Deep Psychovisual Image Representations
Pith reviewed 2026-06-29 08:56 UTC · model grok-4.3
The pith
Psychovisual frequency coding with learned spectral filters produces interpretable object parts and reduces depth dependence in vision models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
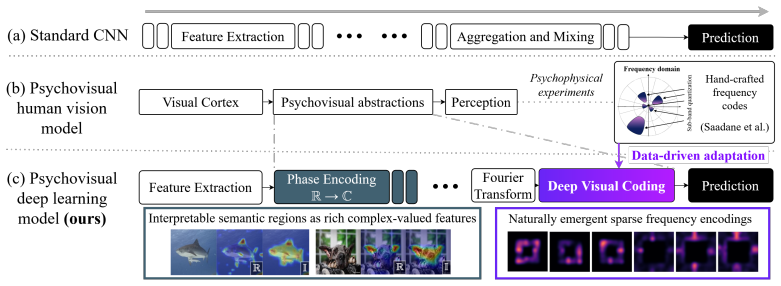
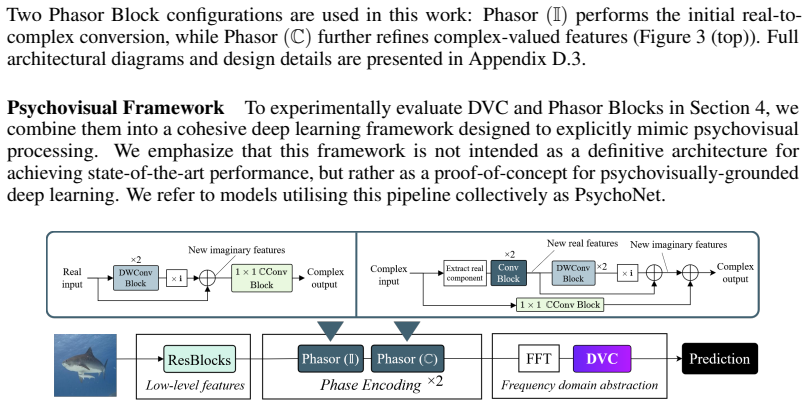
Deep Visual Coding is a learned frequency-domain representation inspired by perceptually salient frequency quantization that, together with complex-valued image representations, produces psychovisual-style abstractions. Data-driven spectral filters encode task-relevant semantic structures within distinct frequency sub-bands, resulting in salience analyses that show highly interpretable object parts and models that are less dependent on depth for scaling compared to CNNs.
What carries the argument
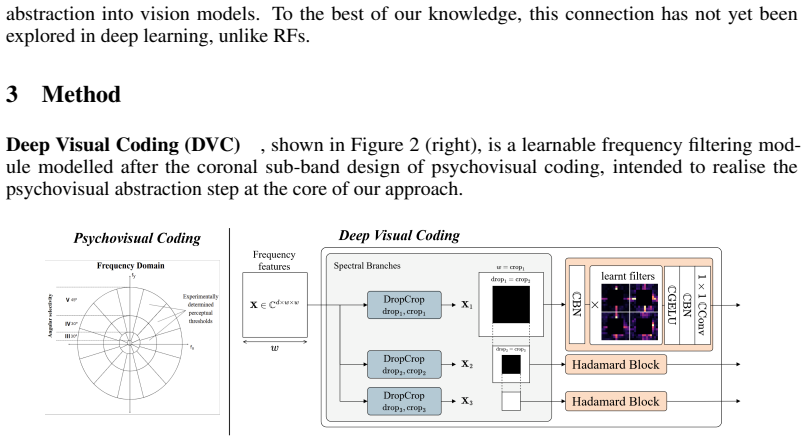
Data-driven spectral filters that learn to encode task-relevant semantic structures within distinct frequency sub-bands, in combination with complex-valued representations.
