Comparing Classical Simulation and Sample-Based Learning of Quantum Systems: Learning the Hardness of Quantum Systems from Samples
Pith reviewed 2026-06-29 11:11 UTC · model grok-4.3
The pith
Within the regimes studied, sample-based learning difficulty for quantum states tracks their classical simulation hardness from entanglement and non-stabilizerness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
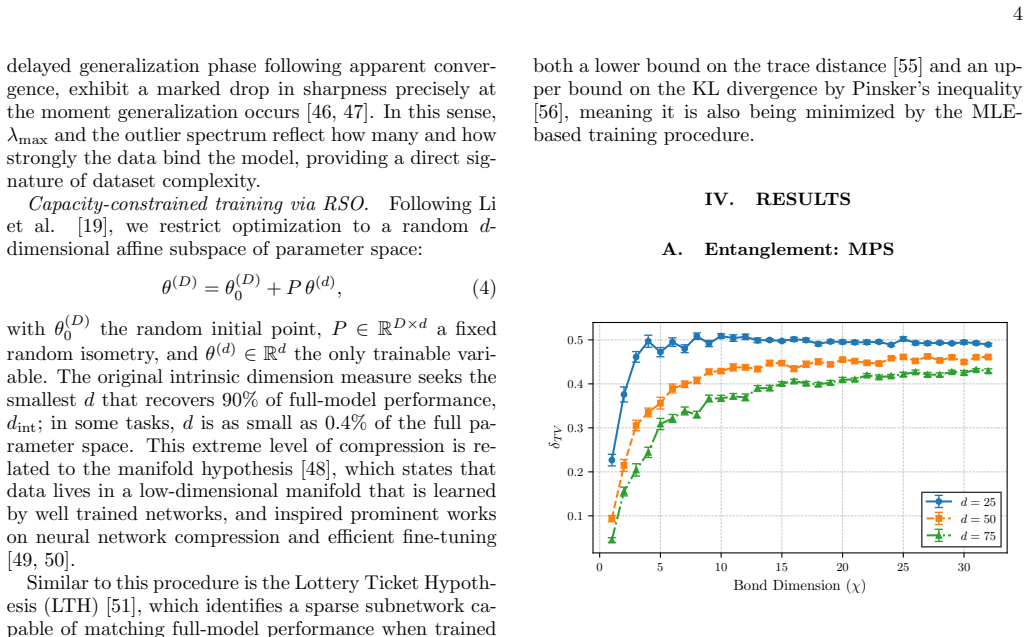
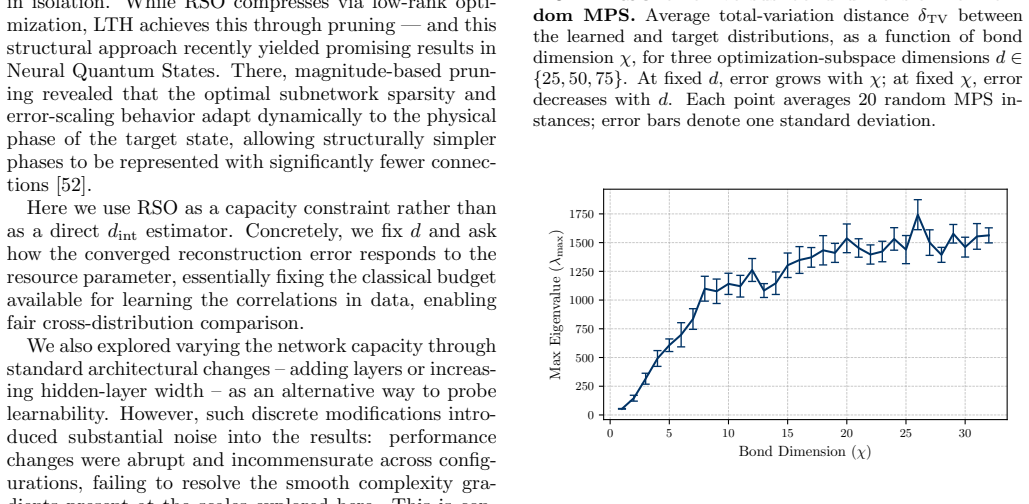
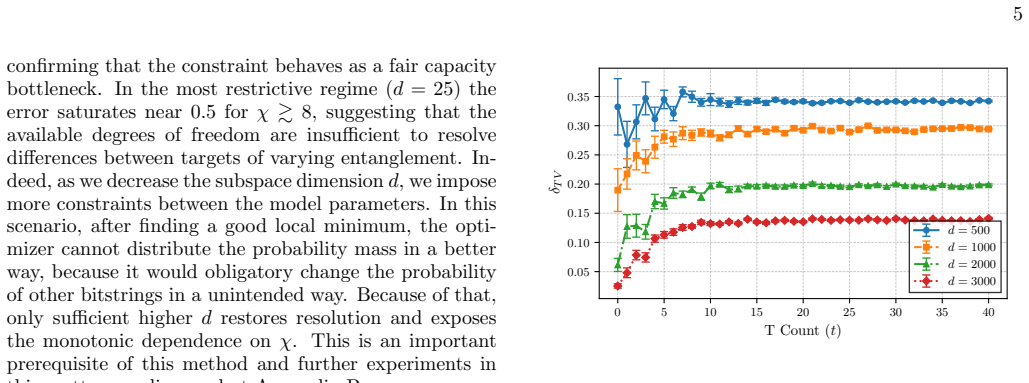
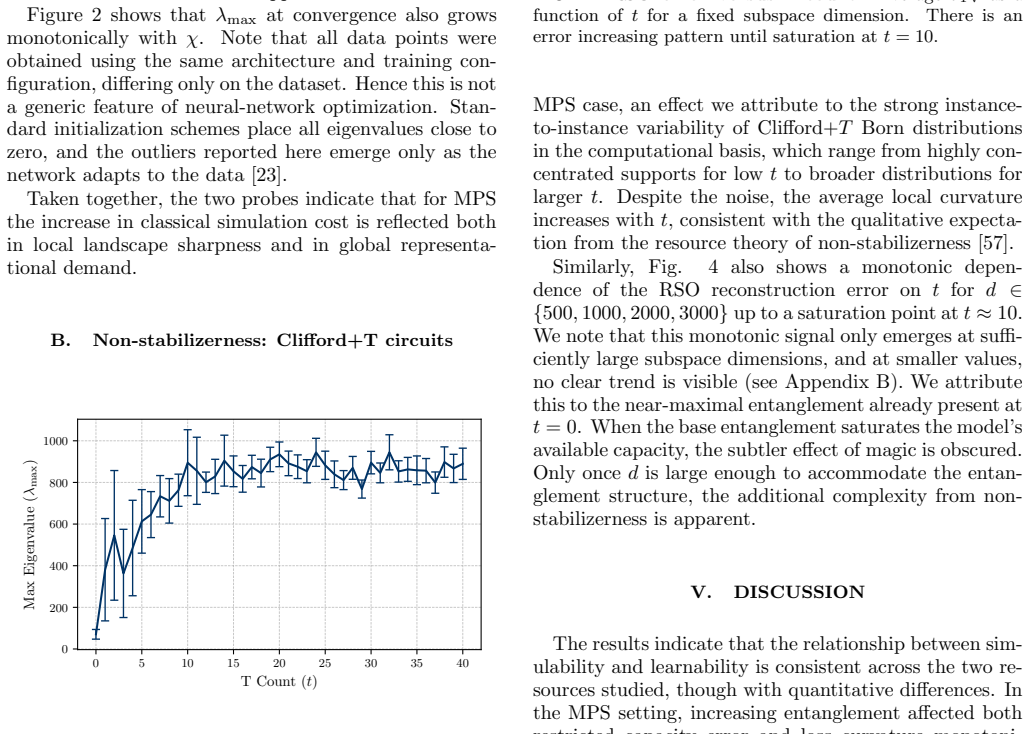
The central claim is that for the regimes studied, classical learnability tracks known simulation complexity measures. Increasing the bond dimension of matrix product states or the number of T gates in Clifford-dominated circuits leads to larger largest Hessian eigenvalues at convergence and degraded reconstruction performance under Random Subspace Optimization for the energy-based generative model.
What carries the argument
The observed tracking between simulation cost parameters (bond dimension for entanglement, T-gate count for non-stabilizerness) and neural-network complexity probes (largest Hessian eigenvalue, Random Subspace Optimization).
If this is right
- Neural-network training dynamics can provide an empirical probe of quantum computational hardness.
- Learnability from samples serves as a proxy for simulation complexity when entanglement or non-stabilizerness is varied.
