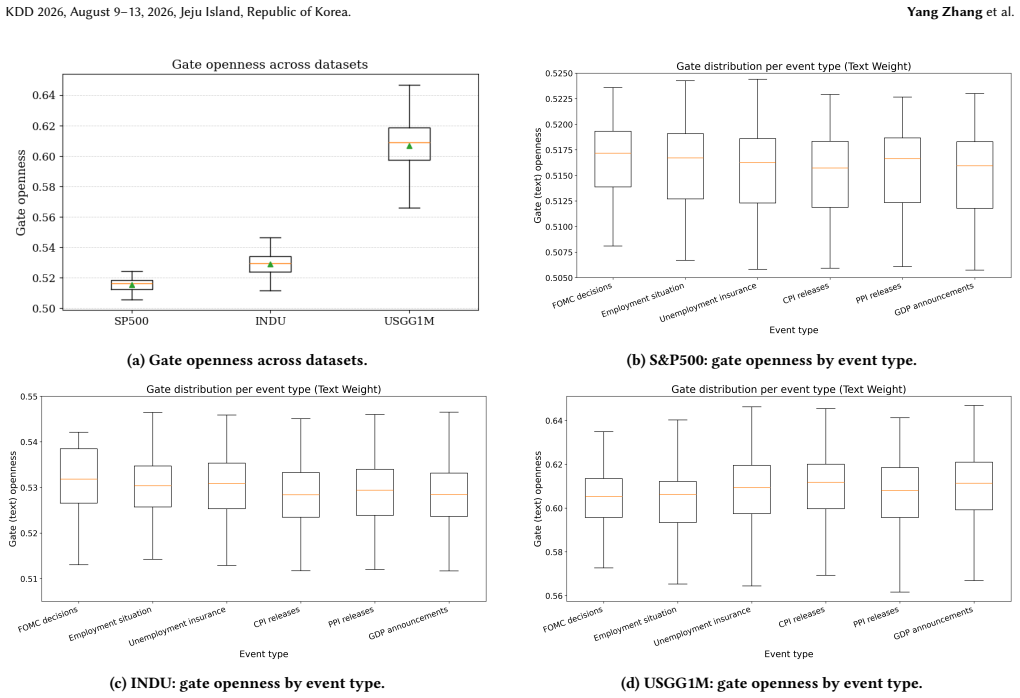
- Live deployment would require checking whether the learned gate remains stable when market regimes shift after the training window.
Load-bearing premise
The gate can be trained to open exactly when text supplies new predictive information without the supervision process itself creating selection bias or inflated performance.
What would settle it
Run the model on a dataset of events already known to carry no incremental signal over prices and check whether accuracy falls back to the level of a price-only baseline.
Figures
read the original abstract
Accurately forecasting the impact of salient financial events on markets is critical for investors and policymakers. However, existing multimodal time-series models typically fuse text and prices symmetrically, without an explicit way to decide when event text is truly predictive, and thus struggle to exploit the directional event-to-price structure and the heterogeneous roles of textual and price signals. In this work, we propose GS-Fuse, a multimodal event-based forecasting framework that employs (i) a Granger-supervised, causal-aware gated fusion module, which learns to open toward event text only when it provides incremental predictive value beyond historical prices, and (ii) a multi-granularity alignment mechanism that jointly aligns high-level event representations and fine-grained textual cues with future market trajectories. Built as a flexible, plug-and-play adapter on top of off-the-shelf large language models and time-series foundation models, GS-Fuse can be instantiated across diverse backbones and market settings. Extensive experiments on real-world financial datasets show that GS-Fuse consistently outperforms state-of-the-art time-series and multimodal baselines across multiple assets and forecasting horizons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GS-Fuse, a multimodal event-based forecasting framework consisting of (i) a Granger-supervised gated fusion module that learns to incorporate event text only when it supplies incremental predictive value beyond historical prices and (ii) a multi-granularity alignment mechanism that aligns high-level event representations and fine-grained textual cues with future market trajectories. The method is presented as a plug-and-play adapter on off-the-shelf LLMs and time-series foundation models, with the central claim that it consistently outperforms state-of-the-art time-series and multimodal baselines across multiple assets and forecasting horizons on real-world financial datasets.