If this is right
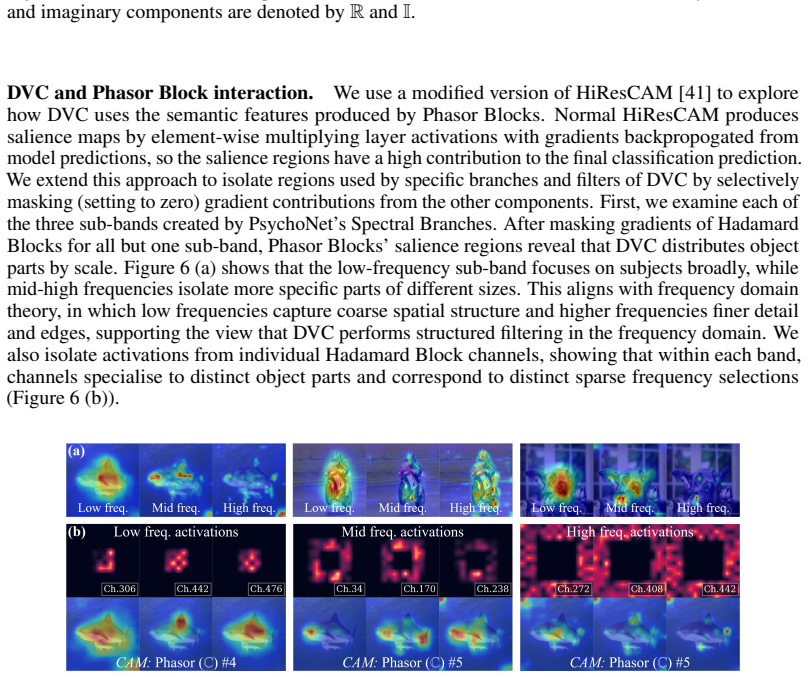
- Psychovisual models extract highly interpretable object parts compared to amorphous regions in CNNs.
- Models require less depth for scaling because complex-valued representations and learned abstractions subsume the role of deep spatial layers.
- Provides a promising path toward more efficient and transparent vision models.
- Utilizes data-driven spectral filters to encode semantic structures in frequency sub-bands.
Where Pith is reading between the lines
- Such frequency-based abstractions might generalize to other perception tasks like audio processing where spectral bands are natural.
- Combining this with existing CNN backbones could create hybrid architectures that are both interpretable and accurate.
- Reduced depth dependence suggests potential for deploying vision models on resource-constrained devices without accuracy loss.
Load-bearing premise
The observed interpretability and reduced depth dependence arise specifically from the psychovisual frequency coding rather than from the complex-valued representation or other implementation choices.
What would settle it
Compare salience maps and depth scaling curves between the proposed model and an otherwise identical model that uses complex values but standard spatial convolutions without the learned frequency sub-band filters.
Figures


read the original abstract
Psychovisual models suggest human vision decouples low-level feature extraction from higher cognition by first forming intermediate abstractions. In contrast, deep learning-based vision models routinely extract and aggregate features using homogeneous stacks of spatial layers, rendering their decision-making processes opaque. In this paper, we propose Deep Visual Coding, a learned frequency-domain representation inspired by 1990s image codes that quantised perceptually salient frequencies, which together with complex-valued image representations produces psychovisual-style abstractions. This approach enables the first psychovisual-based deep learning framework, utilizing data-driven spectral filters that learn to encode task-relevant semantic structures within distinct frequency sub-bands. Salience analyses reveal that our psychovisual models extract highly interpretable object parts compared to the amorphous regions produced by regular Convolutional Neural Networks (CNNs). Furthermore, we find that our models are less depth dependent than CNNs for model scaling, since our complex-valued representations and learned abstractions subsume the role of the deep spatial layers. Together, these findings demonstrate that psychovisual coding provides a promising path toward more efficient and transparent vision models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Deep Visual Coding, a learned frequency-domain representation using data-driven spectral filters and complex-valued image representations to produce psychovisual-style abstractions. It claims this yields salience maps with highly interpretable object parts (unlike amorphous regions from CNNs) and reduced depth dependence for model scaling, as the abstractions subsume the role of deep spatial layers.
Significance. If substantiated, the result would be significant for vision model design by offering a path to greater interpretability and efficiency through psychovisual frequency sub-band encoding of semantic structure. The approach could influence hybrid frequency-spatial architectures if the attribution to the psychovisual component is isolated and the claims are supported by controlled experiments.
major comments (3)
- [Abstract] Abstract: asserts empirical outcomes (interpretable object parts, lower depth dependence) without any quantitative results, baselines, or experimental details; claims rest on unspecified salience analyses.
