HarmoVid: Relightful Video Portrait Harmonization
Pith reviewed 2026-06-29 13:34 UTC · model grok-4.3
The pith
A video diffusion model trained on deflickered image-harmonized pairs produces temporally coherent relightful portrait harmonization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
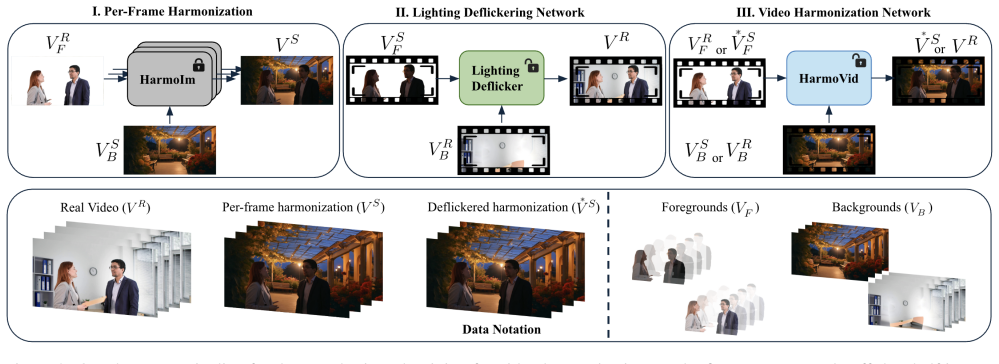
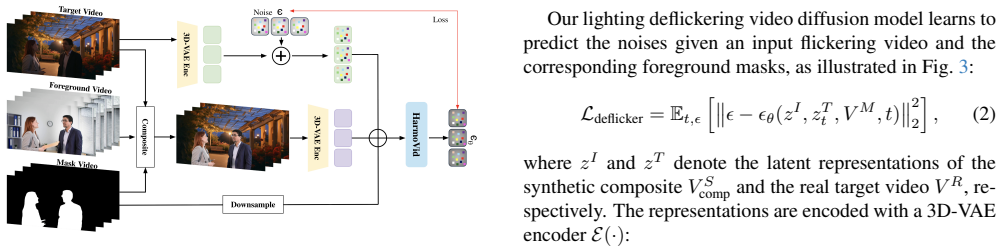
We present a method for harmonizing the lighting of a foreground video to match a target background scene, adjusting shadows, color tone, and illumination intensity. A novel lighting deflickering model stabilizes flickering artifacts in frame-by-frame image harmonization outputs, enabling a video diffusion model to learn from these upgraded pairs plus real and synthetic videos. Asymmetric alpha mask conditioning further supports clean boundaries from real videos, yielding results with strong temporal coherence and physically meaningful lighting.
What carries the argument
The lighting deflickering model that removes global and local flickering from image-based harmonization outputs, paired with asymmetric alpha mask conditioning inside the video diffusion model.
If this is right
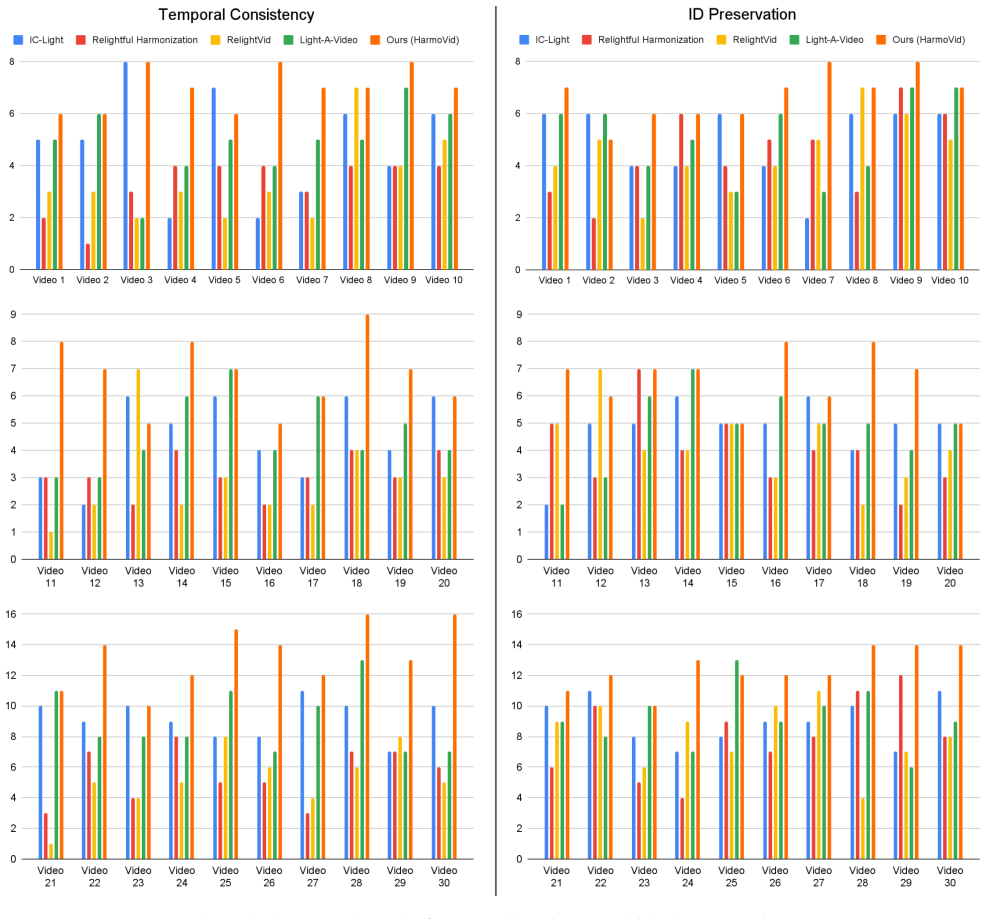
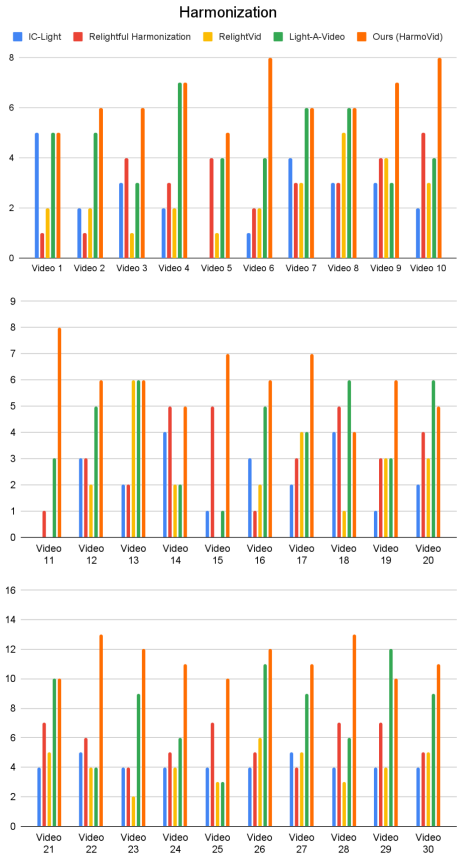
- The harmonized videos exhibit strong temporal coherence without flickering.
- Lighting adjustments remain expressive while producing natural color tones and physically consistent shadows.
- Boundaries between foreground and background appear cleaner than in prior frame-wise methods.
- The same pipeline maintains performance on both real and synthetic input videos.
Where Pith is reading between the lines
- The deflickering step could be reused as a post-process for other video tasks that suffer from per-frame inconsistency.
- Training on a mixture of real and synthetic data suggests the model may generalize to unseen motion and lighting combinations not present in the original image datasets.
- If deflickering quality improves further, the need for large-scale real paired video capture could be reduced.
Load-bearing premise
Frame-by-frame image harmonization followed by the deflickering step yields paired training data free of systematic artifacts that would block the diffusion model from learning stable, physically plausible lighting.
What would settle it
Generate videos from the model and check whether they display persistent frame-to-frame lighting jitter or shadows that violate expected physical behavior under the target illumination; consistent failure on these checks would falsify the claim.
