Stage-wise Distortion-Perception Traversal in Zero-shot Inverse Problems with Diffusion Models
Pith reviewed 2026-06-29 13:27 UTC · model grok-4.3
The pith
A two-stage diffusion method achieves flexible distortion-perception traversal in zero-shot inverse problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
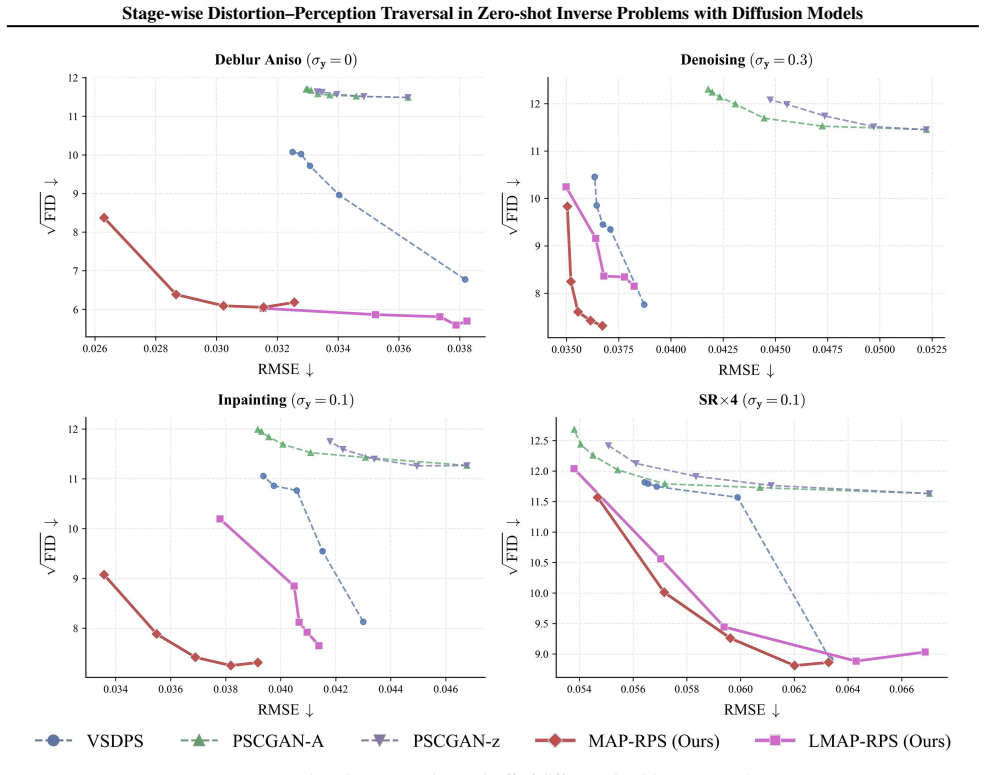
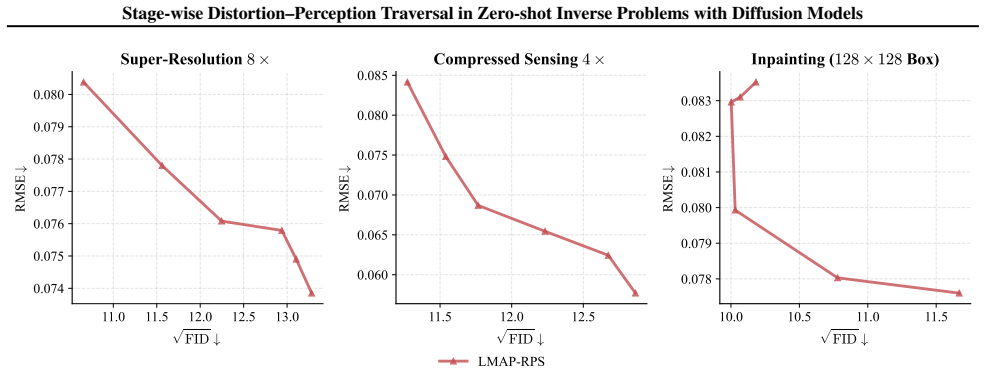
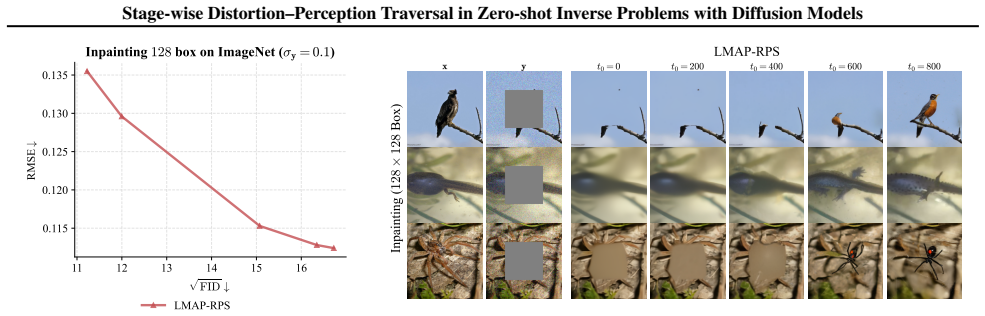
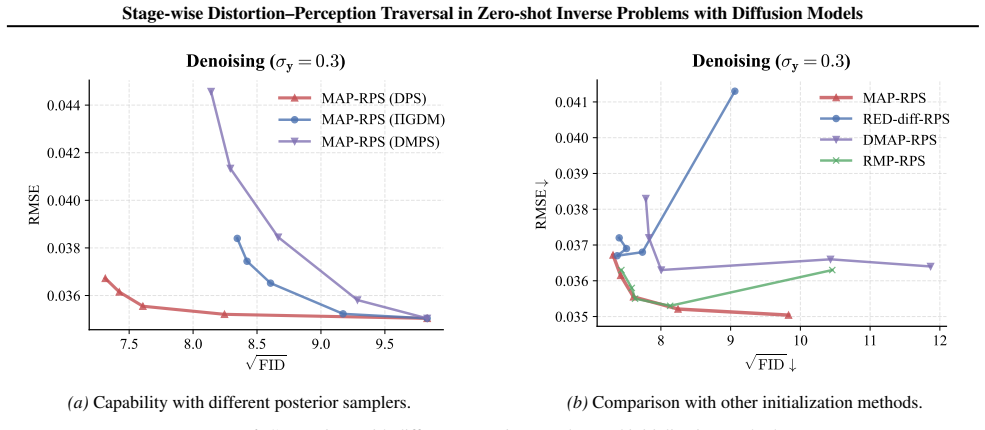
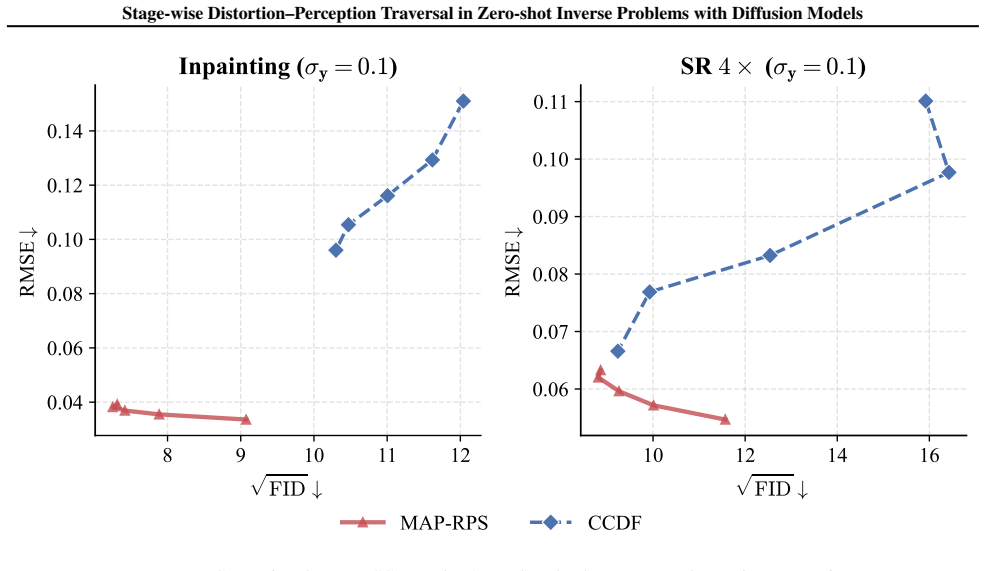