Significance. If the outperformance claims hold after ensuring the Granger supervision signal is computed without lookahead bias, the work could advance causal-aware multimodal fusion in financial time series by providing an explicit mechanism to handle heterogeneous text and price signals, with potential practical value for event-driven forecasting.
major comments (2)
- [§3.2] §3.2 (Granger-supervised gated fusion module): the description does not specify that Granger causality tests are confined exclusively to training-fold data available at each forecast origin. If tests are instead performed on the full series or validation/test windows, the supervision supplies an oracle signal unavailable at deployment time, directly explaining any reported gains since all performance improvements trace to the gate decisions.
- [§4] §4 (Experiments): the manuscript asserts consistent outperformance on real-world datasets but supplies no experimental protocol, baseline definitions, statistical tests, ablation results, or details on how the gated fusion is trained and evaluated, rendering the central claim unevaluable from the provided text.
minor comments (1)
- The multi-granularity alignment mechanism would benefit from explicit equations defining the alignment losses at each granularity level.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which help strengthen the clarity and rigor of the work. We address each point below and will revise the manuscript to incorporate the requested clarifications and details.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Granger-supervised gated fusion module): the description does not specify that Granger causality tests are confined exclusively to training-fold data available at each forecast origin. If tests are instead performed on the full series or validation/test windows, the supervision supplies an oracle signal unavailable at deployment time, directly explaining any reported gains since all performance improvements trace to the gate decisions.
Authors: We agree that the description in §3.2 must explicitly state that Granger causality tests are performed exclusively on the training-fold data available at each forecast origin. The module is designed to use only information observable at the forecast time to determine incremental predictive value. We will add this specification, including pseudocode or a formal statement confirming the temporal split, to eliminate any ambiguity regarding lookahead. revision: yes
-
Referee: [§4] §4 (Experiments): the manuscript asserts consistent outperformance on real-world datasets but supplies no experimental protocol, baseline definitions, statistical tests, ablation results, or details on how the gated fusion is trained and evaluated, rendering the central claim unevaluable from the provided text.
Authors: We acknowledge that the experimental section requires substantially more detail to allow evaluation and reproduction. The full manuscript contains dataset descriptions, but we will expand §4 to include the complete protocol (train/validation/test splits, forecast origins, and rolling-window evaluation), precise baseline implementations and hyperparameters, statistical tests (e.g., Diebold-Mariano), ablation results isolating the gated fusion and alignment components, and training details for the gate (loss, optimizer, and how supervision is applied). revision: yes
Circularity Check
No circularity: model architecture and supervision are independent of evaluation targets
full rationale
The paper introduces a gated fusion module supervised by Granger causality tests and a multi-granularity alignment loss. No equations or sections reduce the reported forecasting performance to a fitted parameter or self-citation by construction. The Granger supervision is described as a training-time mechanism to learn when text adds value; without explicit quotes showing that the causality statistics are computed on full-series data (including test windows) or that the gate output is algebraically identical to the target metric, the performance numbers remain an empirical claim rather than a definitional tautology. Self-citations, if present, are not load-bearing for the central result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- gated fusion parameters
- multi-granularity alignment parameters
axioms (1)
- domain assumption Granger causality can be used to supervise a neural gate so that it opens only on incremental predictive value
Reference graph
Works this paper leans on
-
[1]
Maddix, Hao Wang, Michael W
Abdul Fatir Ansari, Lorenzo Stella, Ali Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebas- tian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Hao Wang, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Bernie Wang. 2024. Chronos: Learning t...
