VFEAgent: A Multimodal Agent Framework for End-to-End Automated Finite Element Analysis
Pith reviewed 2026-06-29 12:29 UTC · model grok-4.3
The pith
VFEAgent automates finite element analysis from images and text using a multi-agent system with built-in verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
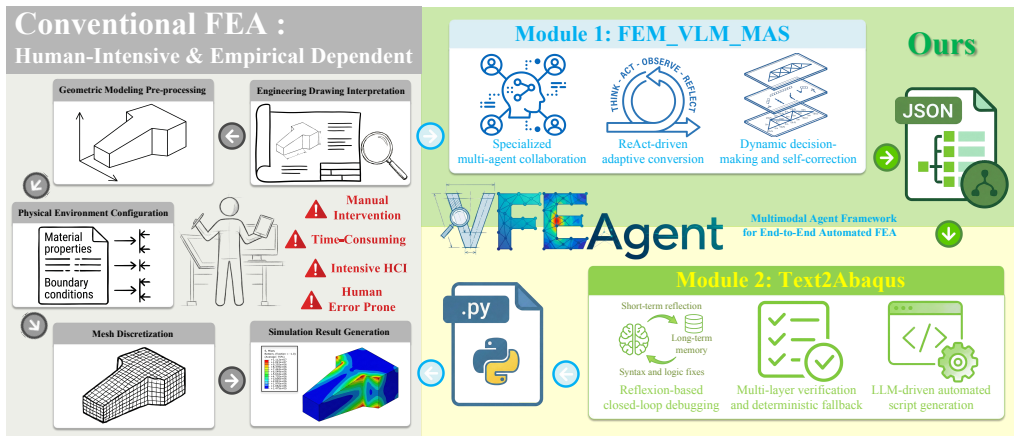
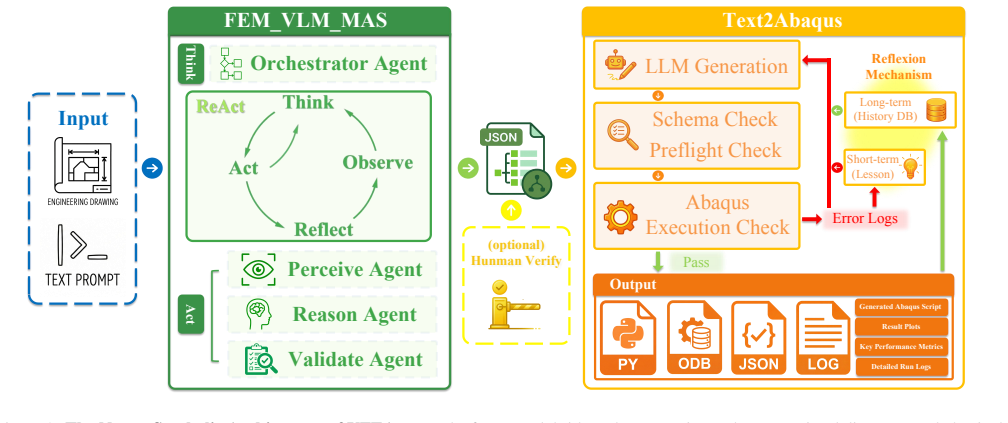
VFEAgent is an end-to-end multi-agent system that automates FEA modeling and simulation directly from input images and problem descriptions. It integrates a multimodal vision-language multi-agent pipeline that employs ReAct-driven reasoning to extract structured FEA specifications from heterogeneous inputs together with a verification-first code synthesis framework that incorporates robust self-debugging and fallback mechanisms to ensure executability and physical validity. Systematic evaluation across engineering mechanics scenarios shows high success rates in generating complete and physically valid simulations that outperform LLM-based baseline methods.
What carries the argument
verification-first code synthesis framework with self-debugging and fallback mechanisms that turns extracted specifications into executable, physically valid FEA code
If this is right
- Complete FEA workflows become generatable from images and text without manual meshing or code writing.
- Physical validity and executability are maintained through automated self-correction rather than post-hoc expert checks.
- The system achieves higher reliability than direct LLM prompting on the same engineering tasks.