Figures





read the original abstract
We present a method for harmonizing the lighting of a foreground video to match a target background scene, adjusting shadows, color tone, and illumination intensity (relightful harmonization). Unlike images, acquiring labeled data for videos, where identical motions are recorded under different lighting conditions, is practically infeasible and non-scalable. While one way to create such paired data is to apply existing image-based harmonization models frame by frame to a video, the resulting outputs often suffer from significant temporal jitters. We overcome this problem by introducing a novel lighting deflickering model that can stabilize the global and local lighting flickering artifacts. Our video diffusion model learns from these upgraded deflickered data with a volume of real and synthetic videos to generate high-quality video harmonization results. We further propose an asymmetric alpha mask conditioning technique to learn the clean boundaries from real videos. Experiments demonstrate that our model achieves strong temporal coherence, naturalness, cleaner boundaries, and physically meaningful lighting behavior, while maintaining strong relighting expressiveness compared to prior image-based and video-based harmonization methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HarmoVid, a method for relightful video portrait harmonization that adjusts foreground lighting (shadows, color tone, illumination) to match a target background. It addresses the lack of paired video data by generating training pairs via frame-by-frame application of existing image-based harmonizers followed by a novel lighting deflickering model to reduce temporal jitter; a video diffusion model is then trained on these deflickered pairs (augmented with real and synthetic videos) together with an asymmetric alpha mask conditioning scheme to improve boundary quality. Experiments are claimed to show improved temporal coherence, naturalness, cleaner boundaries, and physically meaningful lighting while preserving relighting expressiveness relative to prior image- and video-based methods.
Significance. If the central claims hold, the work would represent a meaningful step toward practical video-level relighting and harmonization, particularly by demonstrating a scalable route to paired training data via deflickering and by extending diffusion models to this task. The emphasis on physically meaningful lighting behavior and temporal stability addresses a clear gap between image harmonization and video applications.
major comments (2)
- [§3.2] §3.2 (Data Generation): The central claim that the video diffusion model learns stable, physically meaningful lighting (rather than artifacts from the deflickering process) rests on the unverified assumption that deflickered frame-by-frame harmonized pairs are free of systematic residual jitter or bias; no ablation is described that isolates whether the model extracts lighting or merely reproduces the deflickering output.
- [§4] §4 (Experiments): Performance claims of 'strong temporal coherence, naturalness, cleaner boundaries, and physically meaningful lighting' are stated without accompanying quantitative metrics (e.g., temporal consistency scores, lighting error metrics, or statistical significance tests), making it impossible to assess whether improvements are load-bearing or within noise.
minor comments (2)
- Notation for the asymmetric alpha mask conditioning is introduced without an explicit equation or diagram showing how the mask asymmetry is implemented during training versus inference.
- The abstract and introduction cite 'prior image-based and video-based harmonization methods' but the related-work section would benefit from a concise table comparing key architectural differences (e.g., diffusion vs. GAN, temporal modeling).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] The central claim that the video diffusion model learns stable, physically meaningful lighting (rather than artifacts from the deflickering process) rests on the unverified assumption that deflickered frame-by-frame harmonized pairs are free of systematic residual jitter or bias; no ablation is described that isolates whether the model extracts lighting or merely reproduces the deflickering output.
Authors: We acknowledge the value of an explicit ablation to isolate the diffusion model's contribution from the deflickering step. The deflickering model is trained to minimize lighting jitter while retaining the target lighting from the image harmonizer, and the diffusion model is trained on the resulting pairs augmented with real and synthetic videos. Our comparisons to frame-by-frame baselines already show improved coherence, but to directly address the concern we will add an ablation in the revised Section 3.2 comparing training on deflickered versus jittery pairs, confirming that the model learns consistent lighting rather than simply reproducing deflickering outputs. revision: yes
-
Referee: [§4] Performance claims of 'strong temporal coherence, naturalness, cleaner boundaries, and physically meaningful lighting' are stated without accompanying quantitative metrics (e.g., temporal consistency scores, lighting error metrics, or statistical significance tests), making it impossible to assess whether improvements are load-bearing or within noise.
Authors: We agree that quantitative metrics would provide stronger support for the claims. The manuscript currently emphasizes qualitative results and user studies. In the revision we will add temporal consistency metrics (e.g., frame-to-frame warping error), lighting consistency measures relative to the background, and statistical significance testing for the user studies, reporting these in Section 4 alongside the existing comparisons. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a data-driven video diffusion model trained on pairs generated by applying image-based harmonization frame-by-frame followed by a lighting deflickering step, plus asymmetric alpha mask conditioning. No equations, derivations, or first-principles results are presented in the abstract or described method that reduce any claimed prediction or result to a quantity defined by the authors' own prior work or by construction. The central claims rest on empirical training and experimental evaluation rather than self-referential identities or fitted inputs renamed as predictions. This matches the reader's assessment that no derivation chain reduces the result to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frame-by-frame image harmonization plus a separate deflickering step yields training pairs that allow a video diffusion model to learn temporally stable and physically plausible lighting.
