UniNote: A Unified Embedding Model for Multimodal Representation and Ranking
Pith reviewed 2026-06-29 05:52 UTC · model grok-4.3
The pith
UniNote unifies multimodal embeddings for item-to-item retrieval via contrastive SFT followed by reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
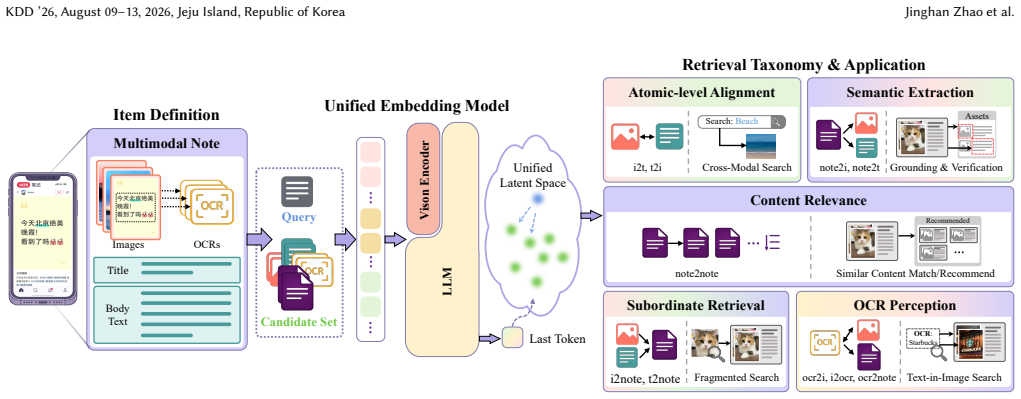
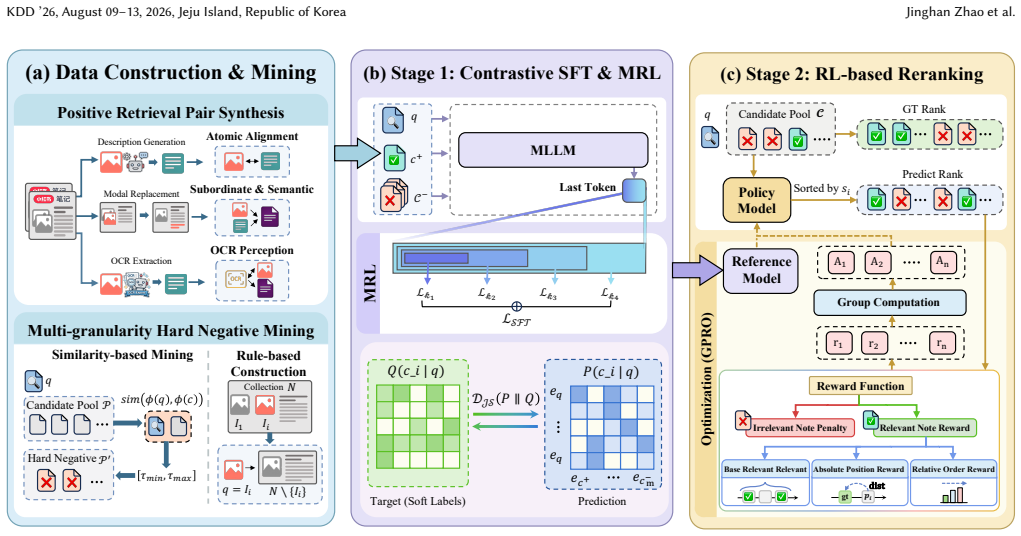
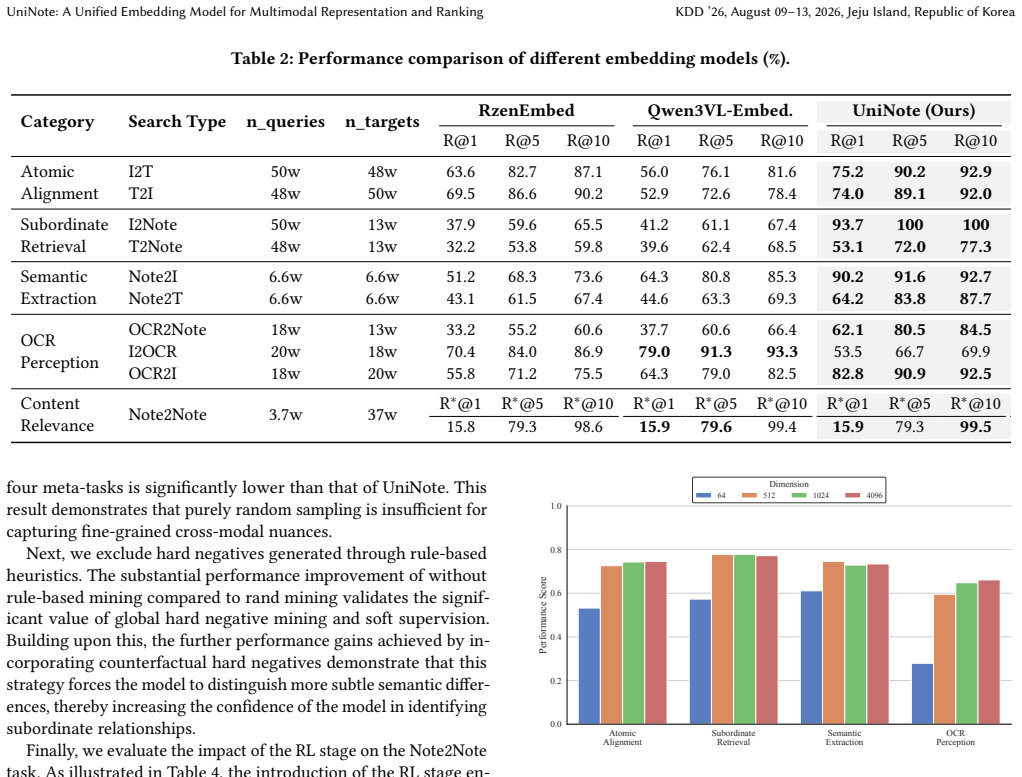
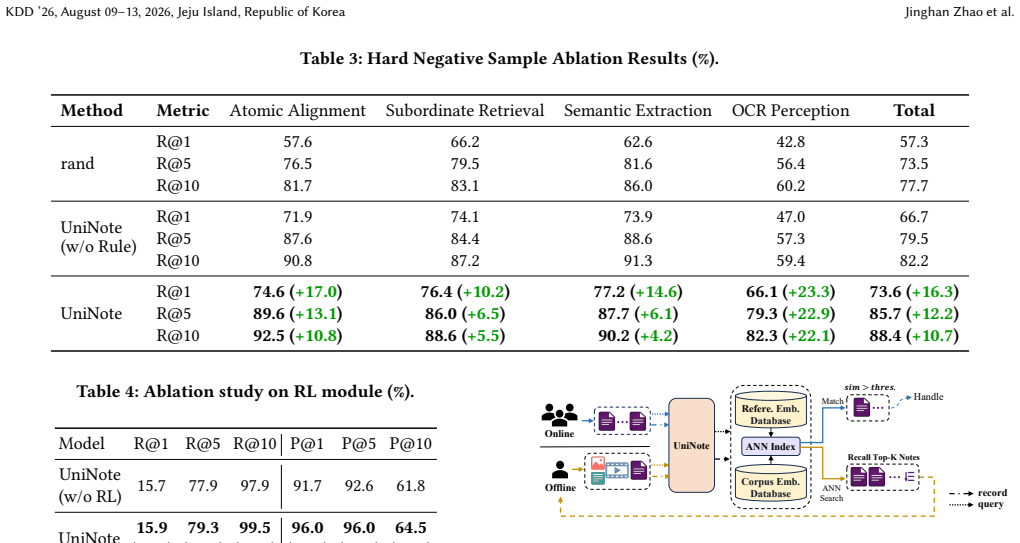
The paper establishes that a unified embedding model called UniNote, equipped with tailored retrieval strategies for multimodal content at varying granularities and trained through a two-stage process of contrastive supervised fine-tuning followed by reinforcement learning, delivers state-of-the-art performance on diverse item-to-item retrieval tasks and yields significant improvements in retrieval quality and cost efficiency when deployed at Xiaohongshu together with Matryoshka Representation Learning.