- Automation covers the full pipeline from specification extraction through simulation output.
Where Pith is reading between the lines
- The same verification-first structure could be applied to other physics simulation types such as computational fluid dynamics.
- Real-time iteration between design changes in an image and updated simulation outputs becomes feasible if the pipeline runs quickly enough.
- Success on 2D mechanics problems leaves open whether the approach scales to full 3D assemblies with contact and nonlinear materials.
Load-bearing premise
The self-debugging and fallback mechanisms can convert multimodal inputs into simulations that are both executable and physically valid without any domain expert review.
What would settle it
A standard cantilever beam or plate bending problem fed to the system produces either non-executable code or results that violate equilibrium or material laws after the verification steps complete.
Figures
read the original abstract
Finite Element Analysis (FEA) serves as the cornerstone of modern engineering design. However, its workflow is inherently complex and relies heavily on domain expertise. Although recent efforts have integrated Large Language Models (LLMs) into FEA, existing approaches face limitations in handling multimodal inputs and executing complex tasks. To address these limitations, we propose VFEAgent, an end-to-end multi-agent system designed to automate FEA modeling and simulation directly from input images and problem descriptions. Our methodology integrates two core components: (1) a multimodal vision-language multi-agent pipeline that employs ReAct-driven reasoning to extract structured FEA specifications from heterogeneous inputs and (2) a verification-first code synthesis framework, incorporating robust self-debugging and fallback mechanisms to ensure executability and physical validity. We systematically evaluated the system across various engineering mechanics scenarios. The results demonstrate that VFEAgent achieves a high success rate in generating complete and physically valid simulations, outperforming LLM-based baseline methods in reliability and correctness. These findings validate the feasibility of automating the complete FEA workflow, highlighting the framework's potential to liberate engineers from tedious manual analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
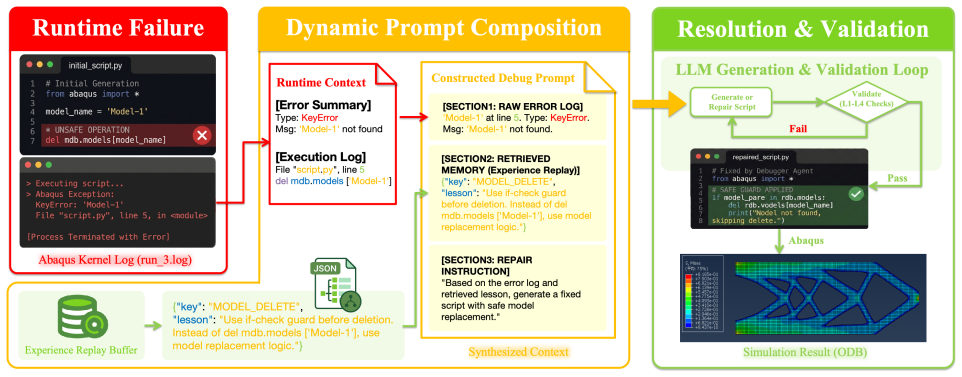
Summary. The manuscript introduces VFEAgent, a multimodal multi-agent framework for end-to-end FEA automation. It uses a vision-language pipeline with ReAct-driven reasoning to extract structured specifications from images and problem descriptions, followed by a verification-first code synthesis module with self-debugging and fallback mechanisms to generate executable scripts for tools such as Abaqus or ANSYS. The central claim is that systematic evaluation across engineering mechanics scenarios yields a high success rate in producing complete and physically valid simulations, outperforming LLM-based baseline methods in reliability and correctness.
Significance. If the empirical results hold under rigorous quantitative validation, the work would demonstrate a practical advance in applying multi-agent LLM systems to complex, multimodal engineering workflows that have historically required substantial domain expertise. The emphasis on verification mechanisms to bridge the gap between code generation and usable FEA output addresses a recognized limitation in prior LLM-assisted simulation efforts. The absence of detailed metrics in the abstract, however, leaves the strength of the contribution dependent on the evaluation section.
major comments (2)
- [Evaluation section] Evaluation section: The claim that VFEAgent achieves a 'high success rate in generating complete and physically valid simulations' is unsupported by any reported quantitative metrics, baseline definitions, evaluation protocol, or error analysis. Physical validity of FEA results requires that computed fields satisfy the governing PDEs to within engineering tolerance (e.g., via comparison of displacements or stresses against analytical solutions or benchmark problems); code executability alone does not establish this.
