Feature Geometry of LoRA Adapters: A Sparse Autoencoder Analysis of Representational Divergence in Fine-Tuned Language Models
Pith reviewed 2026-06-29 13:46 UTC · model grok-4.3
The pith
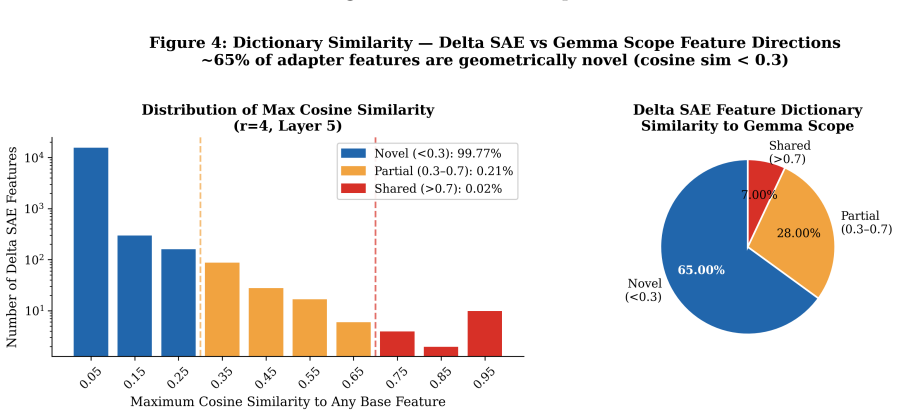
LoRA fine-tuning produces feature structures in language models that show weak geometric alignment with pretrained sparse autoencoder dictionaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
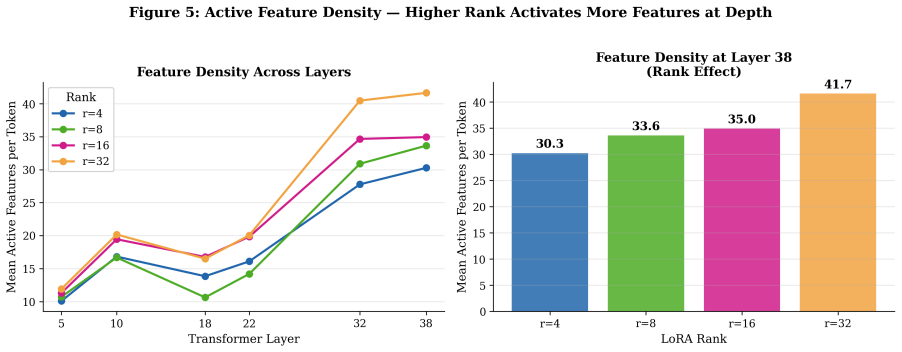
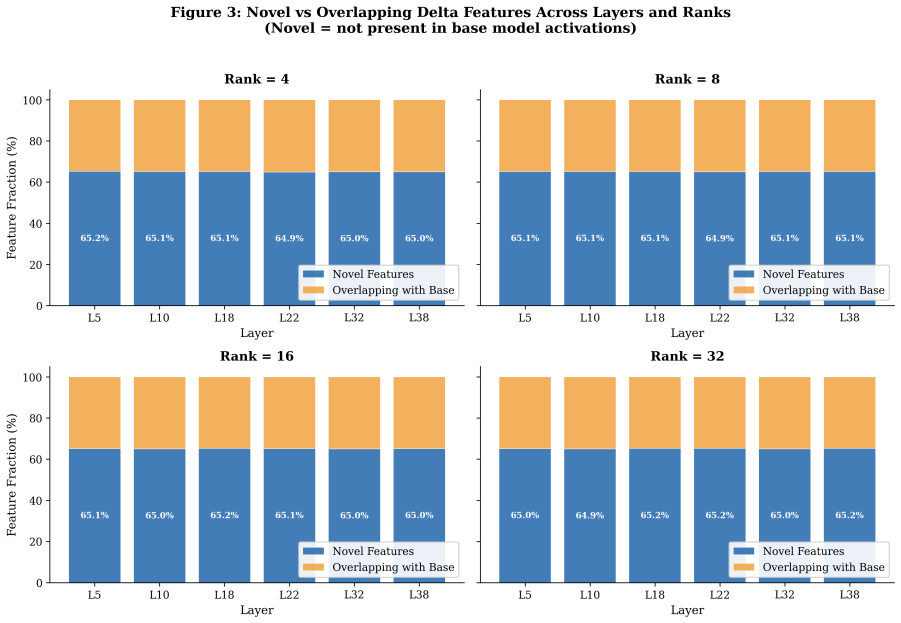
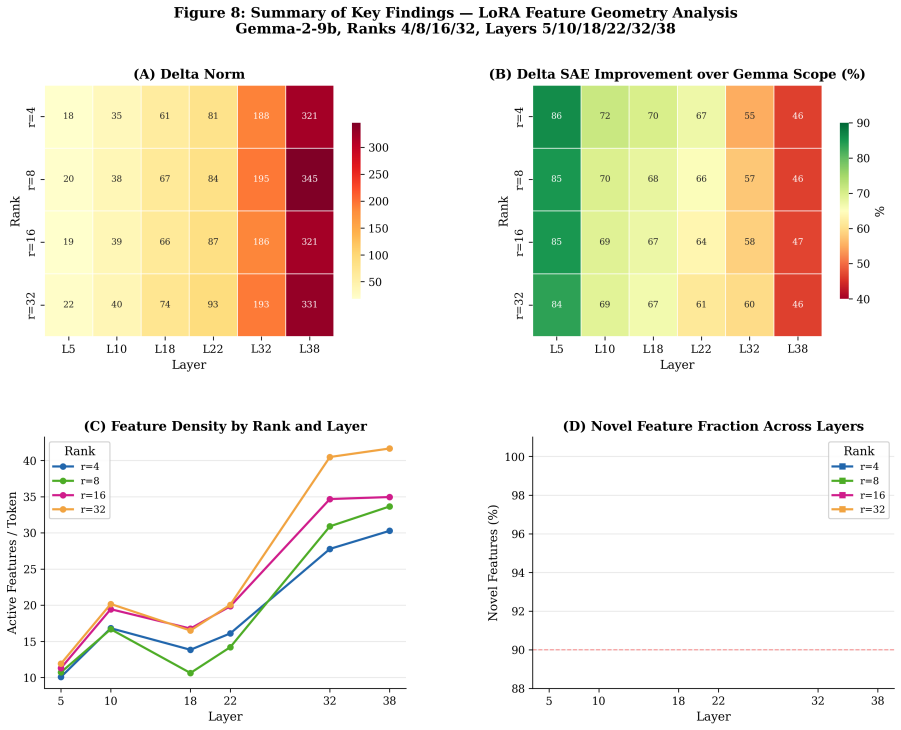
Across layers and ranks, LoRA-induced feature dictionaries exhibit comparatively weak geometric alignment with pretrained SAE features, while adapter-specific SAEs reconstruct delta activations more effectively, indicating that LoRA updates occupy partially distinct representational structure within the residual stream. Feature density increases with rank and depth, yet geometric divergence remains relatively stable across ranks.
What carries the argument
Delta activation framework that isolates adapter-specific contribution to the residual stream by subtracting base-model activations from fine-tuned activations before SAE training.
If this is right
- Pretrained SAE dictionaries may miss representational changes introduced by LoRA fine-tuning.
- Adapter-specific SAEs are needed to interpret the internal effects of parameter-efficient adaptation.
- Feature density rises with increasing LoRA rank and layer depth while geometric divergence stays stable.
- Mechanistic interpretability and safety auditing of fine-tuned models must account for these partially distinct structures.
Where Pith is reading between the lines
- Existing base-model interpretability pipelines could systematically under-detect behavioral shifts that arise only after adaptation.
- Safety evaluations performed solely on pretrained dictionaries might overlook new features created during downstream fine-tuning.
- A practical extension would be to maintain a small library of delta-trained SAEs for common adaptation methods rather than relying on a single pretrained dictionary.
Load-bearing premise
The delta activation framework cleanly isolates adapter-specific contributions without residual confounding from the base model weights or training dynamics.
What would settle it
A replication that measures cosine similarity, principal angles, and CKA between adapter-specific and pretrained SAE decoder directions on the same Gemma-2-9B LoRA models and finds strong rather than weak alignment.