- [Abstract] Abstract: the central attribution of interpretability and depth-independence gains to psychovisual frequency coding is not isolated from the complex-valued representation, as no ablation holding the complex-valued path fixed while removing or replacing the learned spectral filters is described.
- [Abstract] Abstract: no equations, derivations, or formal definitions of the data-driven spectral filters, frequency sub-bands, or complex-valued representations are shown, rendering the method non-reproducible.
minor comments (1)
- [Abstract] Abstract: the reference to '1990s image codes that quantised perceptually salient frequencies' lacks specific citations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: asserts empirical outcomes (interpretable object parts, lower depth dependence) without any quantitative results, baselines, or experimental details; claims rest on unspecified salience analyses.
Authors: We agree that the abstract summarizes outcomes at a high level without quantitative details. The full manuscript reports quantitative salience metrics, baselines, and experimental protocols in the results section. We will revise the abstract to include brief references to key quantitative improvements (e.g., interpretability scores and depth-scaling metrics) to better ground the claims. revision: yes
-
Referee: [Abstract] Abstract: the central attribution of interpretability and depth-independence gains to psychovisual frequency coding is not isolated from the complex-valued representation, as no ablation holding the complex-valued path fixed while removing or replacing the learned spectral filters is described.
Authors: The referee correctly identifies that the abstract (and manuscript) does not present an ablation that holds the complex-valued path fixed while varying the learned spectral filters. Current comparisons are to standard CNNs. We will add this specific ablation experiment and its results to the revised manuscript to isolate the contribution of the psychovisual frequency coding. revision: yes
-
Referee: [Abstract] Abstract: no equations, derivations, or formal definitions of the data-driven spectral filters, frequency sub-bands, or complex-valued representations are shown, rendering the method non-reproducible.
Authors: Abstracts conventionally omit equations for accessibility. The manuscript body contains the formal definitions, derivations, and equations for the spectral filters, sub-bands, and complex-valued representations. We will revise the abstract to explicitly reference the relevant method sections containing these elements. revision: partial
Circularity Check
No derivation chain or self-referential reductions present
full rationale
The provided abstract and context contain no equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations. The paper proposes an empirical architecture (data-driven spectral filters plus complex-valued representations) and reports experimental outcomes on interpretability and depth dependence. These are presented as findings from salience analyses and scaling tests rather than as outputs of a closed mathematical chain that reduces to its own inputs by construction. No uniqueness theorems, ansatzes smuggled via citation, or renamings of known results appear. The central claims therefore remain independent of the circularity patterns enumerated in the instructions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. ImageNet classification with deep convolutional neural networks.Communications of The ACM, 60(6):84–90, May 2017. doi: 10.1145/3065386
-
[2]
ImageNet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Fei-Fei Li. ImageNet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, June 2009. doi: 10.1109/cvpr.2009.5206848
-
[3]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. doi: 10.1109/CVPR.2016.90
-
[4]
Aggregated residual transforma- tions for deep neural networks
Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. Aggregated residual transforma- tions for deep neural networks. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5987–5995, 2017. doi: 10.1109/CVPR.2017.634
-
[5]
Densely connected convolu- tional networks
Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q Weinberger. Densely connected convolu- tional networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017
2017
-
[6]
doi: 10.1109/CVPR52688.2022.00176
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11966–11976, 2022. doi: 10.1109/CVPR52688.2022.01167
-
[7]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In9th International Conference on Learning Representations, ICLR 2021, V...
