High Performance, Low Reliability: Uncertainty Benchmarking for Tabular Foundation Models
Pith reviewed 2026-06-29 13:48 UTC · model grok-4.3
The pith
Tabular foundation models lead in accuracy but show weaker conditional coverage than gradient-boosted trees under conformal prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Although TFMs achieve the highest predictive performance measured by AUC, they exhibit lower conditional coverage under conformal prediction measured by SSCS compared to GBDTs.
What carries the argument
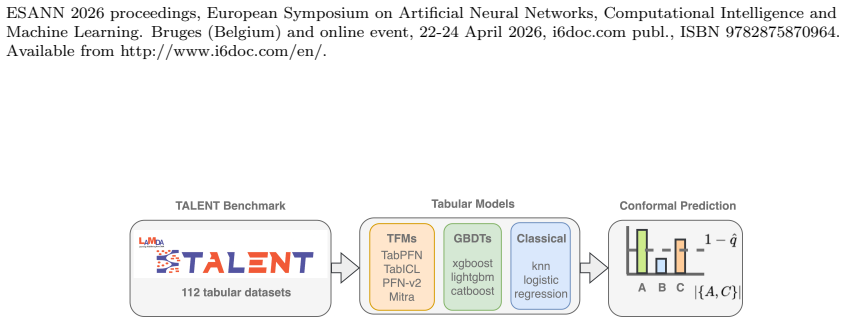
The performance-uncertainty trade-off measured by comparing AUC against SSCS scores from conformal prediction on the TALENT benchmark.
If this is right
- TFMs advance predictive performance but leave well-calibrated uncertainty as an open requirement for reliable adoption.
- GBDTs deliver stronger conditional coverage, suggesting they remain preferable when uncertainty reliability matters most.
- The coverage shortfall grows in specific regimes identified through synthetic data experiments.
- Classical baselines trail in raw performance yet the central contrast lies between TFMs and GBDTs.
Where Pith is reading between the lines
- Model selection in practice may require explicit trade-offs between AUC and SSCS rather than optimizing accuracy alone.
- Architecture or training changes in TFMs could be tested to close the coverage gap while preserving accuracy gains.
- Extending the evaluation to new datasets or alternative conformal methods would test whether the pattern holds beyond the current setup.
- High-stakes deployments might favor GBDTs or add post-hoc calibration steps until TFM uncertainty improves.
Load-bearing premise
The TALENT benchmark datasets together with the selected conformal prediction procedure supply a representative test of uncertainty quantification.
What would settle it
Finding any TFM whose SSCS scores equal or exceed those of GBDTs on the same 112 TALENT datasets under identical conformal settings would contradict the reported trade-off.
Figures

read the original abstract
Recent Tabular Foundation Models (TFMs) have demonstrated state-of-the-art predictive performance, often surpassing Gradient-Boosted Decision Trees (GBDTs). However, the trustworthiness of these models, particularly their uncertainty quantification, has been largely overlooked. We investigate this gap through an extensive study comparing TFMs, GBDTs, and classical baselines on the 112 datasets of the TALENT benchmark. Our results reveal a performance-uncertainty trade-off: although TFMs achieve the highest predictive performance, measured by AUC, they exhibit lower conditional coverage under conformal prediction, measured by SSCS, compared to GBDTs. Complementary experiments on synthetic datasets further characterize the regimes in which this effect intensifies. We conclude that while TFMs advance predictive frontiers, achieving well-calibrated uncertainty remains a major open challenge for their reliable adoption. Code is available at: https://github.com/jose-melo/high-performance-low-reliability
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts an empirical benchmarking study on the 112 datasets of the TALENT benchmark, comparing tabular foundation models (TFMs) against gradient-boosted decision trees (GBDTs) and classical baselines. It claims that TFMs attain the highest predictive performance as measured by AUC yet exhibit lower conditional coverage as measured by SSCS under conformal prediction, establishing a performance-uncertainty trade-off; synthetic experiments are used to identify regimes where the gap widens. Code is released for reproducibility.
Significance. If the reported trade-off is robust, the work usefully flags a practical limitation for deploying TFMs in settings that require reliable uncertainty estimates. The public code release is a clear strength that enables direct verification of the benchmarking pipeline.
major comments (3)
- [Methods] Methods section (conformal prediction procedure): the manuscript provides no explicit description of the nonconformity score, calibration-set construction, or exact definition of the SSCS conditioning mechanism. Because the central claim rests on the SSCS gap, these implementation choices are load-bearing and must be stated unambiguously (or cross-referenced to the released code with line numbers) to allow readers to assess sensitivity.
- [Results] Results and discussion sections: no statistical significance tests, confidence intervals, or per-dataset variability measures are reported for the AUC–SSCS differences aggregated over the 112 TALENT datasets. Without these, the directional claim that TFMs are systematically lower in SSCS cannot be distinguished from dataset-specific or split-specific effects.
- [§5] §5 (synthetic experiments and generalizability): the synthetic regimes are useful but do not test whether TALENT’s dataset properties (size distribution, feature types, or limited shift) systematically favor GBDT calibration over TFMs. This representativeness assumption is load-bearing for the claim that the observed trade-off is general rather than benchmark-specific.
minor comments (2)
- [Abstract] Abstract: the phrase “lower conditional coverage … measured by SSCS” should be accompanied by a one-sentence definition or reference to the metric’s conditioning variable.