- [Methodology section] Methodology (verification-first code synthesis framework): The self-debugging and fallback mechanisms are asserted to ensure both executability and physical validity, yet no post-execution verification steps—such as residual norm checks, mesh convergence studies, or comparison against reference solutions—are described. This conflates successful script execution with satisfaction of the underlying mechanics equations.
minor comments (1)
- [Abstract] Abstract: The statement that the system 'outperforms LLM-based baseline methods' is presented without naming the baselines or reporting any numerical differences, reducing the informativeness of the summary.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for more rigorous quantitative support and clarification in the evaluation and methodology sections. We will revise the manuscript accordingly to strengthen these aspects while preserving the core contributions.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: The claim that VFEAgent achieves a 'high success rate in generating complete and physically valid simulations' is unsupported by any reported quantitative metrics, baseline definitions, evaluation protocol, or error analysis. Physical validity of FEA results requires that computed fields satisfy the governing PDEs to within engineering tolerance (e.g., via comparison of displacements or stresses against analytical solutions or benchmark problems); code executability alone does not establish this.
Authors: We agree that the evaluation section requires explicit quantitative metrics, defined baselines, a detailed protocol, and error analysis to substantiate the claims. In the revised manuscript, we will report concrete success rates (e.g., percentage of cases yielding complete, executable simulations), specify the LLM-based baselines (such as direct prompting without multi-agent coordination), describe the evaluation protocol across the engineering mechanics scenarios, and provide error analysis. For physical validity, we will add explicit comparisons of FEA outputs (displacements/stresses) against analytical solutions or benchmarks for representative cases, confirming satisfaction of governing equations within engineering tolerances where feasible. revision: yes
-
Referee: [Methodology section] Methodology (verification-first code synthesis framework): The self-debugging and fallback mechanisms are asserted to ensure both executability and physical validity, yet no post-execution verification steps—such as residual norm checks, mesh convergence studies, or comparison against reference solutions—are described. This conflates successful script execution with satisfaction of the underlying mechanics equations.
Authors: The verification-first framework employs self-debugging and fallbacks primarily during code synthesis to achieve executable scripts. We acknowledge that post-execution verification steps (e.g., residual norms or mesh convergence) are not explicitly described. In revision, we will clarify the existing mechanisms, add descriptions of any post-execution checks used in evaluation (such as consistency with expected physical behavior), and distinguish between script executability and full PDE validation. Where full residual checks were not performed, we will note this as a limitation and discuss reliance on solver-internal validation and scenario-specific outcome inspection. revision: partial
Circularity Check
No circularity: applied engineering system with direct empirical evaluation
full rationale