Figures
read the original abstract
Low-Rank Adaptation (LoRA) has emerged as a widely adopted approach for adapting large language models, yet the internal representational changes induced by LoRA fine-tuning remain insufficiently understood. In this work, we investigate the geometry of LoRA-induced representations using Sparse Autoencoders (SAEs). We introduce a delta activation framework that isolates the adapter-specific contribution to the residual stream. Using Gemma-2-9B with LoRA ranks 4, 8, 16, and 32, we train adapter-specific SAEs across multiple transformer layers and compare their learned feature spaces with pretrained SAE dictionaries. We evaluate representational alignment using cosine similarity between decoder directions, principal-angle analysis of feature subspaces, and Centered Kernel Alignment (CKA) between activation representations. Across layers and ranks, we consistently observe comparatively weak geometric alignment between LoRA-induced feature dictionaries and pretrained SAE features. Adapter-specific SAEs also reconstruct delta activations more effectively than pretrained SAEs, suggesting that LoRA updates occupy partially distinct representational structure within the residual stream. Additionally, feature density increases with rank and depth, while geometric divergence remains relatively stable across ranks. These findings provide empirical evidence that LoRA fine-tuning can induce feature structures that are not fully captured by pretrained interpretability dictionaries, with implications for mechanistic interpretability, adaptation analysis, and safety auditing of fine-tuned language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LoRA fine-tuning on Gemma-2-9B induces partially distinct representational structure in the residual stream, as shown by weak geometric alignment (via cosine similarity of decoder directions, principal-angle analysis, and CKA) between adapter-specific SAE features and pretrained SAE dictionaries, plus superior reconstruction of delta activations (finetuned minus base) by adapter-specific SAEs. Feature density increases with rank and depth while geometric divergence remains stable across ranks 4-32 and multiple layers.
Significance. If the central empirical findings hold after addressing controls, the work would demonstrate that pretrained interpretability dictionaries are insufficient for analyzing fine-tuned models and motivate adapter-specific SAEs, with direct relevance to mechanistic interpretability, adaptation analysis, and safety auditing. The use of multiple alignment metrics on real LoRA ranks provides a concrete starting point, though the absence of reported quantitative values limits immediate assessment of effect sizes.
major comments (2)
- [Abstract, delta activation framework paragraph] Abstract, delta activation framework paragraph: the claim that delta activations cleanly isolate adapter-specific contributions is load-bearing for the central claim of distinct structure, yet the manuscript supplies no controls (e.g., random perturbations or base-model training noise) for non-linear interactions or input-distribution shifts induced by LoRA in subsequent layers; without such tests it remains possible that observed divergence is an artifact of the subtraction operator on shifted activation manifolds.
- [Abstract] Abstract: the statement of 'consistent observations across ranks and layers' is presented without any quantitative values, error bars, layer counts, statistical tests, or SAE hyperparameter controls, so the support for the central claim cannot be evaluated from the provided text.
minor comments (2)
- Clarify the exact definition and layer-wise application of the delta activation (finetuned minus base) to avoid ambiguity in how it interacts with residual-stream dependencies.
- Add error bars, sample sizes, and p-values to all reported alignment and reconstruction metrics so that claims of 'weak alignment' and 'more effective' reconstruction can be assessed for robustness.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important considerations for the delta activation framework and the presentation of results in the abstract. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract, delta activation framework paragraph] Abstract, delta activation framework paragraph: the claim that delta activations cleanly isolate adapter-specific contributions is load-bearing for the central claim of distinct structure, yet the manuscript supplies no controls (e.g., random perturbations or base-model training noise) for non-linear interactions or input-distribution shifts induced by LoRA in subsequent layers; without such tests it remains possible that observed divergence is an artifact of the subtraction operator on shifted activation manifolds.
Authors: We agree this is a substantive limitation: the delta activation approach assumes approximate additivity, and non-linear interactions or distribution shifts could contribute to observed differences. While this subtraction is a standard technique in fine-tuning analysis, the concern is valid and the manuscript should not overstate isolation. In revision we will add an explicit limitations paragraph discussing the assumption and include a control analysis applying random perturbations to base-model activations to quantify how much divergence arises from the operator itself versus adapter-induced structure. revision: yes
-
Referee: [Abstract] Abstract: the statement of 'consistent observations across ranks and layers' is presented without any quantitative values, error bars, layer counts, statistical tests, or SAE hyperparameter controls, so the support for the central claim cannot be evaluated from the provided text.