2024
-
[2]
Ariyo, Adewumi O
Adebiyi A. Ariyo, Adewumi O. Adewumi, and Charles K. Ayo. [n. d.]. Stock Price Prediction Using the ARIMA Model. InUKSim-AMSS 2014
2014
-
[3]
Wuzhida Bao, Yuting Cao, Yin Yang, Hangjun Che, Junjian Huang, and Shiping Wen. 2025. Data-driven stock forecasting models based on neural networks: A review.Information Fusion113 (2025), 102616
2025
-
[4]
Dinesh Bhuriya, Girish Kaushal, Ashish Sharma, and Upendra Singh. 2017. Stock market predication using a linear regression. InICECA 2017
2017
-
[5]
Bing Cao, Yiming Sun, Pengfei Zhu, and Qinghua Hu. 2023. Multi-Modal Gated Mixture of Local-to-Global Experts for Dynamic Image Fusion. InICCV
2023
-
[6]
C. Q. Cao and R. S. Tsay. 1992. Nonlinear time-series analysis of stock volatilities. J. Appl. Econom.7, S1 (1992), 165–185
1992
-
[7]
Defu Cao, Furong Jia, Sercan O Arik, Tomas Pfister, Yixiang Zheng, Wen Ye, and Yan Liu. 2024. TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting. InThe Twelfth International Conference on Learning Representations
2024
-
[8]
Ching Chang, Wei-Yao Wang, Wen-Chih Peng, and Tien-Fu Chen. 2025. LLM4TS: Aligning Pre-Trained LLMs as Data-Efficient Time-Series Forecasters.ACM Trans. Intell. Syst. Technol.16, 3 (2025). doi:10.1145/3719207
-
[9]
Minghao Chen, Houwen Peng, Jianlong Fu, and Haibin Ling. 2021. AutoFormer: Searching Transformers for Visual Recognition. InICCV 2021
2021
-
[10]
Yuxiao Cheng, Lianglong Li, Tingxiong Xiao, Zongren Li, Jinli Suo, Kunlun He, and Qionghai Dai. 2024. CUTS+: High-Dimensional Causal Discovery from Irregular Time-Series.AAAi(2024)
2024
-
[11]
ANNA CIESLAK, ADAIR MORSE, and ANNETTE VISSING-JORGENSEN. 2019. Stock Returns over the FOMC Cycle.J. Finance74, 5 (2019), 2201–2248
2019
-
[12]
Zizhen Deng, Hu Tian, Xiaolong Zheng, and Daniel Dajun Zeng. 2025. Deep Causal Learning: Representation, Discovery and Inference.ACM Comput. Surv. 58, 2 (2025)
2025
-
[13]
Zihan Dong, Xinyu Fan, and Zhiyuan Peng. 2024. FNSPID: A Comprehensive Financial News Dataset in Time Series. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. doi:10.1145/3637528.3671629
-
[14]
Dr. M. Durairaj and B. H. Krishna Mohan. 2022. A convolutional neural network based approach to financial time series prediction.Neural Comput. Appl.34, 16 (2022), 13319–13337
2022
-
[15]
Eugene F. Fama. 1965. The Behavior of Stock-Market Prices.J. Bus.38, 1 (1965), 34–105
1965
-
[16]
Fama, Lawrence Fisher, Michael C
Eugene F. Fama, Lawrence Fisher, Michael C. Jensen, and Richard Roll. 1969. The Adjustment of Stock Prices to New Information.Int. Econ. Rev.10, 1 (1969), 1–21
1969
-
[17]
Bianca-Mihaela Ganescu, Suchir Salhan, Andrew Caines, and Paula Buttery
-
[18]
InBabyLM
Looking to Learn: Token-wise Dynamic Gating for Low-Resource Vision- Language Modelling. InBabyLM
-
[19]
Pavel Gertler and Roman Horvath. 2018. Central bank communication and financial markets: New high-frequency evidence.J. Financ. Stab.36 (2018), 336– 345
2018
-
[20]
T Gilbert, C Scotti, G Strasser, and C Vega. 2010. Why do certain macroeconomic news announcements have a big impact on asset prices? InAppl. Econom. Forecast. Macro. Finance Workshop