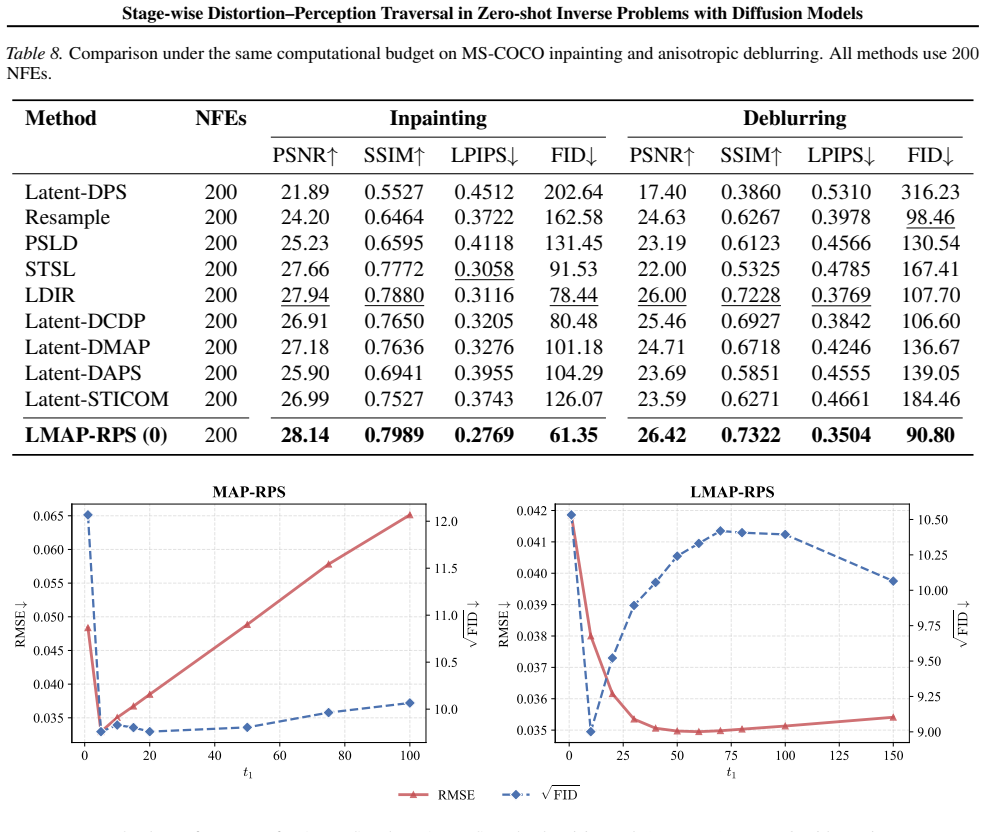
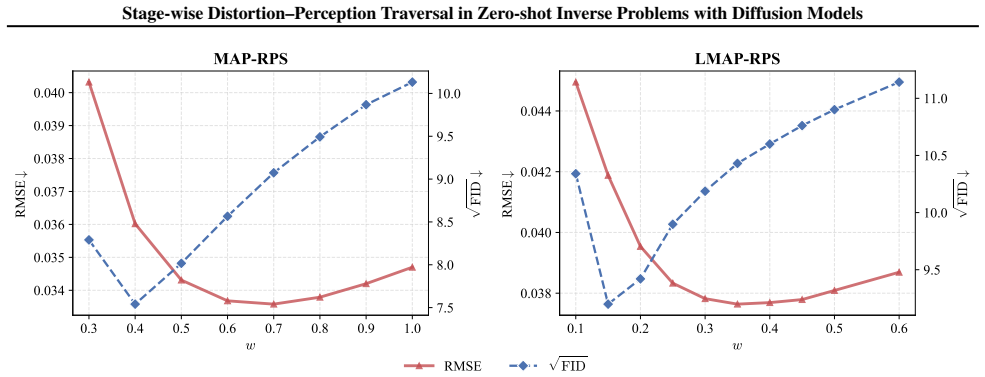
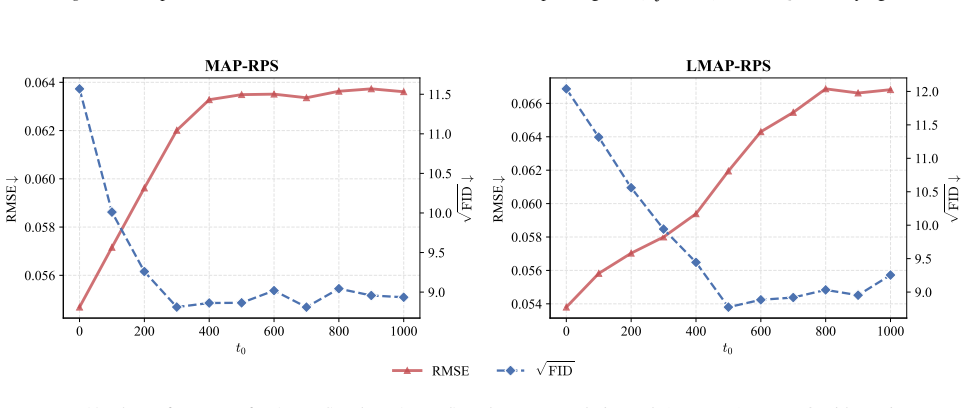
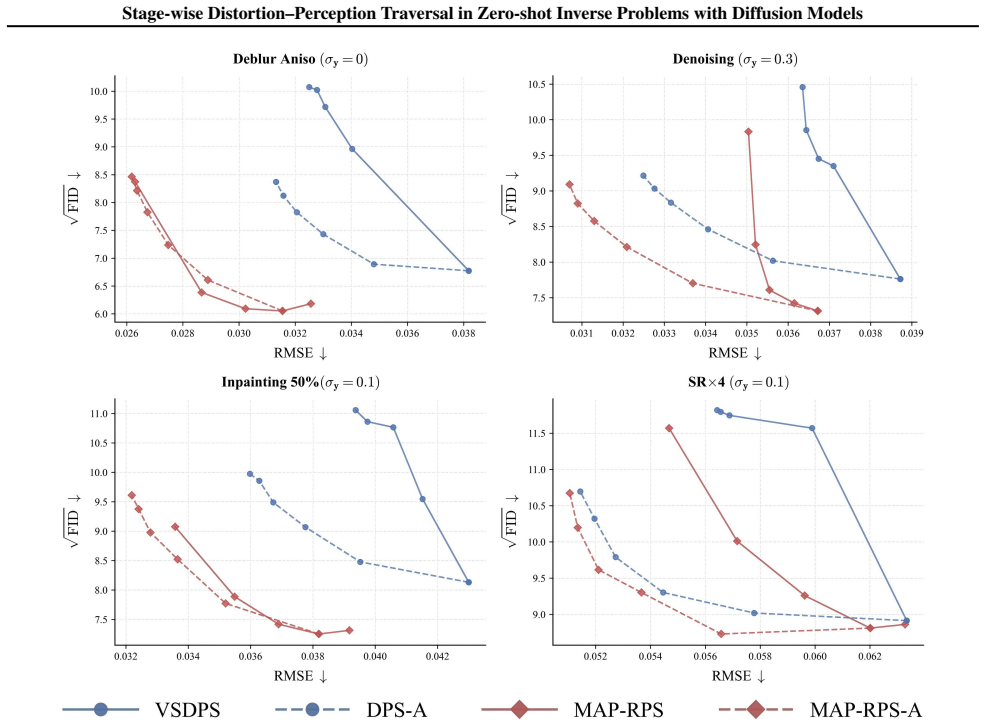
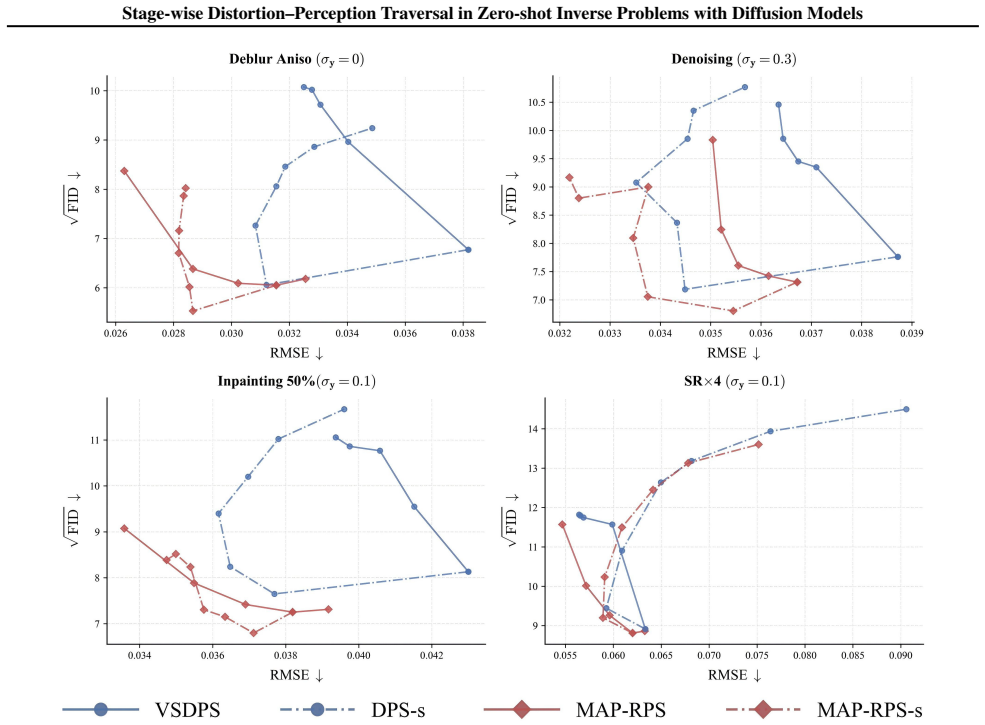
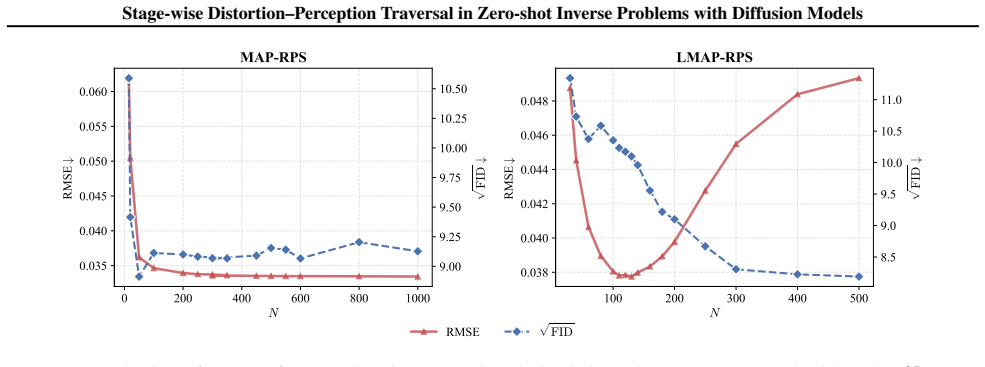
The authors claim that the MAP-RPS method, consisting of an MAP estimation stage that approximates the MMSE solution followed by a re-noised posterior sampling stage that improves perceptual quality, enables effective stage-wise traversal of the distortion-perception tradeoff in zero-shot inverse problems with diffusion models, with theoretical support for both stages and an extension to latent space.
What carries the argument
The MAP-RPS framework, where an MAP estimation stage supplies low-distortion initialization and a re-noised posterior sampling stage raises perceptual quality.
If this is right
- Users gain inference-time control over the distortion-perception balance without retraining the diffusion model.
- The approach works as an efficient solver for real-world inverse problems.
- Extension to latent space allows use of large pre-trained latent diffusion backbones.
- Theoretical analyses establish validity for the two stages separately.
Where Pith is reading between the lines
- Similar staged initialization followed by sampling might apply to other generative models for inverse problems.
- Task-specific tuning of the switch point between stages could further optimize results for particular applications.
- The method may reduce the need for multiple specialized models when perceptual preferences vary across users.
Load-bearing premise
The MAP estimation stage reliably approximates the MMSE solution and the re-noised posterior sampling stage improves perceptual quality without instability or new artifacts.
What would settle it
An experiment in which re-noised posterior sampling after the MAP stage fails to raise perceptual metrics or produces results no better than standard posterior sampling on the same tasks.
