Thinned Mean Field Langevin Dynamics
Pith reviewed 2026-06-29 14:38 UTC · model grok-4.3
The pith
KT-MFLD uses a kernel-thinned coreset of size O(sqrt(N)) so each particle interacts only with the thinned set, cutting complexity from N squared to N to the 3/2 while retaining the original convergence guarantees up to logarithmic factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
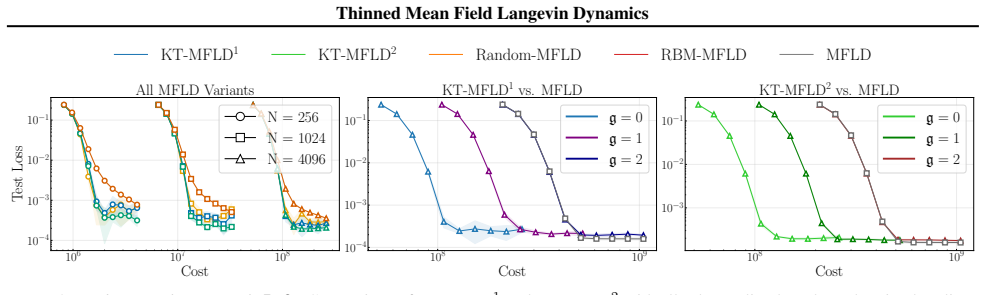
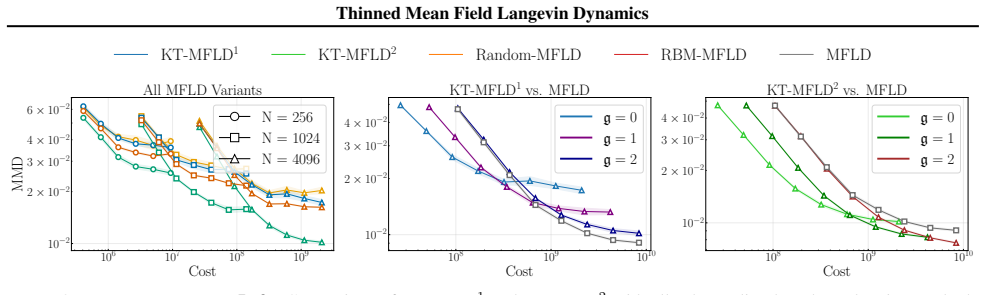
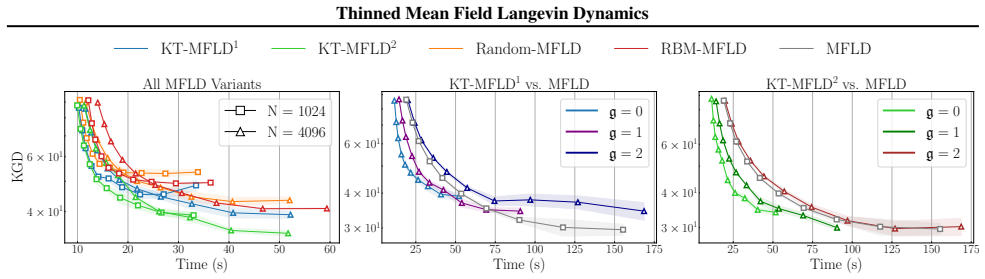
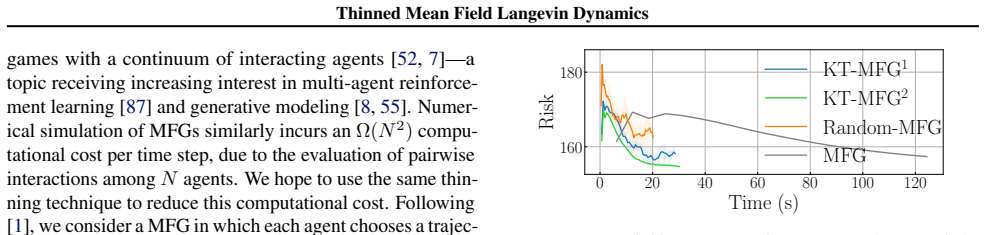
KT-MFLD replaces the quadratic-cost interacting particle system of standard mean-field Langevin dynamics with a thinned version in which each of the N particles interacts only with a kernel-thinned coreset of size O(sqrt(N)). Under mild regularity conditions the thinned dynamics still converge to the invariant measure of the McKean-Vlasov process at the same rate, up to logarithmic factors, as the unthinned dynamics.