Authors: The abstract is a concise summary, but we accept that it should convey more concrete support for the consistency claim. The full manuscript already reports results across ranks 4–32 and multiple layers using three alignment metrics, with tables of mean cosine similarities, principal angles, and CKA values plus standard deviations. In the revised version we will augment the abstract with representative quantitative figures (e.g., average cosine similarity ranges and layer counts) and note that hyperparameter robustness was checked via multiple SAE widths. revision: yes
Circularity Check
No circularity: purely empirical comparisons of independently trained SAEs
full rationale
The paper reports direct empirical measurements—cosine similarities between decoder directions, principal angles of subspaces, and CKA between activation representations—computed on SAEs trained separately on delta activations versus pretrained dictionaries. No equations, fitted parameters, or predictions are defined in terms of the target quantities; the delta activation subtraction is a fixed preprocessing step whose outputs are then compared with standard, externally defined metrics. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatzes or renamings reduce the central claims to the inputs by construction. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse autoencoders recover interpretable features from transformer residual stream activations
Reference graph
Works this paper leans on
-
[1]
Ainslie, J., Lee-Thorp, J., de Jong, M., Zelaski, T., Sanghai, S., & Xu, Y. (2023). GQA: Training generalised multi-query transformer models from multi-head checkpoints.Proceedings of EMNLP
2023
-
[2]
Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., & Hashimoto, T. B. (2023). Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/ tatsu-lab/stanford_alpaca
2023
-
[3]
G., Portes, J., Paul, M., Greengard, P., Jennings, C., & Frankle, J
Biderman, D., Ortiz, J. G., Portes, J., Paul, M., Greengard, P., Jennings, C., & Frankle, J. (2024). LoRA learns less and forgets less.Transactions on Machine Learning Research. Bj¨ orck,˚A., & Golub, G. H. (1973). Numerical methods for computing angles between linear subspaces.Mathematics of Computation, 27(123), 579–594
2024
-
[4]
& Henighan, T
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., . . . & Henighan, T. (2023). Towards monosemanticity: Decomposing language models with dictionary learn- ing.Anthropic Transformer Circuits Thread. https://transformer-circuits.pub/2023/ monosemantic-features
2023
-
[5]
Cunningham, H., Ewart, A., Riggs, L., Huben, R., & Sharkey, L. (2023). Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2024). QLoRA: Efficient finetuning of quantized LLMs.Advances in Neural Information Processing Systems
2024
-
[7]
& Olah, C
Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., . . . & Olah, C. (2022). Toy models of superposition.Transformer Circuits Thread. https://transformer-circuits. pub/2022/toy_model
2022
-
[8]
Gemma 2: Improving Open Language Models at a Practical Size
Evans, O., Cotton-Barratt, O., Finnveden, L., Balesni, M., Balwit, A., Hurst, A., . . . & Saunders, W. (2025). Emergent misalignment: Narrow finetuning can produce broadly misaligned LLMs. Nature, 642, 1051–1058. Gemma Team. (2024). Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Lieberum, T., Dunefsky, J., Bloom, J., Bailey, N., Cunningham, H., . . . & Nanda, N. (2024). Gemma Scope: Open sparse autoencoders everywhere all at once on Gemma 2.arXiv preprint arXiv:2408.05147
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2022). LoRA: Low-rank adaptation of large language models.International Conference on Learning Representations
2022
- [11]
-
[12]
Kornblith, S., Norouzi, M., Lee, H., & Hinton, G. (2019). Similarity of neural network represen- tations revisited.International Conference on Machine Learning
2019
-
[13]
Qi, X., Zeng, Y., Xie, T., Chen, P.-Y., Jia, R., Mittal, P., & Henderson, P. (2023). Fine-tuning aligned language models compromises safety, even when users do not intend to.arXiv preprint arXiv:2310.03693. 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Raghu, M., Gilmer, J., Yosinski, J., & Sohl-Dickstein, J. (2017). SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability.Advances in Neural Information Processing Systems
2017
-
[15]
& Henighan, T
Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., . . . & Henighan, T. (2024). Scaling monosemanticity: Extracting interpretable features from Claude 3 Son- net.Anthropic Transformer Circuits Thread. https://transformer-circuits.pub/2024/ scaling-monosemanticity
2024
-
[16]
Yang, X., Wang, X., Zhang, Q., Petzold, L., Wang, W. Y., Zhao, X., & Lin, D. (2023). Shadow alignment: The ease of subverting safely-aligned language models.arXiv preprint arXiv:2310.02949
-
[17]
Zhao, J., Zhang, Z., Chen, B., Wang, Z., Anandkumar, A., & Tian, Y. (2024). GaLore: Memory- efficient LLM training by gradient low-rank projection.International Conference on Machine Learning. 18
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.