BCER Agent: Reliable Long-Horizon MRI Workflow Execution via Compilation, Artifact Binding, and Bounded Local Recovery
Pith reviewed 2026-06-29 09:09 UTC · model grok-4.3
The pith
BCER decouples high-level planning from execution and adds bounded local recovery to make long-horizon MRI agent workflows reliable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
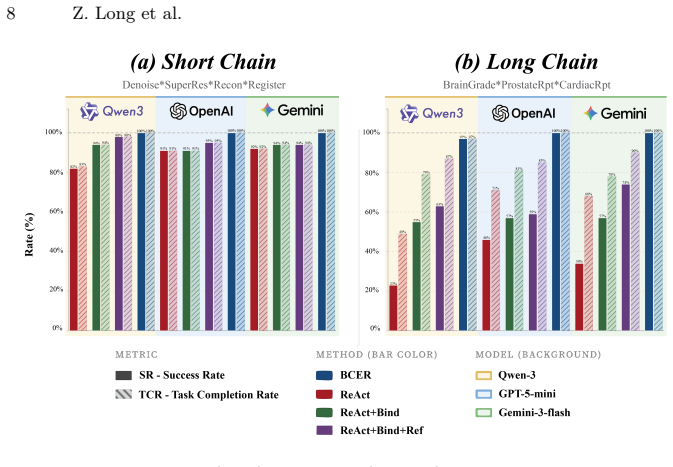
BCER achieves dependable long-horizon MRI workflow execution by decoupling high-level planning from execution and providing bounded local recovery. On a multi-organ benchmark covering brain, prostate, and cardiac tasks, it produces consistent gains in end-to-end execution over reactive baselines, with the largest improvements on long-chain workflows, while also maintaining explicit links between outputs and intermediate artifacts for auditability.
What carries the argument
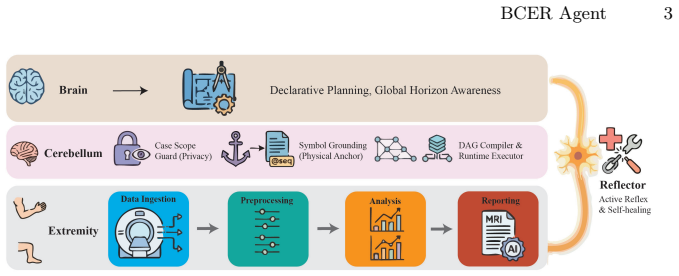
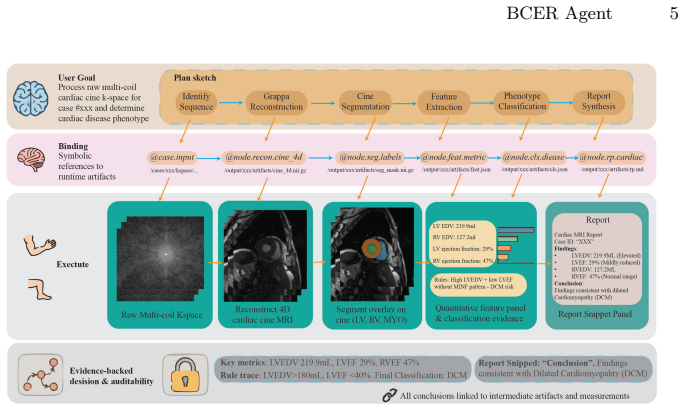
The BCER controller, which compiles workflows, binds artifacts across steps, and applies bounded local recovery to prevent cascading failures.
If this is right
- End-to-end execution success rises relative to reactive baselines on the tested tasks.
- Gains are largest on long-chain workflows that contain many interdependent steps.
- Explicit artifact binding produces traceable links from final outputs back to all intermediate measurements.
- The same controller architecture works across short- and long-chain variants of brain, prostate, and cardiac MRI pipelines.
Where Pith is reading between the lines
- The same compilation-plus-binding pattern could be tested on other volumetric modalities such as CT or PET pipelines.
- Bounded recovery may lower the frequency of full restarts in any agent system whose tasks share intermediate data products.
- Auditability through artifact links offers a route to post-hoc verification that is independent of the backbone model used for planning.
Load-bearing premise
The multi-organ MRI benchmark with matched task contracts across controller variants accurately represents the error modes and interdependencies of real-world long-horizon MRI analysis pipelines.
