Outer-Momentum Restarting in High-Dimensional Two-Phase Optimization
Pith reviewed 2026-06-29 13:28 UTC · model grok-4.3
The pith
Periodic restarts of outer momentum in two-phase distributed optimization discard stale memory via phase cancellation while preserving inner-loop progress.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the linearized squared-loss model where prediction-space residuals evolve under the empirical NTK, periodic restarts of the outer momentum produce a mode-wise restart contraction showing that resets exploit phase cancellation by discarding stale momentum while preserving inner-loop progress.
What carries the argument
mode-wise restart contraction under empirical NTK dynamics
If this is right
- Periodic outer-momentum restarts widen the stable range of outer learning rates and momentum values across communication periods.
- The outer optimizer controls how local-update progress accumulates across rounds, and restarts provide a complementary control on outer memory.
- Toy experiments confirm the contraction behavior predicted by the linearized model.
Where Pith is reading between the lines
- The restart mechanism might transfer to other two-phase or federated optimizers that rely on outer momentum.
- If the contraction holds only in the linear regime, non-linear effects in very deep models could require adjusted restart frequencies.
- Pairing restarts with inner-loop length tuning could further reduce communication while maintaining convergence.
Load-bearing premise
The linearized squared-loss model with empirical NTK dynamics accurately predicts behavior in the actual high-dimensional non-linear optimization used for language-model pretraining.
What would settle it
Language-model pretraining runs that achieve the same or wider stable range of outer learning rates and momentum values without any restarts would falsify the claimed benefit of the mode-wise contraction.
