GAP3D: Generative Alignment of VLM Latents to Patch-Level Embeddings for 3D Generation
Pith reviewed 2026-06-29 13:18 UTC · model grok-4.3
The pith
GAP3D aligns VLM latents to full patch-level image embeddings via diffusion so a frozen 3D generator can use VLM prompts while keeping spatial structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
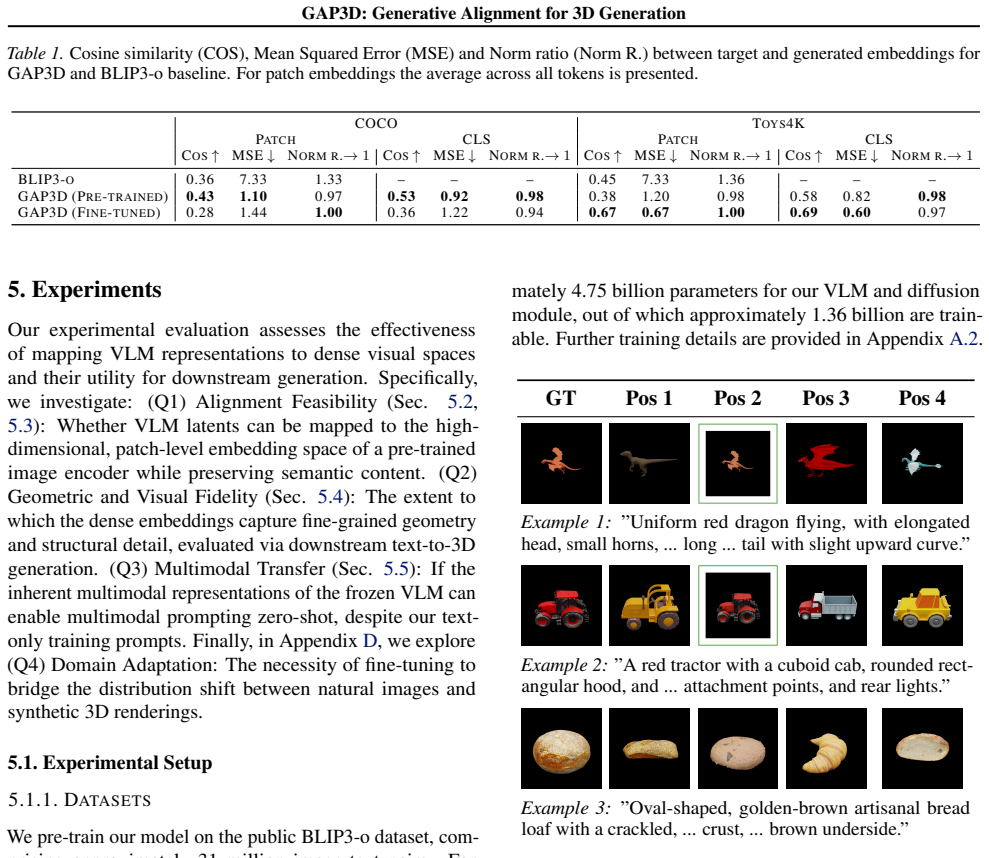
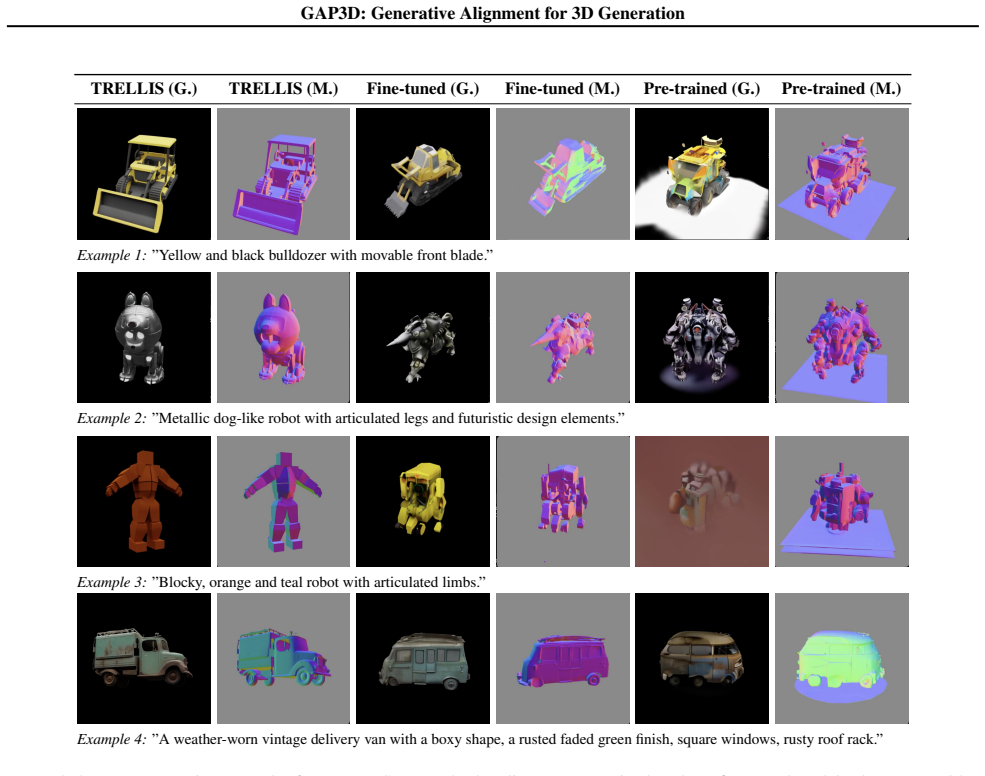
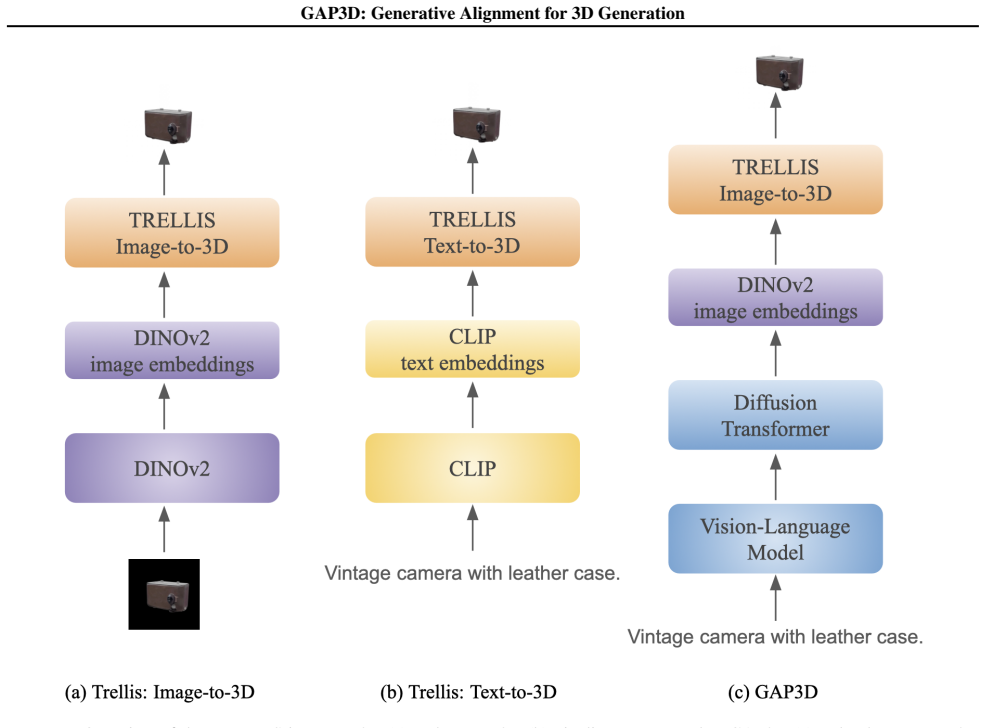
GAP3D is a diffusion-based alignment that maps VLM-generated latents directly onto the complete patch-level feature space of a pre-trained image encoder. This alignment lets a frozen generative model use the VLM as a prompt encoder while preserving the dense spatial conditioning signal required for 3D asset generation. Training occurs primarily on general image-text pairs rather than 3D data, and the method shows zero-shot handling of multimodal prompts despite text-only training.
