Human Label Variation as Stable Signal: Learning Annotator-Specific Explanation Behavior via Cross-Annotator Preference Optimization
Pith reviewed 2026-06-29 13:02 UTC · model grok-4.3
The pith
Large language models can learn stable annotator-specific explanation patterns from human label variation when trained with cross-annotator preference optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
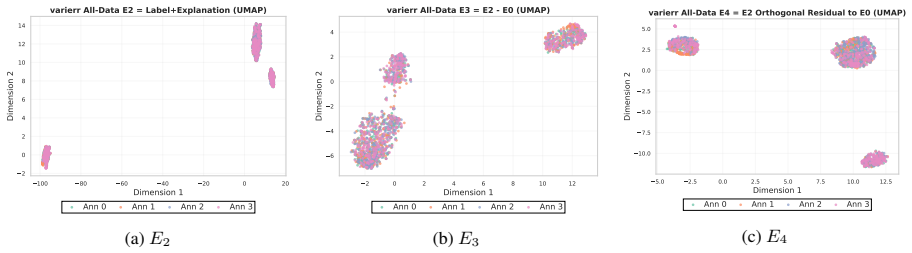
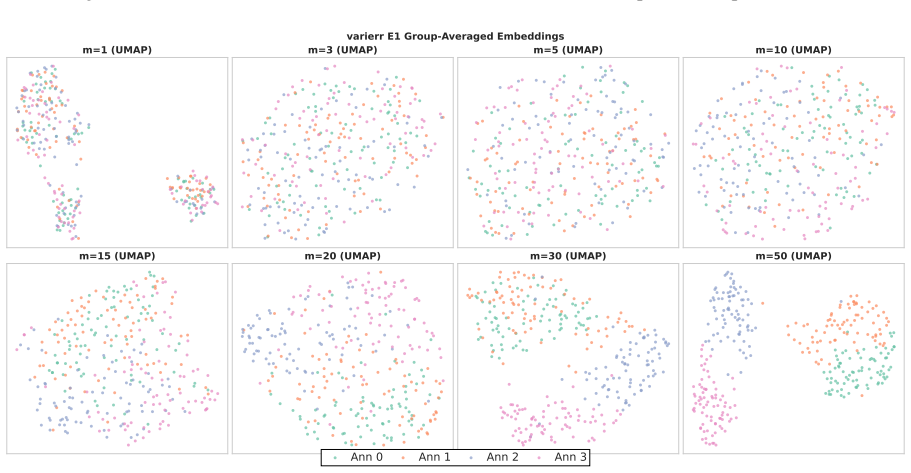
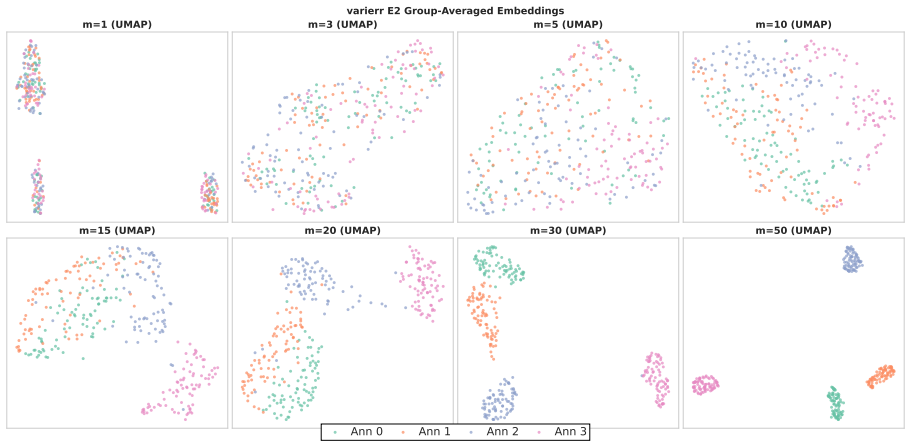
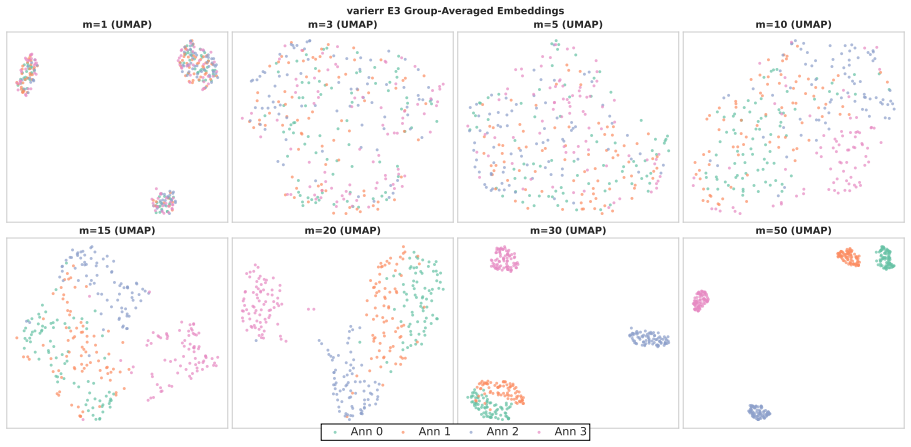
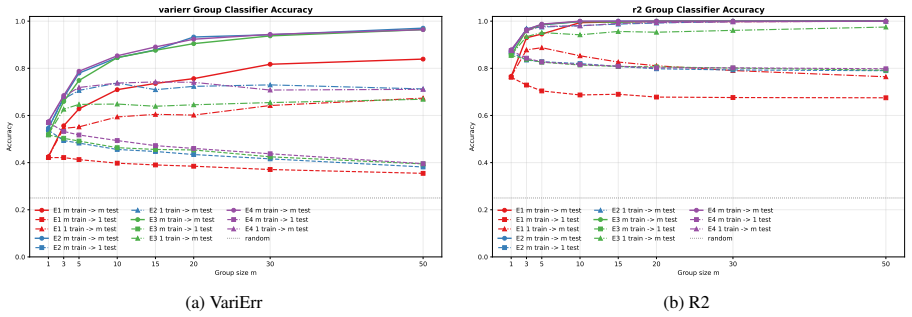
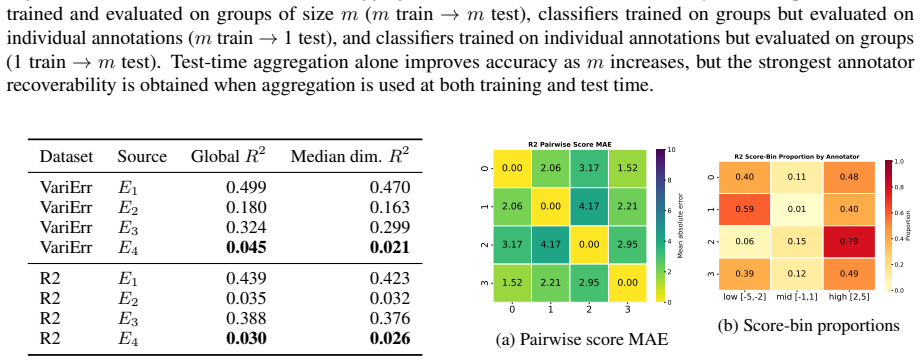
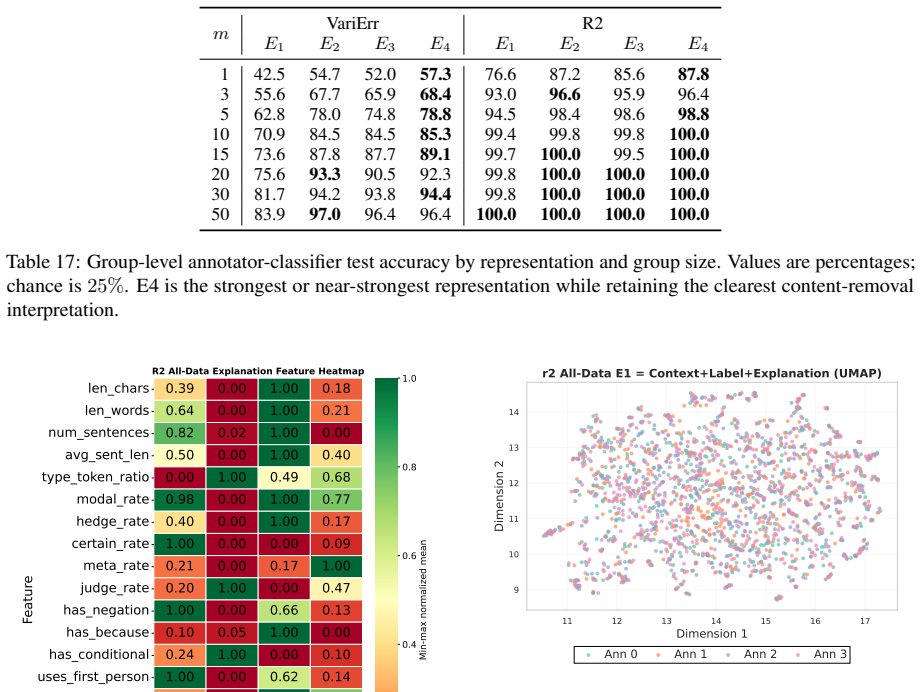
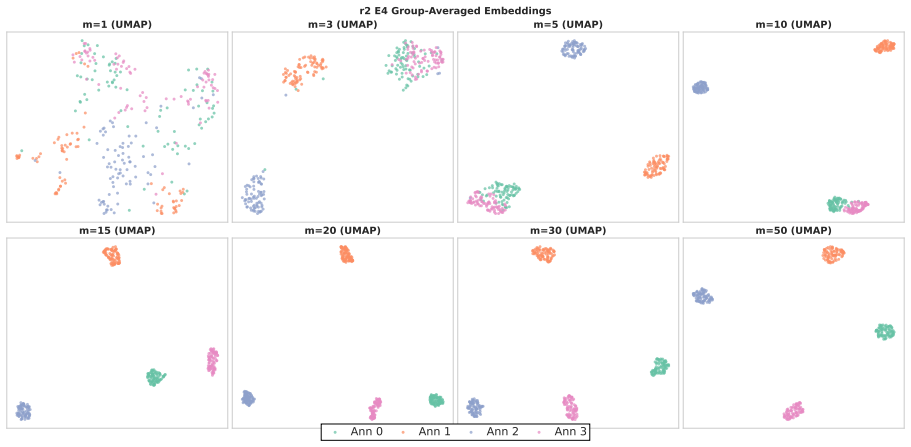