Figures

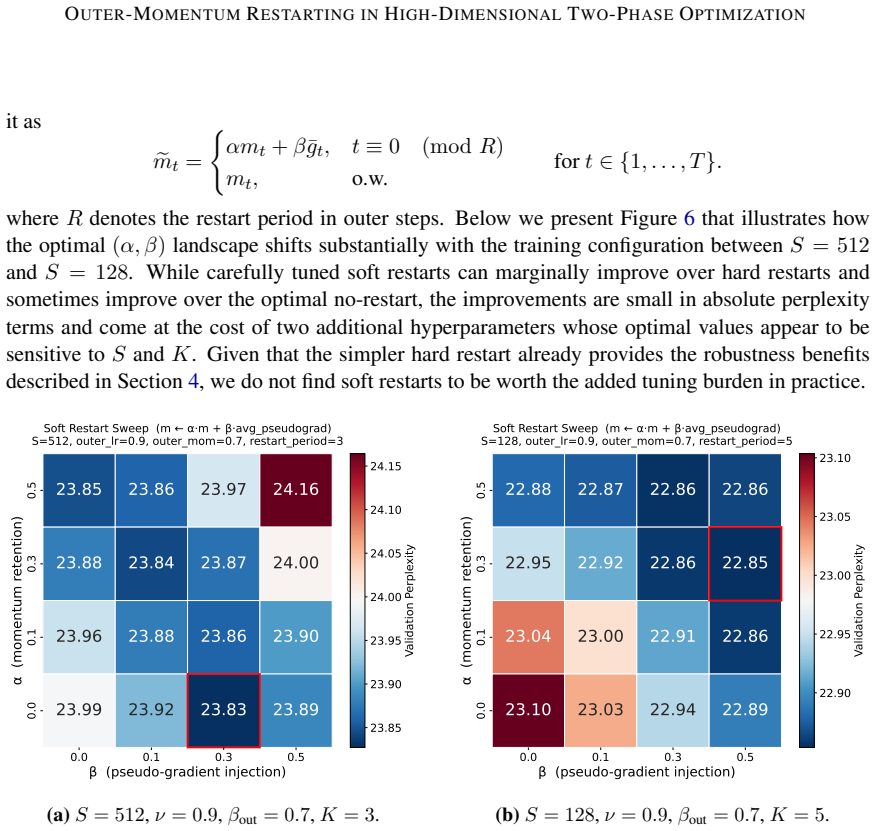
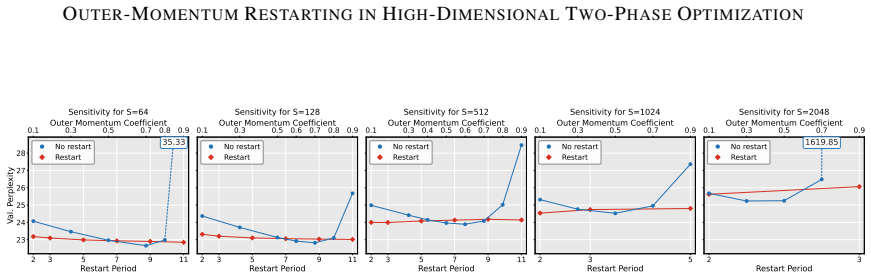
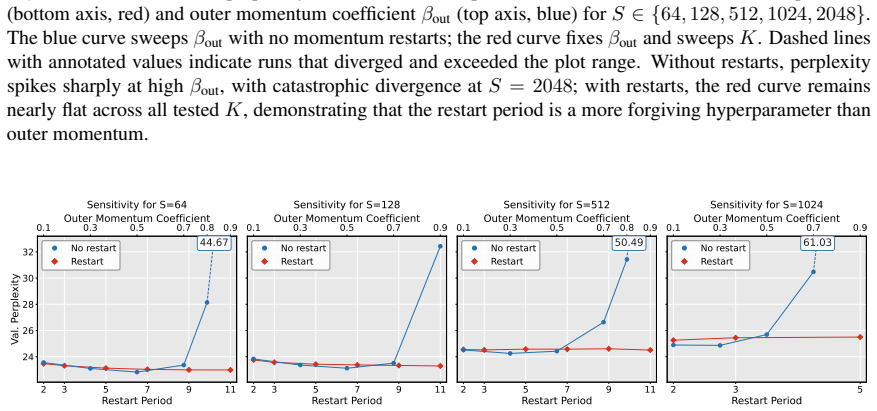
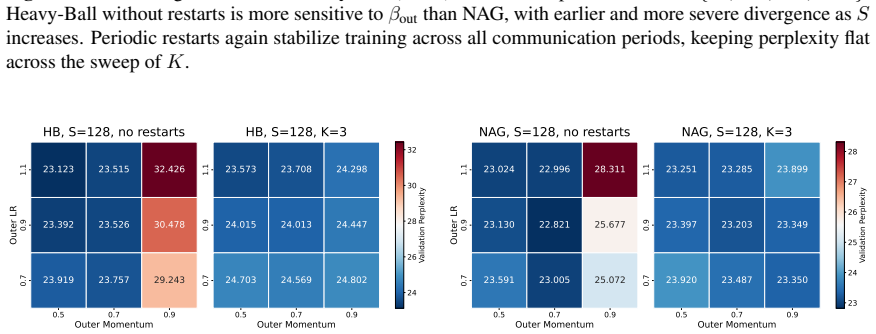
read the original abstract
Communication-efficient distributed optimizers such as DiLoCo reduce synchronization costs by letting workers perform many local updates before aggregating their progress with an outer momentum optimizer. Recent theory suggests that the outer optimizer acts on an effective spectrum induced by the inner optimization loop, and that the choice of outer momentum controls how progress from local updates is accumulated across communication rounds. We study periodic restarting of the outer momentum as a simple complementary mechanism for controlling this outer memory. In a linearized squared-loss model where prediction-space residuals evolve under the empirical NTK, we derive a mode-wise restart contraction showing that resets exploit phase cancellation by discarding stale momentum while preserving inner-loop progress. Toy experiments verify the predicted contraction behavior, and language-model pretraining experiments show that periodic restarts widen the stable range of outer learning rates and momentum values across communication periods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies periodic restarting of the outer momentum in communication-efficient two-phase optimizers such as DiLoCo. In a linearized squared-loss model where prediction-space residuals evolve under the empirical NTK, it derives a mode-wise restart contraction that exploits phase cancellation to discard stale momentum while preserving inner-loop progress. Toy experiments are reported to verify the predicted contraction, and language-model pretraining runs indicate that periodic restarts widen the stable range of outer learning rates and momentum values across communication periods.
