AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation
Pith reviewed 2026-06-29 12:36 UTC · model grok-4.3
The pith
Self-organizing AI agent teams outperform prior single-agent methods in long-running scientific experiments under matched budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that a decentralized team of AI agents, which interpret a shared experimental state, self-organize around hypotheses, critique proposals before compute use, and share successes and failures, produces higher performance than single-agent or centrally planned approaches on three classes of scientific tasks.
What carries the argument
Self-organizing agent teams that form around hypotheses in a shared state with critique and knowledge sharing.
Load-bearing premise
The agents can reliably interpret shared experimental state, form effective self-organized teams, critique proposals before compute use, and share knowledge without coordination overhead or selection bias.
What would settle it
A replication on the BioML-Bench or ProteinGym tasks where the team-based approach yields no statistically significant improvement over the strongest single-agent baseline.
Figures



read the original abstract
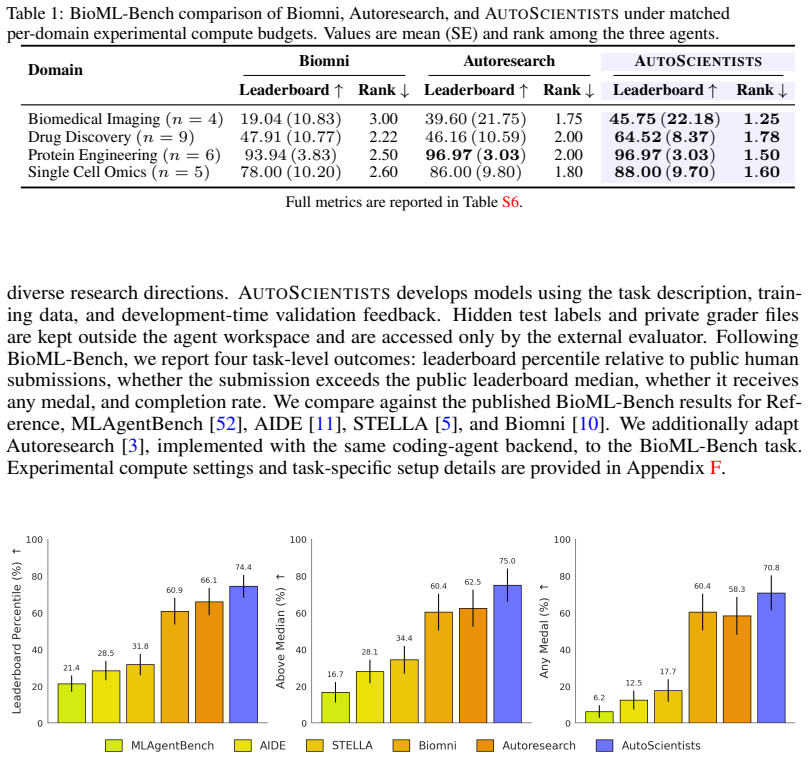
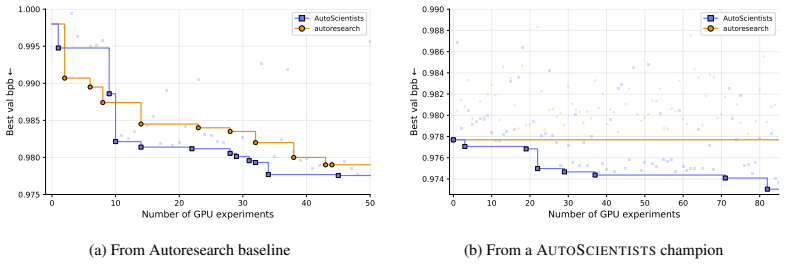
Scientific research proceeds through iterative cycles of hypothesis generation, experiment design, execution, and revision. AI agents can automate parts of this process, but existing approaches typically follow a single research trajectory or coordinate through a central planner with fixed objectives. As a result, they struggle to sustain parallel exploration, adapt as experimental evidence changes, or preserve knowledge of failed directions over long-running experiments. We introduce AutoScientists, a decentralized team of AI agents for long-running computational scientific experimentation. Agents interpret a shared experimental state, self-organize into teams around promising hypotheses, critique proposals before using experimental compute, and share successes and failures to reduce redundant exploration. Under matched experimental budgets, AutoScientists improves over prior AI agents across biomedical machine learning, language-model training optimization, and protein fitness prediction. On BioML-Bench, spanning biomedical imaging, protein engineering, single-cell omics, and drug discovery, AutoScientists achieves a mean leaderboard percentile of 74.4% across 24 tasks, improving over the strongest AI agent by +8.33%. On GPT training optimization, AutoScientists reaches a target validation bits-per-byte 1.9x faster than Autoresearch and continues discovering improvements from a starting champion where the single-agent approach finds none (7 vs. 0 accepted improvements). On ProteinGym fitness prediction, AutoScientists discovers a method for ACE2-Spike binding that improves over the current state-of-the-art model by +12.5% in Spearman correlation. Applied without modification across all 217 ProteinGym assays, the same method improves over the prior state of the art by +6.5% (Spearman correlation).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AutoScientists, a decentralized multi-agent system in which AI agents interpret a shared experimental state, self-organize around promising hypotheses, critique proposals before expending compute, and exchange successes and failures to reduce redundant exploration. It claims that, under matched experimental budgets, this approach outperforms prior single-agent and centrally planned baselines on three suites: BioML-Bench (mean leaderboard percentile 74.4% across 24 tasks, +8.33% over strongest prior agent), GPT training optimization (1.9× faster to target validation bits-per-byte and 7 vs. 0 accepted improvements), and ProteinGym (one assay +12.5% Spearman, 217 assays +6.5% Spearman).
