FedQHD: Closed-Form Function-Space Federated Reinforcement Learning
Pith reviewed 2026-06-29 13:22 UTC · model grok-4.3
The pith
Hyperdimensional encoders with linear readouts let federated Q-learning perform closed-form function-space updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
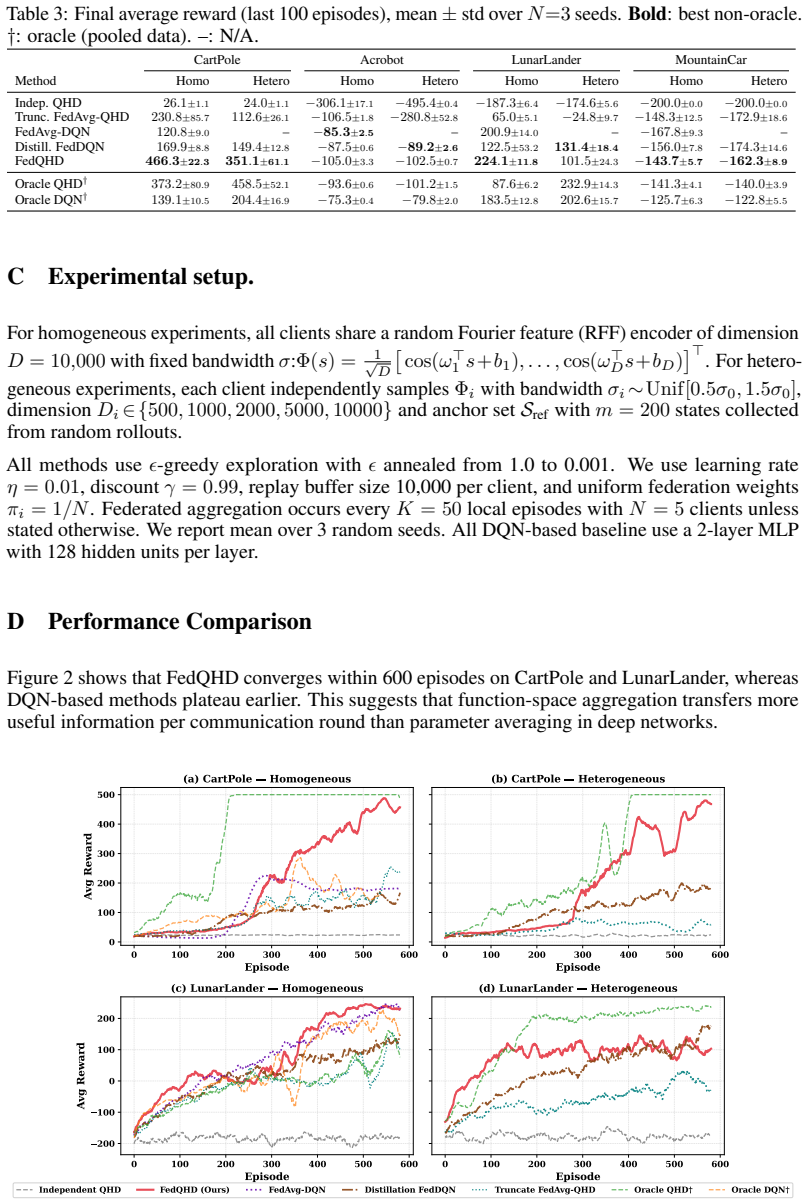
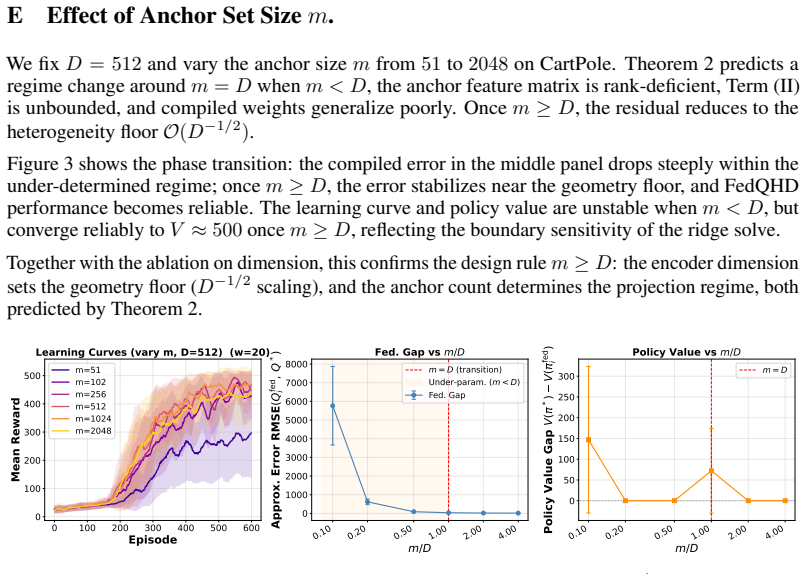
FedQHD represents each client's Q-function by a hyperdimensional random-feature encoder followed by a linear readout matrix; this structure makes the function-space consensus update coincide with weighted averaging of the readout matrices when encoders are identical and, when encoders are heterogeneous, reduces the federation gap to a multiple of the encoder heterogeneity floor once the anchor-state count m satisfies m greater than or equal to the local dimension D_i.