Significance. If the derivation holds, the work supplies a simple, theoretically motivated mechanism for controlling outer memory in distributed optimization of large models. The parameter-free derivation of the mode-wise contraction inside the linearized model, together with its verification in toy settings and the reported expansion of the stable hyperparameter region in LM pretraining, constitute concrete strengths.
minor comments (2)
- Abstract: the summary supplies neither the key equations of the linearized model nor any quantitative statements (e.g., contraction factors or error bars), which reduces immediate verifiability of the central claim.
- LM pretraining section: exclusion criteria for the reported runs and the precise definition of “stable range” are not stated, making it difficult to assess how the observed widening was quantified.
Simulated Author's Rebuttal
We thank the referee for the supportive summary and recommendation of minor revision. No major comments were provided in the report, so we have no specific points requiring rebuttal or revision at this stage.
Circularity Check
Derivation self-contained in linearized NTK model
full rationale
The central derivation of mode-wise restart contraction occurs analytically inside the stated linearized squared-loss model with empirical NTK residual dynamics, using phase cancellation to show discarding of stale momentum while preserving inner-loop progress. This is a direct consequence of the model's equations rather than any fitted parameter renamed as prediction, self-definitional loop, or load-bearing self-citation. Toy experiments verify the derived behavior and LM pretraining reports widened stable ranges, but neither feeds back into the derivation itself. No steps reduce by construction to the paper's inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The linearized squared-loss model with empirical NTK accurately represents the outer-momentum dynamics of the two-phase optimizer.
Reference graph
Works this paper leans on
-
[1]
High dimensional theory of two-phase optimizers.arXiv preprint arXiv:2603.26954, 2026
Atish Agarwala. High dimensional theory of two-phase optimizers.arXiv preprint arXiv:2603.26954, 2026. URLhttps://arxiv.org/abs/2603.26954
-
[2]
Du, Wei Hu, Zhiyuan Li, Ruslan Salakhutdinov, and Ruosong Wang
Sanjeev Arora, Simon S. Du, Wei Hu, Zhiyuan Li, Ruslan Salakhutdinov, and Ruosong Wang. On exact computation with an infinitely wide neural net. InAdvances in Neural Information Processing Systems, volume 32, 2019. URLhttps://arxiv.org/abs/1904.11955
-
[3]
Convergence and accuracy trade-offs in federated learning and meta-learning
Zachary Charles and Jakub Kone ˇcn´y. Convergence and accuracy trade-offs in federated learning and meta-learning. InProceedings of The 24th International Conference on Arti- ficial Intelligence and Statistics, volume 130 ofProceedings of Machine Learning Research, pages 2575–2583. PMLR, 2021. URLhttps://proceedings.mlr.press/v130/ charles21a.html
2021
-
[4]
Iterated vector fields and conservatism, with applications to federated learning
Zachary Charles and Keith Rush. Iterated vector fields and conservatism, with applications to federated learning. InProceedings of The 33rd International Conference on Algorithmic Learning Theory, volume 167 ofProceedings of Machine Learning Research, pages 130–
-
[5]
URLhttps://proceedings.mlr.press/v167/charles22a
PMLR, 2022. URLhttps://proceedings.mlr.press/v167/charles22a. html
2022
-
[6]
Zachary Charles, Gabriel Teston, Lucio Dery, Keith Rush, Nova Fallen, Zachary Garrett, Arthur Szlam, and Arthur Douillard. Communication-efficient language model training scales reliably and robustly: Scaling laws for DiLoCo.arXiv preprint arXiv:2503.09799, 2025. doi: 10.48550/arxiv.2503.09799. URLhttps://arxiv.org/abs/2503.09799
-
[7]
Towards quan- tifying the hessian structure of neural networks.arXiv preprint arXiv:2505.02809, 2025
Zhaorui Dong, Yushun Zhang, Zhi-Quan Luo, Jianfeng Yao, and Ruoyu Sun. Towards quan- tifying the hessian structure of neural networks.arXiv preprint arXiv:2505.02809, 2025. doi: 10.48550/arxiv.2505.02809. URLhttps://arxiv.org/abs/2505.02809
