TRACER: Turn-level Regret Matching with Inner Reinforcement Credit for Cooperative Multi-LLM Reasoning
Pith reviewed 2026-06-29 12:17 UTC · model grok-4.3
The pith
TRACER lets multiple LLMs learn when to speak and what to say by pairing regret-matching controllers with utterance-level credit assignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
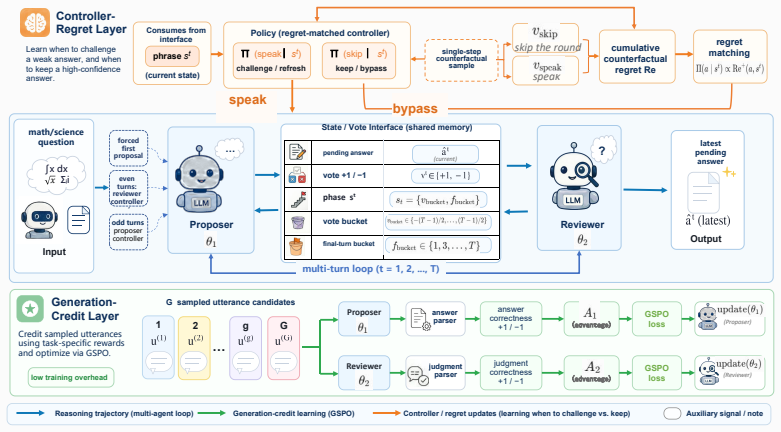
TRACER separates collaborative decision making into a controller-regret layer, where controllers learn whether the agents should speak or skip the current round through regret matching, and a generation-credit layer, which optimizes proposer and reviewer utterances with role-specific GSPO rewards. This design assigns credit at the level of both action modes and generated utterances, thus avoiding free-riding and sparse rewards while greatly reducing computational cost of training by only expanding the choices made by the controllers. Agents acquire collaborative capability as they learn when to utter and what to speak. By designing binary actions ingeniously, the approach extends classical g
What carries the argument
The controller-regret layer with regret matching on binary speak/skip actions combined with the generation-credit layer that applies role-specific GSPO rewards to utterances.
If this is right
- Credit assignment at both mode and utterance levels removes role-level free-riding and sparse-reward problems.
- Computational cost drops because only controller choices are expanded during training.
- Agents develop the ability to decide both when to contribute and what content to produce.
- Binary action design yields mathematically rigorous convergence guarantees from classical game theory.
- The resulting system supplies a testbed for learned collaboration policies on held-out math benchmarks.
Where Pith is reading between the lines
- The same controller-plus-utterance split could be tested on non-math collaborative tasks such as code review or scientific hypothesis generation.
- Convergence claims may allow scaling the number of participating LLMs without the instability seen in fixed multi-agent protocols.
- The binary action restriction might be relaxed in future work while preserving the regret-matching backbone.
- Evaluation across GSM8K, MATH500, and GPQA-Diamond suggests the learned policies transfer better than imitation-based collaboration.
Load-bearing premise
Binary speak-or-skip controller actions paired with GSPO rewards will avoid free-riding, oscillation, and deliver mathematically rigorous convergence when applied to multi-turn LLM generation.
What would settle it
Training runs on GSM8K that show persistent free-riding, continued oscillation between fixed protocols, or lack of convergence matching regret-matching theory after the reported training steps.