What carries the argument
The two-stage training paradigm of contrastive supervised fine-tuning to build base embeddings followed by reinforcement learning to align with content relevance, together with tailored retrieval strategies that operate at multiple granularities.
If this is right
- UniNote reaches state-of-the-art results across multiple item-to-item retrieval benchmarks.
- Integration with Matryoshka Representation Learning produces both higher retrieval quality and lower serving cost in production-scale systems.
- A single model can handle representation learning for complex multimodal items at different levels of detail without separate embedding and ranking pipelines.
- The reinforcement learning stage refines ranking quality after the base embeddings are established.
Where Pith is reading between the lines
- Similar two-stage training might simplify retrieval stacks in other recommendation platforms that currently maintain distinct embedding and ranking components.
- The approach could be tested on non-commercial datasets to check whether the reported gains depend on the specific industrial data distribution.
- Because the model already supports variable embedding lengths via MRL, it may offer a direct route to trading accuracy for speed in resource-limited serving environments.
- The reinforcement learning alignment step might extend to other relevance signals such as user engagement metrics beyond content similarity.
Load-bearing premise
The contrastive SFT plus RL sequence balances global and local signals without needing extra post-training adjustments or specially chosen data that would make the gains look larger than they are.
What would settle it
An independent evaluation on a fresh collection of I2I tasks that finds no accuracy or latency advantage for the full two-stage UniNote over strong single-stage multimodal baselines would falsify the central performance claim.
Figures
read the original abstract
Item-to-Item (I2I) retrieval is a fundamental part of modern content platforms, supporting critical industrial workflows from recommendation engines to content auditing. While multimodal embedding methods have advanced general retrieval, they often falter in I2I scenarios due to the challenges of balancing global content representation with fine-grained local retrieval, the systemic inefficiency of decoupled embedding-and-ranking pipelines, and the inherent trade-offs between model precision and serving latency. To solve these issues, we propose \textbf{UniNote}, a unified embedding model designed for industrial I2I retrieval. Tailored retrieval strategies are introduced to support representation learning over complex, multimodal content at varying granularities. To operationalize these strategies, UniNote employs a two-stage training paradigm: the first stage leverages contrastive SFT to establish robust base embeddings, while the second stage refines ranking quality through a reinforcement learning (RL) process that aligns the model with content relevance. Our results show that UniNote achieves SOTA performance across diverse I2I tasks. Deployed at Xiaohongshu and integrated with Matryoshka Representation Learning (MRL), UniNote achieved significant improvements in retrieval quality and cost efficiency in large-scale applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniNote, a unified embedding model for item-to-item (I2I) retrieval in multimodal content platforms. It introduces tailored retrieval strategies and a two-stage training approach: contrastive supervised fine-tuning (SFT) to establish base embeddings, followed by reinforcement learning (RL) to refine ranking quality. The paper claims that UniNote achieves state-of-the-art (SOTA) performance across diverse I2I tasks and, when deployed at Xiaohongshu with integration to Matryoshka Representation Learning (MRL), delivers significant improvements in retrieval quality and cost efficiency.
Significance. If the reported results and deployment outcomes are substantiated, this work would represent a meaningful advance in industrial multimodal retrieval systems by addressing challenges in global-local balance, pipeline efficiency, and precision-latency trade-offs. The integration with MRL for scalable representations is a notable strength. However, the current presentation provides insufficient empirical grounding to evaluate these contributions.
major comments (2)
- Abstract: The central claims of SOTA performance across diverse I2I tasks and effective balancing of global representation with fine-grained local retrieval via the two-stage contrastive SFT + RL paradigm lack any supporting experiments, ablation studies, baseline definitions, statistical tests, or quantitative results. This is load-bearing because the abstract supplies zero information on RL reward design, data sources, or controls, rendering the effectiveness assertion unverifiable.