Significance. If the reported gains can be shown to arise specifically from the self-organization and critique mechanisms under rigorously matched budgets, the work would provide concrete evidence that decentralized agent teams can sustain longer, less redundant scientific search trajectories than existing single-trajectory or centrally coordinated agents.
major comments (3)
- [Abstract] Abstract: the central claim that gains occur 'under matched experimental budgets' is load-bearing, yet the abstract supplies no protocol for budget accounting (token count, LLM calls, wall-clock time, or proposal count). Without this accounting it is impossible to attribute the 74.4% percentile, 1.9× speedup, or Spearman improvements to self-organization rather than unmatched total compute or prompting differences.
- [Abstract] Abstract: no ablation is described that removes the team self-organization, pre-compute critique, or knowledge-sharing layers while keeping total budget fixed. This omission prevents verification that the claimed mechanisms, rather than simply running more parallel trajectories, produce the observed deltas (7 vs. 0 improvements, +8.33% percentile).
- [Abstract] Abstract: the reported numbers (74.4% mean percentile, 1.9× speedup, +12.5% and +6.5% Spearman) are given without statistical tests, run-to-run variance, exact agent implementations, or data-exclusion rules. These omissions directly affect the soundness of the cross-benchmark superiority claim.
minor comments (1)
- [Abstract] The abstract lists three benchmark suites but does not name the precise tasks, the exact prior-agent baselines, or the leaderboard construction details needed to reproduce the percentile and Spearman figures.
Simulated Author's Rebuttal
We thank the referee for these constructive comments emphasizing experimental rigor. We address each point below and will revise the abstract and relevant sections accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that gains occur 'under matched experimental budgets' is load-bearing, yet the abstract supplies no protocol for budget accounting (token count, LLM calls, wall-clock time, or proposal count). Without this accounting it is impossible to attribute the 74.4% percentile, 1.9× speedup, or Spearman improvements to self-organization rather than unmatched total compute or prompting differences.
Authors: We agree that the abstract should explicitly state the budget-matching protocol. In the revision we will append the following sentence: 'Budgets are matched by equalizing the total number of LLM API calls and token consumption across methods, with full per-experiment accounting in Section 3.2; wall-clock time is not used as the primary metric owing to differences in parallelization.' This directly addresses attribution to the self-organization mechanisms. revision: yes
-
Referee: [Abstract] Abstract: no ablation is described that removes the team self-organization, pre-compute critique, or knowledge-sharing layers while keeping total budget fixed. This omission prevents verification that the claimed mechanisms, rather than simply running more parallel trajectories, produce the observed deltas (7 vs. 0 improvements, +8.33% percentile).
Authors: The full manuscript (Section 4.3 and supplementary ablations) already contains controlled ablations that remove self-organization, critique, and knowledge-sharing one at a time while holding the LLM-call budget fixed; each removal measurably degrades performance toward single-agent baselines. These results are not summarized in the abstract. We will add one sentence to the abstract referencing the ablation outcomes to make the mechanistic contribution explicit. revision: yes
-
Referee: [Abstract] Abstract: the reported numbers (74.4% mean percentile, 1.9× speedup, +12.5% and +6.5% Spearman) are given without statistical tests, run-to-run variance, exact agent implementations, or data-exclusion rules. These omissions directly affect the soundness of the cross-benchmark superiority claim.