Reference graph
Works this paper leans on
-
[1]
Lightctrl: Training-free controllable video re- lighting, 2025
Anonymous. Lightctrl: Training-free controllable video re- lighting, 2025. under review in ICLR2026. 3
2025
-
[2]
Real-time 3d-aware portrait video relighting, 2024
Ziqi Cai, Kaiwen Jiang, Shu-Yu Chen, Yu-Kun Lai, Hongbo Fu, Boxin Shi, and Lin Gao. Real-time 3d-aware portrait video relighting, 2024. 2
2024
-
[3]
Real-time 3d-aware portrait video relighting, 2024
Ziqi Cai, Kaiwen Jiang, Shu-Yu Chen, Yu-Kun Lai, Hongbo Fu, Boxin Shi, and Lin Gao. Real-time 3d-aware portrait video relighting, 2024. 3
2024
-
[4]
Text2relight: Creative portrait relighting with text guidance
Junuk Cha, Mengwei Ren, Krishna Kumar Singh, He Zhang, Yannick Hold-Geoffroy, Seunghyun Yoon, HyunJoon Jung, Jae Shin Yoon, and Seungryul Baek. Text2relight: Creative portrait relighting with text guidance. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1980– 1988, 2025. 1, 2, 4
1980
-
[5]
Synthlight: Por- trait relighting with diffusion model by learning to re-render synthetic faces, 2025
Sumit Chaturvedi, Mengwei Ren, Yannick Hold-Geoffroy, Jingyuan Liu, Julie Dorsey, and Zhixin Shu. Synthlight: Por- trait relighting with diffusion model by learning to re-render synthetic faces, 2025. 2
2025
-
[6]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models, 2024
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models, 2024. 4
2024
-
[7]
Per- sonalized video relighting with an at-home light stage
Jun Myeong Choi, Max Christman, and Roni Sengupta. Per- sonalized video relighting with an at-home light stage. In European Conference on Computer Vision, pages 394–410. Springer, 2024. 2, 3
2024
-
[8]
Scribblelight: Single image indoor relighting with scribbles
Jun Myeong Choi, Annie Wang, Pieter Peers, Anand Bhat- tad, and Roni Sengupta. Scribblelight: Single image indoor relighting with scribbles. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 5720–5731,
-
[9]
Ye Fang, Zeyi Sun, Shangzhan Zhang, Tong Wu, Yinghao Xu, Pan Zhang, Jiaqi Wang, Gordon Wetzstein, and Dahua Lin. Relightvid: Temporal-consistent diffusion model for video relighting.arXiv preprint arXiv:2501.16330, 2025. 2, 3, 5, 6
-
[10]
Portrait video editing em- powered by multimodal generative priors, 2024
Xuan Gao, Haiyao Xiao, Chenglai Zhong, Shimin Hu, Yudong Guo, and Juyong Zhang. Portrait video editing em- powered by multimodal generative priors, 2024. 3
2024
-
[11]
High-fidelity relightable monocular portrait animation with lighting- controllable video diffusion model, 2025
Mingtao Guo, Guanyu Xing, and Yanli Liu. High-fidelity relightable monocular portrait animation with lighting- controllable video diffusion model, 2025. 3
2025
-
[12]
Unirelight: Learning joint decomposition and synthesis for video relight- ing, 2025
Kai He, Ruofan Liang, Jacob Munkberg, Jon Hasselgren, Nandita Vijaykumar, Alexander Keller, Sanja Fidler, Igor Gilitschenski, Zan Gojcic, and Zian Wang. Unirelight: Learning joint decomposition and synthesis for video relight- ing, 2025. 3
2025
-
[13]
Beam: Bridging physically-based rendering and gaussian modeling for relightable volumetric video, 2025
Yu Hong, Yize Wu, Zhehao Shen, Chengcheng Guo, Yuheng Jiang, Yingliang Zhang, Jingyi Yu, and Lan Xu. Beam: Bridging physically-based rendering and gaussian modeling for relightable volumetric video, 2025. 3
2025
-
[14]
Towards high fidelity face relight- ing with realistic shadows, 2021
Andrew Hou, Ze Zhang, Michel Sarkis, Ning Bi, Yiying Tong, and Xiaoming Liu. Towards high fidelity face relight- ing with realistic shadows, 2021. 2
2021
-
[15]
Compose: Comprehensive portrait shadow editing, 2024