What carries the argument
A diffusion model trained to map VLM latents onto the complete patch-level feature space of a pre-trained 2D image encoder.
If this is right
- A 3D generative model can remain frozen and still accept VLM prompts with preserved spatial structure.
- Training the alignment uses mainly general-domain image-text pairs rather than large 3D datasets.
- Zero-shot multimodal prompt handling emerges even though training used only text inputs.
- The representation gap between VLM and image-encoder spaces can be partially closed by diffusion alignment.
Where Pith is reading between the lines
- The same alignment step could be applied to other tasks that need dense conditioning signals from foundation models.
- Modular insertion of VLMs into existing generators reduces the cost of adapting to new prompt encoders.
- Improving the alignment to capture finer geometric details would likely raise the quality ceiling for 3D output.
Load-bearing premise
The aligned patch features from a 2D image encoder contain enough geometric information to drive effective 3D asset generation.
What would settle it
Measure 3D generation quality when the downstream model receives the aligned VLM features versus when it receives the original image-encoder patch features directly; a large drop in quality would indicate the alignment does not supply sufficient structure.
Figures



read the original abstract
Recent approaches integrating vision-language models (VLMs) as prompt encoders for generative model conditioning typically rely on expensive end-to-end training or map features to compressed representations, discarding the dense spatial structure required for geometry-aware tasks like 3D asset generation. To address this, we propose GAP3D, a modular, diffusion-based approach that aligns VLM-generated latents directly to the complete, patch-level feature space of a pre-trained image encoder, enabling a frozen downstream generative model to utilize a VLM as prompt encoder while maintaining a spatially structured conditioning signal. Evaluated on 3D asset generation, our method bypasses the need for large-scale 3D data by training mainly on general-domain image-text pairs. It also exhibits emergent zero-shot capabilities for multimodal prompts, despite being trained exclusively on text input. Finally, while currently prioritizing high-level semantics over fine-grained detail, GAP3D demonstrates that the representation gap between VLM and image-encoder feature spaces can be partially bridged through diffusion-based alignment, taking the first steps towards a modular integration of foundation models through generative alignment to dense embedding spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce GAP3D, a modular diffusion-based approach that aligns VLM-generated latents directly to the complete patch-level feature space of a pre-trained image encoder. This enables a frozen downstream 3D generative model to use a VLM as prompt encoder while preserving a spatially structured conditioning signal. Training occurs mainly on general-domain image-text pairs (bypassing large-scale 3D data), with reported emergent zero-shot capabilities for multimodal prompts despite text-only training; the abstract notes prioritization of high-level semantics over fine-grained detail.
Significance. If the alignment successfully transfers geometry-aware structure, the modular design would allow efficient integration of existing VLMs into 3D pipelines without end-to-end retraining or compression of spatial features, representing a practical advance in data-efficient 3D generation. The emergent multimodal behavior, if substantiated, would further strengthen the case for generative alignment to dense embedding spaces.
major comments (1)
- [Abstract] Abstract: The central claim that diffusion-aligned VLM latents supply a 'spatially structured conditioning signal' sufficient for geometry-aware 3D asset generation rests on the assumption that patch-level features from 2D image encoders encode transferable 3D structure. However, the description provides no multi-view, depth, or 3D-consistency term; training targets derive exclusively from 2D appearance and layout statistics on image-text pairs. This directly engages the load-bearing question of whether the learned mapping can support accurate 3D outputs.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comment on the abstract. We address the concern point-by-point below and agree that clarification is warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that diffusion-aligned VLM latents supply a 'spatially structured conditioning signal' sufficient for geometry-aware 3D asset generation rests on the assumption that patch-level features from 2D image encoders encode transferable 3D structure. However, the description provides no multi-view, depth, or 3D-consistency term; training targets derive exclusively from 2D appearance and layout statistics on image-text pairs. This directly engages the load-bearing question of whether the learned mapping can support accurate 3D outputs.
