Search for Coverage: Learning Coverage-Aware Retrieval with Augmented Sub-Question Answerability
Pith reviewed 2026-06-29 09:45 UTC · model grok-4.3
The pith
CoveR is a bi-encoder trained on synthetic coverage signals from LLM sub-question judgments that raises nugget coverage by 10% over dense baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
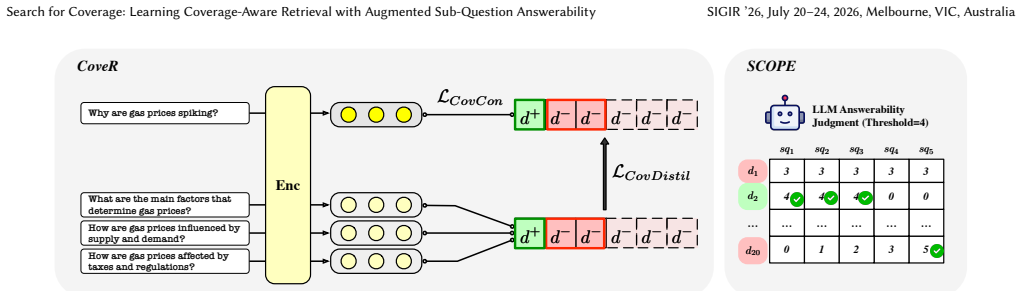
CoveR is a bi-encoder trained with the coverage-based contrastive and distillation objectives on the SCOPE dataset, which comprises 90K training pairs from Researchy Questions with synthetic coverage signals augmented from sub-question answerability judgments generated by LLMs. This training enables CoveR to capture diverse aspects of information needs, and empirical experiments show that CoveR enhances nugget coverage by 10% over strong dense retrieval baselines without sacrificing its relevance-based retrieval capability.
What carries the argument
Coverage-based contrastive and distillation objectives in a bi-encoder that use synthetic coverage signals from LLM sub-question answerability judgments.
If this is right
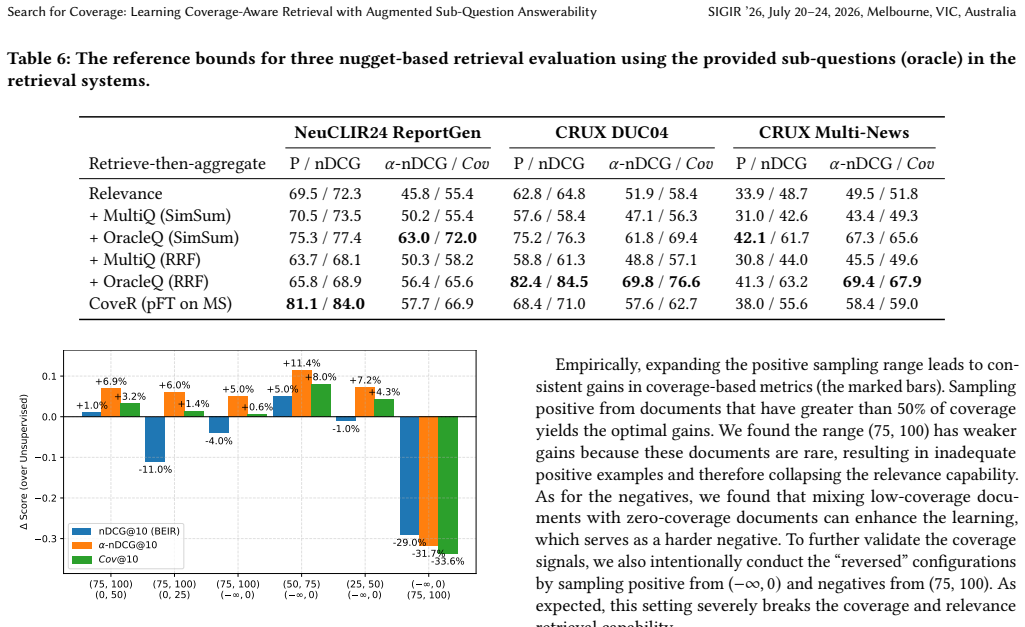
- Nugget coverage rises by 10% relative to strong dense retrieval baselines.