- Both entanglement and non-stabilizerness increase learning difficulty in the same direction as they increase simulation cost.
- Reconstruction performance degrades under constrained model capacity as either quantum resource grows.
Where Pith is reading between the lines
- The correlation might be tested on other controlled families beyond matrix product states and Clifford-plus-T circuits.
- If the pattern holds, it could help identify quantum data sets that are practically hard for classical learning algorithms.
- Training dynamics might offer a way to rank the effective hardness of quantum systems without running full classical simulations.
Load-bearing premise
The fixed energy-based generative model architecture together with the two chosen probes yield a representative measure of learnability that is not an artifact of this specific model class or of the particular controlled state families.
What would settle it
A counterexample family of quantum states where simulation cost is high yet the model learns the samples to high accuracy, or where simulation cost is low yet learning fails under the same training conditions.
Figures

read the original abstract
We investigate the relationship between two distinct classical approaches to quantum systems: direct simulation from a classical description and sample-based learning from measurement data. While both tasks ultimately aim to reproduce Born-rule statistics, complexity-theoretic results suggest that simulability and learnability need not coincide in general. Here we study this relationship empirically using a fixed deep energy-based generative model trained on measurement samples from controlled families of quantum states. We independently tune two quantum resources associated with classical simulation cost: entanglement, through the bond dimension of random matrix product states, and non-stabilizerness, through the number of T gates in Clifford-dominated circuits. Learning difficulty is characterized using two probes of neural-network complexity: the largest Hessian eigenvalue at convergence and Random Subspace Optimization. For both quantum resources, increasing simulation hardness systematically correlates with sharper loss landscapes and degraded reconstruction performance under constrained capacity. Our results indicate that, within the regimes studied here, classical learnability tracks known simulation complexity measures, suggesting that neural-network training dynamics can provide an empirical probe of quantum computational hardness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically studies the link between classical simulation hardness and sample-based learnability of quantum states. Using a fixed deep energy-based generative model, it independently varies bond dimension in random matrix-product states (controlling entanglement) and T-gate count in Clifford+T circuits (controlling non-stabilizerness), then measures learning difficulty via the largest Hessian eigenvalue at convergence and performance under Random Subspace Optimization. The central finding is that increasing either simulation-cost parameter systematically correlates with sharper loss landscapes and degraded reconstruction under capacity constraints, suggesting neural-network training dynamics can empirically probe quantum computational hardness.
Significance. If the correlation holds beyond the specific model class, the work supplies a concrete empirical bridge between two classically distinct tasks (simulation from description versus learning from samples) that complexity theory suggests need not coincide. The controlled, independent variation of two hardness parameters is a methodological strength. However, the absence of architecture ablations or alternative learnability metrics leaves open whether the observed tracking is general or an artifact of the chosen energy-based model and probes.
major comments (2)
- [Abstract] Abstract (description of experimental setup): the central claim that 'classical learnability tracks known simulation complexity measures' rests on the assumption that the fixed deep energy-based generative model together with the Hessian-eigenvalue and Random-Subspace-Optimization probes yield a representative measure of learnability. No ablation across model architectures, training procedures, or alternative learnability metrics is described, so any systematic bias in how this network family encodes Born-rule statistics of the chosen ensembles would produce a spurious correlation.
- [Abstract] Abstract (reporting of results): the text states that 'increasing simulation hardness systematically correlates with sharper loss landscapes and degraded reconstruction' but supplies no statistical details, error bars, number of independent runs, or significance tests. Without these, the reported 'consistent trends in two learning probes' remain plausible yet unverified.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract (description of experimental setup): the central claim that 'classical learnability tracks known simulation complexity measures' rests on the assumption that the fixed deep energy-based generative model together with the Hessian-eigenvalue and Random-Subspace-Optimization probes yield a representative measure of learnability. No ablation across model architectures, training procedures, or alternative learnability metrics is described, so any systematic bias in how this network family encodes Born-rule statistics of the chosen ensembles would produce a spurious correlation.
Authors: Our experimental design deliberately fixes the learning architecture to isolate the effects of varying the two quantum hardness parameters (bond dimension and T-gate count) while holding all other factors constant. This controlled setup directly tests whether the chosen learnability probes track simulation cost. We agree that the absence of architecture ablations leaves open the question of generality, and we will add an explicit discussion of this scope limitation together with suggestions for future work in the revised manuscript. revision: partial
-
Referee: [Abstract] Abstract (reporting of results): the text states that 'increasing simulation hardness systematically correlates with sharper loss landscapes and degraded reconstruction' but supplies no statistical details, error bars, number of independent runs, or significance tests. Without these, the reported 'consistent trends in two learning probes' remain plausible yet unverified.