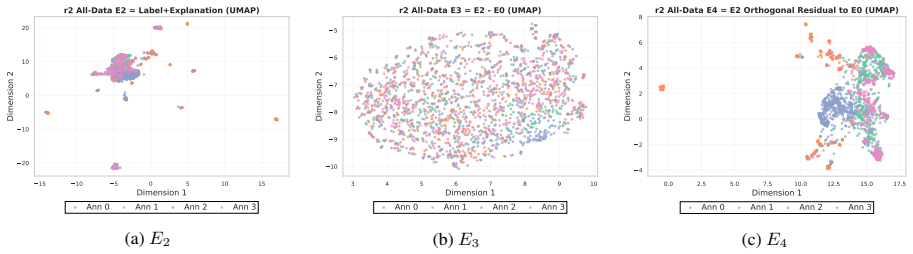
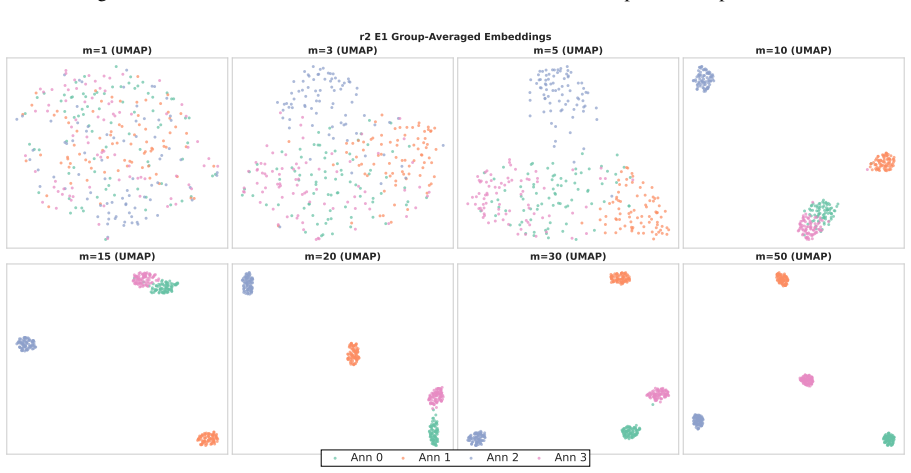
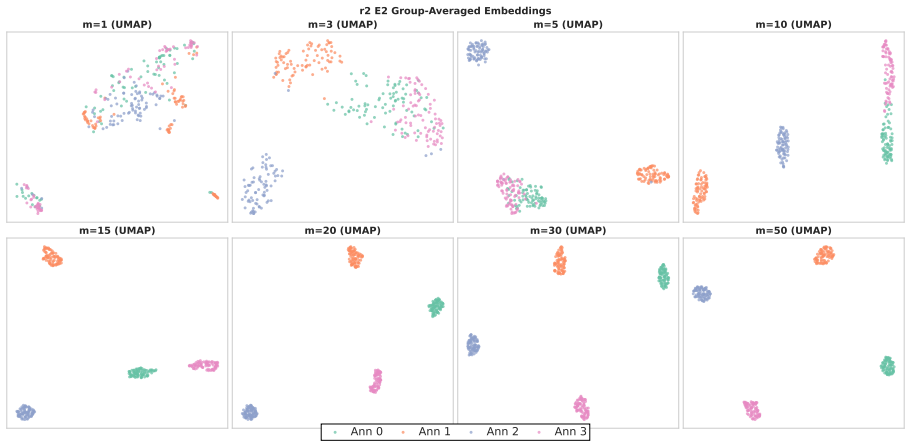
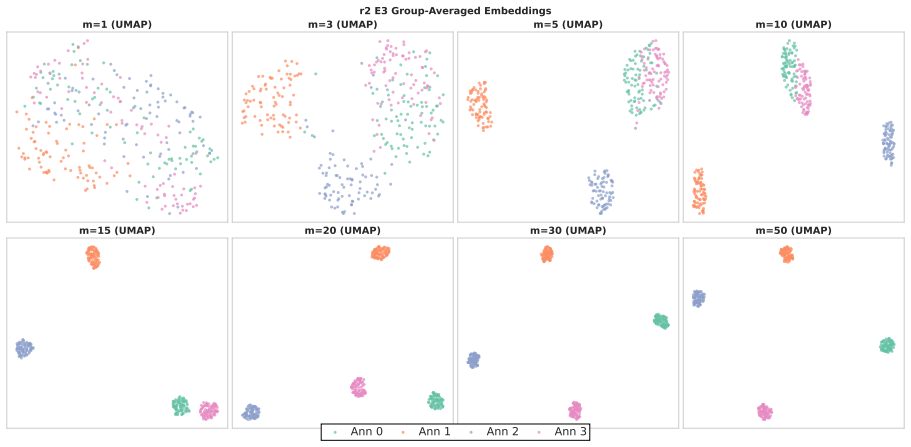
Annotators show stable individual patterns in label-explanation behavior that remain weak at the single-annotation level due to strong input-content effects but become detectable after input-content reduction and annotator-level aggregation; these patterns can be learned by LLMs through cross-annotator preference optimization, which contrasts a target annotator's response with other valid but less target-specific annotations for the same input, yielding better aggregation-aware imitation and judge-based attribution while preserving target-specific reasoning patterns under human validation.