- Relevance-based ranking performance stays intact.
- The model produces a better relevance-coverage trade-off than prior dense retrievers.
- Ablation studies confirm that both the contrastive and distillation objectives contribute to the observed gains.
Where Pith is reading between the lines
- The same synthetic labeling approach could be reused for other retrieval settings where explicit coverage annotations are expensive to collect.
- Downstream RAG pipelines that rely on this retriever may produce fewer incomplete answers because more nuggets reach the generator.
- The method could be tested by swapping the LLM labeler for a smaller model or for human sub-question judgments to measure sensitivity to label quality.
Load-bearing premise
LLM-generated sub-question answerability judgments supply reliable synthetic coverage signals that match human notions of comprehensive retrieval.
What would settle it
A side-by-side human evaluation of retrieved sets in which the correlation between the LLM-derived coverage labels and human judgments of fact completeness falls below a statistically significant threshold.
Figures




read the original abstract
Long-form Retrieval-Augmented Generation (RAG) brings the challenge of coverage-based ranking, because ranking methods must ensure the inclusion of comprehensive relevant nuggets (i.e., facts), which can thereby be synthesized into a comprehensive output. In this work, we propose CoveR (Our code is available at https://github.com/DylanJoo/CoveR ) a dense retrieval method optimized for coverage-aware retrieval scenarios. CoveR is a bi-encoder trained with the coverage-based contrastive and distillation objectives, which enables CoveR to capture diverse aspects of information needs. To train CoveR, we create the SCOPE dataset, (Our training data is available at https://huggingface.co/datasets/DylanJHJ/scope ) which comprises 90K training pairs from Researchy Questions with synthetic coverage signals augmented from sub-question answerability judgments generated by LLMs. Our empirical experiments show that CoveR enhances nugget coverage by 10\% over strong dense retrieval baselines without sacrificing its relevance-based retrieval capability. Further ablation studies validate the importance of our proposed learning method, showing that CoveR achieves a superior trade-off between relevance- and coverage-based ranking, which is essential for long-form RAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoveR, a bi-encoder dense retriever trained via coverage-aware contrastive and distillation objectives to improve nugget coverage for long-form RAG. It introduces the SCOPE dataset (90K pairs derived from Researchy Questions) whose coverage signals are generated synthetically via LLM judgments of sub-question answerability. The central empirical claim is a 10% lift in nugget coverage over strong dense baselines while preserving relevance-based ranking performance; code and training data are released.
Significance. If the LLM-derived coverage signals prove to be reliable proxies, the work supplies a practical training recipe for coverage-aware retrieval, an under-addressed requirement in comprehensive RAG pipelines. The public release of both the model code and the SCOPE dataset constitutes a concrete reproducibility asset that strengthens the contribution.
major comments (2)
- [Abstract] Abstract (dataset construction paragraph): the 10% coverage gain is obtained on labels produced solely by LLM sub-question answerability judgments. No human validation, inter-annotator agreement, or correlation study with human notions of nugget coverage is reported; because the central claim rests on these synthetic signals being faithful proxies, the absence of such validation is load-bearing.
- [Empirical experiments] Empirical experiments (results section): the abstract states a 10% coverage improvement but supplies neither error bars, statistical significance tests, nor visible ablation tables or dataset statistics. Without these, the claim that CoveR achieves a superior relevance-coverage trade-off cannot be verified from the reported evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validation of synthetic signals and the reporting of experimental results. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (dataset construction paragraph): the 10% coverage gain is obtained on labels produced solely by LLM sub-question answerability judgments. No human validation, inter-annotator agreement, or correlation study with human notions of nugget coverage is reported; because the central claim rests on these synthetic signals being faithful proxies, the absence of such validation is load-bearing.