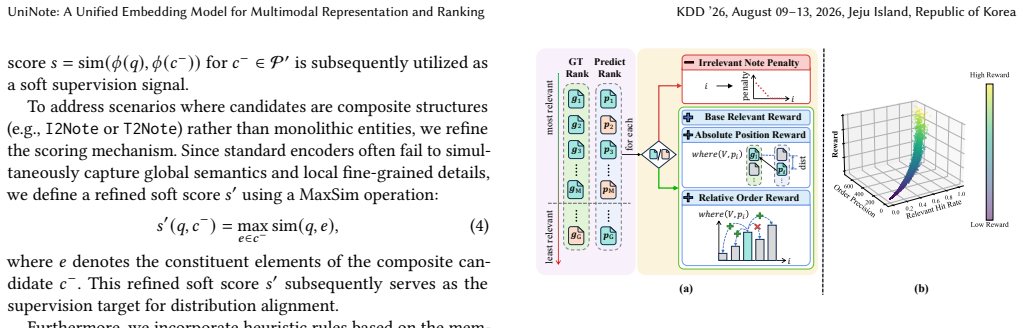
- Two-stage training description (implied Methods section): No details are given on the RL reward function, policy optimization, training data selection, or how the RL stage avoids post-hoc tuning while aligning with content relevance. This directly undermines the claim that the paradigm resolves the stated trade-offs in multimodal I2I retrieval.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract and methods descriptions require additional empirical details and methodological transparency to allow full evaluation of the claims. We will revise the manuscript to strengthen these sections while preserving the core contributions.
read point-by-point responses
-
Referee: Abstract: The central claims of SOTA performance across diverse I2I tasks and effective balancing of global representation with fine-grained local retrieval via the two-stage contrastive SFT + RL paradigm lack any supporting experiments, ablation studies, baseline definitions, statistical tests, or quantitative results. This is load-bearing because the abstract supplies zero information on RL reward design, data sources, or controls, rendering the effectiveness assertion unverifiable.
Authors: The abstract is a high-level summary by design and does not include quantitative results or full methodological specifications; those appear in the Experiments and Methods sections. We will revise the abstract to incorporate key quantitative metrics (e.g., relative improvements over baselines on I2I tasks) and explicit references to the RL components. We will also add a short clause on data sources and controls where space permits, or expand the introduction to cross-reference the detailed experimental evidence already present in the paper. revision: yes
-
Referee: Two-stage training description (implied Methods section): No details are given on the RL reward function, policy optimization, training data selection, or how the RL stage avoids post-hoc tuning while aligning with content relevance. This directly undermines the claim that the paradigm resolves the stated trade-offs in multimodal I2I retrieval.
Authors: The current draft provides only a high-level description of the two-stage paradigm. We will expand the Methods section with concrete specifications: the RL reward function (derived from engagement-based relevance signals), the policy optimization method, training data curation criteria, and explicit design choices that align the RL stage with content relevance without post-hoc tuning. We will also include additional ablation results demonstrating the incremental benefit of the RL stage over contrastive SFT alone. revision: yes
Circularity Check
No circularity detected; empirical model description is self-contained
full rationale
The paper describes UniNote via a two-stage training process (contrastive SFT then RL) and reports empirical SOTA/deployment results, but contains no mathematical derivation chain, equations, predictions, or first-principles results that reduce to inputs by construction. No self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Claims rest on training outcomes and industrial deployment rather than any closed logical loop, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL reward scaling parameters
axioms (1)
- domain assumption Contrastive SFT produces robust base embeddings suitable for subsequent RL refinement
Reference graph
Works this paper leans on
-
[1]
Premnarayan Arya, Amit Kumar Pandey, S Gopal Krishna Patro, Kretika Tiwari, Niranjan Panigrahi, Quadri Noorulhasan Naveed, Ayodele Lasisi, and Wahaj Ah- mad Khan. 2024. MSCMGTB: A Novel Approach for Multimodal Social Media Content Moderation Using Hybrid Graph Theory and Bio-Inspired Optimization. IEEE Access12 (2024), 73700–73718
2024
-
[2]
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. 2024. Mllm-as-a- judge: Assessing multimodal llm-as-a-judge with vision-language benchmark. In Forty-first International Conference on Machine Learning
2024
-
[3]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255
2009
-
[4]
Mark Everingham, SM Ali Eslami, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. 2015. The pascal visual object classes challenge: A retrospective.International journal of computer vision111, 1 (2015), 98–136
2015
- [5]
-
[6]
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. 2021. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vision. 8340– 8349
2021
-
[7]
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song