Authors: The main text and figures report results averaged over multiple independent runs with error bars; we will revise the abstract to include a concise statement of these statistical details (e.g., number of runs and consistency of trends). revision: yes
Circularity Check
No significant circularity: empirical correlation between independently measured quantities.
full rationale
The paper reports an empirical study in which simulation hardness is controlled via externally defined parameters (bond dimension of random MPS, T-gate count in Clifford+T circuits) while learnability is assessed via separate neural-network probes (largest Hessian eigenvalue at convergence, Random Subspace Optimization performance). No derivation, equation, or self-citation reduces one set of quantities to the other by construction or by fitting a parameter that is then renamed as a prediction. The central claim is an observed correlation within fixed model families, not a self-referential identity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The chosen energy-based generative model is capable of approximating the Born-rule statistics of the sampled quantum states under sufficient training.
- domain assumption Largest Hessian eigenvalue at convergence and Random Subspace Optimization performance are valid quantitative proxies for learning difficulty.
Reference graph
Works this paper leans on
-
[1]
A further limitation concerns the measurement basis
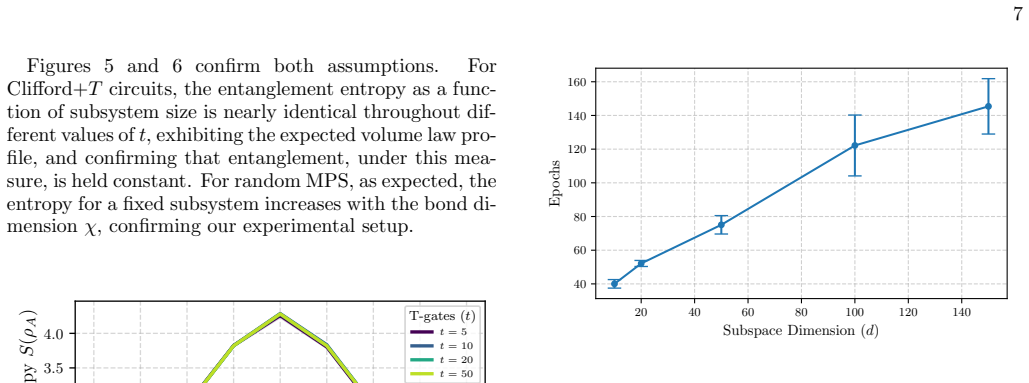
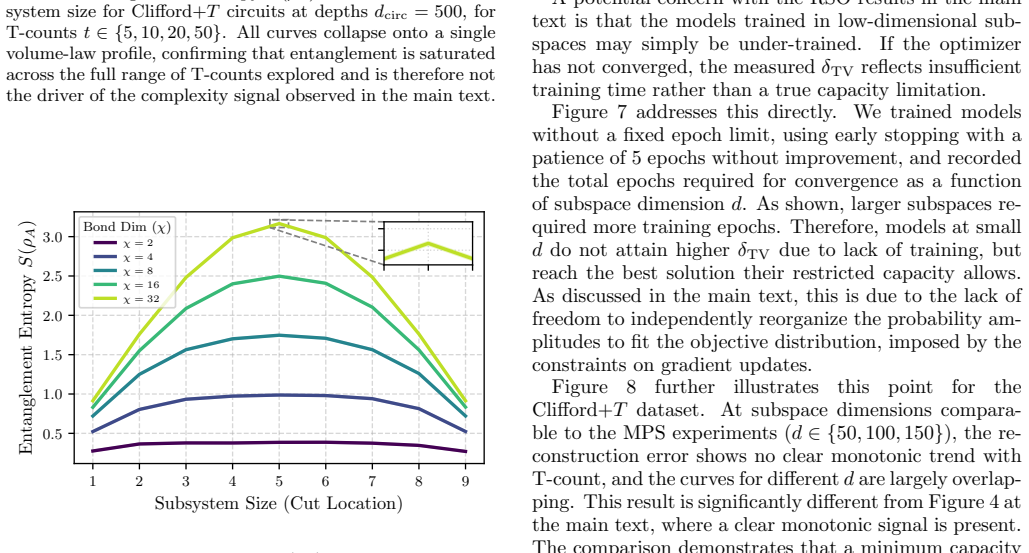
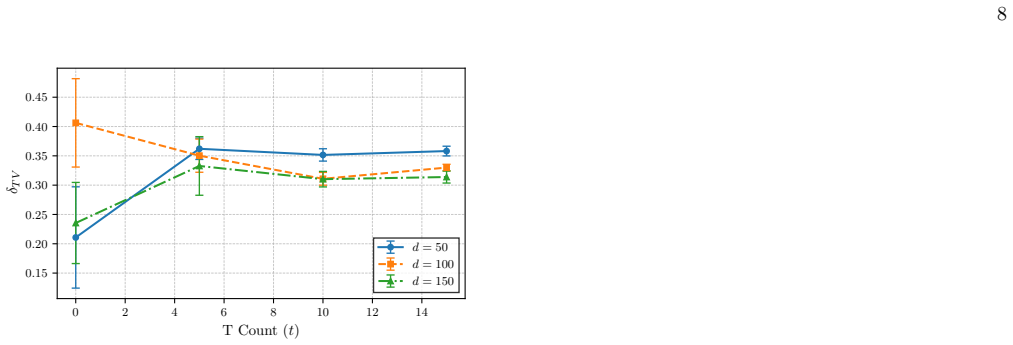
– the smallestdthat recovers a target fraction of full- model performance – would provide a single number per dataset that aims to be consistent across architectures, and would allow a more direct comparison between the two resources. A further limitation concerns the measurement basis. Our model is trained exclusively on Born distributions in the computa...
2025
-
[2]
M. J. Bremner, R. Jozsa, and D. J. Shepherd, Proceed- ings of the Royal Society A: Mathematical, Physical and Engineering Sciences467, 459 (2011)
2011
-
[3]
Aaronson and A
S. Aaronson and A. Arkhipov, inProceedings of the forty- third annual ACM symposium on Theory of computing (2011) pp. 333–342
2011
-
[4]
Aaronson, Proceedings of the Royal Society A: Math- ematical, Physical and Engineering Sciences463, 3089 (2007)
S. Aaronson, Proceedings of the Royal Society A: Math- ematical, Physical and Engineering Sciences463, 3089 (2007)
2007
-
[5]
M. Hinsche, M. Ioannou, A. Nietner, J. Haferkamp, Y. Quek, D. Hangleiter, J.-P. Seifert, J. Eisert, and R. Sweke, Physical Review Letters130, 240602 (2023), arXiv:2207.03140 [quant-ph]
-
[6]
Torlai, G
G. Torlai, G. Mazzola, J. Carrasquilla, M. Troyer, R. Melko, and G. Carleo, Nature physics14, 447 (2018)