What carries the argument
The kernel-thinned coreset of size O(sqrt(N)), which selects a subset of particles whose empirical measure approximates the full interaction kernel sufficiently well to carry the McKean-Vlasov convergence analysis through.
If this is right
- Larger particle systems become feasible for entropy-regularized optimization over distributions.
- The same thinning technique can be applied to other McKean-Vlasov discretizations that currently scale quadratically.
- Tasks such as student-teacher network training, MMD quantization, and post-Bayesian posterior sampling become practical at higher resolution.
- The method yields an explicit complexity-accuracy trade-off controlled by the coreset size.
Where Pith is reading between the lines
- The same thinning idea may extend to non-Langevin mean-field limits provided the interaction kernel admits a good low-rank or sparse approximation.
- If stronger moment bounds hold, even smaller coresets than O(sqrt(N)) might suffice without losing the rate.
- The construction suggests a general route for accelerating any interacting-particle scheme whose convergence proof relies on uniform control of empirical measures.
Load-bearing premise
The kernel-thinned coreset of size O(sqrt(N)) preserves the interaction structure and moment bounds needed for the McKean-Vlasov convergence analysis to carry over without degradation beyond log factors.
What would settle it
A numerical check on a simple Gaussian target showing that the convergence rate of the thinned dynamics degrades by more than a logarithmic factor relative to the full-particle dynamics.
Figures

read the original abstract
Several important learning tasks can be formulated as minimizing an entropy-regularized objective over an appropriate space of probability distributions. Mean-field Langevin dynamics (MFLD) facilitate computation in this general context, casting the minimizer as the invariant distribution of a McKean--Vlasov process, which can be numerically discretized using $N$ particles and thus simulated. However, simulating this interacting particle system has computational complexity of order $N^2$. Motivated by recent research into \emph{kernel thinning}, we propose \texttt{KT-MFLD}, in which each particle interacts only with a thinned particle coreset of size $\mathcal{O}(N^{\frac{1}{2}})$. \texttt{KT-MFLD} thus reduces the computational complexity to order $N^{\frac{3}{2}}$ while, under mild regularity conditions, achieving the same convergence guarantees (up to logarithmic factors) as MFLD. Our theoretical analysis is empirically confirmed on tasks including the training of student-teacher neural networks, quantization with maximum mean discrepancy, and computation of predictively-oriented posteriors in a post-Bayesian framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes KT-MFLD, a computationally efficient variant of mean-field Langevin dynamics (MFLD) for entropy-regularized distribution optimization. Standard MFLD discretizes the McKean-Vlasov process with N particles at O(N²) cost; KT-MFLD replaces full interactions with a kernel-thinned coreset of size O(√N), reducing cost to O(N^{3/2}). The central claim is that, under mild regularity conditions, the thinned dynamics retain the same convergence guarantees as MFLD up to logarithmic factors. The result is supported by theoretical analysis extending prior kernel-thinning and McKean-Vlasov results, together with empirical confirmation on student-teacher network training, MMD quantization, and post-Bayesian posterior computation.