2021
-
[8]
Tolstikhin, N
I. Tolstikhin, N. Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, and Alexey Dosovitskiy. MLP-Mixer: An all-MLP Architecture for Vision. InNeural Information Processing Systems, 2021
2021
-
[9]
Container: Context Aggregation Network.Neural Information Processing Systems, 2021
Peng Gao, Jiasen Lu, Hongsheng Li, Roozbeh Mottaghi, and Aniruddha Kembhavi Kembhavi. Container: Context Aggregation Network.Neural Information Processing Systems, 2021
2021
-
[10]
Gfnet: Global filter networks for visual recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9):10960–10973,
Yongming Rao, Wenliang Zhao, Zheng Zhu, Jie Zhou, and Jiwen Lu. Gfnet: Global filter networks for visual recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9):10960–10973,
-
[11]
doi: 10.1109/TPAMI.2023.3263824
-
[12]
Invariant visual representation by single neurons in the human brain.Nature, 2005
Rodrigo Quian Quiroga, Leila Reddy, Gabriel Kreiman, Christof Koch, and Itzhak Fried. Invariant visual representation by single neurons in the human brain.Nature, 2005. doi: 10.1038/nature03687
-
[13]
Ruff, Roozbeh Kiani, Jerzy Bodurka, Hossein Esteky, Keiji Tanaka, and Peter A
Nikolaus Kriegeskorte, Marieke Mur, Douglas A. Ruff, Roozbeh Kiani, Jerzy Bodurka, Hossein Esteky, Keiji Tanaka, and Peter A. Bandettini. Matching categorical object representations in inferior temporal cortex of man and monkey.Neuron, 2008. doi: 10.1016/j.neuron.2008.10.043
-
[14]
Concept cells: the building blocks of declarative memory functions.Nature Reviews Neuroscience, 2012
Rodrigo Quian Quiroga. Concept cells: the building blocks of declarative memory functions.Nature Reviews Neuroscience, 2012. doi: 10.1038/nrn3251
-
[15]
Seeliger, Antonio Lozano, Thirza Dado, Feng Wang, Pieter R
Lynn Le, Paolo Papale, K. Seeliger, Antonio Lozano, Thirza Dado, Feng Wang, Pieter R. Roelfsema, M. van Gerven, Ya˘gmur Güçlütürk, and Umut Güçlü. Monkeysee: Space-time-resolved reconstructions of natural images from macaque multi-unit activity.Neural Information Processing Systems, 2024
2024
-
[16]
Design of psychovisual quantizers for a visual subband image coding
Abdelhakim Saadane, Hakim Senane, and Dominique Barba. Design of psychovisual quantizers for a visual subband image coding. InVisual Communications and Image Processing ’94, volume 2308, pages 1446–1453. SPIE, September 1994. doi: 10.1117/12.185903
-
[17]
Guedon, Dominique Barba, and Nicole Burger
Jeanpierre V . Guedon, Dominique Barba, and Nicole Burger. Psychovisual image coding via an exact discrete Radon transform. InProceedings Volume 2501, Visual Communications and Image Processing 1995, volume 2501, pages 562–572, 1995. doi: 10.1117/12.206765
-
[18]
A. Saadane, H. Sénane, and D. Barba. Visual Coding: Design of Psychovisual Quantizers.Journal of Visual Communication and Image Representation, 9(4):381–391, December 1998. ISSN 1047-3203. doi: 10.1006/jvci.1998.0393. 11
-
[19]
Fast Fourier Convolution
Lu Chi, Borui Jiang, and Yadong Mu. Fast Fourier Convolution. InAdvances in Neural Information Process- ing Systems, volume 33, pages 4479–4488. Curran Associates, Inc., 2020. URL https://papers.nips. cc/paper_files/paper/2020/hash/2fd5d41ec6cfab47e32164d5624269b1-Abstract.html
2020
-
[20]
Oren Rippel, Jasper Snoek, and Ryan P. Adams. Spectral Representations for Convolutional Neural Networks. InProceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2, NIPS’15, pages 2449–2457, Cambridge, MA, USA, 2015. MIT Press
2015
-
[21]
Phasemp: Robust 3d pose estimation via phase-conditioned human motion prior
Saurabh Yadav and Koteswar Rao Jerripothula. FCCNs: Fully Complex-valued Convolutional Networks using Complex-valued Color Model and Loss Function. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 10655–10664, October 2023. doi: 10.1109/ICCV51070.2023.00981. URL https://ieeexplore.ieee.org/document/10377516. ISSN: 2380-7504
-
[22]
Olshausen and David J
Bruno A. Olshausen and David J. Field. Emergence of simple-cell receptive field properties by learning a sparse code for natural images.Nature, 381(6583):607, June 1996. ISSN 1476-4687. doi: 10.1038/ 381607a0. URLhttps://www.nature.com/articles/381607a0
1996
-
[23]
D. H. Hubel and T. N. Wiesel. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex.The Journal of Physiology, 160(1):106–154.2, January 1962. ISSN 0022-3751. URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1359523/
1962
-
[24]
Dario L. Ringach. Spatial structure and symmetry of simple-cell receptive fields in macaque primary visual cortex.Journal of Neurophysiology, 88(1):455–463, July 2002. doi: 10.1152/jn.2002.88.1.455
-
[25]
Mengkun Liu, Licheng Jiao, Xu Liu, Lingling Li, Fang Liu, Shuyuan Yang, and Xiangrong Zhang. Bio-Inspired Multi-scale Contourlet Attention Networks.IEEE transactions on multimedia, pages 1–16, January 2023. doi: 10.1109/tmm.2023.3304448
-
[26]
Mengkun Liu, Licheng Jiao, Xu Liu, Lingling Li, Fang Liu, and Shuyuan Yang. C-CNN: Contourlet Convolutional Neural Networks.IEEE Transactions on Neural Networks and Learning Systems, 32(6):2636– 2649, June 2021. ISSN 2162-2388. doi: 10.1109/TNNLS.2020.3007412. URL https://ieeexplore. ieee.org/document/9145825. Conference Name: IEEE Transactions on Neural ...