-
[8]
Arthur Douillard, Qixuan Feng, Andrei A. Rusu, Rachita Chhaparia, Yani Donchev, Adhiguna Kuncoro, Marc’Aurelio Ranzato, Arthur Szlam, and Jiajun Shen. DiLoCo: Distributed low- communication training of language models.arXiv preprint arXiv:2311.08105, 2023. doi: 10.48550/arxiv.2311.08105. URLhttps://arxiv.org/abs/2311.08105
-
[9]
Keith Rush, Satyen Kale, Zachary Charles, Gabriel Teston, Zachary Garrett, Jiajun Shen, Ross McIlroy, David Lacey, Alexandre Ram ´e, Arthur Szlam, Marc’Aurelio Ranzato, and Paul R
Arthur Douillard, Yani Donchev, J. Keith Rush, Satyen Kale, Zachary Charles, Gabriel Teston, Zachary Garrett, Jiajun Shen, Ross McIlroy, David Lacey, Alexandre Ram ´e, Arthur Szlam, Marc’Aurelio Ranzato, and Paul R. Barham. Streaming DiLoCo with overlapping commu- nication: Towards a distributed free lunch. InSecond Conference on Language Modeling,
-
[10]
URLhttps://openreview.net/forum?id= yYk3zK0X6Q
doi: 10.48550/arxiv.2501.18512. URLhttps://openreview.net/forum?id= yYk3zK0X6Q
-
[11]
Olivier Fercoq and Zheng Qu. Adaptive restart of accelerated gradient methods under local quadratic growth condition.IMA Journal of Numerical Analysis, 39(4):2069–2095, 2019. doi: 10.1093/imanum/drz007. URLhttps://arxiv.org/abs/1709.02300
-
[12]
Monotonicity and restart in fast gradient methods
Pontus Giselsson and Stephen Boyd. Monotonicity and restart in fast gradient methods. In53rd IEEE Conference on Decision and Control, pages 5058–5063. IEEE, 2014. doi: 6 OUTER-MOMENTUMRESTARTING INHIGH-DIMENSIONALTWO-PHASEOPTIMIZATION 10.1109/cdc.2014.7040179. URLhttps://web.stanford.edu/ ˜boyd/papers/ restart_fgm.html
-
[13]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aure- lia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sif...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/068431-2176 2022
-
[14]
SPAM: Spike-aware adam with momentum reset for stable LLM training
Tianjin Huang, Ziquan Zhu, Gaojie Jin, Lu Liu, Zhangyang Wang, and Shiwei Liu. SPAM: Spike-aware adam with momentum reset for stable LLM training. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025. doi: 10.48550/arxiv.2501.06842. URL https://arxiv.org/abs/2501.06842
-
[15]
Neural tangent kernel: Convergence and generalization in neural networks
Arthur Jacot, Franck Gabriel, and Cl ´ement Hongler. Neural tangent kernel: Convergence and generalization in neural networks. InAdvances in Neural Information Processing Systems, volume 31, 2018. URLhttps://arxiv.org/abs/1806.07572
-
[16]
Dominik Kallusky, Vinay Rao, Vishal Nandavanam, and Hao-Jun Michael Shi. SNOO: Step- K nesterov outer optimizer – the surprising effectiveness of nesterov momentum applied to pseudo-gradients.arXiv preprint arXiv:2510.15830, 2025. doi: 10.48550/arxiv.2510.15830. URLhttps://arxiv.org/abs/2510.15830
-
[17]
Ahmed Khaled, Satyen Kale, Arthur Douillard, Chi Jin, Rob Fergus, and Manzil Zaheer. Understanding outer optimizers in local SGD: Learning rates, momentum, and accelera- tion.arXiv preprint arXiv:2509.10439, 2025. doi: 10.48550/arxiv.2509.10439. URL https://arxiv.org/abs/2509.10439
-
[18]
Donghwan Kim and Jeffrey A. Fessler. Adaptive restart of the optimized gradient method for convex optimization.Journal of Optimization Theory and Applications, 178(1):240– 263, 2018. doi: 10.1007/s10957-018-1287-4. URLhttps://doi.org/10.1007/ s10957-018-1287-4
-
[19]
Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington
Jaehoon Lee, Lechao Xiao, Samuel S. Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington. Wide neural networks of any depth evolve as lin- ear models under gradient descent. InAdvances in Neural Information Processing Systems, volume 32, 2019. URLhttps://arxiv.org/abs/1902.06720
-
[20]
From local SGD to local fixed-point methods for federated learning
Grigory Malinovskiy, Dmitry Kovalev, Elnur Gasanov, Laurent Condat, and Peter Richt ´arik. From local SGD to local fixed-point methods for federated learning. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 6692–6701. PMLR, 2020. URLhttps://proceedings. mlr.press/v119/mal...