Significance. If the uniform-in-time error control holds, the work would provide a concrete route to scaling particle-based mean-field methods beyond the quadratic bottleneck, with direct relevance to large-scale distribution optimization in machine learning. The integration of static kernel thinning with evolving McKean-Vlasov dynamics is a non-trivial technical step whose success would be of interest to both sampling and optimization communities.
major comments (1)
- [theoretical analysis (McKean-Vlasov convergence extension)] The load-bearing step is the claim that an O(√N) kernel-thinned coreset preserves the interaction structure and moment bounds required for McKean-Vlasov convergence uniformly in time. Because kernel thinning is a static quadrature technique applied to a fixed measure, the analysis must explicitly control the approximation error with respect to the time-evolving empirical measure; without such a uniform bound, the accumulated discrepancy can exceed logarithmic factors and degrade the long-time guarantee. The abstract states the result holds “under mild regularity conditions,” but the precise uniformity argument (and any distribution-dependent constants that may grow with the trajectory) needs to be spelled out.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The major comment highlights an important point about making the uniformity argument explicit, which we address below.
read point-by-point responses
-
Referee: [theoretical analysis (McKean-Vlasov convergence extension)] The load-bearing step is the claim that an O(√N) kernel-thinned coreset preserves the interaction structure and moment bounds required for McKean-Vlasov convergence uniformly in time. Because kernel thinning is a static quadrature technique applied to a fixed measure, the analysis must explicitly control the approximation error with respect to the time-evolving empirical measure; without such a uniform bound, the accumulated discrepancy can exceed logarithmic factors and degrade the long-time guarantee. The abstract states the result holds “under mild regularity conditions,” but the precise uniformity argument (and any distribution-dependent constants that may grow with the trajectory) needs to be spelled out.
Authors: We agree that the uniformity of the kernel-thinning error with respect to the time-evolving empirical measure is the central technical step and that this chaining argument should be presented more explicitly. Our proof proceeds by first invoking the standard uniform-in-time moment bounds for MFLD (which hold under the same mild regularity conditions—Lipschitz gradients and quadratic growth of the potential—that guarantee non-explosion in the McKean–Vlasov literature). These bounds ensure that all measures encountered along the trajectory belong to a compact set of measures with uniformly controlled moments. Kernel thinning is then applied to this compact set, yielding an error that is uniform in time up to the logarithmic factors already stated. The distribution-dependent constants therefore remain bounded by quantities that do not grow with the trajectory length. To address the referee’s concern, we will add a dedicated subsection that spells out this argument, including the explicit dependence of constants on the moment bounds. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation relies on external prior results for kernel thinning to construct the O(sqrt(N)) coreset and states that the McKean-Vlasov convergence analysis carries over under mild regularity conditions without degradation beyond logarithmic factors. No equations, claims, or steps in the abstract or described chain reduce by construction to quantities defined or fitted by the authors themselves; the central approximation error bound is not self-referential or obtained via self-citation load-bearing. The work is therefore self-contained against external benchmarks on kernel thinning.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild regularity conditions on the target distribution and interaction kernel suffice for the thinned dynamics to inherit the convergence rate of the unthinned McKean-Vlasov process up to logarithmic factors.