Andrew Hou, Zhixin Shu, Xuaner Zhang, He Zhang, Yan- nick Hold-Geoffroy, Jae Shin Yoon, and Xiaoming Liu. Compose: Comprehensive portrait shadow editing, 2024. 2
2024
-
[16]
Neural gaffer: Relighting any object via diffusion.Advances in Neu- ral Information Processing Systems, 37:141129–141152,
Haian Jin, Yuan Li, Fujun Luan, Yuanbo Xiangli, Sai Bi, Kai Zhang, Zexiang Xu, Jin Sun, and Noah Snavely. Neural gaffer: Relighting any object via diffusion.Advances in Neu- ral Information Processing Systems, 37:141129–141152,
-
[17]
Text2video-zero: Text-to- image diffusion models are zero-shot video generators, 2023
Levon Khachatryan, Andranik Movsisyan, Vahram Tade- vosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text-to- image diffusion models are zero-shot video generators, 2023. 4
2023
-
[18]
Switchlight: Co-design of physics- driven architecture and pre-training framework for human portrait relighting, 2024
Hoon Kim, Minje Jang, Wonjun Yoon, Jisoo Lee, Donghyun Na, and Sanghyun Woo. Switchlight: Co-design of physics- driven architecture and pre-training framework for human portrait relighting, 2024. 2
2024
-
[19]
Blind video deflickering by neural filtering with a flawed atlas
Chenyang Lei, Xuanchi Ren, Zhaoxiang Zhang, and Qifeng Chen. Blind video deflickering by neural filtering with a flawed atlas. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10439– 10448, 2023. 4, 5, 6
2023
-
[20]
Diffusion- renderer: Neural inverse and forward rendering with video diffusion models, 2025
Ruofan Liang, Zan Gojcic, Huan Ling, Jacob Munkberg, Jon Hasselgren, Zhi-Hao Lin, Jun Gao, Alexander Keller, Nan- dita Vijaykumar, Sanja Fidler, and Zian Wang. Diffusion- renderer: Neural inverse and forward rendering with video diffusion models, 2025. 3
2025
-
[21]
Relightable and animatable neural avatars from videos, 2023
Wenbin Lin, Chengwei Zheng, Jun-Hai Yong, and Feng Xu. Relightable and animatable neural avatars from videos, 2023. 3
2023
-
[22]
Illumicraft: Unified geometry and il- lumination diffusion for controllable video generation, 2025
Yuanze Lin, Yi-Wen Chen, Yi-Hsuan Tsai, Ronald Clark, and Ming-Hsuan Yang. Illumicraft: Unified geometry and il- lumination diffusion for controllable video generation, 2025. 3
2025
-
[23]
Tc-light: Temporally coherent generative render- ing for realistic world transfer, 2025
Yang Liu, Chuanchen Luo, Zimo Tang, Yingyan Li, Yuran Yang, Yuanyong Ning, Lue Fan, Zhaoxiang Zhang, and Jun- ran Peng. Tc-light: Temporally coherent generative render- ing for realistic world transfer, 2025. 2, 3
2025
-
[24]
Deep video harmonization with color map- ping consistency.arXiv preprint arXiv:2205.00687, 2022
Xinyuan Lu, Shengyuan Huang, Li Niu, Wenyan Cong, and Liqing Zhang. Deep video harmonization with color map- ping consistency.arXiv preprint arXiv:2205.00687, 2022. 5
-
[25]
Yiqun Mei, He Zhang, Xuaner Zhang, Jianming Zhang, Zhixin Shu, Yilin Wang, Zijun Wei, Shi Yan, HyunJoon Jung, and Vishal M. Patel. Lightpainter: Interactive portrait relighting with freehand scribble, 2023. 2
2023
-
[27]
Yiqun Mei, Yu Zeng, He Zhang, Zhixin Shu, Xuaner Zhang, Sai Bi, Jianming Zhang, HyunJoon Jung, and Vishal M. Pa- tel. Holo-relighting: Controllable volumetric portrait relight- ing from a single image, 2024. 2
2024
-
[28]
Patel, and Paul Debevec
Yiqun Mei, Mingming He, Li Ma, Julien Philip, Wenqi Xian, David M George, Xueming Yu, Gabriel Dedic, Ahmet Lev- ent Tas ¸el, Ning Yu, Vishal M. Patel, and Paul Debevec. Lux post facto: Learning portrait performance relighting with conditional video diffusion and a hybrid dataset, 2025. 3
2025
-
[29]