Figures
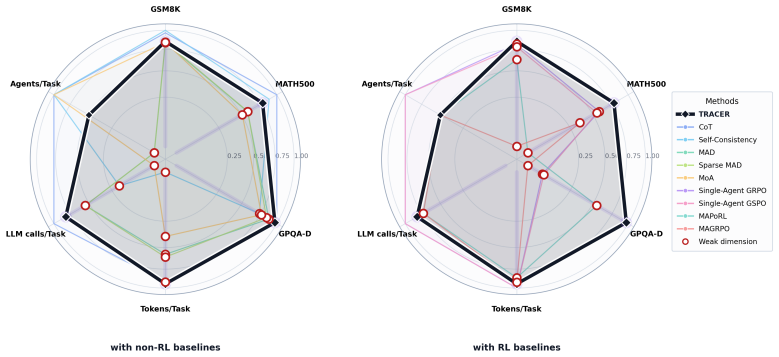
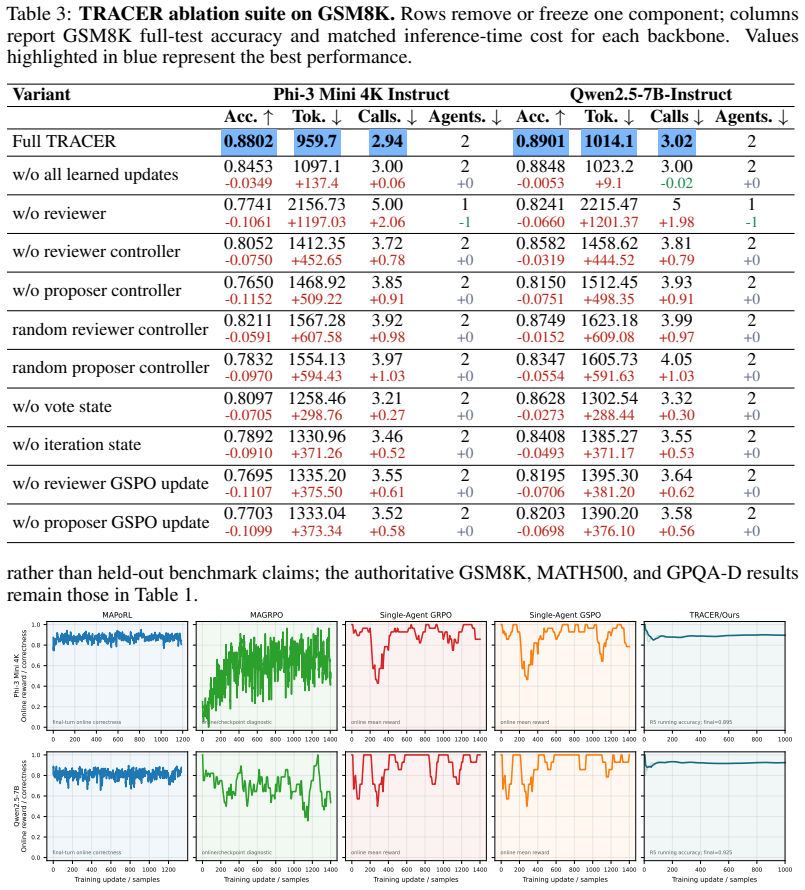
read the original abstract
Large language models increasingly rely on either reinforcement learning or multi-agent prompting to improve reasoning, yet these two paradigms remain difficult to combine. Directly applying single-agent reinforcement learning to multi-turn multi-agent systems faces following dilemmas: i) Sparse rewards, role-level free-riding and excessive training overhead. ii) Agents only imitate to collaborate. iii) Fixed collaboration protocol falls into oscillating local optimum. We introduce TRACER, a turn-level reinforcement framework for cooperative multi-LLM reasoning. TRACER separates collaborative decision making into a controller-regret layer, where controllers learn whether the agents should speak or skip the current round through regret matching, and a generation-credit layer, which optimizes proposer and reviewer utterances with role-specific GSPO rewards. This design i) assigns credit at the level of both action modes and generated utterances, thus avoiding free-riding and sparse rewards. We only expand the choices made by the controllers, thus greatly reducing computational cost of training. Moreover, ii) agents acquire collaborative capability as they learn when to utter and what to speak. Finally, iii) by designing binary actions ingeniously, we extend classical game theory established for finite action spaces to deep learning, thus achieving mathematically rigorous convergence. We train all local RL-style methods on the GSM8K training split and evaluate on held-out GSM8K, MATH500, and GPQA-Diamond to measure in-domain accuracy, cross-benchmark generalization, inference cost, and correction-preservation behavior. The resulting framework provides a compact and reproducible testbed for studying learned collaboration policies beyond fixed debate, voting, or aggregation protocols. Code is available at https://github.com/Shark-Forest/TRACER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TRACER, a turn-level reinforcement framework for cooperative multi-LLM reasoning. It separates collaborative decision making into a controller-regret layer (binary speak/skip actions learned via regret matching) and a generation-credit layer (optimizing proposer/reviewer utterances via role-specific GSPO rewards). The design is claimed to assign credit at both action-mode and utterance levels (avoiding free-riding and sparse rewards while reducing training cost), enable agents to learn when and what to utter, and achieve mathematically rigorous convergence by using binary actions to extend classical finite-action game theory to deep learning. Experiments train on the GSM8K training split and evaluate on held-out GSM8K, MATH500, and GPQA-Diamond for accuracy, generalization, inference cost, and correction-preservation behavior, with code released.