Reference graph
Works this paper leans on
-
[1]
Agrawal, W
S. Agrawal, W. Lee, S. W. Fung, and L. Nurbekyan. Random features for high-dimensional nonlocal mean- field games.Journal of Computational Physics, 459: 111136, 2022
2022
-
[2]
Antonelli and A
F. Antonelli and A. Kohatsu-Higa. Rate of conver- gence of a particle method to the solution of the McKean–Vlasov equation.The Annals of Applied Probability, 12(2):423–476, 2002
2002
-
[3]
Arbel, A
M. Arbel, A. Korba, A. Salim, and A. Gretton. Max- imum mean discrepancy gradient flow.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[4]
Aronszajn
N. Aronszajn. Theory of reproducing kernels.Trans- actions of the American mathematical society, 68(3): 337–404, 1950
1950
-
[5]
G. B. Arous, R. Gheissari, and A. Jagannath. On- 9 Thinned Mean Field Langevin Dynamics line stochastic gradient descent on non-convex losses from high-dimensional inference.Journal of Machine Learning Research, 22(106):1–51, 2021
2021
-
[6]
Bardet, N
J.-B. Bardet, N. Gozlan, F. Malrieu, and P.-A. Zitt. Functional inequalities for Langevin convolutions of compactly supported measures: Explicit bounds and dimension dependence.Bernoulli, 24(1):333–353, 2018
2018
-
[7]
Bensoussan, J
A. Bensoussan, J. Frehse, and P. Yam.Mean field games and mean field type control theory. Springer, 2013
2013
-
[8]
Berner, L
J. Berner, L. Richter, and K. Ullrich. An optimal control perspective on diffusion-based generative mod- eling.Transactions on Machine Learning Research, 2024
2024
-
[9]
S. V . Borodachov, D. P. Hardin, and E. B. Saff. Low complexity methods for discretizing manifolds via riesz energy minimization.Foundations of Compu- tational Mathematics, 14(6):1173–1208, 2014
2014
-
[10]
N. Boyd, G. Schiebinger, and B. Recht. The alternating descent conditional gradient method for sparse inverse problems.SIAM Journal on Optimization, 27(2):616– 639, 2017
2017
-
[11]
V . V . Buldygin and Y . V . Kozachenko.Metric char- acterization of random variables and random pro- cesses, volume 188 ofTranslations of Mathemati- cal Monographs. American Mathematical Society, Providence, RI, 2000. ISBN 0-8218-0533-9. doi: 10.1090/mmono/188. URL https://doi.org/ 10.1090/mmono/188. Translated from the 1998 Russian original by V . Zaiats
-
[12]
Z. Cao, K. Das, N. Langren´e, and M. Lauri`ere. Scal- able method for mean field control with kernel inter- actions via random Fourier features.arXiv preprint arXiv:2601.01175, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Carmona and F
R. Carmona and F. Delarue.Probabilistic Theory of Mean Field Games with Applications I-II. Springer, 2018
2018
-
[14]
A. M. Carrell, A. Gong, A. Shetty, R. Dwivedi, and L. Mackey. Low-rank thinning. InInternational Conference on Machine Learning, pages 6811–6848. PMLR, 2025
2025
-
[15]
J. A. Carrillo, Y .-P. Choi, C. Totzeck, and O. Tse. An analytical framework for consensus-based global opti- mization method.Mathematical Models and Methods in Applied Sciences, 28(06):1037–1066, 2018
2018
- [16]
-
[17]
F. Chen, Y . Lin, Z. Ren, and S. Wang. Uniform-in-time propagation of chaos for kinetic mean field Langevin dynamics.Electronic Journal of Probability, 29:1–43, 2024
2024
-
[18]
Y . Chen, M. Welling, and A. Smola. Super-samples from kernel herding. InProceedings of the Twenty- Sixth Conference on Uncertainty in Artificial Intelli- gence, pages 109–116, 2010
2010
-
[19]
Z. Chen, H. Li, F. Wang, O. Zhang, H. Xu, X. Jiang, Z. Song, and H. Wang. Rethinking the diffusion mod- els for missing data imputation: A gradient flow per- spective.Advances in Neural Information Processing Systems, 37:112050–112103, 2024