Im- age quality assessment for performance evaluation of focus measure operators, 2016
Farida Memon, Mukhtiar Ali Unar, and Sheeraz Memon. Im- age quality assessment for performance evaluation of focus measure operators, 2016. 8
2016
-
[30]
Total relighting: learning to relight portraits for background replacement.ACM Trans
Rohit Pandey, Sergio Orts Escolano, Chloe Legendre, Chris- tian H ¨ane, Sofien Bouaziz, Christoph Rhemann, Paul De- bevec, and Sean Fanello. Total relighting: learning to relight portraits for background replacement.ACM Trans. Graph., 40(4), 2021. 2
2021
-
[31]
Perazzi, J
F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In Computer Vision and Pattern Recognition, 2016. 1
2016
-
[32]
Difareli++: Diffusion face relighting with consistent cast shadows.arXiv e-prints, pages arXiv– 2304, 2023
Puntawat Ponglertnapakorn, Nontawat Tritrong, and Supa- sorn Suwajanakorn. Difareli++: Diffusion face relighting with consistent cast shadows.arXiv e-prints, pages arXiv– 2304, 2023. 2
2023
-
[33]
Luchao Qi, Jiaye Wu, Jun Myeong Choi, Cary Phillips, Roni Sengupta, and Dan B Goldman. Over++: Generative video compositing for layer interaction effects.arXiv preprint arXiv:2512.19661, 2025. 3
-
[34]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 5
2021
-
[36]
Lite2relight: 3d-aware single image portrait relighting
Pramod Rao, Gereon Fox, Abhimitra Meka, Mallikarjun B R, Fangneng Zhan, Tim Weyrich, Bernd Bickel, Hanspeter Pfister, Wojciech Matusik, Mohamed Elgharib, and Chris- tian Theobalt. Lite2relight: 3d-aware single image portrait relighting. InSpecial Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers 24, page 1–12. ACM...
2024
-
[37]
Relightful harmonization: Lighting-aware portrait background replacement
Mengwei Ren, Wei Xiong, Jae Shin Yoon, Zhixin Shu, Jianming Zhang, HyunJoon Jung, Guido Gerig, and He Zhang. Relightful harmonization: Lighting-aware portrait background replacement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6452–6462, 2024. 1, 2, 4, 5, 6
2024
-
[38]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Half-body portrait relighting with overcomplete lighting representation.Computer Graphics Forum, 40(6): 371–381, 2021
Guoxian Song, Tat-Jen Cham, Jianfei Cai, and Jianmin Zheng. Half-body portrait relighting with overcomplete lighting representation.Computer Graphics Forum, 40(6): 371–381, 2021. 2
2021
-
[40]
Barron, Yun-Ta Tsai, Zexiang Xu, Xueming Yu, Graham Fyffe, Christoph Rhemann, Jay Busch, Paul Debevec, and Ravi Ramamoorthi
Tiancheng Sun, Jonathan T. Barron, Yun-Ta Tsai, Zexiang Xu, Xueming Yu, Graham Fyffe, Christoph Rhemann, Jay Busch, Paul Debevec, and Ravi Ramamoorthi. Single image portrait relighting.ACM Transactions on Graphics, 38(4): 1–12, 2019. 2
2019
-
[41]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean conference on com- puter vision, pages 402–419. Springer, 2020. 5
2020
-
[42]
An image inpainting technique based on the fast marching method, 2004
Alexandru Telea. An image inpainting technique based on the fast marching method, 2004. 5
2004
-
[43]
Single image portrait relighting via explicit mul- tiple reflectance channel modeling.ACM Trans
Zhibo Wang, Xin Yu, Ming Lu, Quan Wang, Chen Qian, and Feng Xu. Single image portrait relighting via explicit mul- tiple reflectance channel modeling.ACM Trans. Graph., 39 (6), 2020. 2
2020
-
[44]
Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7623–7633, 2023. 4
2023
-
[45]
Relightable and animatable neural avatar from sparse-view video, 2023
Zhen Xu, Sida Peng, Chen Geng, Linzhan Mou, Zihan Yan, Jiaming Sun, Hujun Bao, and Xiaowei Zhou. Relightable and animatable neural avatar from sparse-view video, 2023. 3