What carries the argument
Cross-annotator preference optimization (CAPO), a training method that contrasts a target annotator's response with other valid but less target-specific annotations for the same input to capture annotator-specific label-explanation behavior.
If this is right
- Prompting methods remain limited and unstable for reproducing annotator-specific behavior.
- Supervised fine-tuning captures annotator-specific behavior more effectively than prompting.
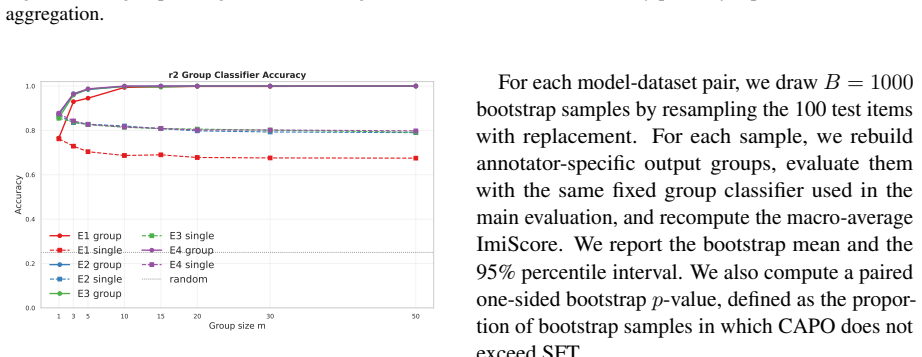
- CAPO improves aggregation-aware imitation and judge-based attribution over supervised fine-tuning.
- Target-specific reasoning patterns stay preserved under human validation after CAPO training.
Where Pith is reading between the lines
- Annotation pipelines could shift from majority labels toward histories of individual explanations for greater consistency.
- The same contrastive approach might extend to other subjective tasks where personal reasoning style matters.
- Models trained this way could serve as proxies for specific annotators when scaling explanation collection.
Load-bearing premise
Annotator-specific patterns in explanations exist and become detectable and learnable only after input-content reduction and annotator-level aggregation.
What would settle it
If human judges cannot attribute CAPO-generated explanations to the intended target annotator more often than those from standard supervised fine-tuning, or if per-annotator aggregation fails to reveal consistent patterns beyond input effects.
Figures

read the original abstract
Free-text explanations extend human label variation (HLV) beyond label disagreement by revealing the reasoning and preferences behind annotators' decisions. We study whether large language models (LLMs) can learn and reproduce such annotator-specific label-explanation behavior. Using two sentence-pair tasks with four annotators each -- natural language inference and paraphrase judgment -- we first analyze whether annotators exhibit stable individual patterns. We find that such patterns are weak at the single-annotation level due to strong input-content effects, but become detectable after input-content reduction and annotator-level aggregation. We then compare prompting and supervised fine-tuning (SFT) baselines and propose cross-annotator preference optimization (CAPO), which contrasts a target annotator's response with other valid but less target-specific annotations for the same input. Experiments show that prompting is limited and unstable, SFT better captures annotator-specific behavior, and CAPO further improves aggregation-aware imitation and judge-based attribution while preserving target-specific reasoning patterns under human validation. Overall, our results show that HLV can be learned as annotator-specific label-explanation behavior, suggesting a path toward scalable explanation-based annotation grounded in annotator histories rather than labels alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that human label variation (HLV) in free-text explanations can be learned as stable annotator-specific behaviors by LLMs. On NLI and paraphrase judgment tasks with four annotators each, single-annotation patterns are weak due to input effects but become detectable after input-content reduction and annotator-level aggregation. Prompting is limited, SFT captures some behavior, and the proposed cross-annotator preference optimization (CAPO) further improves aggregation-aware imitation and judge-based attribution while preserving target-specific patterns per human validation, suggesting scalable explanation-based annotation from annotator histories.