2010
-
[21]
2013.Time variation in asset price responses to macro announcements
Linda Goldberg and Christian Grisse. 2013.Time variation in asset price responses to macro announcements. Working Papers 2013-11. Swiss National Bank
2013
-
[22]
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. 2024. MOMENT: A Family of Open Time-series Foundation Models. InICML 2024
2024
-
[23]
C.W.J. Granger. 1980. Testing for causality: A personal viewpoint.Journal of Economic Dynamics and Control2 (1980), 329–352
1980
-
[24]
Huynh, L
Huy D. Huynh, L. Minh Dang, and Duc Duong. 2017. A New Model for Stock Price Movements Prediction Using Deep Neural Network. InSoICT 2017
2017
-
[25]
Tae Hyup Roh. 2007. Forecasting the volatility of stock price index.Expert Syst. Appl.33, 4 (2007), 916–922
2007
-
[26]
Furong Jia, Kevin Wang, Yixiang Zheng, Defu Cao, and Yan Liu. 2024. GPT4MTS: Prompt-based Large Language Model for Multimodal Time-series Forecasting. AAAI 2024(2024)
2024
-
[27]
Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y. Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen. 2024. Time-LLM: Time Series Forecasting by Reprogramming Large Language Models. InThe Twelfth International Conference on Learning Representations
2024
-
[28]
Baoyu Jing, Dawei Zhou, Kan Ren, and Carl Yang. 2024. Causality-Aware Spa- tiotemporal Graph Neural Networks for Spatiotemporal Time Series Imputation. InCIKM
2024
-
[29]
Saurabh Khanna and Vincent Y. F. Tan. 2020. Economy Statistical Recurrent Units For Inferring Nonlinear Granger Causality. InICLR
2020
-
[30]
Geon Lee, Wenchao Yu, Wei Cheng, and Haifeng Chen. 2024. MoAT: Multi-Modal Augmented Time Series Forecasting. OpenReview
2024
-
[31]
Qing Li, TieJun Wang, Ping Li, Ling Liu, Qixu Gong, and Yuanzhu Chen. 2014. The effect of news and public mood on stock movements.Information Sciences 278 (2014), 826–840
2014
- [32]
-
[33]
Chenxi Liu, Qianxiong Xu, Hao Miao, Sun Yang, Lingzheng Zhang, Cheng Long, Ziyue Li, and Rui Zhao. 2025. TimeCMA: Towards LLM-Empowered Multivariate Time Series Forecasting via Cross-Modality Alignment.Proceedings of the AAAI Conference on Artificial Intelligence39, 18 (Apr. 2025), 18780–18788. doi:10.1609/ aaai.v39i18.34067
2025
-
[34]
Huicheng Liu. 2018. Leveraging Financial News for Stock Trend Prediction with Attention-Based Recurrent Neural Network.arXiv(2018)
2018
-
[35]
Yong Liu, Guo Qin, Xiangdong Huang, Jianmin Wang, and Mingsheng Long
-
[36]
InAdvances in Neural Information Processing Systems, A
AutoTimes: Autoregressive Time Series Forecasters via Large Language Models. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. 122154–122184. doi:10.52202/079017-3882
-
[37]
Yong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. 2024. Timer: Generative Pre-trained Transformers Are Large Time Series Models. InICML 2024
2024
-
[38]
Zehao Liu, Mengzhou Gao, and Pengfei Jiao. 2025. GCAD: Anomaly Detection in Multivariate Time Series from the Perspective of Granger Causality.AAAI (2025)
2025
-
[39]
LUCCA and EMANUEL MOENCH
DAVID O. LUCCA and EMANUEL MOENCH. 2015. The Pre-FOMC Announce- ment Drift.J. Finance70, 1 (2015), 329–371