The paper presents VFEAgent as a multimodal multi-agent framework for automating FEA workflows, with claims resting on experimental success rates across engineering scenarios. No equations, derivations, or predictions appear that reduce performance metrics to fitted parameters, self-definitions, or prior self-citations. The verification-first code synthesis is described as an implemented mechanism whose outputs are evaluated directly; physical-validity language is tied to executability in the reported tests rather than any closed mathematical loop. This is a standard applied-systems paper whose central results are falsifiable via replication on the same test cases.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[Azanaw, 2025] Girmay Mengesha Azanaw. Beyond the classical grid: A critical review of emerging finite ele- ment methodologies in structural engineering–from AI- enhanced solvers to isogeometric, discontinuous, and phase-field paradigms.ResearchGate Preprint, July
2025
-
[2]
[Bakeret al., 2025 ] Christopher Baker, Karen Rafferty, and Mark Price
Preprint, not peer-reviewed. [Bakeret al., 2025 ] Christopher Baker, Karen Rafferty, and Mark Price. Large language models in mechanical en- gineering: A scoping review of applications, challenges, and future directions.Big Data and Cognitive Computing, 9(12):305,
2025
-
[3]
[Fanet al., 2025 ] E Fan, Kang Hu, Zhuowen Wu, Jiangyang Ge, Jiawei Miao, Yuzhi Zhang, He Sun, Weizong Wang, and Tianhan Zhang. ChatCFD: An LLM-driven agent for end-to-end CFD automation with domain-specific struc- tured reasoning.arXiv preprint arXiv:2506.02019,
-
[4]
Agent col- laboration in a multi-agent-system for analysis and opti- mization of mechanical engineering parts
[Gembarski, 2020] Paul Christoph Gembarski. Agent col- laboration in a multi-agent-system for analysis and opti- mization of mechanical engineering parts. InKnowledge- Based and Intelligent Information & Engineering Systems, volume 176, pages 592–601. Elsevier,
2020
-
[5]
A lightweight large language model-based multi-agent system for 2D frame structural analysis
[Genget al., 2025 ] Ziheng Geng, Jiachen Liu, Ran Cao, Lu Cheng, Haifeng Wang, and Minghui Cheng. A lightweight large language model-based multi-agent sys- tem for 2D frame structural analysis.arXiv preprint arXiv:2510.05414,
-
[6]
Parameters in play: Alphazero- inspired AI for autonomous parameter identification in soil constitutive and finite element models.Computers and Geotechnics, 166:106065,
[Ghorbaniet al., 2024 ] Javad Ghorbani, Ramin Aghdasi, Mingxiang Li, Chenguang Zhou, Yongming Li, Wei Zhang, and Liang Chen. Parameters in play: Alphazero- inspired AI for autonomous parameter identification in soil constitutive and finite element models.Computers and Geotechnics, 166:106065,
2024
-
[7]
Weinand, Patrick Kuckertz, and Detlef Stolten
[G”opfertet al., 2023 ] Jan G”opfert, Jann M. Weinand, Patrick Kuckertz, and Detlef Stolten. Opportunities for large language models and discourse in engineering de- sign.arXiv preprint arXiv:2306.09169,
-
[8]
[Greenet al., 2024 ] M. D. Green, K. S. Kirilov, M. Turner, J. Marcon, J. Eichst¨adt, E. Laughton, C. D. Cantwell, S. J. Sherwin, J. Peir ´o, and D. Moxey. NekMesh: An open- source high-order mesh generation framework.Computer Physics Communications, 298:109089,
2024
-
[9]
[Guoet al., 2025 ] Xingang Guo, Yaxin Li, Xiangyi Kong, Yilan Jiang, Xiayu Zhao, Zhichao Zhang, Zhichao Sun, Xinyu Wang, Yuhang Li, Yifan Li, et al. Toward engineer- ing AGI: Benchmarking the engineering design capabili- ties of LLMs.arXiv preprint arXiv:2509.16204,
-
[10]
Guru, Vipul Gupta, Kartik Bali, and Roland Aydin
[Guruet al., 2025 ] Mahish K. Guru, Vipul Gupta, Kartik Bali, and Roland Aydin. From finite element analysis to self-optimization: FRAME (Finite element Reason- ing and AI-Agent Model Engine) and the era of agen- tic AI in engineering. Under review as a conference paper at ICLR 2025,
2025
-
[11]
[Honget al., 2024 ] Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Wang, Jialin Cheng, Jinlin Zhang, Ceyao Wang, Ziyang Yau, Steven Ka Shing Lin, Liyang Zhou, et al
Available at OpenReview: https://openreview.net/forum?id=2TdYc5V4jU. [Honget al., 2024 ] Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Wang, Jialin Cheng, Jinlin Zhang, Ceyao Wang, Ziyang Yau, Steven Ka Shing Lin, Liyang Zhou, et al. MetaGPT: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representati...