What would settle it
A controlled test in which BCER shows no reduction in cascading breakdowns or end-to-end failures on long-chain workflows from the same benchmark would falsify the central performance claim.
Figures
read the original abstract
Many recent medical VLM and agent studies are benchmarked on 2D images or comparatively short tool-calling exchanges, whereas real MRI analysis typically demands long, interdependent pipelines that operate on 3D/4D volumetric data. Under these conditions, reactive tool-calling agents are prone to cascading breakdowns triggered by faulty intermediate references, mismatched tool arguments, and limited control over cross-step dependencies. To address this, we introduce BCER (Brain-Cerebellum-Extremity-Reflector), a controller architecture aimed at dependable long-horizon MRI workflow execution. BCER decouples high-level planning from execution and provides bounded local recovery. We assess BCER on a multi-organ MRI benchmark covering brain, prostate, and cardiac tasks with both short- and long-chain workflows, using matched task contracts across controller variants and several backbone models. Relative to reactive baselines, BCER yields consistent improvements in end-to-end execution, with the most pronounced gains observed on long-chain workflows. BCER additionally enables auditability by maintaining explicit links between final outputs and intermediate artifacts and measurements. Code and benchmark are released at https://github.com/Albertlongzi/BCER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the BCER (Brain-Cerebellum-Extremity-Reflector) controller architecture for reliable long-horizon MRI workflow execution. It decouples high-level planning from execution and provides bounded local recovery. The approach is evaluated on a multi-organ MRI benchmark covering brain, prostate, and cardiac tasks with both short- and long-chain workflows using matched task contracts across controller variants and backbone models. The authors claim that BCER yields consistent improvements in end-to-end execution relative to reactive baselines, with the most pronounced gains on long-chain workflows, and that it enables auditability via explicit links between outputs and intermediate artifacts. Code and benchmark are released.
Significance. If the empirical claims hold, the work addresses a relevant gap in applying vision-language models and agents to complex, long-horizon medical imaging pipelines on 3D/4D volumetric data, where reactive agents are prone to cascading failures. The emphasis on auditability through artifact binding and the public release of code and benchmark constitute clear strengths for reproducibility.
major comments (2)
- Abstract: the central claim that BCER 'yields consistent improvements in end-to-end execution' with 'most pronounced gains observed on long-chain workflows' is asserted without any quantitative metrics, tables, error bars, or statistical tests, preventing evaluation of effect size or reliability.
- Benchmark and evaluation sections: the multi-organ MRI benchmark with matched task contracts is presented as representative of real-world error modes and interdependencies, but without explicit definitions of task contracts, error-mode taxonomy, or interdependency measures, the validity of the cross-controller comparison cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and benchmark description. We address each major comment below and have revised the manuscript to strengthen clarity and substantiation of claims.
read point-by-point responses
-
Referee: Abstract: the central claim that BCER 'yields consistent improvements in end-to-end execution' with 'most pronounced gains observed on long-chain workflows' is asserted without any quantitative metrics, tables, error bars, or statistical tests, preventing evaluation of effect size or reliability.
Authors: We agree that the abstract would benefit from quantitative support. The results section already contains the supporting data (success rates, chain-length breakdowns, and comparisons across backbones), but the abstract summarizes these without numbers. In the revision we have updated the abstract to report key metrics (e.g., end-to-end success-rate deltas for short- versus long-chain workflows) with explicit references to the corresponding tables and error-bar figures. revision: yes
-
Referee: Benchmark and evaluation sections: the multi-organ MRI benchmark with matched task contracts is presented as representative of real-world error modes and interdependencies, but without explicit definitions of task contracts, error-mode taxonomy, or interdependency measures, the validity of the cross-controller comparison cannot be assessed.