Authors: We agree that the absence of human validation for the LLM-generated coverage signals is a limitation, as these signals underpin the reported gains. Our experiments demonstrate consistent improvements when training and evaluating against the same synthetic labels, and we release the full SCOPE dataset to support future human correlation studies. We will add an explicit discussion of this limitation in the revised Limitations section. revision: partial
-
Referee: [Empirical experiments] Empirical experiments (results section): the abstract states a 10% coverage improvement but supplies neither error bars, statistical significance tests, nor visible ablation tables or dataset statistics. Without these, the claim that CoveR achieves a superior relevance-coverage trade-off cannot be verified from the reported evidence.
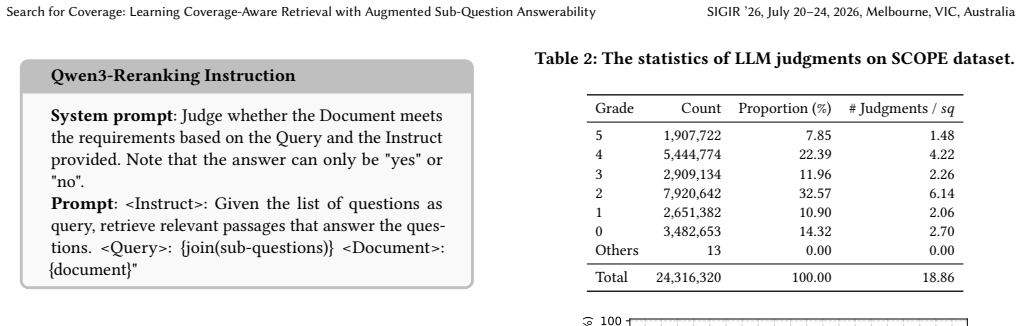
Authors: We acknowledge that the current reporting lacks error bars, significance tests, and expanded dataset statistics. The manuscript already contains ablation studies on the learning objectives, but we will revise the results section to include error bars on main tables, paired statistical significance tests, SCOPE dataset statistics (e.g., sub-question distributions), and clearer ablation tables to substantiate the relevance-coverage trade-off. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs the SCOPE dataset from Researchy Questions using LLM-generated sub-question answerability judgments as synthetic coverage signals, then trains a bi-encoder via standard coverage-based contrastive and distillation objectives. The central empirical claim (10% nugget coverage gain over dense baselines) is presented as an experimental outcome rather than a mathematical identity or fitted parameter renamed as prediction. No equations, self-definitional steps, or load-bearing self-citations appear in the abstract or dataset description that would reduce the result to its inputs by construction. The training pipeline relies on external LLM signals and conventional losses, leaving the reported improvements independently falsifiable via held-out evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-generated answerability labels for sub-questions serve as faithful proxies for human coverage requirements
Reference graph
Works this paper leans on
-
[1]
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al
-
[2]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
MS MARCO: A human generated machine reading comprehension dataset. arXiv:1611.09268
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Jaime Carbonell and Jade Goldstein. 1998. The use of MMR, diversity-based reranking for reordering documents and producing summaries. InProc. of SIGIR. 335–336
1998
-
[4]
Hung-Ting Chen and Eunsol Choi. 2025. Open-World Evaluation for Retrieving Diverse Perspectives. InProc. of NAACL-HLT
2025
- [5]
-
[6]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
-
[7]
InFindings of ACL
M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. InFindings of ACL. 2318– 2335
-
[8]
Charles L A Clarke, Maheedhar Kolla, Gordon V Cormack, Olga Vechtomova, Azin Ashkan, Stefan Büttcher, and Ian MacKinnon. 2008. Novelty and diversity in information retrieval evaluation. InProc. of SIGIR. 659–666
2008
-
[9]
Cormack, Charles L A Clarke, and Stefan Buettcher
Gordon V. Cormack, Charles L A Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proc. of SIGIR. 758–759