Authors: We acknowledge that the abstract omits these details. The main text already reports standard deviations across the 24 BioML-Bench tasks and across the 217 ProteinGym assays, and the GPT optimization includes three independent trajectories. Exact agent prompts and code are released with the paper; data-exclusion rules (invalid or duplicate proposals) are described in Section 3.3. In revision we will insert a short clause in the abstract noting 'results averaged with reported standard deviations' and will add p-value comparisons where the number of replicates permits. revision: partial
Circularity Check
No circularity: empirical system with benchmark results only
full rationale
The paper introduces an agent architecture and reports empirical benchmark gains (74.4% mean percentile on BioML-Bench, 1.9x faster GPT convergence, +12.5% and +6.5% Spearman on ProteinGym) under the claim of matched budgets. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text. All load-bearing claims are external experimental comparisons rather than self-referential definitions or reductions to inputs by construction, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AI agents can reliably interpret a shared experimental state, self-organize into teams, critique proposals, and share knowledge to reduce redundancy
invented entities (1)
-
AutoScientists decentralized agent team
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Discovering Crystal Structure Prediction Algorithms with an AI Co-Scientist
HACO adapts MaskGIT from vision into MaskGXT with symmetry tokens and stratified sampling, reaching 79.06% METRe accuracy on MP-20 polymorph split versus 70.87% for the best baseline.
Reference graph
Works this paper leans on
-
[1]
Empow- ering biomedical discovery with ai agents.Cell, 187(22):6125–6151, 2024
Shanghua Gao, Ada Fang, Yepeng Huang, Valentina Giunchiglia, Ayush Noori, Jonathan Richard Schwarz, Yasha Ektefaie, Jovana Kondic, and Marinka Zitnik. Empow- ering biomedical discovery with ai agents.Cell, 187(22):6125–6151, 2024
2024
-
[2]
Miller, Matthew Greenig, Benjamin Tenmann, and Bo Wang
Henry E. Miller, Matthew Greenig, Benjamin Tenmann, and Bo Wang. BioML-bench: Eval- uation of AI agents for end-to-end biomedical ML.bioRxiv, 2025. doi: 10.1101/2025.09.01. 673319. URL https://www.biorxiv.org/content/early/2025/09/28/2025.09.01.673319. 10
-
[3]
Autoresearch: AI agents running research on single-GPU nanochat training automatically
Andrej Karpathy. Autoresearch: AI agents running research on single-GPU nanochat training automatically. https://github.com/karpathy/autoresearch, 2026. GitHub repository
2026
-
[4]
Kosmos: An AI Scientist for Autonomous Discovery
Ludovico Mitchener, Angela Yiu, Benjamin Chang, Mathieu Bourdenx, Tyler Nadolski, Arvis Sulovari, Eric C Landsness, Daniel L Barabasi, Siddharth Narayanan, Nicky Evans, et al. Kosmos: An AI scientist for autonomous discovery.arXiv preprint arXiv:2511.02824, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Stella: Towards a biomedical world model with self-evolving multimodal agents.bioRxiv, 2026
Ruofan Jin, Mingyang Xu, Fei Meng, Guancheng Wan, Qingran Cai, Yize Jiang, Jin Han, Yuanyuan Chen, Wanqing Lu, Mengyang Wang, Zhiqian Lan, Yuxuan Jiang, Junhong Liu, Dongyao Wang, Le Cong, and Zaixi Zhang. Stella: Towards a biomedical world model with self-evolving multimodal agents.bioRxiv, 2026. doi: 10.1101/2025.07.01.662467. URL https://www.biorxiv.or...
