From Pixels to Words -- Towards Native One-Vision Models at Scale
Pith reviewed 2026-06-29 13:26 UTC · model grok-4.3
The pith
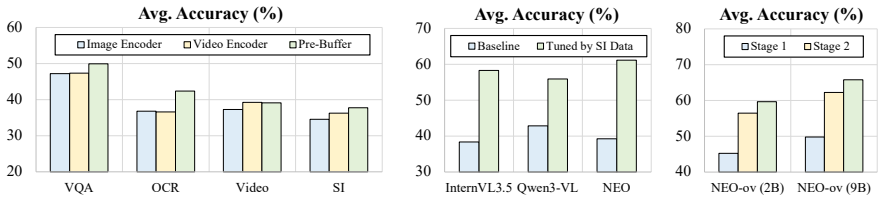
NEO-ov shows a single native model without separate encoders can learn pixel-word mappings end-to-end and close most of the gap to modular vision-language systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
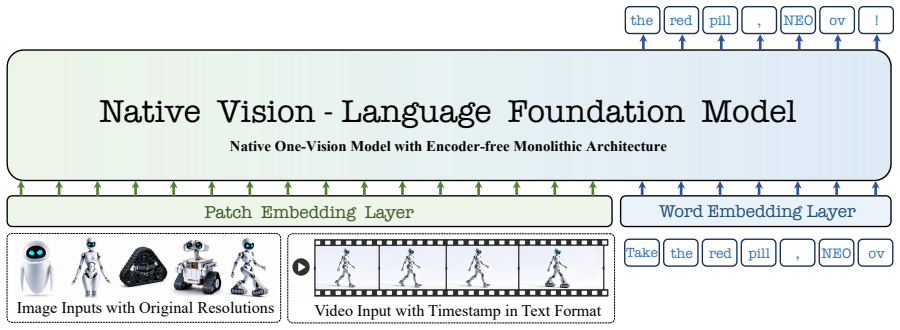
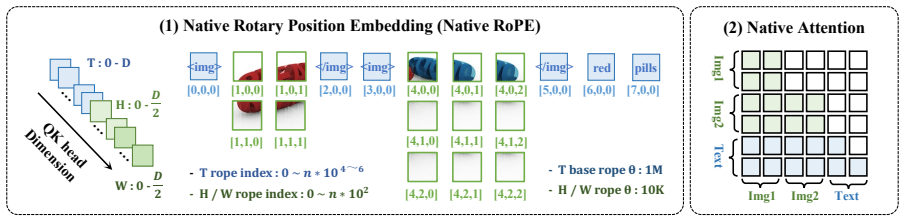
NEO-ov is a native foundation model that learns cross-frame and pixel-word correspondence end-to-end without any external encoders, auxiliary adapters, or post-hoc fusion. By eliminating module boundaries entirely, fine-grained and unified spatiotemporal modeling emerges natively inside the model, narrowing the gap to modular counterparts while excelling at fine-grained visual perception.
What carries the argument
The native one-vision architecture that integrates all processing in a single end-to-end trained network without separate encoders or module boundaries.
If this is right
- Fine-grained spatiotemporal modeling develops inside the model from end-to-end training without explicit alignment stages.
- Performance on vision-language tasks approaches that of modular systems at large scale.
- The model shows stronger results than modular counterparts on tasks requiring detailed visual perception.
- Native architectures become viable for multi-image, video, and spatial-intelligence applications.
- Architectural analyses and training recipes are released to guide future native multimodal work.
Where Pith is reading between the lines
- A single-model design could reduce the engineering overhead of maintaining separate encoders and fusion modules.
- Native cross-frame modeling may scale more naturally to longer video sequences than methods that rely on post-hoc fusion.
- Direct pixel-word learning could preserve low-level visual details that modular pipelines tend to discard early.
- The approach suggests that spatial-intelligence tasks may benefit from training that never breaks the image into an external representation.
Load-bearing premise
Removing all module boundaries and external encoders allows fine-grained spatiotemporal modeling and pixel-word correspondence to emerge natively from end-to-end training alone.
What would settle it
A benchmark result in which NEO-ov falls well behind modular models on fine-grained multi-frame perception tasks while using comparable compute would falsify the central claim.
Figures

read the original abstract
Current vision-language models (VLMs) typically stitch together separate image encoders and language decoders via multi-stage alignment, a modular framework that inevitably fragments pixel-level signals across frames and scatters early pixel-word interactions. In parallel, native VLMs, despite impressive performance on single images, remain largely unexplored in multi-image, video understanding, and spatial intelligence. Hence, we introduce NEO-ov, a native foundation model that learns cross-frame and pixel-word correspondence end-to-end, without any external encoders, auxiliary adapters, or post-hoc fusion. By eliminating module boundaries entirely, NEO-ov enables fine-grained and unified spatiotemporal modeling to emerge natively inside the model. Notably, NEO-ov largely narrows the gap to modular counterparts while excelling at fine-grained visual perception, validating that native "one-vision" architectures are not only feasible but competitive at scale. Beyond empirical performance, we unveil systematic architectural analyses and detailed training recipes to facilitate subsequent native multimodal modeling. Our code and models are publicly available at: https://github.com/EvolvingLMMs-Lab/NEO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NEO-ov, a native end-to-end vision-language foundation model that eliminates separate image encoders, language decoders, adapters, and module boundaries. It claims to learn cross-frame and pixel-word correspondences directly from training, enabling unified spatiotemporal modeling for multi-image, video, and spatial tasks. The work asserts that NEO-ov largely narrows the performance gap to modular VLMs while excelling at fine-grained visual perception, and it provides systematic architectural analyses plus training recipes, with code and models released publicly.