What carries the argument
Hyperdimensional random-feature state encoder with linear readout matrix, which renders the Q-function linear in the trainable parameters and thereby permits exact or bounded closed-form server aggregation via anchor-state averaging followed by ridge projection.
If this is right
- With identical encoders the server average of readout matrices equals the weighted average of the client Q-functions exactly.
- The federation gap decomposes into subspace misalignment, anchor-set conditioning, and regularization bias.
- When the anchor count m is at least the client dimension D_i the gap is controlled solely by the encoder heterogeneity floor.
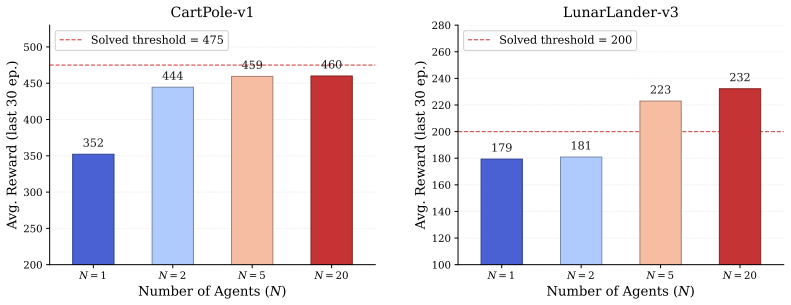
- On continuous-state discrete-action benchmarks the method matches or exceeds parameter-averaging and distillation baselines at substantially lower compute cost.
Where Pith is reading between the lines
- The same linear readout structure could support closed-form aggregation in other federated settings that require function-space consistency across heterogeneous clients.
- Replacing random anchors with states sampled from the actual visitation distribution might further reduce the conditioning term in practice.
- The decomposition suggests that encoder design choices directly trade off against federation error once the anchor regime is satisfied.
Load-bearing premise
The anchor-state set is representative enough that ridge projection error is dominated by subspace misalignment rather than sampling variance or distribution shift between the anchors and the true state distribution.
What would settle it
An experiment in which the measured federation gap fails to approach a small multiple of the encoder heterogeneity floor once the number of anchor states reaches or exceeds each client's dimension.
Figures
read the original abstract
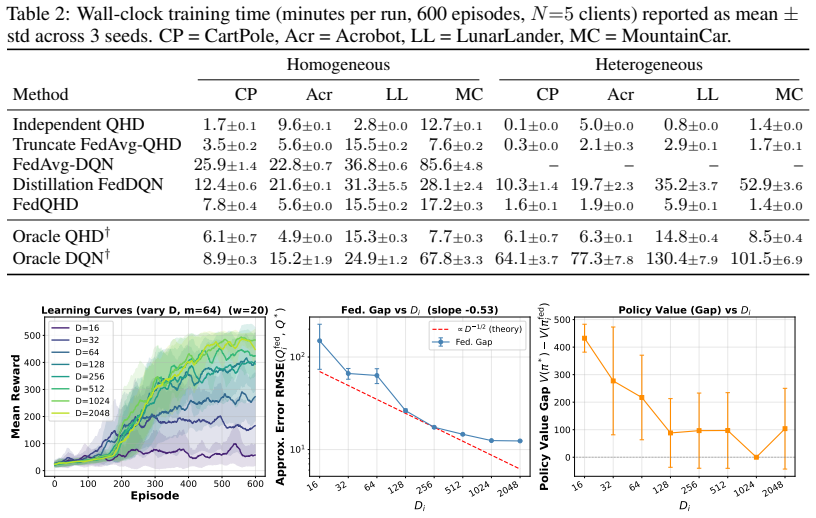
Federated reinforcement learning enables decentralized agents to collaboratively improve policies or value estimates without exchanging raw trajectories. However, FedAvg-style parameter averaging is not function-space consistent: when clients use heterogeneous encoders or even identical nonlinear networks, averaged parameters need not correspond to the weighted average of client value functions in any common function space. We propose FedQHD, a federated Q-learning method using hyperdimensional (random-feature) state encoders with a linear readout, so that Q-functions are nonlinear in state yet linear in trainable parameters. This linear structure enables closed-form aggregation. With a shared encoder, the function-space consensus update coincides exactly with weighted averaging of local readout matrices. With heterogeneous encoders, the server constructs a global teacher by averaging client Q-values on a shared anchor-state set, and each client compiles this teacher into its local representation via a single ridge projection. We formalize the federation gap -- the error incurred when compiling a federated teacher into a heterogeneous client representation -- relative to a client-specific oracle projection. We show that this gap decomposes into subspace misalignment, anchor-set conditioning, and regularization bias. We further identify the anchor-to-dimension ratio $m \geq D_i$ as the well-conditioned regime in which the gap reduces to a multiple of the encoder heterogeneity floor. On four continuous-state, discrete-action control benchmarks, FedQHD matches or outperforms FedAvg-style baselines and distillation-based alternatives while requiring substantially less computation, and the empirical dependence of the federation gap on encoder dimension matches our theoretical analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FedQHD, a federated Q-learning algorithm that employs hyperdimensional random-feature encoders paired with linear readouts to enable closed-form function-space aggregation. With shared encoders the consensus update matches weighted averaging of local readouts exactly; with heterogeneous encoders the server builds a global teacher via anchor-state averaging and clients recover it by ridge projection. The federation gap is decomposed into subspace misalignment, anchor-set conditioning, and regularization bias, with the claim that the gap reduces to a multiple of the encoder-heterogeneity floor once m ≥ D_i. Experiments on four continuous-state discrete-action benchmarks show competitive or superior performance to FedAvg-style and distillation baselines at lower compute cost, and the observed gap scaling with dimension is reported to match the derived dependence.