Significance. If the credit-assignment and convergence claims hold, TRACER could offer a reproducible testbed for learned multi-agent collaboration policies that combine regret matching with LLM generation, potentially reducing overhead compared to full multi-agent RL while improving on fixed protocols. The code release supports reproducibility. Significance is currently limited by the absence of any derivations or results verifying the extension of regret-matching guarantees.
major comments (2)
- [Abstract] Abstract, claim (iii): The assertion that 'by designing binary actions ingeniously, we extend classical game theory established for finite action spaces to deep learning, thus achieving mathematically rigorous convergence' is load-bearing but unsupported. Standard external-regret bounds for regret matching apply only when all action spaces (including payoffs) are finite; the generation-credit layer still optimizes over LLM token sequences (effectively infinite discrete actions) via GSPO rewards. No reduction, approximation, or modified analysis is described that would transfer the finite-game guarantees (e.g., convergence to coarse correlated equilibrium) to the utterance layer. This directly affects the claimed avoidance of oscillation and free-riding.
- [Abstract] Abstract: No equations, update rules, or interaction details are given for the regret-matching controller or the GSPO reward formulation. Without these, it is impossible to verify whether credit is truly assigned at both action-mode and utterance levels or whether the binary-controller restriction actually reduces computational cost while preserving the claimed properties. These mechanisms are central to claims (i) and (ii).
minor comments (2)
- [Abstract] The acronym 'GSPO' is introduced without expansion or reference; define it and briefly state how the rewards are computed.
- [Abstract] The phrase 'we only expand the choices made by the controllers' is imprecise; clarify what 'expand' means in the context of the two-layer architecture.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying ambiguities in the abstract. We address each major comment below, agreeing where the claims require qualification or clarification, and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract, claim (iii): The assertion that 'by designing binary actions ingeniously, we extend classical game theory established for finite action spaces to deep learning, thus achieving mathematically rigorous convergence' is load-bearing but unsupported. Standard external-regret bounds for regret matching apply only when all action spaces (including payoffs) are finite; the generation-credit layer still optimizes over LLM token sequences (effectively infinite discrete actions) via GSPO rewards. No reduction, approximation, or modified analysis is described that would transfer the finite-game guarantees (e.g., convergence to coarse correlated equilibrium) to the utterance layer. This directly affects the claimed avoidance of oscillation and free-riding.
Authors: We agree the abstract phrasing is imprecise and overstates the scope. The binary-action regret-matching analysis and associated finite-game convergence guarantees apply only to the controller-regret layer (speak/skip decisions). The generation-credit layer uses separate GSPO optimization over token sequences and carries no such claim. The manuscript contains no explicit reduction or transfer proof between layers. We will revise the abstract to remove the broad claim and state only that binary actions in the controller enable standard regret-matching application for that component. revision: yes
-
Referee: [Abstract] Abstract: No equations, update rules, or interaction details are given for the regret-matching controller or the GSPO reward formulation. Without these, it is impossible to verify whether credit is truly assigned at both action-mode and utterance levels or whether the binary-controller restriction actually reduces computational cost while preserving the claimed properties. These mechanisms are central to claims (i) and (ii).
Authors: The abstract was written at a high level, but we accept that this prevents verification of the dual-layer credit assignment and cost reduction. The full manuscript defines regret matching on binary controller actions and role-specific GSPO rewards for the generation layer. We will expand the abstract (or add a short paragraph in the introduction) with the key update rules and layer interaction to make these properties explicit. revision: yes
Circularity Check
No circularity: convergence claim asserted without exhibited derivation or self-referential reduction
full rationale
The provided manuscript text (abstract plus placeholder for full text) contains no equations, no explicit derivation steps, and no self-citations that reduce the central convergence claim to fitted parameters or prior author results. The statement that binary speak/skip actions extend regret matching to yield mathematically rigorous convergence is presented as a design consequence rather than derived via a chain that loops back to its own inputs. No load-bearing step matches any of the enumerated circularity patterns; the paper therefore remains self-contained against external benchmarks for the purpose of this analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Viet Bui, Tien Mai, and Hong Thanh Nguyen. Preference-guided learning for sparse- reward multi-agent reinforcement learning.arXiv preprint arXiv:2509.21828, 2025. doi: 10.48550/arXiv.2509.21828. URLhttps://arxiv.org/abs/2509.21828
-
[2]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 11733–11763. PMLR, 2024. URL https://proceedings.mlr. press/v235...