2024
-
[12]
AutoFEA: En- hancing AI copilot by integrating finite element analysis using large language models with graph neural networks
[Houet al., 2025 ] Shifu Hou, Rick Johnson, Ramandeep Makhija, Lingwei Chen, and Yanfang Ye. AutoFEA: En- hancing AI copilot by integrating finite element analysis using large language models with graph neural networks. InProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence, volume 39, pages 24078–24085,
2025
-
[13]
Fine-tuning vision-language model for automated engineering drawing information extraction
[Khanet al., 2024 ] Muhammad Tayyab Khan, Lequn Chen, Ye Han Ng, Wenhe Feng, Nicholas Yew Jin Tan, and Se- ung Ki Moon. Fine-tuning vision-language model for automated engineering drawing information extraction. arXiv preprint arXiv:2411.03707,
-
[14]
[Khanet al., 2025 ] Muhammad Tayyab Khan, Lequn Chen, Zane Yong, Jun Ming Tan, Wenhe Feng, and Seung Ki Moon. From drawings to decisions: A hybrid vision- language framework for parsing 2D engineering drawings into structured manufacturing knowledge.Robotics and Computer-Integrated Manufacturing, 91:102862,
2025
-
[15]
[Liuet al., 2022 ] Wing Kam Liu, Shaofan Li, and Harold S
arXiv preprint arXiv:2506.17374. [Liuet al., 2022 ] Wing Kam Liu, Shaofan Li, and Harold S. Park. Eighty years of the finite element method: Birth, evolution, and future.Archives of Computational Methods in Engineering, 29(6):4431–4497,
-
[16]
FEM-Bench: A Structured Scientific Reasoning Benchmark for Evaluating Code-Generating LLMs
[Mohammadzadehet al., 2025 ] Saeed Mohammadzadeh, Erfan Hamdi, Joel Shor, and Emma Lejeune. FEM-Bench: A structured scientific reasoning benchmark for evaluating code-generating LLMs.arXiv preprint arXiv:2512.20732,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
[Muduret al., 2025 ] Nayantara Mudur, Hao Cui, Subhashini Venugopalan, Paul Raccuglia, Michael P. Brenner, and Peter Norgaard. FEABench: Evaluating language mod- els on multiphysics reasoning ability.arXiv preprint arXiv:2504.06260,
-
[18]
[Ni and Buehler, 2024] Bo Ni and Markus J. Buehler. MechAgents: Large language model multi-agent collabo- rations can solve mechanics problems, generate new data, and integrate knowledge.Extreme Mechanics Letters, 67:102131,
2024
-
[19]
FeaGPT: an end-to- end agentic-AI for finite element analysis
[Qiet al., 2025 ] Yupeng Qi, Ran Xu, and Xu Chu. FeaGPT: an end-to-end agentic-AI for finite element analysis.arXiv preprint arXiv:2510.21993,
-
[20]
Ai-enhanced finite el- ement method (FEM) for structural analysis.Journal of Electrical Systems, 20(1):661–676,
[Sahani, 2025] Suresh Kumar Sahani. Ai-enhanced finite el- ement method (FEM) for structural analysis.Journal of Electrical Systems, 20(1):661–676,
2025
-
[21]
Application of machine learn- ing and deep learning in finite element analysis: A com- prehensive review.Archives of Computational Methods in Engineering, 31(3):1413–1451,
[Shahet al., 2024 ] Vatsal Shah, Rajesh Singh Thakur, Ro- hit Mishra, Anurag Gupta, Rajendra Kumar Singh, and Sandeep Kumar Mishra. Application of machine learn- ing and deep learning in finite element analysis: A com- prehensive review.Archives of Computational Methods in Engineering, 31(3):1413–1451,
2024
-
[22]
Reflexion: Language agents with verbal re- inforcement learning
[Shinnet al., 2024 ] Noah Shinn, Federico Cassano, Ash- win Labash, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal re- inforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36,
2024
-
[23]
Optimizing collaboration of LLM-based agents for finite element analysis
[Tian and Zhang, 2024] Chuan Tian and Yilei Zhang. Col- laboration dynamics and reliability challenges of multi- agent LLM systems in finite element analysis.arXiv preprint arXiv:2408.13406,
-
[24]
Chain-of-thought prompting elicits reason- ing in large language models
[Weiet al., 2022 ] Jason Wei, Xuezhi Wang, Dale Schuur- mans, Maarten Bosma, fei bfe, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reason- ing in large language models. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), volume 35, pages 24824–24837,
2022
-
[25]
ReAct: Synergizing reasoning and acting in language models
[Yaoet al., 2023 ] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Repre- sentations (ICLR),
2023
- [26]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.