2024
-
[20]
Z. Chen, A. Mustafi, P. Glaser, A. Korba, A. Gretton, and B. K. Sriperumbudur. (De)-regularized maximum mean discrepancy gradient flow.Journal of Machine Learning Research, 26(235):1–77, 2025
2025
- [21]
-
[22]
Z. Chen, T. Karvonen, H. Kanagawa, F.-X. Briol, and C. J. Oates. Stationary MMD points. InInternational Conference on Machine Learning, 2026
2026
- [23]
-
[24]
L. Chizat. Mean-field Langevin dynamics: Exponen- tial convergence and annealing.Transactions on Ma- chine Learning Research, 2022
2022
-
[25]
Chizat and F
L. Chizat and F. Bach. On the global convergence of gradient descent for over-parameterized models using optimal transport.Advances in Neural Information Processing Systems, 2018
2018
-
[26]
Chizat, S
L. Chizat, S. Zhang, M. Heitz, and G. Schiebinger. Trajectory inference via mean-field Langevin in path space.Advances in Neural Information Processing Systems, pages 16731–16742, 2022
2022
-
[27]
F. R. Crucinio, V . De Bortoli, A. Doucet, and A. M. Jo- hansen. Solving a class of Fredholm integral equations of the first kind via Langevin gradient flows.Stochastic Processes and their Applications, 173:104374, 2024
2024
-
[28]
Del Moral
P. Del Moral. Mean field simulation for Monte Carlo integration.Monographs on Statistics and Applied Probability, 126(26):6, 2013
2013
-
[29]
Dick and F
J. Dick and F. Pillichshammer. Discrepancy theory and quasi-Monte Carlo integration. InA Panorama of Discrepancy Theory, pages 539–619. Springer, 2014. 10 Thinned Mean Field Langevin Dynamics
2014
- [30]
-
[31]
Doucet, N
A. Doucet, N. De Freitas, and N. Gordon. An in- troduction to sequential Monte Carlo methods. In Sequential Monte Carlo methods in Practice, pages 3–14. Springer, 2001
2001
-
[32]
R. M. Dudley.Uniform Central Limit Theorems. Cam- bridge University Press, 2014
2014
-
[33]
Durmus and ´E
A. Durmus and ´E. Moulines. High-dimensional Bayesian inference via the unadjusted Langevin al- gorithm.Bernoulli, 25(4A):2854–2882, 2019
2019
-
[34]
Dwivedi and L
R. Dwivedi and L. Mackey. Generalized kernel thin- ning. InInternational Conference on Learning Repre- sentations, 2022
2022
-
[35]
Dwivedi and L
R. Dwivedi and L. Mackey. Kernel thinning.Journal of Machine Learning Research, 25(152):1–77, 2024
2024
-
[36]
L. C. Evans.Partial differential equations, volume 19. American mathematical society, 2022
2022
-
[37]
Fr ¨ohlich and B
J. Fr ¨ohlich and B. Zegarlinski. Some comments on the Sherrington–Kirkpatrick model of spin glasses. Communications in Mathematical Physics, 112(4): 553–566, 1987
1987
-
[38]
Gneiting and A
T. Gneiting and A. E. Raftery. Strictly proper scor- ing rules, prediction, and estimation.Journal of the American Statistical Association, 102(477):359–378, 2007
2007
-
[39]
Gretton, K
A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Sch ¨olkopf, and A. Smola. A kernel two-sample test.Journal of Machine Learning Research, 13(1): 723–773, 2012
2012
-
[40]
A. Gu, E. Chien, and K. Greenewald. Partially ob- served trajectory inference using optimal transport and a dynamics prior. InInternational Conference on Learning Representations, 2025
2025
-
[41]
Y . He, K. Balasubramanian, B. K. Sriperumbudur, and J. Lu. Regularized Langevin variational gradient flow. Foundations of Computational Mathematics, 25(4): 1199–1257, 2025
2025
-
[42]
K. Hu, Z. Ren, D. ˇSiˇska, and Ł. Szpruch. Mean-field Langevin dynamics and energy landscape of neural networks. InAnnales de l’Institut Henri Poincare (B) Probabilites et statistiques, volume 57, pages 2043–