-
[6]
Shanghua Gao, Richard Zhu, Zhenglun Kong, Ayush Noori, Xiaorui Su, Curtis Ginder, Theodoros Tsiligkaridis, and Marinka Zitnik. Txagent: an ai agent for therapeutic reason- ing across a universe of tools.arXiv preprint arXiv:2503.10970, 2025
-
[7]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, et al. Towards an ai co-scientist. arXiv preprint arXiv:2502.18864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Ai mirrors experimental science to uncover a mechanism of gene transfer crucial to bacterial evolution
José R Penadés, Juraj Gottweis, Lingchen He, Jonasz B Patkowski, Alexander Daryin, Wei- Hung Weng, Tao Tu, Anil Palepu, Artiom Myaskovsky, Annalisa Pawlosky, et al. Ai mirrors experimental science to uncover a mechanism of gene transfer crucial to bacterial evolution. Cell, 188(23):6654–6665, 2025
2025
-
[9]
Pengwei Sui, Michelle M. Li, Shanghua Gao, Wanxiang Shen, Valentina Giunchiglia, Andrew Shen, Yepeng Huang, Zhenglun Kong, and Marinka Zitnik. Medea: An omics ai agent for therapeutic discovery.bioRxiv, 2026. doi: 10.64898/2026.01.16.696667. URL https: //www.biorxiv.org/content/early/2026/01/20/2026.01.16.696667
-
[10]
Biomni: A general-purpose biomedical AI agent
Kexin Huang, Serena Zhang, Hanchen Wang, Yuanhao Qu, Yingzhou Lu, Yusuf Roohani, Ryan Li, Lin Qiu, Gavin Li, Junze Zhang, et al. Biomni: A general-purpose biomedical AI agent. biorxiv, 2025
2025
-
[11]
AIDE: AI-Driven Exploration in the Space of Code
Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Ja- cenko, and Yuxiang Wu. AIDE: AI-driven exploration in the space of code.arXiv preprint arXiv:2502.13138, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Ao Qu, Han Zheng, Zijian Zhou, Yihao Yan, Yihong Tang, Shao Yong Ong, Fenglu Hong, Kaichen Zhou, Chonghe Jiang, Minwei Kong, et al. Coral: Towards autonomous multi-agent evolution for open-ended discovery.arXiv preprint arXiv:2604.01658, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Shiyang Feng, Runmin Ma, Xiangchao Yan, Yue Fan, Yusong Hu, Songtao Huang, Shuaiyu Zhang, Zongsheng Cao, Tianshuo Peng, Jiakang Yuan, et al. Internagent-1.5: A unified agentic framework for long-horizon autonomous scientific discovery.arXiv preprint arXiv:2602.08990, 2026
-
[14]
The virtual lab of ai agents designs new sars-cov-2 nanobodies.Nature, 646(8085):716–723, 2025
Kyle Swanson, Wesley Wu, Nash L Bulaong, John E Pak, and James Zou. The virtual lab of ai agents designs new sars-cov-2 nanobodies.Nature, 646(8085):716–723, 2025
2025
-
[15]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning, 2024
2024
-
[16]
ReConcile: Round-table conference improves reasoning via consensus among diverse LLMs, 2024
Justin Chih-Yao Chen, Swarnadeep Saha, and Mohit Bansal. ReConcile: Round-table conference improves reasoning via consensus among diverse LLMs, 2024. URL https: //arxiv.org/abs/2309.13007
-
[17]
Proteingym: Large-scale benchmarks for protein fitness prediction and design
Pascal Notin, Aaron Kollasch, Daniel Ritter, Lood van Niekerk, Steffanie Paul, Han Spinner, Nathan Rollins, Ada Shaw, Rose Orenbuch, Ruben Weitzman, Jonathan Frazer, Mafalda Dias, Dinko Franceschi, Yarin Gal, and Debora Marks. Proteingym: Large-scale benchmarks for protein fitness prediction and design. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Ha...
2023
-
[18]
Agentic AI for scientific discovery: A survey of progress, challenges, and future directions,
Mourad Gridach, Jay Nanavati, Khaldoun Zine El Abidine, Lenon Mendes, and Christina Mack. Agentic AI for scientific discovery: A survey of progress, challenges, and future directions,
- [19]
-
[20]
A vision for auto research with LLM agents, 2025
Chengwei Liu, Chong Wang, Jiayue Cao, Jingquan Ge, Kun Wang, Lyuye Zhang, Ming-Ming Cheng, Penghai Zhao, Tianlin Li, Xiaojun Jia, Xiang Li, Xingshuai Li, Yang Liu, Yebo Feng, Yihao Huang, Yijia Xu, Yuqiang Sun, Zhenhong Zhou, and Zhengzi Xu. A vision for auto research with LLM agents, 2025. URL https://arxiv.org/abs/2504.18765
-
[21]
Agent laboratory: Using LLM agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using LLM agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
2025
-
[22]
Jonathan Bragg, Mike D’Arcy, Nishant Balepur, Dan Bareket, Bhavana Dalvi, Sergey Feldman, Dany Haddad, Jena D. Hwang, Peter Jansen, Varsha Kishore, Bodhisattwa Prasad Majumder, Aakanksha Naik, Sigal Rahamimov, Kyle Richardson, Amanpreet Singh, Harshit Surana, Aryeh Tiktinsky, Rosni Vasu, Guy Wiener, Chloe Anastasiades, Stefan Candra, Jason Dunkelberger, D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