Significance. If the reduction of the federation gap to encoder heterogeneity holds under the stated anchor-set conditions and transfers to the reported benchmarks, the work supplies a theoretically grounded alternative to parameter averaging that preserves function-space consistency while supporting heterogeneous encoders. The closed-form aggregation and explicit gap decomposition constitute a concrete advance for federated RL with nonlinear function approximators.
major comments (2)
- [§4.2–4.3] §4.2–4.3 (Federation-gap decomposition and m ≥ D_i regime): The reduction of the gap to a multiple of the encoder-heterogeneity floor is derived under the assumption that ridge-projection error on the anchor set is dominated by subspace misalignment rather than sampling variance or distribution shift between anchor states and the true state distribution. The manuscript provides no empirical check (e.g., comparison of projection residuals on anchor versus held-out states, or sensitivity to anchor-set sampling) that this dominance condition holds for the anchor sets actually used on the four benchmarks; without such verification the theoretical guarantee does not demonstrably apply to the reported empirical results.
- [§5] §5 (Experiments): The claim that “the empirical dependence of the federation gap on encoder dimension matches our theoretical analysis” is stated without reporting the precise quantitative metric used for the match (e.g., slope of gap vs. 1/D or R² of the predicted scaling), nor are confidence intervals or ablation results over anchor-set size m shown; this leaves the empirical support for the m ≥ D_i regime under-specified.
minor comments (2)
- [§5] Notation for the anchor-set size m and client dimension D_i is introduced without an explicit statement of how m is chosen relative to the state-space dimension or trajectory length in the experimental section.
- [§3, §5] The abstract and §3 refer to “hyperdimensional (random-feature) state encoders” but the precise distribution from which the random features are drawn (e.g., Gaussian, Rademacher) is not restated in the experimental protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the theoretical and computational contributions of FedQHD. We address each major comment below with clarifications and planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4.2–4.3] §4.2–4.3 (Federation-gap decomposition and m ≥ D_i regime): The reduction of the gap to a multiple of the encoder-heterogeneity floor is derived under the assumption that ridge-projection error on the anchor set is dominated by subspace misalignment rather than sampling variance or distribution shift between anchor states and the true state distribution. The manuscript provides no empirical check (e.g., comparison of projection residuals on anchor versus held-out states, or sensitivity to anchor-set sampling) that this dominance condition holds for the anchor sets actually used on the four benchmarks; without such verification the theoretical guarantee does not demonstrably apply to the reported empirical results.
Authors: We agree that verifying the dominance of subspace misalignment over sampling variance and distribution shift would strengthen the connection between the theory in §4.2–4.3 and the benchmarks. In the revised manuscript we will add an empirical check that compares ridge-projection residuals on the anchor states against residuals on a held-out set drawn from the true state distribution, together with a sensitivity analysis over different anchor-set samplings. These additions will confirm whether the stated dominance condition holds for the anchor sets employed in the four benchmarks. revision: yes
-
Referee: [§5] §5 (Experiments): The claim that “the empirical dependence of the federation gap on encoder dimension matches our theoretical analysis” is stated without reporting the precise quantitative metric used for the match (e.g., slope of gap vs. 1/D or R² of the predicted scaling), nor are confidence intervals or ablation results over anchor-set size m shown; this leaves the empirical support for the m ≥ D_i regime under-specified.