Authors: We appreciate this point. The manuscript introduces matched task contracts and an error-mode taxonomy in the benchmark construction, yet the definitions were not stated with sufficient formality. The revised version adds a dedicated subsection that formally defines task contracts, enumerates the error-mode taxonomy with examples drawn from the three organs, and specifies the interdependency measures used to generate long-chain workflows. These additions make the cross-controller evaluation criteria fully explicit. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces the BCER controller architecture for long-horizon MRI workflows and evaluates it through empirical comparisons to reactive baselines on a multi-organ MRI benchmark with matched task contracts. No equations, parameter fittings, derivation chains, or self-referential definitions appear in the abstract or the described content. Central claims rest on observed end-to-end execution improvements rather than any reduction to inputs by construction, self-citation load-bearing premises, or ansatz smuggling. The benchmark and artifact-binding mechanisms are presented as external evaluation constructs, keeping the work self-contained against independent performance metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reactive tool-calling agents are prone to cascading breakdowns triggered by faulty intermediate references and mismatched tool arguments in long MRI pipelines
invented entities (1)
-
BCER controller architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Computers in biology and medicine148, 105817 (2022)
Adams, L.C., Makowski, M.R., Engel, G., Rattunde, M., Busch, F., Asbach, P., Niehues, S.M., Vinayahalingam, S., van Ginneken, B., Litjens, G., et al.: Prostate158-an expert-annotated 3t mri dataset and algorithm for prostate cancer detection. Computers in biology and medicine148, 105817 (2022)
2022
-
[2]
Bakas, S., Reyes, M., Jakab, A., Bauer, S., Rempfler, M., Crimi, A., Shinohara, R.T., Berger, C., Ha, S.M., Rozycki, M., et al.: Identifying the best machine learn- ing algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the brats challenge. arXiv preprint arXiv:1811.02629 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Bernard, O., Lalande, A., Zotti, C., Cervenansky, F., Yang, X., Heng, P.A., Cetin, I., Lekadir, K., Camara, O., Ballester, M.A.G., et al.: Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: is the problem solved? IEEE transactions on medical imaging37(11), 2514–2525 (2018)
2018
-
[4]
Frontiers in Neuroinformatics5, 13 (2011)
Gorgolewski, K., Burns, C.D., Madison, C., Clark, D., Halchenko, Y.O., Waskom, M.L., Ghosh, S.S.: Nipype: A flexible, lightweight and extensible neuroimaging data processing framework in python. Frontiers in Neuroinformatics5, 13 (2011). https://doi.org/10.3389/fninf.2011.00013
-
[5]
Advances in Neural Information Processing Systems37, 79410–79452 (2024)
Kim, Y., Park, C., Jeong, H., Chan, Y.S., Xu, X., McDuff, D., Lee, H., Ghassemi, M., Breazeal, C., Park, H.W.: Mdagents: An adaptive collaboration of llms for medical decision-making. Advances in Neural Information Processing Systems37, 79410–79452 (2024)
2024
-
[6]
Scientific Data5, 180251 (2018).https://doi.org/10.1038/sdata.2018.251
Lau, J.J., Gayen, S., Ben Abacha, A., Demner-Fushman, D.: A dataset of clinically generated visual questions and answers about radiology images. Scientific Data5, 180251 (2018).https://doi.org/10.1038/sdata.2018.251
-
[7]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Li, B., Yan, T., Pan, Y., Luo, J., Ji, R., Ding, J., Xu, Z., Liu, S., Dong, H., Lin, Z., et al.: Mmedagent: Learning to use medical tools with multi-modal agent. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 8745–8760 (2024)
2024
-
[8]
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day (2023).https://doi.org/10.48550/arXiv.2306.00890, https://arxiv.org/abs/2306.00890
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.00890 2023
-
[9]
https://doi.org/10.48550/arXiv.2102.09542,https://arxiv.org/abs/2102
Liu, B., Zhan, L.M., Xu, L., Ma, L., Yang, Y., Wu, X.M.: Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering (2021). https://doi.org/10.48550/arXiv.2102.09542,https://arxiv.org/abs/2102. 09542
-
[10]
arXiv preprint arXiv:2601.00226 (2026)
Long, Z., Nader, B., Wang, L., Malaji, A.V., Yang, C.C., Sun, H., Saouaf, R., Daskivich, T., Kim, H., Xie, Y., et al.: Let distortion guide restoration (dgr): A physics-informed learning framework for prostate diffusion mri. arXiv preprint arXiv:2601.00226 (2026)