2043
-
[43]
Institut Henri Poincar´e, 2021
2021
-
[44]
Jankowiak, G
M. Jankowiak, G. Pleiss, and J. Gardner. Parametric Gaussian process regressors. InInternational Confer- ence on Machine Learning, pages 4702–4712. PMLR, 2020
2020
-
[45]
S. Jin, L. Li, and J.-G. Liu. Random batch methods (RBM) for interacting particle systems.Journal of Computational Physics, 400:108877, 2020
2020
-
[46]
Jordan, D
R. Jordan, D. Kinderlehrer, and F. Otto. The variational formulation of the Fokker–Planck equation.SIAM Journal on Mathematical Analysis, 29(1):1–17, 1998
1998
-
[47]
V . R. Joseph, D. Wang, L. Gu, S. Lyu, and R. Tuo. Deterministic sampling of expensive posteriors using minimum energy designs.Technometrics, 61:297–308, 2019
2019
-
[48]
Katzfuss, J
M. Katzfuss, J. R. Stroud, and C. K. Wikle. Under- standing the ensemble Kalman filter.The American Statistician, 70(4):350–357, 2016
2016
-
[49]
Kazashi and F
Y . Kazashi and F. Nobile. Density estimation in RKHS with application to Korobov spaces in high dimen- sions.SIAM Journal on Numerical Analysis, 61(2): 1080–1102, 2023
2023
-
[50]
P. E. Kloeden and R. Pearson. The numerical solu- tion of stochastic differential equations.The ANZIAM Journal, 20(1):8–12, 1977
1977
-
[51]
Korba, P.-C
A. Korba, P.-C. Aubin-Frankowski, S. Majewski, and P. Ablin. Kernel Stein discrepancy descent. InIn- ternational Conference on Machine Learning, pages 5719–5730. PMLR, 2021
2021
-
[52]
Predictive variational inference: Learn the predictively optimal posterior distribution
J. Lai and Y . Yao. Predictive variational inference: Learn the predictively optimal posterior distribution. arXiv preprint arXiv:2410.14843, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Lasry and P.-L
J.-M. Lasry and P.-L. Lions. Mean field games. Japanese Journal of Mathematics, 2(1):229–260, 2007
2007
-
[54]
L. Li, R. Dwivedi, and L. Mackey. Debiased distri- bution compression. InInternational Conference on Machine Learning, pages 27675–27731, 2024
2024
-
[55]
C. Liu, J. Zhuo, P. Cheng, R. Zhang, and J. Zhu. Un- derstanding and accelerating particle-based variational inference. InInternational Conference on Machine Learning, pages 4082–4092. PMLR, 2019
2019
-
[56]
G.-H. Liu, T. Chen, O. So, and E. Theodorou. Deep generalized Schr¨odinger bridge.Advances in Neural Information Processing Systems, 35:9374–9388, 2022
2022
-
[57]
Liu and D
Q. Liu and D. Wang. Stein variational gradient descent: A general purpose Bayesian inference algorithm.Ad- vances in Neural Information Processing Systems, 29, 2016
2016
-
[58]
Q. Liu, M. A. Fisher, Z. Shen, K. Tant, X. Zhao, A. Curtis, and C. J. Oates. Detecting model misspeci- fication in Bayesian inverse problems via variational gradient descent.arXiv preprint arXiv:2512.01667, 2025. 11 Thinned Mean Field Langevin Dynamics
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Mak and V
S. Mak and V . R. Joseph. Support points.The Annals of Statistics, 46(6A):2562–2592, 2018
2018
-
[60]
Masegosa
A. Masegosa. Learning under model misspecifica- tion: Applications to variational and ensemble meth- ods.Advances in Neural Information Processing Sys- tems, 2020
2020
-
[61]
Y . McLatchie, B.-E. Cherief-Abdellatif, D. T. Frazier, and J. Knoblauch. Predictively oriented posteriors. arXiv preprint arXiv:2510.01915, 2025
-
[62]
S. Mei, A. Montanari, and P.-M. Nguyen. A mean field view of the landscape of two-layer neural networks. Proceedings of the National Academy of Sciences, 115 (33):E7665–E7671, 2018