-
[27]
E. J. Candés and D. L. Donoho. Ridgelets: a key to higher-dimensional intermittency?Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 357(1760): 2495–2509, 1999. doi: 10.1098/rsta.1999.0444
-
[28]
Jean-Luc Starck, E.J. Candes, and D.L. Donoho. The curvelet transform for image denoising.IEEE Transactions on Image Processing, 11(6):670–684, June 2002. ISSN 1941-0042. doi: 10.1109/TIP.2002. 1014998. Conference Name: IEEE Transactions on Image Processing
-
[29]
Do and M
M.N. Do and M. Vetterli. The contourlet transform: an efficient directional multiresolution image representation.IEEE Transactions on Image Processing, 14(12):2091–2106, December 2005. ISSN 1941-
2091
-
[30]
URLhttps://ieeexplore.ieee.org/document/1532309
doi: 10.1109/TIP.2005.859376. URLhttps://ieeexplore.ieee.org/document/1532309
-
[31]
Gonzalez and Richard E
Rafael C. Gonzalez and Richard E. Woods.Digital Image Processing 3rd Edition. Prentice Hall, January 2014
2014
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Shaohua Li, Kaiping Xue, Bin Zhu, Chenkai Ding, Xindi Gao, David Wei, and Tao Wan. Falcon: A fourier transform based approach for fast and secure convolutional neural network predictions. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8702–8711, 2020. doi: 10.1109/CVPR42600.2020.00873
-
[33]
Unrolling of deep graph total variation for image denoising,
Bochen Guan, Jinnian Zhang, William A. Sethares, Richard Kijowski, and Fang Liu. Spectral Domain Convolutional Neural Network. InICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2795–2799, June 2021. doi: 10.1109/ICASSP39728.2021. 9413409. ISSN: 2379-190X
-
[34]
J. Lee-Thorp, J. Ainslie, Ilya Eckstein, and Santiago Ontañón. FNet: Mixing Tokens with Fourier Transforms.North American Chapter of the Association for Computational Linguistics, 2021. doi: 10.18653/v1/2022.naacl-main.319
-
[35]
Phasemp: Robust 3d pose estimation via phase-conditioned human motion prior
Zhipeng Huang, Zhizheng Zhang, Cuiling Lan, Zheng-Jun Zha, Yan Lu, and Baining Guo. Adaptive frequency filters as efficient global token mixers. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 6026–6036, 2023. doi: 10.1109/ICCV51070.2023.00556. 12
-
[36]
Julia Grabinski, Janis Keuper, and Margret Keuper. As large as it gets: Learning infinitely large filters via neural implicit functions in the fourier domain.ArXiv, abs/2307.10001, 2023. URL https://api. semanticscholar.org/CorpusID:259982481
-
[37]
Resolution-invariant image classification based on fourier neural operators
Samira Kabri, Tim Roith, Daniel Tenbrinck, and Martin Burger. Resolution-invariant image classification based on fourier neural operators. InScale Space and Variational Methods in Computer Vision: 9th International Conference, SSVM 2023, Santa Margherita Di Pula, Italy, May 21–25, 2023, Proceedings, page 236–249, Berlin, Heidelberg, 2023. Springer-Verlag....