2024
-
[3]
Group-in-group policy optimization for LLM agent training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for LLM agent training. InAdvances in Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=QXEhBMNrCW
2025
-
[4]
Counterfactual multi-agent policy gradients
Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. InProceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018. doi: 10.1609/aaai.v32i1.11794. URL https://ojs.aaai. org/index.php/AAAI/article/view/11794
-
[5]
Sven Gronauer and Klaus Diepold. Multi-agent deep reinforcement learning: A survey.Artificial Intelligence Review, 55(2):895–943, 2022. doi: 10.1007/s10462-021-09996-w. URL https: //link.springer.com/article/10.1007/s10462-021-09996-w
-
[7]
A simple adaptive procedure leading to corre- lated equilibrium.Econometrica, 68(5):1127–1150, 2000
Sergiu Hart and Andreu Mas-Colell. A simple adaptive procedure leading to corre- lated equilibrium.Econometrica, 68(5):1127–1150, 2000. doi: 10.1111/1468-0262. 00153. URL https://www.econometricsociety.org/publications/econometrica/ 2000/09/01/simple-adaptive-procedure-leading-correlated-equilibrium
-
[8]
Multi-agent counterfactual regret minimiza- tion for partial-information collaborative games
Matthew Hartley, Stephan Zheng, and Yisong Yue. Multi-agent counterfactual regret minimiza- tion for partial-information collaborative games. InNIPS 2017 Workshop on Learning in the Presence of Strategic Behavior, 2017. URL https://people.eecs.berkeley.edu/~nika/ mlstrat/
2017
-
[9]
MetaGPT: Meta programming for A multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for A multi-agent collaborative framework. InInternational Conference on Learning Represen- tations, 2024. URL htt...
2024
-
[10]
Value- based deep multi-agent reinforcement learning with dynamic sparse train- ing
Pihe Hu, Shaolong Li, Zhuoran Li, Ling Pan, and Longbo Huang. Value- based deep multi-agent reinforcement learning with dynamic sparse train- ing. InAdvances in Neural Information Processing Systems, volume 37, 2024. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 31888563b194f9bb33ce1aebc7e1551c-Abstract-Conference.html
2024
-
[11]
Multi-agent reinforcement learning: A comprehensive survey.arXiv preprint arXiv:2312.10256, 2023
Dom Huh and Prasant Mohapatra. Multi-agent reinforcement learning: A comprehensive survey.arXiv preprint arXiv:2312.10256, 2023. doi: 10.48550/arXiv.2312.10256. URL https://arxiv.org/abs/2312.10256
-
[12]
CAMEL: Communicative agents for "mind" exploration of large language model so- ciety
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for "mind" exploration of large language model so- ciety. InAdvances in Neural Information Processing Systems, volume 36, pages 51991–52008, 2023. URL https://proceedings.neurips.cc/paper/2023/hash/ a3621ee907def47c1b952ade25c67698-Abstract-Conference...
2023
-
[13]
Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. A survey on LLM-based multi- agent systems: Workflow, infrastructure, and challenges.Vicinagearth, 1(1):9, 2024. doi: 10.1007/s44336-024-00009-2. URL https://link.springer.com/article/10.1007/ s44336-024-00009-2
-
[14]
Improving multi-agent debate with sparse communication topology
Yunxuan Li, Yibing Du, Jiageng Zhang, Le Hou, Peter Grabowski, Yeqing Li, and Eugene Ie. Improving multi-agent debate with sparse communication topology. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7281–7294. Association for Computational Linguistics, 2024. doi: 10.18653/v1/2024.findings-emnlp.427. URL https: //aclanthol...
-
[15]
Boyin Liu, Zhiqiang Pu, Yi Pan, Jianqiang Yi, Yanyan Liang, and D. Zhang. Lazy agents: A new perspective on solving sparse reward problem in multi-agent reinforcement learning. InProceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 21937–21950. PMLR, 2023. URL https: //proceedi...
2023
-
[16]
Maximum entropy heterogeneous-agent reinforcement learning
Jiarong Liu, Yifan Zhong, Siyi Hu, Haobo Fu, Qiang Fu, Xiaojun Chang, and Yaodong Yang. Maximum entropy heterogeneous-agent reinforcement learning. InInternational Conference on Learning Representations, 2024. URL https://proceedings.iclr.cc/paper_files/ paper/2024/hash/fe066022bab2a6c6a3c57032a1623c70-Abstract-Conference. html
2024
-
[17]
Keliang Liu, Dingkang Yang, Ziyun Qian, Weijie Yin, Yuchi Wang, Hongsheng Li, Jun Liu, Peng Zhai, Yang Liu, and Lihua Zhang. Reinforcement learning meets large language mod- els: A survey of advancements and applications across the LLM lifecycle.arXiv preprint arXiv:2509.16679, 2025. doi: 10.48550/arXiv.2509.16679. URL https://arxiv.org/abs/ 2509.16679
-
[18]
LLM collaboration with multi-agent reinforcement learning.arXiv preprint arXiv:2508.04652, 2025
Shuo Liu, Tianle Chen, Zeyu Liang, Xueguang Lyu, and Christopher Amato. LLM collaboration with multi-agent reinforcement learning.arXiv preprint arXiv:2508.04652, 2025. doi: 10. 48550/arXiv.2508.04652. URLhttps://arxiv.org/abs/2508.04652
-
[19]
Training language models to follow instructions with hu- man feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Chris- tiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with hu- man feedb...