2015
-
[40]
Donato Masciandaro, Oana Peia, and Davide Romelli. 2024. Central bank com- munication and social media: From silence to Twitter.J. Econ. Surv.38, 2 (2024), 365–388
2024
-
[41]
Puneet Mathur, Atula Neerkaje, Malika Chhibber, Ramit Sawhney, Fuming Guo, Franck Dernoncourt, Sanghamitra Dutta, and Dinesh Manocha. 2022. MONOP- OLY: Financial Prediction from MONetary POLicY Conference Videos Using KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Yang Zhanget al. Multimodal Cues. InMM 2022
2022
-
[42]
Thien Hai Nguyen, Kiyoaki Shirai, and Julien Velcin. 2015. Sentiment analysis on social media for stock movement prediction.Expert Syst. Appl.42, 24 (2015), 9603–9611
2015
-
[43]
Kun Ouyang, Yi Liu, Shicheng Li, Ruihan Bao, Keiko Harimoto, and Xu Sun. 2024. Modal-adaptive Knowledge-enhanced Graph-based Financial Prediction from Monetary Policy Conference Calls with LLM. InFinNLP-KDF-ECONLP 2024
2024
-
[44]
González
John Edison Arevalo Ovalle, Thamar Solorio, Manuel Montes-y-Gómez, and Fabio A. González. 2017. Gated Multimodal Units for Information Fusion. InICLR Workshop
2017
-
[45]
Zijie Pan, Yushan Jiang, Sahil Garg, Anderson Schneider, Yuriy Nevmyvaka, and Dongjin Song. 2024. $S^2$IP-LLM: Semantic Space Informed Prompt Learning with LLM for Time Series Forecasting. InICML
2024
-
[46]
Pui Cheong Fung, J
G. Pui Cheong Fung, J. Xu Yu, and Wai Lam. 2003. Stock prediction: Integrating text mining approach using real-time news. InCIFEr. 395–402
2003
-
[47]
Yu Qin and Yi Yang. 2019. What You Say and How You Say It Matters: Predicting Stock Volatility Using Verbal and Vocal Cues. InACL 2019
2019
-
[48]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InICML
2021
-
[49]
Carlo Rosa. 2011. Words that shake traders: The stock market’s reaction to central bank communication in real time.J. Empir. Finance18, 5 (2011), 915–934
2011
-
[50]
Carlo Rosa. 2013. The financial market effect of FOMC minutes.Econ. Policy Rev. (2013), 67–81
2013
-
[51]
Carlo Rosa. 2016. Fedspeak: Who Moves U.S. Asset Prices?Int. J. Cent. Bank.12, 4 (2016), 223–261
2016
-
[52]
Ramit Sawhney, Shivam Agarwal, Arnav Wadhwa, and Rajiv Ratn Shah. 2020. Deep Attentive Learning for Stock Movement Prediction From Social Media Text and Company Correlations. InEMNLP 2020
2020
-
[53]
Ramit Sawhney, Puneet Mathur, Ayush Mangal, Piyush Khanna, Rajiv Ratn Shah, and Roger Zimmermann. 2020. Multimodal Multi-Task Financial Risk Forecasting. InMM 2020
2020
-
[54]
A Gopalakrishnan, Vijay Krishna Menon, and K
Sreelekshmy Selvin, R Vinayakumar, E. A Gopalakrishnan, Vijay Krishna Menon, and K. P. Soman. 2017. Stock price prediction using LSTM, RNN and CNN-sliding window model. InICACCI 2017
2017
-
[55]
Agam Shah, Suvan Paturi, and Sudheer Chava. 2023. Trillion Dollar Words: A New Financial Dataset, Task & Market Analysis. InACL 2023
2023
-
[56]
Yu Shi, Zongliang Fu, Shuo Chen, Bohan Zhao, Wei Xu, Changshui Zhang, and Jian Li. 2025. Kronos: A Foundation Model for the Language of Financial Markets. InRecent Advances in Time Series Foundation Models Have We Reached the ’BERT Moment’?