Significance. If the empirical results hold, the work demonstrates a concrete method for modeling individual annotator reasoning preferences beyond aggregate labels, with potential to improve fidelity in explanation generation and annotation systems that leverage per-annotator histories.
major comments (2)
- [Experiments] The central empirical claim that CAPO outperforms SFT on aggregation-aware metrics rests on experiments whose details (error bars, statistical tests, data exclusion rules) are not reported in the abstract or summary; this load-bearing support for outperformance is therefore moderate and requires explicit quantification in the results section.
- [Analysis of annotator patterns] The stability analysis treats input-content reduction and annotator-level aggregation as the precondition that makes patterns detectable; the specific reduction procedure and controls for whether it introduces artifacts rather than revealing true annotator signals need to be shown to be robust, as this underpins the claim that HLV is learnable as annotator-specific behavior.
minor comments (1)
- [Abstract] The abstract mentions 'human validation' but does not specify the protocol or inter-annotator agreement for the judge-based attribution; adding this would improve clarity without altering the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Experiments] The central empirical claim that CAPO outperforms SFT on aggregation-aware metrics rests on experiments whose details (error bars, statistical tests, data exclusion rules) are not reported in the abstract or summary; this load-bearing support for outperformance is therefore moderate and requires explicit quantification in the results section.
Authors: We agree that the abstract does not contain these details. The full results section reports multiple runs with error bars and basic comparisons, but we will revise it to explicitly include statistical significance tests (e.g., paired t-tests), precise data exclusion criteria, and quantified error bars to strengthen the empirical support for CAPO outperforming SFT. revision: yes
-
Referee: [Analysis of annotator patterns] The stability analysis treats input-content reduction and annotator-level aggregation as the precondition that makes patterns detectable; the specific reduction procedure and controls for whether it introduces artifacts rather than revealing true annotator signals need to be shown to be robust, as this underpins the claim that HLV is learnable as annotator-specific behavior.
Authors: Section 3.2 describes the input-content reduction procedure (removal of lexical overlap while retaining annotator-specific reasoning). To demonstrate robustness, we will add controls comparing multiple reduction variants and artifact checks (e.g., shuffled annotator baselines) in a revised analysis subsection. revision: yes
Circularity Check
No significant circularity; empirical method comparison is self-contained
full rationale
The paper's core argument proceeds from empirical observation (stability of annotator patterns only after aggregation) to method comparison (prompting vs SFT vs CAPO) on two tasks with human validation. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The aggregation step is treated as an observed precondition rather than a derived necessity, and CAPO is introduced as a contrastive training procedure whose performance is measured externally. This is a standard empirical ML study whose claims rest on experimental outcomes rather than internal definitional reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- CAPO contrast and optimization hyperparameters
axioms (2)
- domain assumption Annotator patterns become detectable and stable after input-content reduction and annotator-level aggregation
- standard math Standard LLM fine-tuning and preference optimization procedures can be applied to explanation data without additional unstated constraints
Reference graph
Works this paper leans on
-
[1]
seeing the big through the small
Refusal in language models is mediated by a single direction. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neu- ral Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024. Shlomo Argamon, Moshe Koppel, James W. Pen- nebaker, and Jonathan Schler. 2009. Automatically profiling the aut...
-
[2]
Mario Giulianelli, Joris Baan, Wilker Aziz, Raquel Fernández, and Barbara Plank
Chatgpt outperforms crowd-workers for text- annotation tasks.CoRR, abs/2303.15056. Mario Giulianelli, Joris Baan, Wilker Aziz, Raquel Fernández, and Barbara Plank. 2023. What comes next? evaluating uncertainty in neural text generators against human production variability. InProceed- ings of the 2023 Conference on Empirical Methods in Natural Language Pro...