- [Figures] Figure captions: several figures lack axis labels or legend entries that would allow a reader to interpret the SSCS values without returning to the main text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Methods] Methods section (conformal prediction procedure): the manuscript provides no explicit description of the nonconformity score, calibration-set construction, or exact definition of the SSCS conditioning mechanism. Because the central claim rests on the SSCS gap, these implementation choices are load-bearing and must be stated unambiguously (or cross-referenced to the released code with line numbers) to allow readers to assess sensitivity.
Authors: We agree that additional detail is warranted. The manuscript will be revised to explicitly state the nonconformity score (absolute residual for regression; 1 minus predicted probability for classification), the calibration-set construction (random 20% split of the training data), and the SSCS definition (empirical coverage within predicted-probability strata). Direct line-number cross-references to the public repository will also be added. revision: yes
-
Referee: [Results] Results and discussion sections: no statistical significance tests, confidence intervals, or per-dataset variability measures are reported for the AUC–SSCS differences aggregated over the 112 TALENT datasets. Without these, the directional claim that TFMs are systematically lower in SSCS cannot be distinguished from dataset-specific or split-specific effects.
Authors: We accept this criticism. The revised Results section will include bootstrap confidence intervals on the mean AUC–SSCS differences across the 112 datasets together with the proportion of datasets in which the SSCS ordering holds. These additions will quantify the consistency of the observed trade-off. revision: yes
-
Referee: [§5] §5 (synthetic experiments and generalizability): the synthetic regimes are useful but do not test whether TALENT’s dataset properties (size distribution, feature types, or limited shift) systematically favor GBDT calibration over TFMs. This representativeness assumption is load-bearing for the claim that the observed trade-off is general rather than benchmark-specific.
Authors: The synthetic experiments isolate mechanistic factors (sample size, feature correlation) that widen the gap; they are not intended as a statistical replica of TALENT. We will expand the discussion to acknowledge that TALENT-specific characteristics could influence the magnitude of the trade-off and will list this as an explicit limitation and avenue for future work. revision: partial
Circularity Check
No significant circularity: empirical benchmarking study
full rationale
This is an empirical benchmarking paper that reports direct performance measurements (AUC for predictive accuracy, SSCS for conditional coverage under conformal prediction) across the TALENT datasets and synthetic experiments. No mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or self-citation chains appear in the abstract or described claims. The central results are measurements on held-out data splits rather than quantities forced by construction from inputs, so the study is self-contained with no load-bearing steps that reduce to the paper's own definitions or prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conformal prediction yields valid conditional coverage when applied to the model outputs on the TALENT splits
Reference graph
Works this paper leans on
-
[1]
Fraud dataset benchmark and applications.arXiv preprint arXiv:2208.14417, 2022
Prince Grover, Julia Xu, Justin Tittelfitz, Anqi Cheng, Zheng Li, Jakub Zablocki, Jianbo Liu, and Hao Zhou. Fraud Dataset Benchmark and Applications, September 2023. arXiv:2208.14417 version: 3
-
[2]
Explainable AI for clinical and remote health applications: a survey on tabular and time series data.Artificial Intelligence Review, 56(6):5261–5315, June 2023
Flavio Di Martino and Franca Delmastro. Explainable AI for clinical and remote health applications: a survey on tabular and time series data.Artificial Intelligence Review, 56(6):5261–5315, June 2023
2023
-
[3]
Why do tree-based models still outperform deep learning on typical tabular data? 2022
L´ eo Grinsztajn, Edouard Oyallon, and Ga¨ el Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data? 2022
2022
-
[4]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Noah Hollmann, Samuel M¨ uller, Katharina Eggensperger, and Frank Hutter. TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second. September 2022
2022
-
[5]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, January 2025
Noah Hollmann, Samuel M¨ uller, Lennart Purucker, Arjun Krishnakumar, Max K¨ orfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, January 2025. Publisher: Nature Publishing Group
2025
-
[6]
TabICL: A Tabular Foundation Model for In-Context Learning on Large Data
Jingang Qu, David Holzm¨ uller, Ga¨ el Varoquaux, and Marine Le Morvan. TabICL: A Tabular Foundation Model for In-Context Learning on Large Data, February 2025. arXiv:2502.05564 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
TabArena: A Living Benchmark for Machine Learning on Tabular Data
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzm¨ uller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. TabArena: A Living Benchmark for Machine Learning on Tabular Data, June 2025. arXiv:2506.16791 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Talent: A tabular analytics and learning toolbox.arXiv preprint arXiv:2407.04057, 2024
Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, and Han-Jia Ye. TALENT: A Tabular Analytics and Learning Toolbox, July 2024. arXiv:2407.04057 [cs]
-
[9]
Wong, Emine Yilmaz, Shuming Shi, and Zhaopeng Tu
Fanghua Ye, Mingming Yang, Jianhui Pang, Longyue Wang, Derek F. Wong, Emine Yilmaz, Shuming Shi, and Zhaopeng Tu. Benchmarking LLMs via Uncertainty Quantifi- cation.Advances in Neural Information Processing Systems, 37:15356–15385, December 2024
2024
-
[10]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
Anastasios N. Angelopoulos and Stephen Bates. A Gentle Introduction to Con- formal Prediction and Distribution-Free Uncertainty Quantification, December 2022. arXiv:2107.07511 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Xiyuan Zhang, Danielle C. Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Bo- ran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W. Mahoney, Cuixiong Hu, Huzefa Rangwala, George Karypis, and Bernie Wang. Mitra: Mixed Synthetic Priors for Enhancing Tabular Foundation Models, October 2025. arXiv:2510.21204 [cs]
-
[12]
Yury Gorishniy, Akim Kotelnikov, and Artem Babenko. TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling, February 2025. arXiv:2410.24210 [cs]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.