2025
-
[57]
Jianfeng Si, Arjun Mukherjee, Bing Liu, Qing Li, Huayi Li, and Xiaotie Deng
-
[58]
InACL 2013
Exploiting Topic based Twitter Sentiment for Stock Prediction. InACL 2013
2013
-
[59]
Raul Cruz Tadle. 2022. FOMC minutes sentiments and their impact on financial markets.J. Econ. Bus.118 (2022), 106021
2022
-
[60]
Sabera J Talukder, Yisong Yue, and Georgia Gkioxari. 2024. TOTEM: TOkenized Time Series EMbeddings for General Time Series Analysis.TMLR(2024)
2024
-
[61]
2007.Modelling Financial Time Series
Stephen J Taylor. 2007.Modelling Financial Time Series. World Scientific Publish- ing
2007
-
[62]
Qianqian Xie, Weiguang Han, Yanzhao Lai, Min Peng, and Jimin Huang. 2023. The Wall Street Neophyte: A Zero-Shot Analysis of ChatGPT Over MultiModal Stock Movement Prediction Challenges
2023
-
[63]
Yumo Xu and Shay B. Cohen. 2018. Stock Movement Prediction from Tweets and Historical Prices. InACL 2018
2018
-
[64]
Linyi Yang, Tin Lok James Ng, Barry Smyth, and Riuhai Dong. 2020. HTML: Hierarchical Transformer-based Multi-task Learning for Volatility Prediction. In WWW 2020
2020
-
[65]
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. 2022. FILIP: Fine-grained In- teractive Language-Image Pre-Training. InInternational Conference on Learning Representations
2022
-
[66]
Xinli Yu, Zheng Chen, and Yanbin Lu. 2023. Harnessing LLMs for Temporal Data - A Study on Explainable Financial Time Series Forecasting. InEMNLP
2023
-
[67]
Yang Zhang, Wenbo Yang, Jun Wang, Qiang Ma, and Jie Xiong. 2025. CAMEF: Causal-Augmented Multi-Modality Event-Driven Financial Forecasting by Inte- grating Time Series Patterns and Salient Macroeconomic Announcements. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (KDD ’25). 3867–3878. doi:10.1145/3711896.3736872
-
[68]
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. InAAAI 2021
2021
-
[69]
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. 2022. FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting. InICML 2022
2022
-
[70]
Wenzhang Zhou, Dawei Du, Libo Zhang, Tiejian Luo, and Yanjun Wu. 2022. Multi- Granularity Alignment Domain Adaptation for Object Detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 9581–9590
2022
-
[71]
Zhihan Zhou, Liqian Ma, and Han Liu. 2021. Trade the Event: Corporate Events Detection for News-Based Event-Driven Trading. InACL Findings
2021
-
[72]
Shihao Zou, Xianying Huang, and Xudong Shen. 2023. Multimodal Prompt Transformer with Hybrid Contrastive Learning for Emotion Recognition in Conversation. InMM. A Implementation Details for Baselines and GS-Fuse Single-modality baselines (ARIMA, DLinear, Autoformer, FEDformer, iTransformer, PatchTST) are adapted from Time-Series-Library5 to the event-driv...
2023
-
[73]
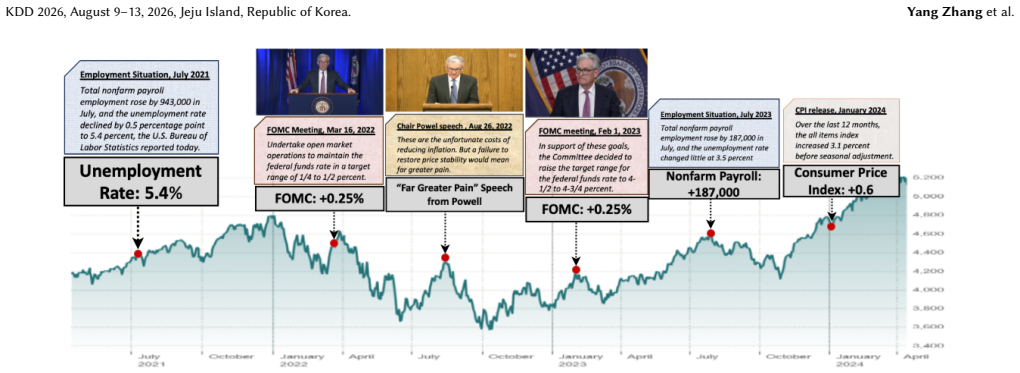
federal funds rate target range
We adapt their official implementations to the same event-driven forecasting horizons (35, 70, and 140 steps) and keep their default hyperparameters. For time-series foundation models, including MOMENT, Kronos, TimesFM, and Chronos, we use the official repositories9 and retrain them on our event-driven setup for 10 epochs with batch size 32. ForGS-Fuse, w...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.