-
[3]
Annotation artifacts in natural language infer- ence data. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, Volume 2 (Short Papers), pages 107–112, New Orleans, Louisiana. Association for Computa- tional Linguistics. Pingjun Hong, Beiduo Chen, Siyao Peng, Ma...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Computational methods in authorship attribu- tion.J. Assoc. Inf. Sci. Technol., 60(1):9–26. Elisa Leonardelli, Silvia Casola, Siyao Peng, Giu- lia Rizzi, Valerio Basile, Elisabetta Fersini, Diego Frassinelli, Hyewon Jang, Maja Pavlovic, Barbara Plank, and Massimo Poesio. 2025. LeWiDi-2025 at NLPerspectives: Third edition of the learning with disagreements...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Sys- tems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023. Sara Rajaee, Yadollah Yaghoobzadeh, and Moham- mad Taher Pilehvar. 2022. Looking at the overlo...
-
[6]
Contradiction
Be cautious when labeling as "Contradiction" or "Entailment", as these labels require explicit evidence and logical connections
-
[7]
the context only mentions
Use phrases like "the context only mentions" or "it is unclear if" to indicate uncertainty
-
[8]
Provide concise explanations that summarize the reasoning behind the label
-
[9]
Contradiction
Be strict in your labeling, especially when it comes to "Contradiction" and "Entailment"
-
[10]
context,
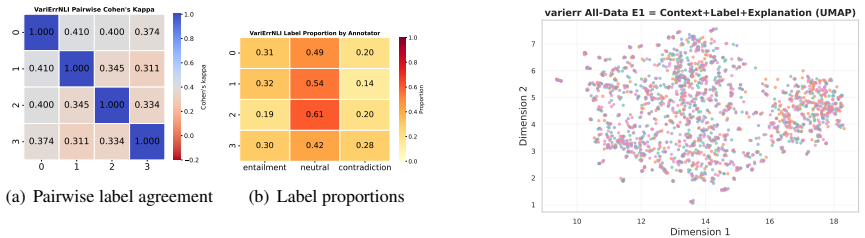
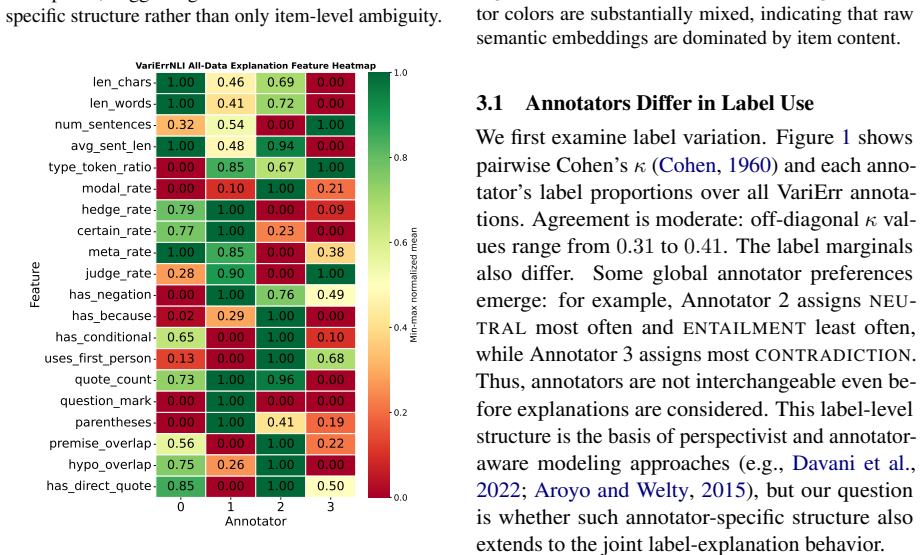
Recognize implicit evidence, such as tone or context, when possible. 33 Annotator Behavioral interpretation Empirical cues Representative examples VariErr NLI 0 Evidence-checking and context- grounded: treats the task as verifying whether the hypothesis is explicitly licensed by the context. Longer explanations; frequent meta- level NLI terms such as “con...
-
[11]
the statement implies
Use phrases like "the statement implies" or "the context suggests" to indicate logical connections. VariErr Llama3.2 Annotator 1 value profile **Annotation Style Profile: Annotator_1 ** **Label/Score Bias: ** * Tends to avoid making definitive judgments, often labeling as "Neutral" when the context suggests a stronger stance. * May not always provide a cl...