LMR-BENCH: Evaluating LLM agent’s ability on reproducing language modeling research,
Shuo Yan, Ruochen Li, Ziming Luo, Zimu Wang, Daoyang Li, Liqiang Jing, Kaiyu He, Peilin Wu, George Michalopoulos, Yue Zhang, Ziyang Zhang, Mian Zhang, Zhiyu Chen, and Xinya Du. LMR-BENCH: Evaluating LLM agent’s ability on reproducing language modeling research,
- [24]
-
[25]
Dechao Bu, Jingbo Sun, Kun Li, Zihao He, Wei Huang, Jinlin Hu, Shanshan Zhang, Shuang- shuang Lei, Peipei Huo, Zhihao Wang, et al. Empowering ai data scientists using a multi-agent llm framework with self-evolving capabilities for autonomous, tool-aware biomedical data analyses.Nature Biomedical Engineering, pages 1–16, 2026
2026
-
[26]
Ali Essam Ghareeb, Benjamin Chang, Ludovico Mitchener, Angela Yiu, Caralyn J Szostkiewicz, Jon M Laurent, Muhammed T Razzak, Andrew D White, Michaela M Hinks, and Samuel G Rodriques. Robin: A multi-agent system for automating scientific discovery.arXiv preprint arXiv:2505.13400, 2025
-
[27]
GenoMAS: A Multi-Agent Framework for Scientific Discovery via Code-Driven Gene Expression Analysis
Haoyang Liu, Yijiang Li, and Haohan Wang. GenoMAS: A multi-agent framework for scientific discovery via code-driven gene expression analysis.arXiv preprint arXiv:2507.21035, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Yingming Pu, Tao Lin, and Hongyu Chen. Piflow: Principle-aware scientific discovery with multi-agent collaboration.arXiv preprint arXiv:2505.15047, 2025
-
[29]
Scitoolagent: a knowledge-graph-driven scientific agent for multitool integration.Nature Computational Science, 5(10):962–972, 2025
Keyan Ding, Jing Yu, Junjie Huang, Yuchen Yang, Qiang Zhang, and Huajun Chen. Scitoolagent: a knowledge-graph-driven scientific agent for multitool integration.Nature Computational Science, 5(10):962–972, 2025
2025
-
[30]
Dong Han, Zhehong Ai, Pengxiang Cai, Shanya Lu, Jianpeng Chen, Zihao Ye, Shuzhou Sun, Ben Gao, Lingli Ge, Weida Wang, et al. ChemBOMAS: Accelerated BO in chemistry with LLM-enhanced multi-agent system.arXiv preprint arXiv:2509.08736, 2025
-
[31]
SR-scientist: Scientific equation discovery with agentic AI.arXiv preprint arXiv:2510.11661, 2025
Shijie Xia, Yuhan Sun, and Pengfei Liu. SR-scientist: Scientific equation discovery with agentic AI.arXiv preprint arXiv:2510.11661, 2025
-
[32]
SelfAI: A self-directed framework for long-horizon scientific discovery, 2025
Xiao Wu, Ting-Zhu Huang, Liang-Jian Deng, Xiaobing Yu, Yu Zhong, Shangqi Deng, Ufaq Khan, Jianghao Wu, Xiaofeng Liu, Imran Razzak, Xiaojun Chang, and Yutong Xie. SelfAI: A self-directed framework for long-horizon scientific discovery, 2025. URL https://arxiv.org/abs/ 2512.00403. 12
-
[33]
EvoScientist: Towards multi-agent evolving AI scientists for end-to-end scientific discovery, 2026
Yougang Lyu, Xi Zhang, Xinhao Yi, Yuyue Zhao, Shuyu Guo, Wenxiang Hu, Jan Piotrowski, Jakub Kaliski, Jacopo Urbani, Zaiqiao Meng, Lun Zhou, and Xiaohui Yan. EvoScientist: Towards multi-agent evolving AI scientists for end-to-end scientific discovery, 2026. URL https://arxiv.org/abs/2603.08127
-
[34]
CASCADE: Cumulative agentic skill creation through autonomous development and evolution
Xu Huang, Junwu Chen, Yuxing Fei, Zhuohan Li, Philippe Schwaller, and Gerbrand Ceder. CASCADE: Cumulative agentic skill creation through autonomous development and evolution. arXiv preprint arXiv:2512.23880, 2025
-
[35]
Towards end-to-end automation of ai research.Nature, 651(8107):914–919, 2026
Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Yamada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. Towards end-to-end automation of ai research.Nature, 651(8107):914–919, 2026
2026
-
[36]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. AlphaEvolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Language agents as optimizable graphs.arXiv preprint arXiv:2402.16823, 2024
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Language agents as optimizable graphs.arXiv preprint arXiv:2402.16823, 2024
-
[38]
On the resilience of LLM-based multi-agent collaboration with faulty agents
Jen tse Huang, Jiaxu Zhou, Tailin Jin, Xuhui Zhou, Zixi Chen, Wenxuan Wang, Youliang Yuan, Michael Lyu, and Maarten Sap. On the resilience of LLM-based multi-agent collaboration with faulty agents. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=bkiM54QftZ