Figures







read the original abstract
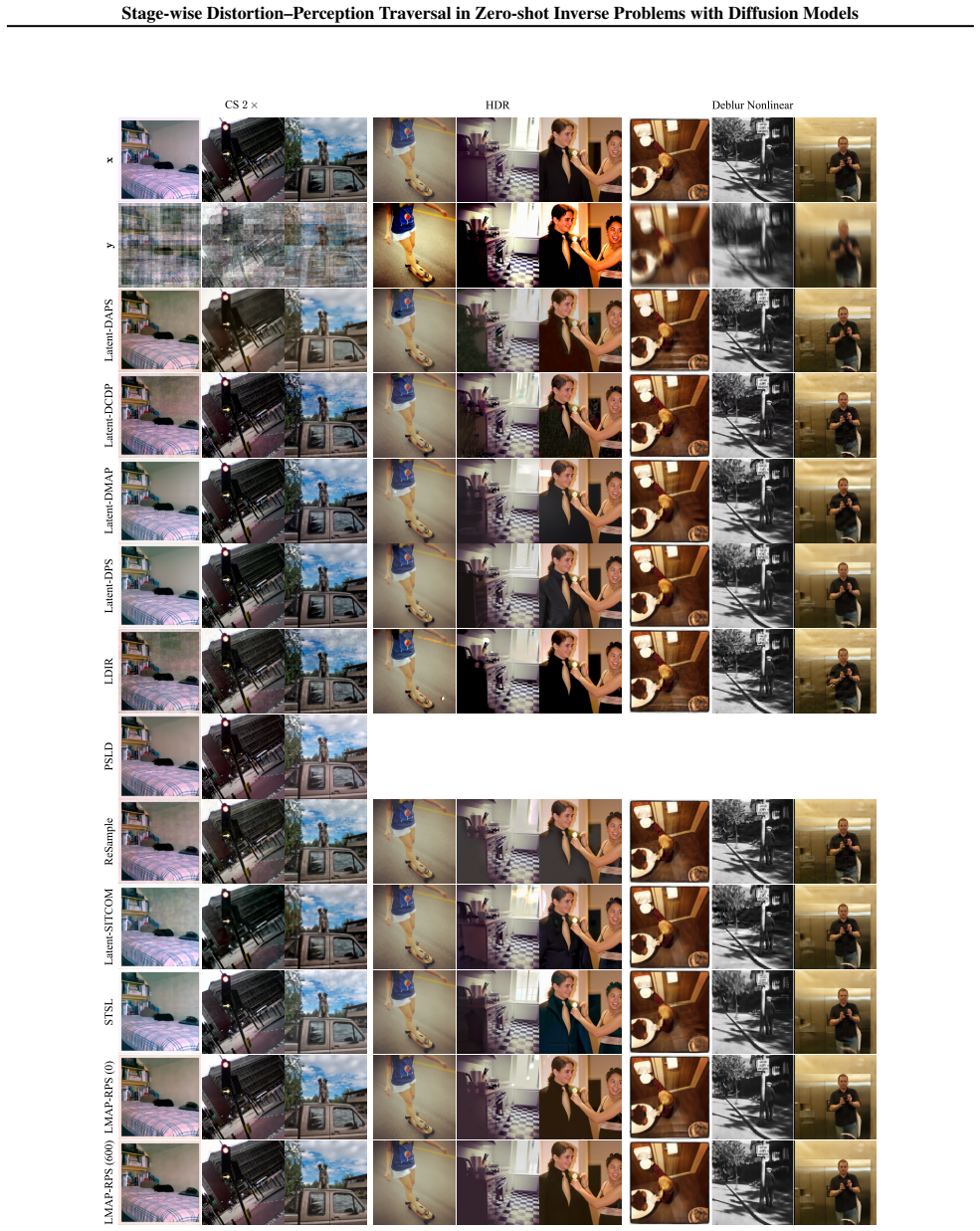
The distortion-perception (D-P) tradeoff is a fundamental phenomenon of Bayesian inverse problems, which characterizes the inherent tension between distortion performance and perceptual quality. Enabling flexible traversal of the D-P tradeoff at inference time is crucial for practical applications. Despite the recent success of diffusion models in zero-shot inverse problem solving, efficient and principled strategies for D-P traversal in diffusion-based inverse algorithms remain inadequately characterized. In this paper, we propose a stage-wise framework for realizing D-P traversal using a single diffusion model in zero-shot inverse problems. Our proposed method, termed MAP-RPS, starts with an MAP estimation stage that approximates the MMSE solution and provides a low-distortion initialization, followed by a re-noised posterior sampling stage that progressively improves perceptual quality. We provide theoretical analyses for both stages, establishing the validity and effectiveness of the proposed design. Furthermore, we extend MAP-RPS to the latent space, yielding LMAP-RPS, which enjoys broader applicability by leveraging large-scale pre-trained latent diffusion backbones. Extensive experiments demonstrate that MAP-RPS and LMAP-RPS enable more effective D-P traversal on various tasks, while also exhibiting strong performance as efficient solvers for real-world inverse problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MAP-RPS, a stage-wise framework for distortion-perception (D-P) traversal in zero-shot inverse problems using diffusion models. It begins with an MAP estimation stage that approximates the MMSE solution to provide a low-distortion initialization, followed by a re-noised posterior sampling (RPS) stage that progressively improves perceptual quality. Theoretical analyses are provided to establish the validity of both stages. The method is extended to latent space as LMAP-RPS for use with large-scale pre-trained latent diffusion models. Experiments on various tasks demonstrate effective D-P traversal and strong performance as inverse problem solvers.