2022
-
[20]
Ozdaglar, Kaiqing Zhang, and Joo- Kyung Kim
Chanwoo Park, Seungju Han, Xingzhi Guo, Asuman E. Ozdaglar, Kaiqing Zhang, and Joo- Kyung Kim. MAPoRL: Multi-agent post-co-training for collaborative large language models with reinforcement learning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30215–30248. Association for Comput...
-
[21]
ChatDev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15174– 15186, 2...
-
[22]
Jordan, and Philipp Moritz
John Schulman, Sergey Levine, Pieter Abbeel, Michael I. Jordan, and Philipp Moritz. Trust region policy optimization. InProceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 1889–1897. PMLR,
-
[23]
URLhttps://proceedings.mlr.press/v37/schulman15.html
-
[24]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. doi: 10.48550/arXiv. 1707.06347. URLhttps://arxiv.org/abs/1707.06347. 11
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2017
-
[25]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. doi: 10.48550/arXiv.2402.03300. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[26]
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduc- tion. The MIT Press, 1998. URL https://mitpress.mit.edu/9780262193986/ reinforcement-learning/
-
[27]
Sutton, David A
Richard S. Sutton, David A. McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. InAdvances in Neural Information Processing Systems, volume 12, 1999. URL https://papers.nips.cc/paper_ files/paper/1999/hash/464d828b85b0bed98e80ade0a5c43b0f-Abstract.html
1999
-
[28]
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D. Nguyen. Multi-agent collaboration mechanisms: A survey of LLMs.arXiv preprint arXiv:2501.06322, 2025. doi: 10.48550/arXiv.2501.06322. URL https://arxiv.org/abs/ 2501.06322
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.06322 2025
-
[29]
Mixture-of-agents enhances large language model capabilities
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities. InInternational Conference on Learning Represen- tations, 2025. URLhttps://openreview.net/forum?id=h0ZfDIrj7T
2025
-
[30]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations, 2023. URL https:// openreview.net/forum?id=1PL1NIMMrw
2023
-
[31]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large lan- guage models. InAdvances in Neural Information Processing Systems, volume 35, pages 24824–24837, 2022. URL https://proceedings.neurips.cc/paper_files/paper/ 2022/hash/9d5609613524...
2022
-
[32]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. doi: 10.48550/arXiv.2507.18071. URL https://arxiv.org/abs/2507.18071
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.18071 2025
-
[33]
intermediate aggregater
Martin Zinkevich, Michael Johanson, Michael Bowling, and Carmelo Piccione. Regret mini- mization in games with incomplete information. InAdvances in Neural Information Processing Systems, volume 20, pages 1729–1736, 2007. URL https://papers.nips.cc/paper_ files/paper/2007/hash/08d98638c6fcd194a4b1e6992063e944-Abstract.html. Appendix Contents Appendix A Ex...
2007
-
[34]
Players: proposer’s controller u1 and reviewer’s controlleru2, corresponding to the two players in classic CFR
-
[35]
Round mechanism: finite T rounds of interaction, with agents speaking alternately, pro- poser’s controller first
-
[36]
Other- wise, the proposer’s controller decides whether to invoke the proposer to generate a new answer or skip the round
Role division: • Odd rounds: When there is no pending answer, the proposer is forced to speak. Other- wise, the proposer’s controller decides whether to invoke the proposer to generate a new answer or skip the round. • Even rounds: the reviewer’s controller determines whether to invoke the reviewer
-
[37]
Information structure: given a prompt x∼ D , each agent observes different structured information. D.3.2 Correspondence Table Classic CFR Concept Corresponding TRACER Concept Players 1, 2 proposer’s controlleru 1, reviewer’s controlleru2 Information setI∈ I i Observation state containing problem, role description, and structured information Behavioral str...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.