2009
-
[10]
Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, and Jimmy Lin
- [11]
- [12]
-
[13]
Laura Dietz. 2024. A workbench for autograding retrieve/generate systems. In Proc. of SIGIR
2024
-
[14]
Alexander Fabbri, Irene Li, Tianwei She, Suyi Li, and Dragomir Radev. 2019. Multi- News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model. InProc. of ACL. 1074–1084
2019
- [15]
-
[16]
Naghmeh Farzi and Laura Dietz. 2024. Pencils down! Automatic rubric-based evaluation of retrieve/generate systems. InProc. of SIGIR. 175–184
2024
-
[17]
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. Enabling large language models to generate text with citations. InProc. of EMNLP. 6465–6488
2023
-
[18]
Max Grusky, Mor Naaman, and Yoav Artzi. 2018. Newsroom: A dataset of 1.3 million summaries with diverse extractive strategies. InProc. of NAACL-HLT. 708–719
2018
-
[19]
Matthew Henderson, Rami Al-Rfou, Brian Strope, Yun hsuan Sung, Laszlo Lukacs, Ruiqi Guo, Sanjiv Kumar, Balint Miklos, and Ray Kurzweil. 2017. Efficient Natural Language Response Suggestion for Smart Reply. arXiv:1705.00652
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [20]
-
[21]
Landry, Eugene Yang, Suzan Verberne, and Andrew Yates
Jia-Huei Ju, François G. Landry, Eugene Yang, Suzan Verberne, and Andrew Yates
-
[22]
LANCER: LLM Reranking for Nugget Coverage. InProc. of ECIR. 188–203
-
[23]
Jia-Huei Ju, Suzan Verberne, Maarten de Rijke, and Andrew Yates. 2025. Con- trolled retrieval-augmented context evaluation for long-form RAG. InFindings of EMNLP. 21102–21121
2025
-
[24]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProc. of EMNLP. 6769–6781
2020
-
[25]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research.Tr...
2019
-
[26]
Dahyun Lee, Yongrae Jo, Haeju Park, and Moontae Lee. 2025. Shifting from ranking to set selection for retrieval augmented generation. InProc. of ACL. 17606–17619. Search for Coverage: Learning Coverage-Aware Retrieval with Augmented Sub-Question Answerability SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia
2025
-
[27]
Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. 2019. Latent retrieval for weakly supervised open domain question answering. InProc. of ACL. 6086–6096
2019
-
[28]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks.Proc. of NIPS
2020
- [29]
-
[30]
Sheng-Chieh Lin, Akari Asai, Minghan Li, Barlas Oguz, Jimmy Lin, Yashar Mehdad, Wen tau Yih, and Xilun Chen. 2023. How to Train Your Dragon: Diverse Augmentation Towards Generalizable Dense Retrieval. InProc. of EMNLP
2023
-
[31]
Xueguang Ma, Luyu Gao, Shengyao Zhuang, Jiaqi Samantha Zhan, Jamie Callan, and Jimmy Lin. 2025. Tevatron 2.0: Unified Document Retrieval Toolkit across Scale, Language, and Modality. InProc. of SIGIR. 4061–4065
2025
-
[32]
James Mayfield, Eugene Yang, Dawn Lawrie, Sean MacAvaney, Paul McNamee, Douglas W Oard, Luca Soldaini, Ian Soboroff, Orion Weller, Efsun Kayi, Kate Sanders, Marc Mason, and Noah Hibbler. 2024. On the evaluation of machine- generated reports. InProc. of SIGIR. 1904–1915
2024
-
[33]
MetaAI. 2024. The Llama 3 herd of models. arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Sewon Min, Kenton Lee, Ming-Wei Chang, Kristina Toutanova, and Hannaneh Hajishirzi. 2021. Joint passage ranking for diverse multi-answer retrieval. InProc. of EMNLP
2021
-
[35]
Zach Nussbaum, John Xavier Morris, Andriy Mulyar, and Brandon Duderstadt