Significance. If the theoretical analyses hold and the experiments are reproducible, the work provides a principled, single-model approach to flexibly traversing the D-P tradeoff at inference time in zero-shot settings. This addresses a practical gap in diffusion-based inverse algorithms and could enable better control in applications like image restoration, with the latent extension broadening applicability to large models.
major comments (1)
- [Theoretical analyses for MAP estimation stage] The theoretical analysis of the MAP stage (claimed to approximate the MMSE solution) does not appear to state explicit conditions under which the approximation holds for the non-Gaussian, multimodal posteriors that arise in diffusion models for image inverse problems. In general Bayesian settings the mode and mean diverge outside local Gaussianity or small-noise regimes; without this regime being specified, the low-distortion initialization premise and the subsequent RPS analysis rest on an unsecured step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The theoretical analysis of the MAP stage (claimed to approximate the MMSE solution) does not appear to state explicit conditions under which the approximation holds for the non-Gaussian, multimodal posteriors that arise in diffusion models for image inverse problems. In general Bayesian settings the mode and mean diverge outside local Gaussianity or small-noise regimes; without this regime being specified, the low-distortion initialization premise and the subsequent RPS analysis rest on an unsecured step.
Authors: We agree that the manuscript would benefit from explicitly stating the conditions under which the MAP approximation to the MMSE solution is valid. The current theoretical analysis relies on the diffusion model's posterior properties but does not delineate the regime (e.g., local Gaussianity or small-noise settings) for multimodal cases. In the revised manuscript, we will add a paragraph in the MAP stage analysis section to specify these assumptions and discuss their relevance to the D-P traversal framework, thereby strengthening the foundation for both the initialization and the RPS stage. revision: yes
Circularity Check
No circularity: derivation rests on independent theoretical analyses
full rationale
The paper's central claims rest on an MAP estimation stage approximating MMSE followed by re-noised posterior sampling, with explicit statements that theoretical analyses establish validity for both stages. No equations or steps in the abstract reduce by construction to fitted inputs, self-definitions, or self-citation chains; the analyses are presented as external to the method itself. The derivation chain is therefore self-contained against the provided description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Song, J., Meng, C., and Ermon, S
URL https://openreview.net/forum? id=j8hdRqOUhN. Song, J., Meng, C., and Ermon, S. Denoising diffu- sion implicit models. InInternational Conference on Learning Representations, 2021a. URL https:// openreview.net/forum?id=St1giarCHLP. Song, J., Vahdat, A., Mardani, M., and Kautz, J. Pseudoinverse-guided diffusion models for inverse prob- lems. InInternati...
2023
-
[2]
URL https://openreview.net/forum? id=GcvLoqOoXL. 11 Stage-wise Distortion–Perception Traversal in Zero-shot Inverse Problems with Diffusion Models Xu, X. and Chi, Y . Provably robust score-based diffusion posterior sampling for plug-and-play image reconstruc- tion.Advances in Neural Information Processing Systems, 37:36148–36184, 2024. Xue, Z., Cai, P., Y...
-
[3]
local MAP
that characterizes a fundamental property of strongly log-concave densities. Lemma B.2.(Brascamp & Lieb, 1976) Suppose that −logp(x) is twice continuously differentiable and strongly convex. Then for any test functionh, the following inequality holds: E|h(x)−E(h(x))| 2 ≤E h ∇h(x)T ∇2(−logp(x)) −1 ∇h(x) i .(29) The next lemma establishes a differential equ...
1976
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.