-
[8]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Natural adversarial examples. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15262–15271
- [9]
-
[10]
Ting Jiang, Minghui Song, Zihan Zhang, Haizhen Huang, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, and Fuzhen Zhuang. 2024. E5-v: Universal embeddings with multimodal large language models.arXiv preprint arXiv:2407.12580(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. 2014. Referitgame: Referring to objects in photographs of natural scenes. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 787–798
2014
-
[12]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2024. Nv-embed: Improved techniques for training llms as generalist embedding models.arXiv preprint arXiv:2405.17428 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
-
[14]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning. PMLR, 12888–12900
2022
-
[15]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, et al . 2026. Qwen3-VL- Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking.arXiv preprint arXiv:2601.04720(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. InEuropean conference on computer vision. Springer, 740–755
2014
-
[17]
Fuxiao Liu, Yinghan Wang, Tianlu Wang, and Vicente Ordonez. 2021. Visual news: Benchmark and challenges in news image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing. 6761–6771
2021
-
[18]
Qidong Liu, Jiaxi Hu, Yutian Xiao, Xiangyu Zhao, Jingtong Gao, Wanyu Wang, Qing Li, and Jiliang Tang. 2024. Multimodal recommender systems: A survey. Comput. Surveys57, 2 (2024), 1–17
2024
- [19]
-
[20]
Yikun Liu, Yajie Zhang, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. 2025. Lamra: Large multimodal model as your advanced retrieval assistant. InProceedings of the Computer Vision and Pattern Recognition Conference. 4015–4025
2025
-
[21]
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. 2021. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 2200–2209
2021
-
[22]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[23]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, Richang Hong, and Tat-Seng Chua. 2019. MMGCN: Multi-modal graph convolution network for personalized recommendation of micro-video. InProceedings of the 27th ACM international conference on multimedia. 1437–1445
2019
-
[25]
Chuhan Wu, Fangzhao Wu, Tao Qi, Chao Zhang, Yongfeng Huang, and Tong Xu
-
[26]
InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval
Mm-rec: Visiolinguistic model empowered multimodal news recommenda- tion. InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 2560–2564
-
[27]
Derong Xu, Wei Chen, Wenjun Peng, Chao Zhang, Tong Xu, Xiangyu Zhao, Xian Wu, Yefeng Zheng, Yang Wang, and Enhong Chen. 2024. Large language models for generative information extraction: A survey.Frontiers of Computer Science18, 6 (2024), 186357
2024
- [28]
-
[29]
Jialin Yuan, Ye Yu, Gaurav Mittal, Matthew Hall, Sandra Sajeev, and Mei Chen
-
[30]
InProceedings of the IEEE/CVF winter conference on applications of computer vision
Rethinking multimodal content moderation from an asymmetric angle with mixed-modality. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 8532–8542
-
[31]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sig- moid loss for language image pre-training. InProceedings of the IEEE/CVF inter- national conference on computer vision. 11975–11986
2023
-
[32]
Chao Zhang, Haoxin Zhang, Shiwei Wu, Di Wu, Tong Xu, Xiangyu Zhao, Yan Gao, Yao Hu, and Enhong Chen. 2025. Notellm-2: Multimodal large representation models for recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. 2815–2826
2025
-
[33]
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. 2024. GME: Im- proving Universal Multimodal Retrieval by Multimodal LLMs.arXiv preprint arXiv:2412.16855(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
2023
-
[35]
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba
-
[36]
Places: A 10 million image database for scene recognition.IEEE transactions on pattern analysis and machine intelligence40, 6 (2017), 1452–1464
2017
-
[37]
Yuke Zhu, Oliver Groth, Michael Bernstein, and Li Fei-Fei. 2016. Visual7w: Grounded question answering in images. InProceedings of the IEEE conference on computer vision and pattern recognition. 4995–5004. A Contrastive SFT Settings We filter high-quality notes from the raw dataset of Xiaohongshu based on a threshold of more than 100 likes. Balanced proce...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.