2025
-
[39]
Can ai agents agree?arXiv preprint arXiv:2603.01213, 2026
Frédéric Berdoz, Leonardo Rugli, and Roger Wattenhofer. Can ai agents agree?arXiv preprint arXiv:2603.01213, 2026
-
[40]
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D. Nguyen. Multi-agent collaboration mechanisms: A survey of LLMs, 2025. URL https://arxiv.org/abs/2501.06322
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Yingxuan Yang, Chengrui Qu, Muning Wen, Laixi Shi, Ying Wen, Weinan Zhang, Adam Wierman, and Shangding Gu. Understanding agent scaling in LLM-based multi-agent systems via diversity.arXiv preprint arXiv:2602.03794, 2026
-
[42]
Towards a Science of Scaling Agent Systems
Yubin Kim, Ken Gu, Chanwoo Park, Chunjong Park, Samuel Schmidgall, A Ali Heydari, Yao Yan, Zhihan Zhang, Yuchen Zhuang, Mark Malhotra, et al. Towards a science of scaling agent systems.arXiv preprint arXiv:2512.08296, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Multi-Agent Teams Hold Experts Back
Aneesh Pappu, Batu El, Hancheng Cao, Carmelo di Nolfo, Yanchao Sun, Meng Cao, and James Zou. Multi-agent teams hold experts back.arXiv preprint arXiv:2602.01011, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
MultiAgentBench: Evaluating the collaboration and competition of LLM agents, 2025
Kunlun Zhu, Hongyi Du, Zhaochen Hong, Xiaocheng Yang, Shuyi Guo, Zhe Wang, Zhenhailong Wang, Cheng Qian, Xiangru Tang, Heng Ji, and Jiaxuan You. MultiAgentBench: Evaluating the collaboration and competition of LLM agents, 2025. URL https://arxiv.org/abs/2503.01935
-
[45]
Collaborative research across disciplinary and organi- zational boundaries.Social studies of science, 35(5):703–722, 2005
Jonathon N Cummings and Sara Kiesler. Collaborative research across disciplinary and organi- zational boundaries.Social studies of science, 35(5):703–722, 2005
2005
-
[46]
The increasing dominance of teams in production of knowledge.Science, 316(5827):1036–1039, 2007
Stefan Wuchty, Benjamin F Jones, and Brian Uzzi. The increasing dominance of teams in production of knowledge.Science, 316(5827):1036–1039, 2007
2007
-
[47]
Flat teams drive scientific innovation.Proceedings of the National Academy of Sciences, 119(23):e2200927119, 2022
Fengli Xu, Lingfei Wu, and James Evans. Flat teams drive scientific innovation.Proceedings of the National Academy of Sciences, 119(23):e2200927119, 2022
2022
-
[48]
The science of team science: A review of the empirical evidence and research gaps on collaboration in science.American psychologist, 73(4):532, 2018
Kara L Hall, Amanda L V ogel, Grace C Huang, Katrina J Serrano, Elise L Rice, Sophia P Tsakraklides, and Stephen M Fiore. The science of team science: A review of the empirical evidence and research gaps on collaboration in science.American psychologist, 73(4):532, 2018. 13
2018
-
[49]
Xinyu Zhu, Yuzhu Cai, Zexi Liu, Bingyang Zheng, Cheng Wang, Rui Ye, Jiaao Chen, Han- rui Wang, Wei-Chen Wang, Yuzhi Zhang, et al. Toward ultra-long-horizon agentic science: Cognitive accumulation for machine learning engineering.arXiv preprint arXiv:2601.10402, 2026
-
[50]
Emergent Coordination in Multi-Agent Language Models
Christoph Riedl. Emergent coordination in multi-agent language models.arXiv preprint arXiv:2510.05174, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Model cards for model reporting
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchin- son, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. InProceedings of the conference on fairness, accountability, and transparency, pages 220–229, 2019
2019
-
[52]
Claude Code: Overview
Anthropic. Claude Code: Overview. https://code.claude.com/docs/en/overview, 2026. Product documentation. Accessed: 2026-05-06
2026
-
[53]
Claude Sonnet 4.6
Anthropic. Claude Sonnet 4.6. https://www.anthropic.com/claude/sonnet, 2026. Model documentation. Model ID:claude-sonnet-4-6. Accessed: 2026-05-06
2026
-
[54]
Qian Huang, Jian V ora, Percy Liang, and Jure Leskovec. Mlagentbench: Evaluating language agents on machine learning experimentation.arXiv preprint arXiv:2310.03302, 2023
-
[55]
Kermut: Composite kernel regression for protein variant effects
Peter Mø rch Groth, Mads Herbert Kerrn, Lars Olsen, Jesper Salomon, and Wouter Boomsma. Kermut: Composite kernel regression for protein variant effects. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 29514–29565. Curran Associates, Inc., 2024...