Authors: We agree that the alignment training uses only 2D image-text pairs and introduces no explicit multi-view, depth, or 3D-consistency losses. The method is intentionally designed this way to avoid dependence on large-scale 3D data for the alignment stage. The patch-level feature space is taken from a frozen pre-trained image encoder (e.g., DINOv2-style) whose embeddings have been shown in prior literature to carry implicit geometric cues derived from its original 2D training corpus. Critically, the downstream 3D generative model is frozen and was itself trained to map these exact patch embeddings to 3D geometry; thus the 3D structure is supplied by that model rather than by the alignment. The diffusion alignment simply learns to produce latents inside the same embedding space from VLM inputs. Empirical results on 3D asset generation tasks support that the aligned signal is usable by the downstream model for geometry-aware outputs, albeit with the acknowledged emphasis on high-level semantics. We will revise the abstract to more explicitly separate the role of the alignment (mapping to the existing patch space) from the geometric capacity of the frozen 3D model. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, fitted parameters, or derivation steps that reduce to self-referential definitions, self-citations, or renamed inputs. The method is presented as a diffusion-based alignment trained on image-text pairs to map VLM latents to patch embeddings, with claims about bypassing 3D data and enabling frozen downstream models; these are forward proposals without any load-bearing reduction to prior self-referential results or fitted quantities called predictions. No self-citation load-bearing, ansatz smuggling, or uniqueness theorems from authors are invoked in the text. The derivation chain is self-contained as a proposed technique evaluated on 3D tasks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
cc/paper_files/paper/2023/file/ 70364304877b5e767de4e9a2a511be0c-Paper-Datasets_ and_Benchmarks.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2023/file/ 70364304877b5e767de4e9a2a511be0c-Paper-Datasets_ and_Benchmarks.pdf. Dong, R., Han, C., Peng, Y ., Qi, Z., Ge, Z., Yang, J., Zhao, L., Sun, J., Zhou, H., Wei, H., Kong, X., Zhang, X., Ma, K., and Yi, L. DreamLLM: Synergistic mul- timodal comprehension and creation. InThe Twelfth Internationa...
2023
-
[2]
Han, X., Jin, L., Liu, X., and Liang, P
URL https://openreview.net/forum? id=y01KGvd9Bw. Han, X., Jin, L., Liu, X., and Liang, P. P. Progressive compositionality in text-to-image generative models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=S85PP4xjFD. Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, ...
2025
-
[3]
cc/paper_files/paper/2017/file/ 8a1d694707eb0fefe65871369074926d-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2017/file/ 8a1d694707eb0fefe65871369074926d-Paper. pdf. Huang, K., Duan, C., Sun, K., Xie, E., Li, Z., and Liu, X. T2I-CompBench++: An Enhanced and Comprehensive Benchmark for Compositional Text-to-Image Generation .IEEE Transactions on Pattern Analysis & Machine Intelligence, 47(05):3563–3579, May 202...
-
[4]
Springer-Verlag. ISBN 978-3-031-73234-8. doi: 10.1007/978-3-031-73235-5 7. URL https://doi. org/10.1007/978-3-031-73235-5_7. Lee, T., Yasunaga, M., Meng, C., Mai, Y ., Park, J. S., Gupta, A., Zhang, Y ., Narayanan, D., Teufel, H. B., Bellagente, M., Kang, M., Park, T., Leskovec, J., Zhu, J.-Y ., Fei-Fei, L., Wu, J., Ermon, S., and Liang, P. Holistic evalu...
-
[5]
cc/paper_files/paper/2017/file/ d8bf84be3800d12f74d8b05e9b89836f-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2017/file/ d8bf84be3800d12f74d8b05e9b89836f-Paper. pdf. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transferable visual models from natural language supervision. In Meila, M. and Zhang, T...
2017
-
[6]
The background is black and no other objects are present
URL https://api.semanticscholar. org/CorpusID:231639354. Szegedy, C., Vanhoucke, V ., Ioffe, S., Shlens, J., and Wo- jna, Z. Rethinking the inception architecture for com- puter vision. In2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las V egas, NV , USA, June 27-30, 2016, pp. 2818–2826. IEEE Com- puter Society, 2016. doi: 10...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.