Multi-Stage VLM Pipeline for Zero-Shot Traffic Accident Understanding
Pith reviewed 2026-06-29 08:42 UTC · model grok-4.3
The pith
A three-stage pipeline on frozen vision-language models wins a zero-shot traffic accident prediction challenge by blending two model sizes and snapping outputs to vehicle detections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
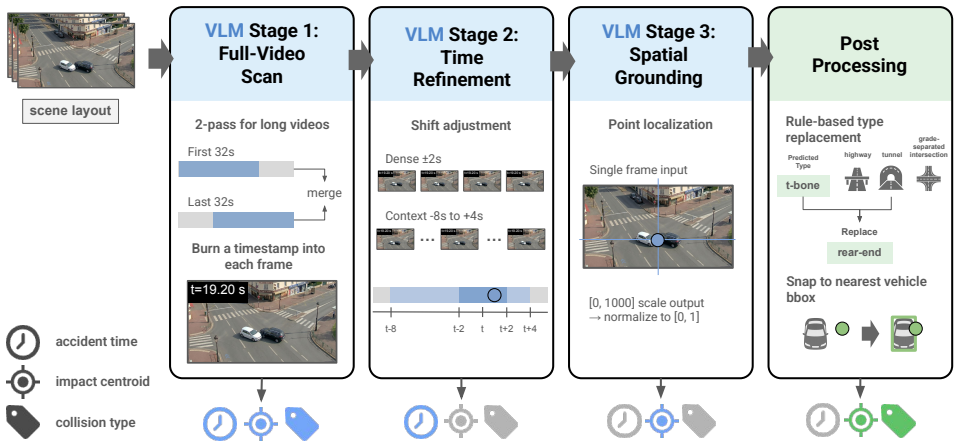
On a frozen Qwen3-VL-32B-Instruct checkpoint the authors build a three-stage pipeline of full-video joint prediction, time refinement, and single-frame grounding of the impact centroid. The identical pipeline is executed on a 235B Mixture-of-Experts sibling model. Outputs are blended in a 9:1 ratio and each predicted point is snapped onto the nearest vehicle detection. This system attains Public LB 0.55469 and Private LB 0.57080, exceeding the strongest host baseline by roughly 0.21 and securing first place in the challenge.
What carries the argument
The three-stage pipeline of full-video joint prediction followed by time refinement and single-frame grounding, combined with 9:1 blending of two VLM sizes and snapping each point to the nearest vehicle detection.
If this is right
- Each of the three stages and the blending step contributes measurably to the final score according to the reported ablations.
- Alternative pipeline designs tested by the authors produced lower scores and therefore shaped the final architecture.
- The system produces joint predictions for timing, centroid, and collision type in a single zero-shot pass over each video.
- Snapping predictions to detected vehicles corrects localization errors that arise from the language-model outputs.
- No task-specific training data or fine-tuning of the underlying models is required.
Where Pith is reading between the lines
- The same staged prompting structure could be applied to other video event-understanding problems such as near-miss detection or infrastructure monitoring.
- Substituting newer or larger models into the existing stages would allow direct measurement of further gains without redesigning the pipeline.
- The 9:1 blending ratio and snapping rule may require recalibration when the input videos come from cameras with different resolutions or viewing angles.
- Public release of the code makes it possible for others to test the pipeline on additional CCTV datasets beyond the original challenge.
Load-bearing premise
The specific three-stage pipeline design together with 9:1 blending and vehicle snapping will produce reliable zero-shot performance gains on the challenge metrics without overfitting to the evaluation setup.
What would settle it
Re-running the identical pipeline without the snapping step or without the 9:1 blend and recording whether the private leaderboard score falls to or below the 0.358 baseline level.
Figures
read the original abstract
We present the 1st-place solution to the ACCIDENT challenge at the CVPR 2026 AUTOPILOT Workshop, which asks for zero-shot prediction of accident timing, impact centroid, and collision type from CCTV footage. On a frozen Qwen3-VL-32B-Instruct checkpoint we build a three-stage pipeline (full-video joint prediction, time refinement, and single-frame grounding of the impact centroid), run the same pipeline a second time on a 235B Mixture-of-Experts sibling, blend the two outputs 9:1, and finally snap each predicted point onto the nearest vehicle detection. The final system reaches Public LB 0.55469 / Private LB 0.57080, roughly +0.21 over the strongest host baseline (Molmo-7B, 0.358) and wins the challenge. We ablate each component, report the negative results that shaped the final design, and release the code at https://github.com/fuumin621/cvpr2026-accident-1st-place-solution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the 1st-place entry for the ACCIDENT challenge at the CVPR 2026 AUTOPILOT Workshop. On frozen Qwen3-VL-32B-Instruct and 235B MoE checkpoints it constructs a three-stage pipeline (full-video joint prediction of timing/centroid/type, time refinement, single-frame grounding of the impact centroid), blends the two model outputs 9:1, and snaps each predicted point to the nearest vehicle detection. The system reports Public LB 0.55469 / Private LB 0.57080 (+0.21 over the strongest baseline) together with component ablations and the negative results that shaped the design; code is released.