-
[56]
S. L. Lee, P. Yadav, Y . Li, J. J. Meudt, J. Strang, D. Hebel, A. Alfson, S. J. Olson, T. R. Kruser, J. B. Smilowitz, K. Borchert, B. Loritz, L. Gharzai, S. Karimpour, J. Bayouth, and M. F. Bassetti. Uw-madison gi tract image segmentation. https://kaggle.com/competitions/ uw-madison-gi-tract-image-segmentation, 2022. Kaggle
2022
-
[57]
Osic pulmonary fibrosis progression
Ahmed Shahin, Carmela Wegworth, David, Elizabeth Estes, Julia Elliott, Justin Zita, Si- monWalsh, Slepetys, and Will Cukierski. Osic pulmonary fibrosis progression. https: //kaggle.com/competitions/osic-pulmonary-fibrosis-progression, 2020. Kaggle
2020
-
[58]
Histopathologic cancer detection
Will Cukierski. Histopathologic cancer detection. https://kaggle.com/competitions/ histopathologic-cancer-detection, 2018. Kaggle
2018
-
[59]
Rsna-miccai brain tumor radiogenomic classification
Adam Flanders, Chris Carr, Evan Calabrese, PhD FelipeKitamura, MD, inversion, JeffRudie, John Mongan, Julia Elliott, Luciano Prevedello, Michelle Riopel, sprint, Spyridon Bakas, and Ujjwal. Rsna-miccai brain tumor radiogenomic classification. https://kaggle.com/competitions/ rsna-miccai-brain-tumor-radiogenomic-classification, 2021. Kaggle
2021
-
[60]
Kexin Huang, Tianfan Fu, Wenhao Gao, Yue Zhao, Yusuf Roohani, Jure Leskovec, Connor W Coley, Cao Xiao, Jimeng Sun, and Marinka Zitnik. Therapeutics data commons: Machine learn- ing datasets and tasks for drug discovery and development.arXiv preprint arXiv:2102.09548, 2021
-
[61]
Polaris: The benchmarking platform for drug discovery
Polaris. Polaris: The benchmarking platform for drug discovery. https://polarishub.io/, 2026. Accessed: May 2026
2026
-
[62]
Defining and benchmarking open problems in single-cell analysis.Nature Biotechnology, 43(7):1035– 1040, 2025
Malte D Luecken, Scott Gigante, Daniel B Burkhardt, Robrecht Cannoodt, Daniel C Strobl, Nikolay S Markov, Luke Zappia, Giovanni Palla, Wesley Lewis, Daniel Dimitrov, et al. Defining and benchmarking open problems in single-cell analysis.Nature Biotechnology, 43(7):1035– 1040, 2025
2025
-
[63]
Evolutionary-scale prediction of atomic-level protein structure with a language model.Science, 379(6637):1123–1130, 2023
Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, Robert Verkuil, Ori Kabeli, Yaniv Shmueli, et al. Evolutionary-scale prediction of atomic-level protein structure with a language model.Science, 379(6637):1123–1130, 2023. 14
2023
-
[64]
Robust deep learning–based protein sequence design using proteinmpnn.Science, 378(6615):49–56, 2022
Justas Dauparas, Ivan Anishchenko, Nathaniel Bennett, Hua Bai, Robert J Ragotte, Lukas F Milles, Basile IM Wicky, Alexis Courbet, Rob J de Haas, Neville Bethel, et al. Robust deep learning–based protein sequence design using proteinmpnn.Science, 378(6615):49–56, 2022
2022
-
[65]
Seyone Chithrananda, Gabriel Grand, and Bharath Ramsundar. Chemberta: large-scale self- supervised pretraining for molecular property prediction.arXiv preprint arXiv:2010.09885, 2020
-
[66]
Chemprop: a machine learning package for chemical property prediction.Journal of chemical information and modeling, 64 (1):9–17, 2024
Esther Heid, Kevin P Greenman, Yunsie Chung, Shih-Cheng Li, David E Graff, Florence H Vermeire, Haoyang Wu, William H Green, and Charles J McGill. Chemprop: a machine learning package for chemical property prediction.Journal of chemical information and modeling, 64 (1):9–17, 2024
2024
-
[67]
https://www.rdkit.org, 2026
RDKit: Open-source cheminformatics. https://www.rdkit.org, 2026. Accessed: May 2026
2026
-
[68]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, pages 785–794, New York, NY , USA, 2016. ACM. ISBN 978-1-4503-4232-2. doi: 10.1145/2939672.2939785. URL http://doi.acm.org/10.1145/2939672.2939785