-
[38]
H. Senane, A. Saadane, and D. Barba. Image coding in the context of a psychovisual image representation with vector quantization. InProceedings., International Conference on Image Processing, volume 1, pages 97–100 vol.1, October 1995. doi: 10.1109/ICIP.1995.529048
-
[39]
W Cooley, P
J. W Cooley, P. Lewis, and P. Welch. The finite Fourier transform.Audio and Electroacoustics, IEEE Transactions on, 17(2):77–85, June 1969. ISSN 0018-9278
1969
-
[40]
ChiYan Lee, Hideyuki Hasegawa, and Shangce Gao. Complex-Valued Neural Networks: A Comprehensive Survey.IEEE/CAA Journal of Automatica Sinica, 9(8):1406–1426, August 2022. doi: 10.1109/jas.2022. 105743
-
[41]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. 2009. URL https://api. semanticscholar.org/CorpusID:18268744
2009
-
[42]
Sachin Karmani, Thanushon Sivakaran, Gaurav Prasad, Mehmet Ali, Wenbo Yang, and Sheyang Tang. KPCA-CAM: Visual Explainability of Deep Computer Vision Models Using Kernel PCA.IEEE Interna- tional Workshop on Multimedia Signal Processing, 2024. doi: 10.1109/mmsp61759.2024.10743968
-
[43]
Rachel Lea Draelos and Lawrence Carin. Use HiResCAM instead of Grad-CAM for faithful explanations of convolutional neural networks.arXiv preprint arXiv:2011.08891, November 2020. URL https: //arxiv.org/abs/2011.08891
-
[44]
Frequencylowcut pooling - plug and play against catastrophic overfitting
Julia Grabinski, Steffen Jung, Janis Keuper, and Margret Keuper. Frequencylowcut pooling - plug and play against catastrophic overfitting. InComputer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XIV, page 36–57, Berlin, Heidelberg, 2022. Springer-Verlag. ISBN 978-3-031-19780-2. doi: 10.1007/978-3-0...
-
[45]
Jose Hanen and Dominique Barba. High-quality subband image coding of TV signals at 5 Mbit/s with motion compensation interpolation and visually optimized scalar quantization. InVisual Communications and Image Processing ’93, volume 2094, pages 1477–1485. SPIE, October 1993. doi: 10.1117/12.157907
-
[46]
Interactions of chromatic components in the perceptual quantization of the achromatic component
Patrick Le Callet, Abdelhakim Saadane, and Dominique Barba. Interactions of chromatic components in the perceptual quantization of the achromatic component. InHuman Vision and Electronic Imaging IV, volume 3644, pages 121–128. SPIE, May 1999. doi: 10.1117/12.348432
-
[47]
On the masking effects in a perceptually based image quality metric
Abdelhakim Saadane, Nachida Bekkat, and Dominique Barba. On the masking effects in a perceptually based image quality metric. InImaging and vision systems: theory, assessment and applications, pages 161–177. Nova Science Publishers, Inc., USA, January 2001. ISBN 978-1-59033-033-3
2001
-
[48]
Philippe, and D
Nicolas Normand, Jean-Pierre Guédon, O. Philippe, and D. Barba. Controlled redundancy for image coding and high-speed transmission.Proc. of the SPIE - The International Society for Optical Engineering, 2727:1070–1081, 1996. ISSN 0277-786X
1996
-
[49]
Andrew Kingston and Imants Svalbe. Generalised finite radon transform forN×Nimages.Image and Vision Computing, 25(10):1620–1630, October 2007. ISSN 0262-8856. doi: 10.1016/j.imavis.2006.03.002
-
[50]
S. S. Chandra, N. Normand, A. Kingston, J. Guédon, and I. Svalbe. Robust Digital Image Reconstruction via the Discrete Fourier Slice Theorem.Signal Processing Letters, IEEE, 21(6):682–686, June 2014. ISSN 1070-9908. doi: 10.1109/LSP.2014.2313341
-
[51]
Guédon, Nicolas Normand, Pierre Verbert, Benoit Parrein, and Florent Autrusseau
Jean-Pierre V . Guédon, Nicolas Normand, Pierre Verbert, Benoit Parrein, and Florent Autrusseau. Load- balancing and scalable multimedia distribution using the Mojette transform.Internet Multimedia Manage- ment Systems II, 4519(1):226–234, 2001