-
[12]
Use a formal, objective tone and avoid emotive language or personal opinions
-
[13]
Focus on literal meaning and context, avoiding value judgments or assumptions
-
[14]
Provide a clear and concise explanation to support the label, but avoid elaborating on the reasoning unless necessary
-
[15]
Use straightforward language and avoid jargon or technical terms unless necessary
-
[16]
Be cautious in labeling, avoiding strong or absolute statements
-
[17]
it’s not clear
Indicate uncertainty or ambiguity in the context using phrases like "it’s not clear" or "it’s not clear whether"
-
[18]
Contradiction
Avoid making value judgments or assumptions, focusing on literal meaning and context instead. VariErr Llama3.2 Annotator 2 value profile **Annotator_2’s Annotation Behavior Profile ** **Label/Score Bias: ** * Tends to label as "Contradiction" when the premise and hypothesis are mutually exclusive, but not necessarily contradictory in a strict sense. * Lab...
-
[19]
Evaluate the strength of the premise and hypothesis based on logical coherence and implications
-
[20]
Consider the context and tone of the text when making judgments
-
[21]
Use explicit statements and logical implications to support judgments
-
[22]
usually,
Be concise and clear in explanations, using phrases like "usually," "typically," or "in context" to clarify reasoning
-
[23]
Be lenient in cases where the premise and hypothesis are ambiguous or lack clear implications
-
[24]
Indicate uncertainty or ambiguity in judgments when the premise and hypothesis are unclear or lack clear implications
-
[25]
Entailment
Avoid over-interpreting or over-analyzing text, and be cautious in cases where the premise and hypothesis are ambiguous or lack clear implications. VariErr Llama3.2 Annotator 3 value profile Based on the provided examples, here is a compact profile of Annotator_3’s annotation behavior: **Label/Score Bias: ** 35 * Tends to label as "Entailment" when the co...
-
[26]
Annotator_3 tends to emphasize specific keywords or phrases in the questions, which can lead to different answers
-
[27]
They do not provide explicit explanations for their answers, relying on the literal meaning of the questions
-
[28]
Annotator_3’s explanations are often brief, providing only a concise indication of whether the questions are paraphrases or not
-
[29]
**Profile:** To imitate Annotator_3, follow these guidelines:
They do not acknowledge the context or nuances of the questions, focusing solely on the literal meaning. **Profile:** To imitate Annotator_3, follow these guidelines:
-
[30]
Focus on the literal meaning of the questions
-
[31]
Emphasize specific keywords or phrases in the questions
-
[32]
Provide concise explanations, avoiding complex sentences or jargon
-
[33]
Classify questions as paraphrases or not based on their similarity in meaning
-
[34]
Avoid expressing value judgments or providing explicit evidence
-
[35]
Be strict in your classification of paraphrases, assigning low scores (-5) 40 when the questions are not similar in meaning
-
[36]
Do not express uncertainty in your answers
-
[37]
some" vs
Use simple and straightforward language in your explanations. H.2.2 Qwen3 profiles These profiles correspond to profile model family: qwen3, sample size: 50, seed: 42. R2 Qwen3 Annotator 0 value profile **Annotator_0 Profile (Imitation Guide) ** - **Label/Score Bias **: Strongly penalizes minor differences (e.g., word order, quantifiers like "some" vs. "a...
2014
-
[38]
different conditions
as "different conditions" rather than topic differences. **Imitation Rules for New Items **:
-
[39]
unrelated
Compare core topic, object, and intent. 2. R2 Qwen3 Annotator 2 value profile **Annotator_2 Profile (Imitation Guide) ** - **Label/Score Bias **: Tends to assign **high scores (4-5) ** when questions share core domain, key phrase, and intent, even with minor differences (e.g., word order, redundancy, or minor qualifiers). **Low scores (-3 to -5) ** only w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.