-
[69]
Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems, 30, 2017
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems, 30, 2017
2017
-
[70]
CatBoost: gradient boosting with categorical features support
Anna Veronika Dorogush, Vasily Ershov, and Andrey Gulin. Catboost: gradient boosting with categorical features support.arXiv preprint arXiv:1810.11363, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[71]
Efficientnet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. InInternational conference on machine learning, pages 6105–6114. PMLR, 2019
2019
-
[72]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[73]
Masked inverse folding with sequence transfer for protein representation learning.Protein Engineering, Design and Selection, 36: gzad015, 2023
Kevin K Yang, Niccolò Zanichelli, and Hugh Yeh. Masked inverse folding with sequence transfer for protein representation learning.Protein Engineering, Design and Selection, 36: gzad015, 2023
2023
-
[74]
Yang Tan, Ruilin Wang, Banghao Wu, Liang Hong, and Bingxin Zhou. From high-throughput evaluation to wet-lab studies: advancing mutation effect prediction with a retrieval-enhanced model.Bioinformatics, 41(Supplement 1):i401–i409, 07 2025. doi: 10.1093/bioinformatics/ btaf189. URL https://doi.org/10.1093/bioinformatics/btaf189
-
[75]
Prosst: Protein language modeling with quantized structure and disentangled attention.Advances in Neural Information Processing Systems, 37: 35700–35726, 2024
Mingchen Li, Yang Tan, Xinzhu Ma, Bozitao Zhong, Huiqun Yu, Ziyi Zhou, Wanli Ouyang, Bingxin Zhou, Pan Tan, and Liang Hong. Prosst: Protein language modeling with quantized structure and disentangled attention.Advances in Neural Information Processing Systems, 37: 35700–35726, 2024
2024
-
[76]
Residue conser- vation and solvent accessibility are (almost) all you need for predicting mutational effects in proteins.Bioinformatics, 41(6):btaf322, 2025
Matsvei Tsishyn, Pauline Hermans, Marianne Rooman, and Fabrizio Pucci. Residue conser- vation and solvent accessibility are (almost) all you need for predicting mutational effects in proteins.Bioinformatics, 41(6):btaf322, 2025
2025
-
[77]
Prescott: a population aware, epistatic, and structural model accurately predicts missense effects.Genome Biology, 26(1):113, 2025
Mustafa Tekpinar, Laurent David, Thomas Henry, and Alessandra Carbone. Prescott: a population aware, epistatic, and structural model accurately predicts missense effects.Genome Biology, 26(1):113, 2025
2025
-
[78]
xtrimopglm: unified 100-billion-parameter pretrained transformer for deciphering the language of proteins.Nature Methods, 22(5):1028–1039, 2025
Bo Chen, Xingyi Cheng, Pan Li, Yangli-ao Geng, Jing Gong, Shen Li, Zhilei Bei, Xu Tan, Boyan Wang, Xin Zeng, et al. xtrimopglm: unified 100-billion-parameter pretrained transformer for deciphering the language of proteins.Nature Methods, 22(5):1028–1039, 2025
2025
-
[79]
Saprot: Protein language modeling with structure-aware vocabulary
Jin Su, Chenchen Han, Yuyang Zhou, Junjie Shan, Xibin Zhou, and Fajie Yuan. Saprot: Protein language modeling with structure-aware vocabulary. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=6MRm3G4NiU. 15
2024
-
[80]
Learning inverse folding from millions of predicted structures
Chloe Hsu, Robert Verkuil, Jason Liu, Zeming Lin, Brian Hie, Tom Sercu, Adam Lerer, and Alexander Rives. Learning inverse folding from millions of predicted structures. InInternational conference on machine learning, pages 8946–8970. PMLR, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.