2023
-
[46]
Follow your motion: A generic temporal con- sistency portrait editing framework with trajectory guidance,
Haijie Yang, Zhenyu Zhang, Hao Tang, Jianjun Qian, and Jian Yang. Follow your motion: A generic temporal con- sistency portrait editing framework with trajectory guidance,
-
[47]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Learning to relight portrait images via a virtual light stage and synthetic-to-real adaptation.ACM Transactions on Graphics, 41(6):1–21,
Yu-Ying Yeh, Koki Nagano, Sameh Khamis, Jan Kautz, Ming-Yu Liu, and Ting-Chun Wang. Learning to relight portrait images via a virtual light stage and synthetic-to-real adaptation.ACM Transactions on Graphics, 41(6):1–21,
-
[49]
Generative portrait shadow removal, 2024
Jae Shin Yoon, Zhixin Shu, Mengwei Ren, Xuaner Zhang, Yannick Hold-Geoffroy, Krishna Kumar Singh, and He Zhang. Generative portrait shadow removal, 2024. 1, 2
2024
-
[50]
Lumen: Consistent video relighting and harmo- nious background replacement with video generative mod- els, 2025
Jianshu Zeng, Yuxuan Liu, Yutong Feng, Chenxuan Miao, Zixiang Gao, Jiwang Qu, Jianzhang Zhang, Bin Wang, and Kun Yuan. Lumen: Consistent video relighting and harmo- nious background replacement with video generative mod- els, 2025. 2, 3
2025
-
[51]
Neural video portrait relighting in real-time via con- sistency modeling, 2021
Longwen Zhang, Qixuan Zhang, Minye Wu, Jingyi Yu, and Lan Xu. Neural video portrait relighting in real-time via con- sistency modeling, 2021. 2, 3
2021
-
[52]
Scal- ing in-the-wild training for diffusion-based illumination har- monization and editing by imposing consistent light trans- port
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Scal- ing in-the-wild training for diffusion-based illumination har- monization and editing by imposing consistent light trans- port. InThe Thirteenth International Conference on Learn- ing Representations, 2025. 1, 2, 5, 6
2025
-
[53]
Lumisculpt: Enabling consistent portrait lighting in video generation, 2025
Yuxin Zhang, Dandan Zheng, Biao Gong, Shiwen Wang, Jingdong Chen, Ming Yang, Weiming Dong, and Chang- sheng Xu. Lumisculpt: Enabling consistent portrait lighting in video generation, 2025. 2, 3
2025
-
[54]
Avid: Any-length video inpainting with diffusion model
Zhixing Zhang, Bichen Wu, Xiaoyan Wang, Yaqiao Luo, Luxin Zhang, Yinan Zhao, Peter Vajda, Dimitris Metaxas, and Licheng Yu. Avid: Any-length video inpainting with diffusion model. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 7162–7172, 2024. 5
2024
-
[55]
Vidcraft3: Camera, object, and lighting control for image-to-video generation,
Sixiao Zheng, Zimian Peng, Yanpeng Zhou, Yi Zhu, Hang Xu, Xiangru Huang, and Yanwei Fu. Vidcraft3: Camera, object, and lighting control for image-to-video generation,
-
[56]
Hao Zhou, Sunil Hadap, Kalyan Sunkavalli, and David W. Jacobs. Deep single-image portrait relighting. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), 2019. 2
2019
-
[57]
Deep single-image portrait relighting
Hao Zhou, Sunil Hadap, Kalyan Sunkavalli, and David W Jacobs. Deep single-image portrait relighting. InProceed- ings of the IEEE/CVF international conference on computer vision, pages 7194–7202, 2019. 2
2019
-
[58]
Yujie Zhou, Jiazi Bu, Pengyang Ling, Pan Zhang, Tong Wu, Qidong Huang, Jinsong Li, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, et al. Light-a-video: Training-free video relighting via progressive light fusion.arXiv preprint arXiv:2502.08590, 2025. 2, 3, 5, 6 HarmoVid: Relightful Video Portrait Harmonization Supplementary Material Along with this supplemental PD...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.