2018
-
[7]
Carrasquilla and R
J. Carrasquilla and R. G. Melko, Nature Physics13, 431 (2017)
2017
-
[8]
Carrasquilla, Advances in Physics: X5, 1797528 (2020)
J. Carrasquilla, Advances in Physics: X5, 1797528 (2020)
2020
- [9]
-
[10]
Bittel, A
L. Bittel, A. A. Mele, J. Eisert, and L. Leone, Quantum 9, 1665 (2025)
2025
-
[11]
Huang, R
H.-Y. Huang, R. Kueng, G. Torlai, V. V. Albert, and J. Preskill, Science377, eabk3333 (2022)
2022
-
[12]
A condition under which classical simulability implies efficient state learnability
M. Yoganathan, A condition under which classical simulability implies efficient state learnability (2019), arXiv:1907.08163 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[13]
Ippoliti and V
M. Ippoliti and V. Khemani, PRX Quantum5, 020304 (2024)
2024
- [14]
-
[15]
Kliesch and I
M. Kliesch and I. Roth, PRX quantum2, 010201 (2021)
2021
-
[16]
Hangleiter and J
D. Hangleiter and J. Eisert, Reviews of Modern Physics 95, 035001 (2023)
2023
- [17]
- [18]
- [19]
-
[20]
C. Li, H. Farkhoor, R. Liu, and J. Yosinski, arXiv preprint arXiv:1804.08838 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Ghorbani, S
B. Ghorbani, S. Krishnan, and Y. Xiao, inInterna- tional Conference on Machine Learning(PMLR, 2019) pp. 2232–2241
2019
-
[22]
Schollw¨ ock, Annals of physics326, 96 (2011)
U. Schollw¨ ock, Annals of physics326, 96 (2011)
2011
-
[23]
Bravyi and D
S. Bravyi and D. Gosset, Physical review letters116, 250501 (2016)
2016
-
[24]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
L. Sagun, U. Evci, V. U. Guney, Y. Dauphin, and L. Bot- tou, arXiv preprint arXiv:1706.04454 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Classical simulation of quantum computation, the Gottesman-Knill theorem, and slightly beyond
M. Nest, arXiv preprint arXiv:0811.0898 (2008)
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[26]
The Heisenberg Representation of Quantum Computers
D. Gottesman, arXiv preprint quant-ph/9807006 (1998)
work page internal anchor Pith review Pith/arXiv arXiv 1998
-
[27]
Aaronson and D
S. Aaronson and D. Gottesman, Physical Review A—Atomic, Molecular, and Optical Physics70, 052328 (2004)
2004
-
[28]
Bravyi and A
S. Bravyi and A. Kitaev, Physical Review A—Atomic, Molecular, and Optical Physics71, 022316 (2005)
2005
-
[29]
L. Chen, R. J. Garcia, K. Bu, and A. Jaffe, Physical Review B109, 174207 (2024)
2024
-
[30]
Vidal, Physical review letters91, 147902 (2003)
G. Vidal, Physical review letters91, 147902 (2003). 9
2003
-
[31]
S. Zhou, Z. Yang, A. Hamma, and C. Chamon, SciPost Physics9, 087 (2020)
2020
-
[32]
Iannotti, G
D. Iannotti, G. Esposito, L. C. Venuti, and A. Hamma, Quantum9, 1797 (2025)
2025
-
[33]
Gray, Journal of Open Source Software3, 819 (2018)
J. Gray, Journal of Open Source Software3, 819 (2018)
2018
-