Significance. If the empirical claims are substantiated by detailed results, this would be a meaningful contribution by demonstrating the viability of fully native one-vision architectures at scale and supplying practical guidance for future unified multimodal models. The public release of code and models strengthens potential impact and reproducibility.
major comments (2)
- Abstract: the central empirical claim that NEO-ov 'largely narrows the gap to modular counterparts' is stated without any metrics, baselines, ablation results, or benchmark tables, preventing assessment of whether the performance assertion is supported.
- Abstract: the assumption that fine-grained spatiotemporal modeling and pixel-word correspondence emerge natively solely from removing module boundaries and end-to-end training is presented as validated by results, but no experimental details, training dynamics, or comparisons are supplied to test this weakest assumption.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The two major comments both concern the abstract's level of detail in supporting its claims. We address each below and note that revisions to the abstract are appropriate.
read point-by-point responses
-
Referee: Abstract: the central empirical claim that NEO-ov 'largely narrows the gap to modular counterparts' is stated without any metrics, baselines, ablation results, or benchmark tables, preventing assessment of whether the performance assertion is supported.
Authors: We agree the abstract is concise and omits specific numbers. The full manuscript contains the requested details in the experimental sections and tables. To improve self-containment, we will revise the abstract to incorporate key quantitative results (e.g., performance deltas on multi-image and video benchmarks) while remaining within length limits. revision: yes
-
Referee: Abstract: the assumption that fine-grained spatiotemporal modeling and pixel-word correspondence emerge natively solely from removing module boundaries and end-to-end training is presented as validated by results, but no experimental details, training dynamics, or comparisons are supplied to test this weakest assumption.
Authors: The abstract summarizes the hypothesis; the supporting evidence (architectural ablations, training curves, and cross-frame correspondence analyses) appears in the main body. We will revise the abstract to include a brief reference to these experiments so the claim is better grounded within the abstract itself. revision: yes
Circularity Check
No circularity detected; derivation is empirical and self-contained
full rationale
The provided abstract and context describe an empirical architecture (NEO-ov) trained end-to-end without external encoders, with performance claims presented as outcomes of that training rather than derived from fitted parameters or self-referential definitions. No equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the text. The central claim reduces to benchmark results from native training, which is externally falsifiable and does not reduce to its own inputs by construction. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
ERA: Entropy-Guided Visual Token Pruning with Rectified Attention for Efficient MLLMs
ERA proposes entropy-guided token pruning with bias-aware recycling and logit rectification to compress visual inputs in MLLMs while mitigating attention collapse.
Reference graph
Works this paper leans on
-
[1]
InAd- vances of Neural Information Processing Systems, New Orleans, LA, USA
Instructblip: towards general-purpose vision- language models with instruction tuning. InAd- vances of Neural Information Processing Systems, New Orleans, LA, USA. Haiwen Diao, Yufeng Cui, Xiaotong Li, Yueze Wang, Huchuan Lu, and Xinlong Wang. 2024. Unveil- ing encoder-free vision-language models.CoRR, abs/2406.11832. Haiwen Diao, Mingxuan Li, Silei Wu, L...
-
[2]
InEuro- pean Conference on Computer Vision, volume 9908, pages 235–251, Amsterdam, The Netherlands
A diagram is worth a dozen images. InEuro- pean Conference on Computer Vision, volume 9908, pages 235–251, Amsterdam, The Netherlands. Weixian Lei, Jiacong Wang, Haochen Wang, Xiangtai Li, Jun Hao Liew, Jiashi Feng, and Zilong Huang
-
[3]
The scalability of simplicity: Empirical anal- ysis of vision-language learning with a single trans- former.CoRR, abs/2504.10462. Bo Li, Kaichen Zhang, Hao Zhang, Dong Guo, Ren- rui Zhang, Feng Li, Yuanhan Zhang, Ziwei Liu, and Chunyuan Li. 2024a. Llava-next: stronger llms su- percharge multimodal capabilities in the wild. Bohao Li, Rui Wang, Guangzhi Wan...
-
[4]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee
Langbridge: Interpreting image as a com- bination of language embeddings.arXiv preprint arXiv:2503.19404. Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024a. Improved baselines with visual instruc- tion tuning. InIEEE Conference on Computer Vision and Pattern Recognition, pages 26286–26296, Seat- tle, W A, USA. Haotian Liu, Chunyuan Li, Qingyang...
-
[5]
Llama 2: Open Foundation and Fine-Tuned Chat Models
3dsrbench: A comprehensive 3d spatial rea- soning benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6924–6934. Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq R. Joty, and Enamul Hoque. 2022. Chartqa: a bench- mark for question answering about charts with vi- sual and logical reasoning. InAnnual Meeting of the Ass...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Advances in Neural Information Processing Systems, 37:28828–28857
Longvideobench: A benchmark for long- context interleaved video-language understanding. Advances in Neural Information Processing Systems, 37:28828–28857. xAI. 2024. Grok-1.5 vision preview. Rui Yan, Lin Song, Yicheng Xiao, Runhui Huang, Yix- iao Ge, Ying Shan, and Hengshuang Zhao. 2025. Haplovl: A single-transformer baseline for multi- modal understandin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.