2001
-
[52]
Wen Hou and Cishen Zhang. Parallel-Beam CT Reconstruction Based on Mojette Transform and Com- pressed Sensing.International Journal of Computer and Electrical Engineering, pages 83–87, 2013. ISSN 17938163. doi: 10.7763/IJCEE.2013.V5.669. 13
-
[53]
Benoit Parrein, Pierre Verbert, Nicolas Normand, and Jean-Pierre V . Guédon. Scalable multiple descriptions on packets networks via the n-dimensional Mojette transform.Quality of Service over Next-Generation Data Networks, 4524(1):243–252, 2001
2001
-
[54]
Pierre Verbert, Jean-Pierre V . Guédon, and Benoit Parrein. Distributed and compressed multimedia transmission using a discrete backprojection operator.Internet Multimedia Management Systems III, 4862 (1):315–325, 2002. doi: 10.1117/12.473047
-
[55]
John Wiley & Sons, March 2013
Jeanpierre Guédon.The Mojette Transform: Theory and Applications. John Wiley & Sons, March 2013. ISBN 9781118622933
2013
-
[56]
Complex-valued Neural Networks with Non-parametric Activation Functions
Simone Scardapane, Steven Van Vaerenbergh, Amir Hussain, and Aurelio Uncini. Complex-valued Neural Networks with Non-parametric Activation Functions, February 2018. URL http://arxiv.org/abs/ 1802.08026. arXiv:1802.08026 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[57]
Chiheb Trabelsi, Olexa Bilaniuk, Ying Zhang, Dmitriy Serdyuk, Sandeep Subramanian, Joao Felipe Santos, Soroush Mehri, Negar Rostamzadeh, Yoshua Bengio, and Christopher J. Pal. Deep Complex Networks. InInternational Conference on Learning Representations, February 2018. URL https: //openreview.net/forum?id=H1T2hmZAb
2018
-
[58]
Complex-valued densely connected convolutional networks
Wenhan Li, Wenqing Xie, and Zhifang Wang. Complex-valued densely connected convolutional networks. In Jianchao Zeng, Weipeng Jing, Xianhua Song, and Zeguang Lu, editors,Data Science, pages 299–309, Singapore, 2020. Springer Singapore. ISBN 978-981-15-7981-3
2020
-
[59]
Complex fully convolutional neural networks for mr image reconstruction
Muneer Dedmari, Sailesh Conjeti, Santiago Estrada, Phillip Ehses, Tony Stocker, and Martin Reuter. Complex fully convolutional neural networks for mr image reconstruction. InMachine Learning for Medical Image Reconstruction : first International Workshop, MLMIR 2018, volume 1. Springer, 2018
2018
-
[60]
Compressed sensing mri reconstruction with co-vegan: Complex-valued generative adversarial network
Bhavya Vasudeva, Puneesh Deora, Saumik Bhattacharya, and Pyari Mohan Pradhan. Compressed sensing mri reconstruction with co-vegan: Complex-valued generative adversarial network. In2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1779–1788, 2022. doi: 10.1109/ W ACV51458.2022.00184
-
[61]
Elizabeth Cole, Joseph Cheng, John Pauly, and Shreyas Vasanawala. Analysis of deep complex- valued convolutional neural networks for mri reconstruction and phase-focused applications.Mag- netic Resonance in Medicine, 86(2):1093–1109, 2021. doi: https://doi.org/10.1002/mrm.28733. URL https://onlinelibrary.wiley.com/doi/abs/10.1002/mrm.28733
-
[62]
Automatic differentiation in pytorch
Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. InNIPS-W, 2017
2017
-
[63]
Fedus, Xianzhi Du, E
Irwan Bello, W. Fedus, Xianzhi Du, E. D. Cubuk, A. Srinivas, Tsung-Yi Lin, Jonathon Shlens, and Barret Zoph. Revisiting ResNets: Improved Training and Scaling Strategies.Neural Information Processing Systems, 2021. 14 Appendices In the following we present appendices to our work, structured as follows: Appendix A lists the abbreviations used throughout ou...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.