Significance. If the gains prove robust, the work supplies concrete evidence that staged prompting plus modest ensembling on large frozen VLMs can deliver substantial zero-shot performance on a complex video-understanding task. Explicit reporting of negative results and public code release are concrete strengths that support reproducibility and incremental progress in traffic-safety video analysis.
major comments (2)
- [Abstract] Abstract: the central zero-shot claim rests on the assertion that the three-stage design, 9:1 blend, and snapping rule were not tuned to the public leaderboard. The text states that these choices emerged from iterative refinement guided by negative results, yet no independent held-out corpus or cross-dataset transfer experiment is described. This leaves open the possibility that the reported margin is distribution-specific rather than intrinsic to the pipeline; a concrete test would be to freeze the final configuration and evaluate on an external accident-video corpus never seen during design.
- [Abstract] Abstract (pipeline description): the contribution of the final nearest-vehicle snapping step is not isolated in the reported ablations. Because snapping is a deterministic post-processing rule applied after the VLM stages, its removal or replacement with an alternative (e.g., raw VLM centroid) would be required to establish whether the leaderboard margin is carried primarily by the multi-stage VLM reasoning or by the heuristic.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence statement of the exact leaderboard metric (e.g., a weighted combination of timing, centroid, and type accuracy) so readers can interpret the numerical margin without external lookup.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central zero-shot claim rests on the assertion that the three-stage design, 9:1 blend, and snapping rule were not tuned to the public leaderboard. The text states that these choices emerged from iterative refinement guided by negative results, yet no independent held-out corpus or cross-dataset transfer experiment is described. This leaves open the possibility that the reported margin is distribution-specific rather than intrinsic to the pipeline; a concrete test would be to freeze the final configuration and evaluate on an external accident-video corpus never seen during design.
Authors: We agree that an external held-out corpus would provide stronger evidence for the generalizability of the pipeline. The iterative refinement was guided by negative results observed during development on the challenge training and validation data, with the private leaderboard acting as an independent test. We will update the manuscript to explicitly acknowledge this limitation and clarify that the zero-shot claim pertains to the absence of task-specific fine-tuning rather than complete independence from the challenge distribution. revision: partial
-
Referee: [Abstract] Abstract (pipeline description): the contribution of the final nearest-vehicle snapping step is not isolated in the reported ablations. Because snapping is a deterministic post-processing rule applied after the VLM stages, its removal or replacement with an alternative (e.g., raw VLM centroid) would be required to establish whether the leaderboard margin is carried primarily by the multi-stage VLM reasoning or by the heuristic.
Authors: Thank you for pointing this out. While we performed ablations on the main pipeline stages, we did not explicitly isolate the snapping step. We will add this ablation in the revised manuscript, reporting performance with and without the nearest-vehicle snapping to quantify its contribution. revision: yes
- Evaluation on an external accident-video corpus never seen during the design process.
Circularity Check
No circularity; empirical pipeline validated on external leaderboard.
full rationale
The paper describes an empirical three-stage VLM pipeline evaluated on an external challenge leaderboard (Public/Private LB scores vs. Molmo-7B baseline). No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text. Ablations and negative results are reported without reducing the central claim to self-referential definitions or imported uniqueness theorems. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Shuai Bai et al. Qwen3-VL technical report. arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
CARLA : An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio L\'opez, and Vladlen Koltun. CARLA : An open urban driving simulator. In Proceedings of the 1st Annual Conference on Robot Learning (CoRL), pages 1--16, 2017
2017
-
[4]
Efficient memory management for large language model serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention . In Proceedings of the 29th Symposium on Operating Systems Principles (SOSP), 2023
2023
-
[5]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll \'a r. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2980--2988, 2017
2017
-
[6]
Accident: A benchmark dataset for vehicle accident detection from traffic surveillance videos
Lukas Picek, Michal C erm \'a k, Marek Hanzl, and Vojt e ch C erm \'a k. Accident: A benchmark dataset for vehicle accident detection from traffic surveillance videos. In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2026
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.