-
[11]
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Qian, Y., Choi, Y.: Self-refine: Iterative refinement with self-feedback (2023).https://doi.org/10.48550/arXiv.2303.17651,https:// arxiv.org/abs/2303.17651
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.17651 2023
-
[12]
In: International MICCAI brainlesion workshop
Myronenko,A.:3dmribraintumorsegmentationusingautoencoderregularization. In: International MICCAI brainlesion workshop. pp. 311–320. Springer (2018)
2018
-
[13]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Nath, V., Li, W., Yang, D., Myronenko, A., Zheng, M., Lu, Y., Liu, Z., Yin, H., Law, Y.M., Tang, Y., et al.: Vila-m3: Enhancing vision-language models with medical expert knowledge. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14788–14798 (2025) BCER Agent 11
2025
-
[14]
Nature Medicine28(1), 31–38 (2022).https://doi.org/10.1038/ s41591-021-01614-0
Rajpurkar, P., Chen, E., Banerjee, O., Topol, E.J.: Ai in health and medicine. Nature Medicine28(1), 31–38 (2022).https://doi.org/10.1038/ s41591-021-01614-0
2022
-
[15]
Medical image analysis73, 102155 (2021)
Saha, A., Hosseinzadeh, M., Huisman, H.: End-to-end prostate cancer detection in bpmri via 3d cnns: Effects of attention mechanisms, clinical priori and decoupled false positive reduction. Medical image analysis73, 102155 (2021)
2021
-
[16]
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
Shen, Y., Song, K., Tan, X., Li, D., Lu, W., Zhuang, Y.: Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face (2023).https://doi.org/10. 48550/arXiv.2303.17580,https://arxiv.org/abs/2303.17580
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Reflexion: Language Agents with Verbal Reinforcement Learning
Shinn, N., Labash, B., Gopinath, A., Narasimhan, K., Yao, S.: Reflexion: Lan- guage agents with verbal reinforcement learning (2023).https://doi.org/10. 48550/arXiv.2303.11366,https://arxiv.org/abs/2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
In: Findings of the Association for Computational Linguistics: ACL 2024
Tang, X., Zou, A., Zhang, Z., Li, Z., Zhao, Y., Zhang, X., Cohan, A., Gerstein, M.: Medagents:Largelanguagemodelsascollaboratorsforzero-shotmedicalreasoning. In: Findings of the Association for Computational Linguistics: ACL 2024. pp. 599–
2024
-
[20]
Association for Computational Linguistics, Bangkok, Thailand (2024).https: //doi.org/10.18653/v1/2024.findings-acl.33
-
[21]
Scientific data11(1), 404 (2024)
Tibrewala, R., Dutt, T., Tong, A., Ginocchio, L., Lattanzi, R., Keerthivasan, M.B., Baete, S.H., Chopra, S., Lui, Y.W., Sodickson, D.K., et al.: Fastmri prostate: A public, biparametric mri dataset to advance machine learning for prostate cancer imaging. Scientific data11(1), 404 (2024)
2024
-
[22]
Scientific Data11(1), 687 (2024)
Wang, C., Lyu, J., Wang, S., Qin, C., Guo, K., Zhang, X., Yu, X., Li, Y., Wang, F., Jin, J., et al.: Cmrxrecon: A publicly available k-space dataset and benchmark to advance deep learning for cardiac mri. Scientific Data11(1), 687 (2024)
2024
-
[23]
Executable code actions elicit better LLM agents, 2024
Wang, X., Chen, Y., Yuan, L., Zhang, Y., Li, Y., Peng, H., Ji, H.: Executable code actions elicit better llm agents. In: Proceedings of the 41st International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 235, pp. 50208–50232 (2024).https://doi.org/10.48550/arXiv.2402.01030, https://proceedings.mlr.press/v235/wang24h.html
-
[24]
Wang, Z., Cai, S., Liu, A., Ma, X., Liang, Y.: Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents (2023).https://doi.org/10.48550/arXiv.2302.01560,https://arxiv. org/abs/2302.01560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.01560 2023
-
[25]
Wang, Z., Wu, J., Cai, L., Low, C.H., Yang, X., Li, Q., Jin, Y.: Medagent- pro: Towards evidence-based multi-modal medical diagnosis via reasoning agen- tic workflow (2025).https://doi.org/10.48550/arXiv.2503.18968,https:// arxiv.org/abs/2503.18968
-
[26]
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: React: Synergizingreasoningandactinginlanguagemodels.In:Theeleventhinternational conference on learning representations (2022)
2022
-
[27]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Zhao, Y., Kellman, P., Xue, H., Yang, T., Zhang, Y., Han, Y., Simonetti, O., Tao, Q.: Reverse imaging for wide-spectrum generalization of cardiac mri segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 555–565. Springer (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.