-
[36]
Nomic Embed: Training a Reproducible Long Context Text Embedder. TMLR
- [37]
-
[38]
Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxi- ang Dong, Hua Wu, and Haifeng Wang. 2021. RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering. In Proc. of NAACL-HLT. 5835–5847
2021
-
[39]
Corbin Rosset, Ho-Lam Chung, Guanghui Qin, Ethan Chau, Zhuo Feng, Ahmed Awadallah, Jennifer Neville, and Nikhil Rao. 2025. Researchy Questions: A Dataset of Multi-Perspective, Decompositional Questions for Deep Research. InProc. of SIGIR. 3712–3722
2025
-
[40]
Chris Samarinas, Alexander Krubner, Alireza Salemi, Youngwoo Kim, and Hamed Zamani. 2025. Beyond Factual Accuracy: Evaluating Coverage of Diverse Factual Information in Long-form Text Generation. InFindings of ACL. 13468–13482
2025
-
[41]
David P Sander and Laura Dietz. 2021. EXAM: How to evaluate retrieve-and- generate systems for users who do not (yet) know what they want.DESIRES, 136–146
2021
-
[42]
Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, and Ming-Wei Chang. 2022. ASQA: Factoid questions meet long-form answers. InProc. of EMNLP. 8273–8288
2022
-
[43]
Haochen Tan, Zhijiang Guo, Zhan Shi, Lu Xu, Zhili Liu, Yunlong Feng, Xiaoguang Li, Yasheng Wang, Lifeng Shang, Qun Liu, and Linqi Song. 2024. ProxyQA: An alternative framework for evaluating long-form text generation with large language models. InProc. of ACL. 6806–6827
2024
-
[44]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InProc. of NeurIPS
2021
-
[45]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[46]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge- Intensive Multi-Step Questions. InProc. of ACL. 10014–10037
-
[47]
Ellen M Voorhees. 2003. Evaluating answers to definition questions. InProc. of NAACL-HLT
2003
- [48]
-
[49]
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hall- ström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Griffin Thomas Adams, Jeremy Howard, and Iacopo Poli. 2025. Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference. In...
2025
-
[50]
Martin Wechsler and Peter Schäuble. 2000. The probability ranking principle revisited.Inf. Retr. Boston.3, 3 (2000), 217–227
2000
-
[51]
Bennett, Junaid Ahmed, and Arnold Overwijk
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul N. Bennett, Junaid Ahmed, and Arnold Overwijk. 2021. Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval. InProc. of ICLR
2021
-
[52]
Xiao Yang, Kai Sun, Hao Xin, Yushi Sun, Nikita Bhalla, Xiangsen Chen, Sajal Choudhary, Rongze Daniel Gui, Ziran Will Jiang, Ziyu Jiang, Lingkun Kong, Brian Moran, Jiaqi Wang, Yifan Ethan Xu, An Yan, Chenyu Yang, Eting Yuan, Hanwen Zha, Nan Tang, Lei Chen, Nicolas Scheffer, Yue Liu, Nirav Shah, Rakesh Wanga, Anuj Kumar, Wen-tau Yih, and Xin Luna Dong. 2024...
2024
-
[53]
Wen-Tau Yih, Kristina Toutanova, John C Platt, and Christopher Meek. 2011. Learning Discriminative Projections for Text Similarity Measures. InProc. of CoNLL. 247–256
2011
-
[54]
Puxuan Yu, Razieh Rahimi, Zhiqi Huang, and James Allan. 2023. Search Result Diversification Using Query Aspects as Bottlenecks. InProc. of CIKM. 3040–3051
2023
-
[55]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[56]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models. arXiv:2506.05176
work page internal anchor Pith review Pith/arXiv arXiv
- [57]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.