[34]
Garnerone, T
S. Garnerone, T. R. de Oliveira, and P. Zanardi, Physical Review A—Atomic, Molecular, and Optical Physics81, 032336 (2010)
2010
-
[35]
A. Javadi-Abhari, M. Treinish, K. Krsulich, C. J. Wood, J. Lishman, J. Gacon, S. Martiel, P. D. Na- tion, L. S. Bishop, A. W. Cross,et al., arXiv preprint arXiv:2405.08810 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
G. E. Hinton, Neural computation14, 1771 (2002)
2002
-
[37]
N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyan- skiy, and P. T. P. Tang, arXiv preprint arXiv:1609.04836 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[38]
Sharpness-Aware Minimization for Efficiently Improving Generalization
P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur, arXiv preprint arXiv:2010.01412 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[39]
A note on the evaluation of generative models
L. Theis, A. v. d. Oord, and M. Bethge, arXiv preprint arXiv:1511.01844 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[40]
Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond
L. Sagun, L. Bottou, and Y. LeCun, arXiv preprint arXiv:1611.07476 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[41]
Gradient Descent Happens in a Tiny Subspace
G. Gur-Ari, D. A. Roberts, and E. Dyer, arXiv preprint arXiv:1812.04754 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [42]
-
[43]
Chaudhari, A
P. Chaudhari, A. Choromanska, S. Soatto, Y. Le- Cun, C. Baldassi, C. Borgs, J. Chayes, L. Sagun, and R. Zecchina, Journal of Statistical Mechanics: Theory and Experiment2019, 124018 (2019)
2019
-
[44]
LeCun, J
Y. LeCun, J. Denker, and S. Solla, Advances in neural information processing systems2(1989)
1989
-
[45]
Frantar and D
E. Frantar and D. Alistarh, inInternational conference on machine learning(PMLR, 2023) pp. 10323–10337
2023
-
[46]
P. W. Koh and P. Liang, inInternational conference on machine learning(PMLR, 2017) pp. 1885–1894
2017
-
[47]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
A. Power, Y. Burda, H. Edwards, I. Babuschkin, and V. Misra, arXiv preprint arXiv:2201.02177 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
T. Han, L. Adilova, H. Petzka, J. Kleesiek, and M. Kamp, Advances in Neural Information Processing Systems38, 106766 (2026)
2026
-
[49]
Bengio, A
Y. Bengio, A. Courville, and P. Vincent, IEEE transac- tions on pattern analysis and machine intelligence35, 1798 (2013)
2013
-
[50]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen,et al., Iclr1, 3 (2022)
2022
-
[51]
Dettmers, M
T. Dettmers, M. Lewis, Y. Belkada, and L. Zettlemoyer, Advances in neural information processing systems35, 30318 (2022)
2022
-
[52]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
J. Frankle and M. Carbin, arXiv preprint arXiv:1803.03635 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