2020
-
[21]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Ag ¨uera y Arcas
H. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Ag ¨uera y Arcas. Communication-efficient learning of deep networks from decentralized data. InPro- 7 OUTER-MOMENTUMRESTARTING INHIGH-DIMENSIONALTWO-PHASEOPTIMIZATION ceedings of the 20th International Conference on Artificial Intelligence and Statistics, vol- ume 54 ofProceedings of...
2017
-
[22]
Brendan O’Donoghue and Emmanuel Cand `es. Adaptive restart for accelerated gradient schemes.Foundations of Computational Mathematics, 15(3):715–732, 2015. doi: 10.1007/ s10208-013-9150-3. URLhttps://doi.org/10.1007/s10208-013-9150-3
-
[23]
Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcn´y, Sanjiv Kumar, and H
Sashank J. Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcn´y, Sanjiv Kumar, and H. Brendan McMahan. Adaptive federated optimization. InIn- ternational Conference on Learning Representations, 2021. URLhttps://openreview. net/forum?id=LkFG3lB13U5
2021
-
[24]
Sharpness, restart and acceleration
Vincent Roulet and Alexandre d’Aspremont. Sharpness, restart and acceleration. InAdvances in Neural Information Processing Systems, volume 30, 2017. URLhttps://papers. nips.cc/paper/6712-sharpness-restart-and-acceleration
2017
-
[25]
Kristi Topollai and Anna Choromanska. Understanding quantization of optimizer states in LLM pre-training: Dynamics of state staleness and effectiveness of state resets.arXiv preprint arXiv:2603.16731, 2026. URLhttps://arxiv.org/abs/2603.16731
-
[26]
Bao Wang, Tan M. Nguyen, Andrea L. Bertozzi, Richard G. Baraniuk, and Stanley J. Osher. Scheduled restart momentum for accelerated stochastic gradient descent.SIAM Journal on Imaging Sciences, 15(2):738–761, 2022. doi: 10.1137/21M1453311. URLhttps://doi. org/10.1137/21M1453311
-
[27]
Fantastic pretraining optimizers and where to find them.arXiv preprint arXiv:2509.02046, 2025
Kaiyue Wen, David Hall, Tengyu Ma, and Percy Liang. Fantastic pretraining optimizers and where to find them.arXiv preprint arXiv:2509.02046, 2025. doi: 10.48550/arxiv.2509.02046. URLhttps://arxiv.org/abs/2509.02046
-
[28]
Zhang, James Lucas, Jimmy Ba, and Geoffrey E
Michael R. Zhang, James Lucas, Jimmy Ba, and Geoffrey E. Hinton. Lookahead optimizer: ksteps forward, 1 step back. InAdvances in Neural Information Processing Systems, vol- ume 32, 2019. URLhttps://proceedings.neurips.cc/paper/2019/hash/ 90fd4f88f588ae64038134f1eeaa023f-Abstract.html
2019
-
[29]
Why transformers need adam: A hessian perspective
Yushun Zhang, Congliang Chen, Tian Ding, Ziniu Li, Ruoyu Sun, and Zhi-Quan Luo. Why transformers need adam: A hessian perspective. InAdvances in Neural Infor- mation Processing Systems, volume 37, 2024. doi: 10.48550/arxiv.2402.16788. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ ee0e45ff4de76cbfdf07015a7839f339-Abstract-Conference.html....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.