Authors: We accept that the quantitative details of the claimed match should be reported explicitly. The revision will state the precise metrics (slope of gap versus 1/D and R² of the linear fit), include confidence intervals on the measured gaps, and add an ablation over anchor-set size m. These changes will make the empirical support for the m ≥ D_i regime fully specified. revision: yes
Circularity Check
No significant circularity; derivation follows from linear readout architecture and ridge projection algebra.
full rationale
The paper selects hyperdimensional encoders with linear readouts precisely so that Q-functions are linear in parameters, making weighted averaging and ridge-based compilation closed-form by direct linear algebra (no self-definition or fitted prediction). The federation-gap decomposition into misalignment/conditioning/bias terms and the m ≥ D_i reduction are stated as formal results from the projection equations, without reducing to data fits or self-citation chains. Anchor-state representativeness is an external modeling assumption for transferring the bound to practice, not a definitional step inside the derivation itself. No load-bearing self-citations or ansatzes are indicated in the provided text.
Axiom & Free-Parameter Ledger
free parameters (2)
- regularization parameter lambda
- anchor-set size m
axioms (1)
- standard math Ridge regression yields the minimum-norm solution that matches the teacher on the anchor set.
Reference graph
Works this paper leans on
-
[1]
On the Equivalence between Kernel Quadrature Rules and Random Feature Expansions
Francis Bach. On the equivalence between quadrature rules and random features.arXiv preprint arXiv:1502.06800, 135,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym.arXiv preprint arXiv:1606.01540,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Hong-You Chen and Wei-Lun Chao. Fedbe: Making bayesian model ensemble applicable to federated learning.arXiv preprint arXiv:2009.01974,
-
[4]
Xiaofeng Fan, Yining Ma, Zhongxiang Dai, Wei Jing, Cheston Tan, and Bryan Kian Hsiang Low
URL https://arxiv.org/ abs/2301.11135. Xiaofeng Fan, Yining Ma, Zhongxiang Dai, Wei Jing, Cheston Tan, and Bryan Kian Hsiang Low. Fault-tolerant federated reinforcement learning with theoretical guarantee.Advances in neural information processing systems, 34:1007–1021,
-
[5]
Distilling the Knowledge in a Neural Network
URLhttps://arxiv.org/abs/1503.02531. Wenzheng Jiang, Ji Wang, Xiongtao Zhang, Weidong Bao, Cheston Tan, and Flint Xiaofeng Fan. Fedhpd: Heterogeneous federated reinforcement learning via policy distillation.arXiv preprint arXiv:2502.00870,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith
URLhttps://arxiv.org/abs/1910.03581. Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks.Proceedings of Machine learning and systems, 2:429–450,
-
[7]
Boyi Liu, Lujia Wang, and Ming Liu
URLhttps://arxiv.org/abs/2006.07242. Boyi Liu, Lujia Wang, and Ming Liu. Lifelong federated reinforcement learning: a learning archi- tecture for navigation in cloud robotic systems.IEEE Robotics and Automation Letters, 4(4): 4555–4562,
-
[8]
Jiaju Qi, Qihao Zhou, Lei Lei, and Kan Zheng. Federated reinforcement learning: Techniques, applications, and open challenges.arXiv preprint arXiv:2108.11887,
-
[9]
URLhttps://arxiv.org/abs/1511.06295. Yee Teh, Victor Bapst, Wojciech M Czarnecki, John Quan, James Kirkpatrick, Raia Hadsell, Nicolas Heess, and Razvan Pascanu. Distral: Robust multitask reinforcement learning.Advances in neural information processing systems, 30,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://arxiv.org/abs/1901.08277. A QHD Semi-Gradient Update For completeness, we record the semi-gradient TD update rule used by QHD [Ni et al., 2022a]. Given a transition (s, a, r, s′), a delayed target weight W − i , and learning rate η, define the bootstrapped target y=r+γℜ Φi(s′)H w− i,a⋆ , a ⋆ = arg max a′∈A Qi(s′, a′). The semi-gradient update o...
-
[11]
Error RMSE(Qfed i , Q * ) Fed
0 100 200 300 400 500 600 Episode 0 100 200 300 400 500Mean Reward Learning Curves (vary m, D=512) (w=20) m=51 m=102 m=256 m=512 m=1024 m=2048 0.10 0.20 0.50 1.00 2.00 4.00 m/D 0 1000 2000 3000 4000 5000 6000 7000 8000 Approx. Error RMSE(Qfed i , Q * ) Fed. Gap vs m/D m = D (transition) Under-param. (m < D) Fed. Gap 0.10 0.20 0.50 1.00 2.00 4.00 m/D 0 50 ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.