Barton, J
B. Barton, J. Carrasquilla, C. Roth, and A. Valenti, Ma- chine Learning: Science and Technology (2026)
2026
-
[54]
Raghu, B
M. Raghu, B. Poole, J. Kleinberg, S. Ganguli, and J. Sohl-Dickstein, ininternational conference on machine learning(PMLR, 2017) pp. 2847–2854
2017
-
[55]
Aghajanyan, S
A. Aghajanyan, S. Gupta, and L. Zettlemoyer, inPro- ceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers)(2021) pp. 7319–7328
2021
-
[56]
M. A. Nielsen and I. L. Chuang,Quantum computation and quantum information(Cambridge university press, 2010)
2010
-
[57]
T. M. Cover,Elements of information theory(John Wi- ley & Sons, 1999)
1999
-
[58]
Veitch, S
V. Veitch, S. H. Mousavian, D. Gottesman, and J. Emer- son, New Journal of Physics16, 013009 (2014)
2014
-
[59]
Turkeshi, E
X. Turkeshi, E. Tirrito, and P. Sierant, Nature Commu- nications16, 2575 (2025)
2025
-
[60]
Leone, S
L. Leone, S. F. Oliviero, Y. Zhou, and A. Hamma, Quan- tum5, 453 (2021)
2021
-
[61]
Z. Yao, A. Gholami, S. Shen, M. Mustafa, K. Keutzer, and M. Mahoney, inproceedings of the AAAI conference on artificial intelligence, Vol. 35 (2021) pp. 10665–10673
2021
-
[62]
Brunner, D
N. Brunner, D. Cavalcanti, S. Pironio, V. Scarani, and S. Wehner, Reviews of modern physics86, 419 (2014)
2014
-
[63]
R. Uola, A. C. Costa, H. C. Nguyen, and O. G¨ uhne, Reviews of Modern Physics92, 015001 (2020)
2020
-
[64]
A. Bera, T. Das, D. Sadhukhan, S. Singha Roy, A. Sen, and U. Sen, Reports on Progress in Physics81, 024001 (2018)
2018
-
[65]
Horodecki, P
R. Horodecki, P. Horodecki, M. Horodecki, and K. Horodecki, Reviews of modern physics81, 865 (2009)
2009
-
[66]
Facco, M
E. Facco, M. d’Errico, A. Rodriguez, and A. Laio, Scien- tific reports7, 12140 (2017)
2017
-
[67]
Weimar, L
M. Weimar, L. M. Rachbauer, I. Starshynov, D. Faccio, L. Adilova, D. Bouchet, and S. Rotter, Physical Review X15, 031072 (2025)
2025
-
[68]
Kamkari, B
H. Kamkari, B. L. Ross, R. Hosseinzadeh, J. C. Cresswell, and G. Loaiza-Ganem, Advances in Neural Information Processing Systems37, 38307 (2024)
2024
-
[69]
Tempczyk, R
P. Tempczyk, R. Michaluk, L. Garncarek, P. Spurek, J. Tabor, and A. Golinski, inInternational Conference on Machine Learning(PMLR, 2022) pp. 21205–21231
2022
-
[70]
Passetti, D
G. Passetti, D. Hofmann, P. Neitemeier, L. Grunwald, M. A. Sentef, and D. M. Kennes, Physical Review Letters 131, 036502 (2023)
2023
-
[71]
Denis, A
Z. Denis, A. Sinibaldi, and G. Carleo, Physical Review Letters134, 079701 (2025)
2025
-
[72]
Bukov, A
M. Bukov, A. G. Day, D. Sels, P. Weinberg, A. Polkovnikov, and P. Mehta, Physical Review X8, 031086 (2018)
2018
-
[73]
Valenti, E
A. Valenti, E. van Nieuwenburg, S. Huber, and E. Gre- plova, Physical Review Research1, 033092 (2019)
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.