2018
-
[63]
W. R. Morningstar, A. Alemi, and J. V . Dillon. PACm- Bayes: Narrowing the empirical risk gap in the mis- specified Bayesian regime. InInternational Confer- ence on Artificial Intelligence and Statistics, pages 8270–8298. PMLR, 2022
2022
-
[64]
K. P. Murphy.Probabilistic Machine Learning: An Introduction. MIT Press, 2022
2022
-
[65]
R. M. Neal.Probabilistic inference using Markov chain Monte Carlo methods. Department of Computer Science, University of Toronto Toronto, ON, Canada, 1993
1993
-
[66]
A. Nitanda. Improved particle approximation error for mean field neural networks.Advances in Neural Information Processing Systems, 37:113823–113845, 2024
2024
-
[67]
Stochastic Particle Gradient Descent for Infinite Ensembles
A. Nitanda and T. Suzuki. Stochastic particle gra- dient descent for infinite ensembles.arXiv preprint arXiv:1712.05438, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[68]
Nitanda, D
A. Nitanda, D. Wu, and T. Suzuki. Convex analysis of the mean field Langevin dynamics. InInternational Conference on Artificial Intelligence and Statistics, pages 9741–9757. PMLR, 2022
2022
-
[69]
Nitanda, A
A. Nitanda, A. Lee, D. T. X. Kai, M. Sakaguchi, and T. Suzuki. Propagation of chaos for mean-field Langevin dynamics and its application to model en- semble. InInternational Conference on Machine Learning, 2025
2025
-
[70]
Paige, D
B. Paige, D. Sejdinovic, and F. Wood. Super-sampling with a reservoir. InConference on Uncertainty in Artificial Intelligence. AUAI Press, 2016
2016
-
[71]
Rainforth, C
T. Rainforth, C. Naesseth, F. Lindsten, B. Paige, J.-W. Vandemeent, A. Doucet, and F. Wood. Interacting particle Markov chain Monte Carlo. InInternational Conference on Machine Learning, pages 2616–2625. PMLR, 2016
2016
-
[72]
Y . Ren, E. Nichani, D. Wu, and J. D. Lee. Emergence and scaling laws in SGD learning of shallow neural networks.Advances in Neural Information Processing Systems, 2025
2025
-
[73]
Rotskoff and E
G. Rotskoff and E. Vanden-Eijnden. Trainability and accuracy of artificial neural networks: An interacting particle system approach.Communications on Pure and Applied Mathematics, 75(9):1889–1935, 2022
1935
-
[74]
Santambrogio.Optimal Transport for Applied Math- ematicians
F. Santambrogio.Optimal Transport for Applied Math- ematicians. Springer, 2015
2015
-
[75]
Z. Shen, J. Knoblauch, S. Power, and C. J. Oates. Prediction-centric uncertainty quantification via MMD. InThe 28th International Conference on Artificial In- telligence and Statistics, 2025
2025
-
[76]
Sheth and R
R. Sheth and R. Khardon. Pseudo-Bayesian learn- ing via direct loss minimization with applications to sparse Gaussian process models. InSymposium on Advances in Approximate Bayesian Inference, pages 1–18. PMLR, 2020
2020
-
[77]
Shetty, R
A. Shetty, R. Dwivedi, and L. Mackey. Distribution compression in near-linear time. InInternational Con- ference on Learning Representations, 2022
2022
-
[78]
Stein and W
V . Stein and W. Li. Accelerated Stein variational gra- dient flow. InInternational Conference on Geometric Science of Information, pages 80–90. Springer, 2025
2025
-
[79]
Steinwart and A
I. Steinwart and A. Christmann.Support vector ma- chines. Springer Science & Business Media, 2008
2008
-
[80]
Suzuki, D
T. Suzuki, D. Wu, and A. Nitanda. Convergence of mean-field Langevin dynamics: Time-space discretiza- tion, stochastic gradient, and variance reduction.Ad- vances in Neural Information Processing Systems, 36: 15545–15577, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.